Hadoop3.2.1版本的环境搭建
关注:Java提升营,最新文章第一时间送达,10T 免费学习资料随时领取!!!
最近有人提出能不能发一些大数据相关的知识,No problem ! 今天先从安装环境说起,搭建起自己的学习环境。
Hadoop的三种搭建方式以及使用环境:
- 单机版适合开发调试;
- 伪分布式适合模拟集群学习;
- 完全分布式适用生产环境。
这篇文件介绍如何搭建完全分布式的hadoop集群,一个主节点,两个数据节点。
先决条件
- 准备3台服务器
虚拟机、物理机、云上实例均可,本篇使用Openstack私有云里面的3个实例进行安装部署。
- 操作系统及软件版本
| 服务器 | 系统 | 内存 | IP | 规划 | JDK | HADOOP |
|---|---|---|---|---|---|---|
| node1 | Ubuntu 18.04.2 LTS | 8G | 10.101.18.21 | master | JDK 1.8.0_222 | hadoop-3.2.1 |
| node2 | Ubuntu 18.04.2 LTS | 8G | 10.101.18.8 | slave1 | JDK 1.8.0_222 | hadoop-3.2.1 |
| node3 | Ubuntu 18.04.2 LTS | 8G | 10.101.18.24 | slave2 | JDK 1.8.0_222 | hadoop-3.2.1 |
- 三台机器安装JDK
因为Hadoop是用Java语言编写的,所以计算机上需要安装Java环境,我在这使用JDK 1.8.0_222(推荐使用Sun JDK)
安装命令
sudo apt install openjdk-8-jdk-headless
配置JAVA环境变量,在当前用户根目录下的.profile文件最下面加入以下内容:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
使用source命令让立即生效
source .profile
- host配置
修改三台服务器的hosts文件
vim /etc/hosts
#添加下面内容,根据个人服务器IP配置
10.101.18.21 master
10.101.18.8 slave1
10.101.18.24 slave2
免密登陆配置
- 生产秘钥
ssh-keygen -t rsa
- master免密登录到slave中
ssh-copy-id -i ~/.ssh/id_rsa.pub master
ssh-copy-id -i ~/.ssh/id_rsa.pub slave1
ssh-copy-id -i ~/.ssh/id_rsa.pub slave2
- 测试免密登陆
ssh master
ssh slave1
ssh slave2
Hadoop搭建
我们先在Master节点下载Hadoop包,然后修改配置,随后复制到其他Slave节点稍作修改就可以了。
- 下载安装包,创建Hadoop目录
#下载
wget http://http://apache.claz.org/hadoop/common/hadoop-3.2.1//hadoop-3.2.1.tar.gz
#解压到 /usr/local 目录
sudo tar -xzvf hadoop-3.2.1.tar.gz -C /usr/local
#修改hadoop的文件权限
sudo chown -R ubuntu:ubuntu hadoop-3.2.1.tar.gz
#重命名文件夹
sudo mv hadoop-3.2.1 hadoop
- 配置Master节点的Hadoop环境变量
