Python 爬虫 爬取 煎蛋网 图片
今天, 试着爬取了煎蛋网的图片。
用到的包:
urllib.request
os
分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地。过程简单清晰明了
直接上源代码:
import urllib.request
import os def url_open(url):
req = urllib.request.Request(url)
req.add_header('user-agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36')
response = urllib.request.urlopen(url)
html = response.read() return html def get_page(url):
html = url_open(url).decode('utf-8') a = html.find('current-comment-page')+23
b = html.find(']',a) return html[a:b] def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = [] a = html.find('img src=') while a != -1:
b = html.find('.jpg',a ,a+255)
if b != -1:
img_addrs.append('https:'+html[a+9:b+4]) # 'img src='为9个偏移 '.jpg'为4个偏移
else:
b = a+9
a = html.find('img src=', b) return img_addrs def save_imgs(folder, img_addrs):
for each in img_addrs:
filename = each.split('/')[-1]
with open(filename, 'wb') as f:
img = url_open(each)
f.write(img)
print(img_addrs) def download_mm(folder = 'xxoo', pages = 5):
os.mkdir(folder)
os.chdir(folder) url = 'http://jandan.net/ooxx/'
page_num = int(get_page(url)) for i in range(pages):
page_num -= i
page_url = url + 'page-'+ str(page_num) + '#comments'
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs) if __name__ == '__main__':
download_mm()
其中在主函数download_mm()中,将pages设置在了5面。
本来设置的是10,但是在程序执行的过程中。出现了404ERROR错误
即imgae_url出现了错误。尝试着在save_img()函数中加入了测试代码:print(img_addrs),
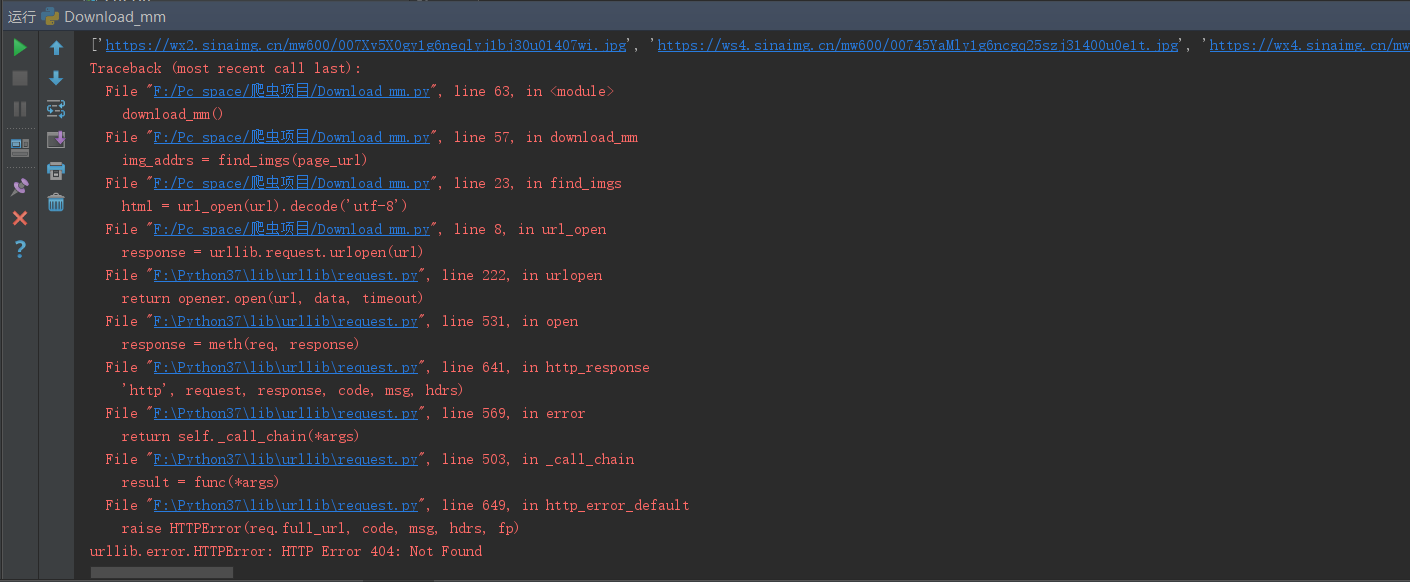
想到会不会是因为后面页数的图片,img_url的格式出现了改变,导致404,所以将pages改成5,
再次运行,结果没有问题,图片能正常下载:
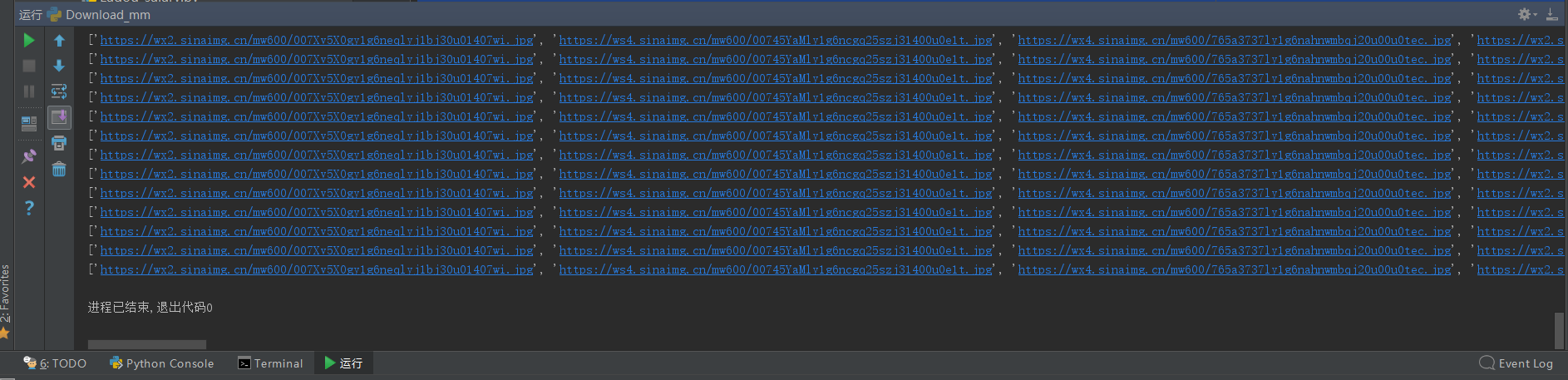
仔细观察发现,刚好是在第五面的图片往后,出现了不可下载的问题(404)。 所以在煎蛋网上,我们直接跳到第6面查看图片的url。

上图是后5面的图片url,下图是前5面的图片url

而源代码中,寻找的图片url为使用find()函数,进行定为<img src=‘’> <.jpg>中的图片url,所以后5面出现的a href 无法匹配,即出现了404 ERROR。如果想要下载后续的图片,需要重新添加一个url定位
即在find中将 img src 改成 a href,偏移量也需要更改。
总结:
使用find()来定位网页标签确实太过low,所以以后在爬虫中要尽量使用正则表达式和Beautifulsoup包来提高效率,而这两项我还不是特别熟,所以需要更多的训练。
Python 爬虫 爬取 煎蛋网 图片的更多相关文章
- python爬虫–爬取煎蛋网妹子图片
前几天刚学了python网络编程,书里没什么实践项目,只好到网上找点东西做. 一直对爬虫很好奇,所以不妨从爬虫先入手吧. Python版本:3.6 这是我看的教程:Python - Jack -Cui ...
- python爬虫爬取煎蛋网妹子图片
import urllib.request import os def url_open(url): req = urllib.request.Request(url) req.add_header( ...
- python3爬虫爬取煎蛋网妹纸图片(上篇)
其实之前实现过这个功能,是使用selenium模拟浏览器页面点击来完成的,但是效率实际上相对来说较低.本次以解密参数来完成爬取的过程. 首先打开煎蛋网http://jandan.net/ooxx,查看 ...
