算法-一步步教你如何用c语言实现堆排序(非递归)
看了左神的堆排序,觉得思路很清晰,比常见的递归的堆排序要更容易理解,所以自己整理了一下笔记,带大家一步步实现堆排序算法
首先介绍什么是大根堆:每一个子树的最大值都是子树的头结点,即根结点是所有结点的最大值
堆排序是基于数组和二叉树思想实现的(二叉树是脑补结构,实际是数组)
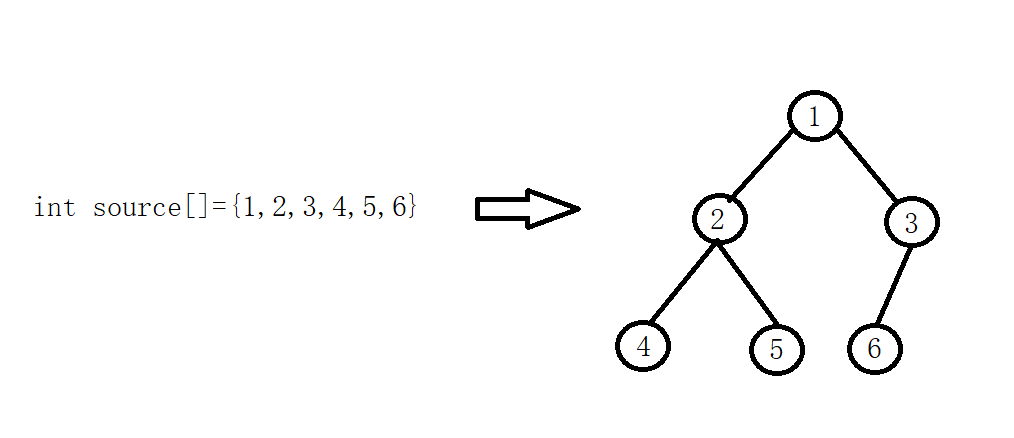
堆排序过程
1、数组建成大根堆,首先,遍历所有结点,当前结点index和父结点(index-1)/ 2 比较 (当前数组的下标是index,此结点的父结点的下标就是(index-1)/ 2 ),如果比父结点大,交换,变成父结点的位置再和上一层的父结点比较,直到满足大根堆条件
int swap(int source[], int a, int b)
{
int temp = source[a];
source[a] = source[b];
source[b] = temp;
}
int heapsort(int source[], int len)
{
for (int i = ; i <len; i++)
{
heapInsert(source, i);
}
}
int heapInsert(int source[], int index)
{
while (source[index] > source[(index - ) / ])
{
swap(source, index, (index - ) / );
index = (index - ) / ;
}
}
2、让根结点和最后一个结点交换位置,也就是数组的第一个数和最后一个数交换位置,接下来最后一个数不用考虑了,比如一个数组有5个数,定义一个变量size=5,大根堆的根结点放到最后一个数后,--size
int size = len;
swap(source, , --size);
3、让交换后的头结点经历一个向下的调整,让结点和自己的两个孩子比较,如果孩子的值比头结点大,交换,交换到孩子结点位置,继续和下面的两个孩子比较,直到满足大根堆条件
int heapify(int source[], int index, int size)//index表示要和它两个孩子比较的结点
{
int left = index * + ; //找到index左孩子结点的数组下标
while (left < size)
{
int largest = left + < size && source[left + ] > source[left] ? source[left + ] : source[left];//如果有右孩子且右孩子比左孩子大,令largest=右孩子的值,也就是把两个孩子中最大的一个数赋给largest
if (source[index] < source[largest])
{
swap(source, index, largest);
index = largest;
left = index * + ;
}
else break;
} }
4、重复第2步,第3步,直到size = 0 ,整个数组排序过程结束
while (size > )
{
swap(source, , --size);
heapify(source, , size);
}
源代码如下
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int swap(int source[], int a, int b)
{
int temp = source[a];
source[a] = source[b];
source[b] = temp;
}
int heapsort(int source[], int len)
{
for (int i = ; i < len; i++)
{
heapInsert(source, i);
}
int size = len;
while (size > )
{
swap(source, , --size);
heapify(source, , size);
}
}
int heapInsert(int source[], int index)
{
while (source[index] > source[(index - ) / ])
{
swap(source, index, (index - ) / );
index = (index - ) / ;
}
}
int heapify(int source[], int index, int size)//index表示要和它两个孩子比较的结点
{
int left = index * + ; //找到index左孩子结点的数组下标
while (left < size)
{
int largest = left + < size && source[left + ] > source[left] ? left + : left;//如果有右孩子且右孩子比左孩子大,令largest=右孩子的值,也就是把两个孩子中最大的一个数赋给largest
if (source[index] < source[largest])
{
swap(source, index, largest);
index = largest;
left = index * + ;
}
else break;
} }
int main()
{
int source[] = { ,,,,,,,,,,,,,,,,, };
int len;
len = sizeof(source) / sizeof(int);
heapsort(source, len);
for (int i = ; i < len; i++)
{
printf("%d ", source[i]);
} }
输出结果

以上就是堆排序的所有细节,这个版本很优良,堆排序的额外空间复杂度是O(1),如果用递归的话,递归有递归栈,额外空间复杂度不就上去了吗,设计成这种迭代的可以省空间,时间复杂度为O(n log n)
转载请注明出处、作者 谢谢
算法-一步步教你如何用c语言实现堆排序(非递归)的更多相关文章
- 自己写算法---java的堆的非递归遍历
import java.io.*; import java.util.*; public class Main { public static void main(String args[]) { S ...