和配置JDK环境变量一样,编辑用户目录下的.profile文件, 添加Hadoop环境变量:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
执行 source .profile 让立即生效
- 配置Master节点
Hadoop 的各个组件均用XML文件进行配置, 配置文件都放在 /usr/local/hadoop/etc/hadoop 目录中:
- core-site.xml:配置通用属性,例如HDFS和MapReduce常用的I/O设置等
- hdfs-site.xml:Hadoop守护进程配置,包括namenode、辅助namenode和datanode等
- mapred-site.xml:MapReduce守护进程配置
- yarn-site.xml:资源调度相关配置
a. 编辑core-site.xml文件,修改内容如下:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
参数说明:
- fs.defaultFS:默认文件系统,HDFS的客户端访问HDFS需要此参数
- hadoop.tmp.dir:指定Hadoop数据存储的临时目录,其它目录会基于此路径, 建议设置到一个足够空间的地方,而不是默认的/tmp下
如没有配置
hadoop.tmp.dir参数,系统使用默认的临时目录:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被删除,必须重新执行format才行,否则会出错。
b. 编辑hdfs-site.xml,修改内容如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
</property>
</configuration>
参数说明:
- dfs.replication:数据块副本数
- dfs.name.dir:指定namenode节点的文件存储目录
- dfs.data.dir:指定datanode节点的文件存储目录
c. 编辑mapred-site.xml,修改内容如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
d. 编辑yarn-site.xml,修改内容如下:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME</value>
</property>
</configuration>
e. 编辑workers, 修改内容如下:
slave1
slave2
配置worker节点
- 配置Slave节点
将Master节点配置好的Hadoop打包,发送到其他两个节点:
# 打包hadoop包
tar -cxf hadoop.tar.gz /usr/local/hadoop
# 拷贝到其他两个节点
scp hadoop.tar.gz ubuntu@slave1:~
scp hadoop.tar.gz ubuntu@slave2:~
在其他节点加压Hadoop包到/usr/local目录
sudo tar -xzvf hadoop.tar.gz -C /usr/local/
配置Slave1和Slaver2两个节点的Hadoop环境变量:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
启动集群
- 格式化HDFS文件系统
进入Master节点的Hadoop目录,执行一下操作:
bin/hadoop namenode -format
格式化namenode,第一次启动服务前执行的操作,以后不需要执行。
截取部分日志(看第5行日志表示格式化成功):