- Python Scrapy 爬取煎蛋网妹子图实例(一)
前面介绍了爬虫框架的一个实例,那个比较简单,这里在介绍一个实例 爬取 煎蛋网 妹子图,遗憾的是 上周煎蛋网还有妹子图了,但是这周妹子图变成了 随手拍, 不过没关系,我们爬图的目的是为了加强实战应用,管 ...
- scrapy从安装到爬取煎蛋网图片
下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/pip install wheelpip install lxmlpip install pyopens ...
- python3爬虫爬取煎蛋网妹纸图片(下篇)2018.6.25有效
分析完了真实图片链接地址,下面要做的就是写代码去实现了.想直接看源代码的可以点击这里 大致思路是:获取一个页面的的html---->使用正则表达式提取出图片hash值并进行base64解码--- ...
- Python Scrapy 爬取煎蛋网妹子图实例(二)
上篇已经介绍了 图片的爬取,后来觉得不太好,每次爬取的图片 都在一个文件下,不方便区分,且数据库中没有爬取的时间标识,不方便后续查看 数据时何时爬取的,所以这里进行了局部修改 修改一:修改爬虫执行方式 ...
- python爬取煎蛋网图片
``` py2版本: #-*- coding:utf-8 -*-#from __future__ import unicode_literimport urllib,urllib2,timeimpor ...
- selenium爬取煎蛋网
selenium爬取煎蛋网 直接上代码 from selenium import webdriver from selenium.webdriver.support.ui import WebDriv ...
随机推荐
- redis.windows.conf配置详解
redis.windows.conf配置详解 转自:https://www.cnblogs.com/kreo/p/4423362.html # redis 配置文件示例 # 当你需要为某个配置项指定内 ...
- 去重合并两个有序链表之直接操作和Set集合操作
两者思路对比: 直接操作:因为传入的是两个有序的链表,所以说我就直接以其中一个链表为基准,与另外一个链表比较,只将比返回值链表的最后一个记录的值大的插入,不将等值的插入,理论时间复杂度为O(n) Se ...
- Salesforce LWC学习(七) Navigation & Toast
上一篇我们介绍了针对LWC中常用的LDS的适配的wire service以及@salesforce模块提供的相关的service,其实LWC中还提供其他的好用的service,比如针对导航相关的lig ...
- 算法与数据结构基础 - 递归(Recursion)
递归基础 递归(Recursion)是常见常用的算法,是DFS.分治法.回溯.二叉树遍历等方法的基础,典型的应用递归的问题有求阶乘.汉诺塔.斐波那契数列等,可视化过程. 应用递归算法一般分三步,一是定 ...
- Python 踩坑之旅文件系统篇其一文件夹也是个文件
目录 1.1 案例 1.2 分析 1.3 扩展 1.4 技术关键字 下期预告 代码示例支持 平台: Mac OS Python: 2.7.10 代码示例: - wx: 菜单 - Python踩坑指南代 ...
- FEDay会后-Serverless与云开发,可能是前端的下一站
进化本身是生物体与环境之间持续不断的信息交换的具体表现. -- 摘自<信息简史> 很荣幸在9月21号成都举办的第五届FEDay上作为讲师为大家分享腾讯云在近两年推出的云开发相关的技术和知识 ...
- 200行代码实现Mini ASP.NET Core
前言 在学习ASP.NET Core源码过程中,偶然看见蒋金楠老师的ASP.NET Core框架揭秘,不到200行代码实现了ASP.NET Core Mini框架,针对框架本质进行了讲解,受益匪浅,本 ...
- Java假期样卷 简易通讯录
score.java package score; public class score { String name; String num; int age; boolean sex; double ...
- .net core 使用Rotativa创建PDF文档
一.下载Rotaiva 工具 = > NuGet包管理器 = > 管理解决方案的NuGet程序包 在打开的页面中搜索 Rotativa.AspNetCore 如下图: 选中红框的记 ...
- mysql replace into使用
使用mysql插入数据时,我们通常使用的是insert into来处理,replace into有时可以替代insert into功能,但replace into也有自己的用法 准备一张测试表: CR ...