- 一步步教你轻松学奇异值分解SVD降维算法
一步步教你轻松学奇异值分解SVD降维算法 (白宁超 2018年10月24日09:04:56 ) 摘要:奇异值分解(singular value decomposition)是线性代数中一种重要的矩阵分 ...
- 一步步教你轻松学支持向量机SVM算法之案例篇2
一步步教你轻松学支持向量机SVM算法之案例篇2 (白宁超 2018年10月22日10:09:07) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- 一步步教你轻松学支持向量机SVM算法之理论篇1
一步步教你轻松学支持向量机SVM算法之理论篇1 (白宁超 2018年10月22日10:03:35) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- 一步步教你轻松学主成分分析PCA降维算法
一步步教你轻松学主成分分析PCA降维算法 (白宁超 2018年10月22日10:14:18) 摘要:主成分分析(英语:Principal components analysis,PCA)是一种分析.简 ...
- 一步步教你轻松学关联规则Apriori算法
一步步教你轻松学关联规则Apriori算法 (白宁超 2018年10月22日09:51:05) 摘要:先验算法(Apriori Algorithm)是关联规则学习的经典算法之一,常常应用在商业等诸多领 ...
- 一步步教你轻松学K-means聚类算法
一步步教你轻松学K-means聚类算法(白宁超 2018年9月13日09:10:33) 导读:k-均值算法(英文:k-means clustering),属于比较常用的算法之一,文本首先介绍聚类的理 ...
- 一步步教你轻松学朴素贝叶斯模型算法Sklearn深度篇3
一步步教你轻松学朴素贝叶斯深度篇3(白宁超 2018年9月4日14:18:14) 导读:朴素贝叶斯模型是机器学习常用的模型算法之一,其在文本分类方面简单易行,且取得不错的分类效果.所以很受欢迎,对 ...
- 一步步教你轻松学KNN模型算法
一步步教你轻松学KNN模型算法( 白宁超 2018年7月24日08:52:16 ) 导读:机器学习算法中KNN属于比较简单的典型算法,既可以做聚类又可以做分类使用.本文通过一个模拟的实际案例进行讲解. ...
随机推荐
- Flume NG高可用集群搭建详解
.Flume NG简述 Flume NG是一个分布式,高可用,可靠的系统,它能将不同的海量数据收集,移动并存储到一个数据存储系统中.轻量,配置简单,适用于各种日志收集,并支持 Failover和负载均 ...
- SYN1618型 高精度天文时间同步系统
SYN1618型 高精度天文时间同步系统 产品概述 SYN1618型 高精度天文时间同步系统是由西安同步电子科技有限公司精心设计.自行研发生产的一款高精度的时频频率标准设备,接收GPS.GLON ...
- python集合的内建函数
s.issubset(t) 如果s 是t 的子集,则返回True,否则返回False s.issuperset(t) 如果t 是s 的超集,则返回True,否则返回False s.union(t) 返 ...
- 常用Linux网络命令
TCP状态统计: netstat -anp TCP各个状态的连接数:netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a] ...
- Mac sublime text3 安装插件
一.下载Mac版sublime text3 下载地址:http://www.pc6.com/mac/120663.html(参考) 2.安装后打开 1.在界面的最上端找到tools(英文版),选择第一 ...
- 【IDE】idea在debug模式启动非常慢,debug模式一直在启动中状态
现象:一直处于启动中状态,日志刷的很慢,非debug模式正常启动: 最终解决方式:下图按钮,取消所有打过的断点,问题解决
- Oracle 数据库表中已有重复数据添加唯一键(唯一约束)
Oracle 数据库表中已有重复数据添加唯一键(唯一约束) 问题描述 以 demo 举例,模拟真实场景. 表 TEST_TABLE 有如下字段和数据:id 是主键,code 没有设置键和索引 ID C ...
- 你所不知的spring与mybatis整合方法
内容目录 1.采用MapperScannerConfigurer2.采用接口org.apache.ibatis.session.SqlSession的实现类org.mybatis.spring.Sql ...
- MySQL metalock的一些技巧(写大于读的案例,以及获得锁的顺序)
前言:元数据锁不是锁定数据,而是锁定描述数据的元数据信息.就像很多装修工人(工作线程)在室内(对象上)装修(操作),不能有其他工人(线程)把屋子拆了(表删除了). MySQL 为了数据一致性使用元数据 ...
- SPOJ:NPC2016A(数学)
http://www.spoj.com/problems/NPC2016A/en/ 题意:在一个n*n的平面里面,初始在(x,y)需要碰到每条边一次,然后返回(x,y),问最短路径是多长. 思路:像样 ...