2019-11-11 13:34:18,960 INFO util.GSet: VM type = 64-bit
2019-11-11 13:34:18,960 INFO util.GSet: 0.029999999329447746% max memory 1.7 GB = 544.5 KB
2019-11-11 13:34:18,961 INFO util.GSet: capacity = 2^16 = 65536 entries
2019-11-11 13:34:18,994 INFO namenode.FSImage: Allocated new BlockPoolId: BP-2017092058-10.101.18.21-1573450458983
2019-11-11 13:34:19,010 INFO common.Storage: Storage directory /usr/local/hadoop/hdfs/name has been successfully formatted.
2019-11-11 13:34:19,051 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop/hdfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2019-11-11 13:34:19,186 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/hdfs/name/current/fsimage.ckpt_0000000000000000000 of size 401 bytes saved in 0 seconds .
2019-11-11 13:34:19,207 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2019-11-11 13:34:19,214 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
- 启动Hadoop集群
sbin/start-all.sh
启动过程遇到的问题与解决方案:
a. 错误:master: rcmd: socket: Permission denied
解决:
执行 echo "ssh" > /etc/pdsh/rcmd_default
b. 错误:JAVA_HOME is not set and could not be found.
解决:
修改三个节点的hadoop-env.sh,添加下面JAVA环境变量
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
- 使用jps命令查看运行情况
Master节点执行输出:
19557 ResourceManager
19914 Jps
19291 SecondaryNameNode
18959 NameNode
Slave节点执行输入:
18580 NodeManager
18366 DataNode
18703 Jps
- 查看Hadoop集群状态
hadoop dfsadmin -report
查看结果:
Configured Capacity: 41258442752 (38.42 GB)
Present Capacity: 5170511872 (4.82 GB)
DFS Remaining: 5170454528 (4.82 GB)
DFS Used: 57344 (56 KB)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (2):
Name: 10.101.18.24:9866 (slave2)
Hostname: slave2
Decommission Status : Normal
Configured Capacity: 20629221376 (19.21 GB)
DFS Used: 28672 (28 KB)
Non DFS Used: 16919797760 (15.76 GB)
DFS Remaining: 3692617728 (3.44 GB)
DFS Used%: 0.00%
DFS Remaining%: 17.90%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Mon Nov 11 15:00:27 CST 2019
Last Block Report: Mon Nov 11 14:05:48 CST 2019
Num of Blocks: 0
Name: 10.101.18.8:9866 (slave1)
Hostname: slave1
Decommission Status : Normal
Configured Capacity: 20629221376 (19.21 GB)
DFS Used: 28672 (28 KB)
Non DFS Used: 19134578688 (17.82 GB)
DFS Remaining: 1477836800 (1.38 GB)
DFS Used%: 0.00%
DFS Remaining%: 7.16%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Mon Nov 11 15:00:24 CST 2019
Last Block Report: Mon Nov 11 13:53:57 CST 2019
Num of Blocks: 0
- 关闭Hadoop
sbin/stop-all.sh
Web查看Hadoop集群状态
在浏览器输入 http://10.101.18.21:9870 ,结果如下:
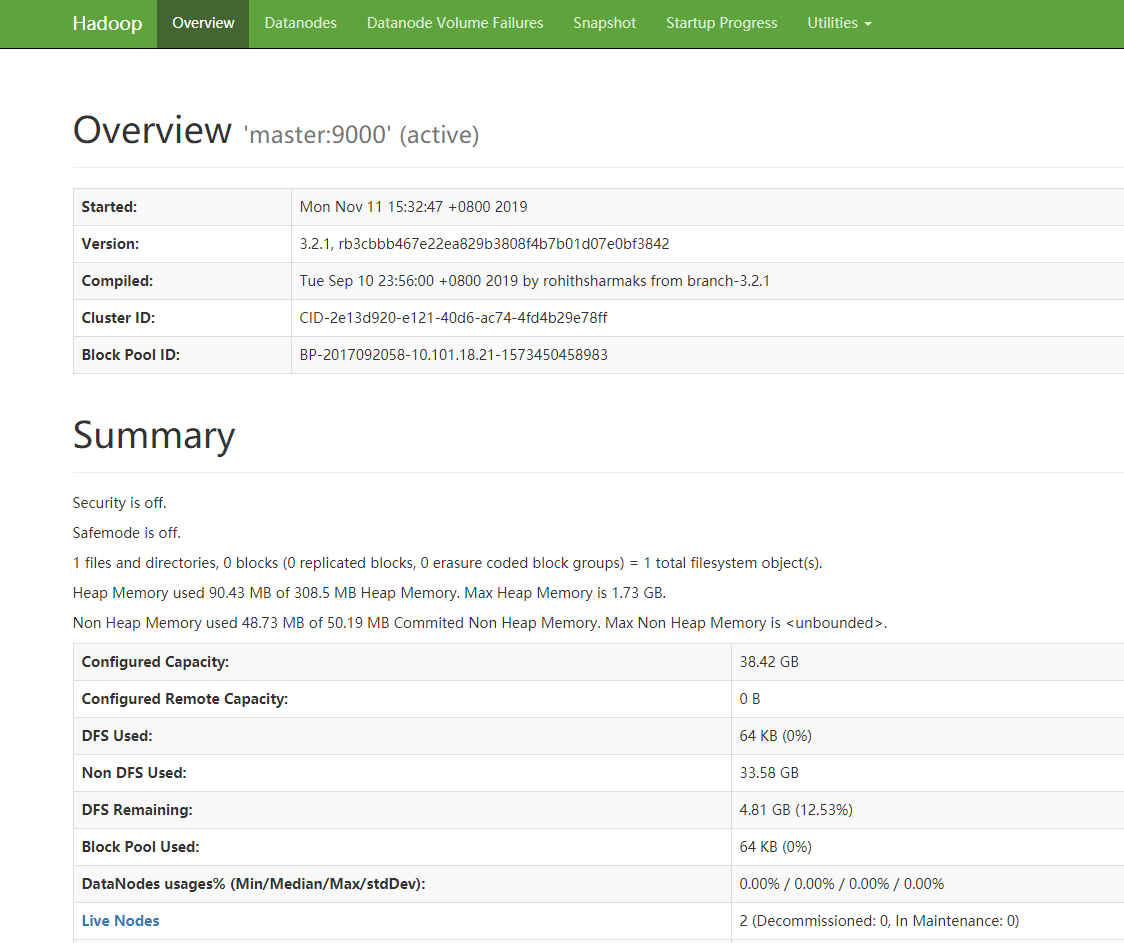
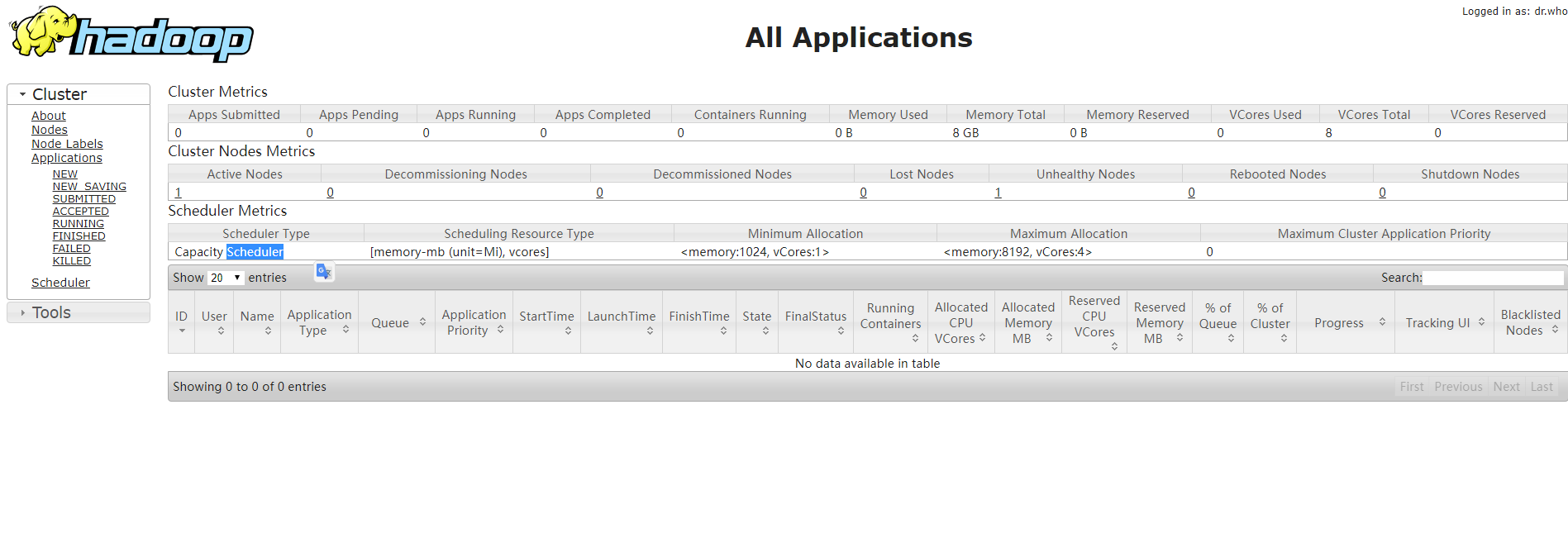
在浏览器输入 http://10.101.18.21:8088 ,结果如下:
Hadoop3.2.1版本的环境搭建的更多相关文章
- 大数据学习笔记【一】:Hadoop-3.1.2完全分布式环境搭建(Windows 10)
一.前言 Hadoop原理架构本人就不在此赘述了,可以自行百度,本文仅介绍Hadoop-3.1.2完全分布式环境搭建(本人使用三个虚拟机搭建). 首先,步骤: ① 准备安装包和工具: hadoop-3 ...
- 一步一步了解Cocos2dx 3.0 正式版本开发环境搭建(Win32/Android)
cocos2d-x 3.0发布有一段时间了,作为一个初学者,我一直觉得cocos2d-x很坑.每个比较大的版本变动,都会有不一样的项目创建方式,每次的跨度都挺大…… 但是凭心而论,3.0RC版本开始 ...
- Cocos2d-X-3.0 之后的版本的环境搭建
Cocos2d-X-3.0 之后的版本的环境搭建 由于cocos2d游戏开发引擎更新十分频繁,官方文档同步不够及时和完善.所以不要照着官方文档来照做生成工程. <点击图片就能进入网站> ...
- Cocos2d-X-3.0之后的版本的环境搭建
由于cocos2d游戏开发引擎更新十分频繁,官方文档同步不够及时和完善.所以不要照着官方文档来照做生成工程. <点击图片就能进入网站> 具体的步骤: 1.获取cocos2d-X的源码v3. ...
- HDFS【hadoop3.1.3 windows开发环境搭建】
目录 一.配置hadoop3.1.3 windows环境依赖 配置环境变量 添加到path路径 在cmd中测试 二.idea中的配置 创建工程/模块 添加pom.xml依赖 日志添加--配置log4j ...
- go 版本 gRPC 环境搭建(3.0正式版)
之前装过 gRPC 的各个测试版本,有些残余的文件,正式版的安装和之前残留的清除整理如下: 安装 go 版本的 gRPC go 的安装略过.需要 go 1.5 以上版本. $ go version ...
- py-faster-rcnn(running the demo): ubuntu14.04+caffe+cuda7.5+cudnn5.1.3+python2.7环境搭建记录
第一次写博客,以此纪念这几天安装caffe,跑faster-rcnn的血泪史.在此特别感谢网络各路大神,来自全球各地,让我能从中汲取营养,吸取经验,总结规律. faster-rcnn分为matlab版 ...
- Cocos2d-x 3.2 学习笔记(一)环境搭建
目前项目无事,时间比较充裕,因此来学习下cocos2dx,当然本人也是新手一个, 写此笔记做备忘和脚步. 最近3.2版本更新出來了!官方说这是自2.x分支以来修复了超过450个bug,3.2版本是目前 ...
- OpenCV环境搭建
前言 我在上本科时候曾经用过opencv,那时候还是1.x版本,还必须在linux下自己编译. 时过境迁,最近突然想起来写个小程序来分析图片,就又想起了opencv.现在已然是2.4的版本. 环境搭建 ...
随机推荐
- json.dumps和json.loads
概念理解 1.json.dumps()和json.loads()是json格式处理函数(可以这么理解,json是字符串) (1)json.dumps()函数是将一个Python数据类型列表进行json ...
- Java自动化测试框架-01 - TestNG之入门篇 - 大佬的鸡肋,菜鸟的盛宴(详细教程)
TestNG是什么? TestNG按照官方的定义: TestNG是一个测试框架,其灵感来自JUnit和NUnit,但引入了一些新的功能,使其功能更强大,使用更方便. TestNG是一个开源自动化测试框 ...
- Java线程池的底层实现与使用
前言 在我们进行开发的时候,为了充分利用系统资源,我们通常会进行多线程开发,实现起来非常简单,需要使用线程的时候就去创建一个线程(继承Thread类.实现Runnable接口.使用Callable和F ...
- Redis之数据类型及命令
Redis(REmote DIctionary Server) 是一个遵守BSD协议.支持网络.可基于内存亦可持久化的日志型key-value存储系统. KEY 常用指令: 指令 注释 备注 exit ...
- bugku账号被盗了
首先访问这个网站. 点击一下 使用burp抓包 将false改为true试试,获得了新的返回包,包含了一个网站,访问这个网站,下载下发现是一个软件. 随便填写一个账号密码,并使用wireshark抓包 ...
- python自动化测试三部曲之request+django实现接口测试
国庆期间准备写三篇博客,介绍和总结下接口测试,由于国庆期间带娃,没有按照计划完成,今天才完成第二篇,惭愧惭愧. 这里我第一篇博客的地址:https://www.cnblogs.com/bainianm ...
- tf.split
tf.split(dimension, num_split, input):dimension的意思就是输入张量的哪一个维度,如果是0就表示对第0维度进行切割.num_split就是切割的数量,如果是 ...
- Idea项目注释规范设置
Idea项目注释规范设置文档 1.类注释: /** *@ClassName: ${NAME} *@Description: TODO *@Author: guohui *@Da ...
- Web安全之爆破中的验证码识别~
写爆破靶场的时候发现对于爆破有验证码的有点意思~这里简单总结下我们爆破有验证码的场景中几种有效的方法~~~ 0x01 使用现成工具 这里有pkav团队的神器PKAV HTTP Fuzzer 1.5.6 ...
- PHP list的赋值
List右边的赋值对象是一个以数值为索引的数组,左边的变量的位置和赋值对象的键值一一对应,有些位置的变量可以省略不写.非末尾的被赋值变量省略时,分隔的逗号不能省略.左边变量被赋值的顺序是从右到左的. ...