spark通过JDBC读取外部数据库,过滤数据
官网链接:
http://spark.apache.org/docs/latest/sql-programming-guide.html#jdbc-to-other-databases
http://spark.apache.org/docs/latest/sql-data-sources-jdbc.html
1. 过滤数据
情景:使用spark通过JDBC的方式读取postgresql数据库中的表然后存储到hive表中供后面数据处理使用,但是只读取postgresql表中的某些字段,并且做一下数据上的过滤
根据平常的方式,基本都是读取整张表,感觉不应该这么不友好的,于是去官网翻了翻,如下:
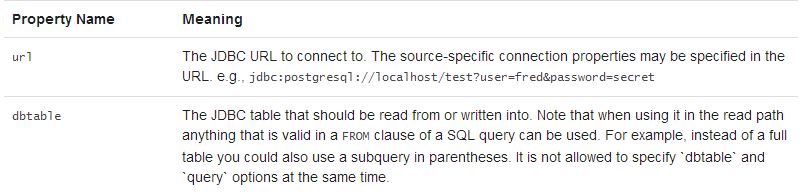
指定dbtable参数时候可以使用子查询的方式,不单纯是指定表名
测试代码如下:
package com.kong.test.test;
import java.util.Properties;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
public class SparkHiveTest {
public static void main(String[] args) {
SparkSession spark = SparkSession
.builder()
.appName("SparkCalibration")
.master("local")
.enableHiveSupport()
.getOrCreate();
spark.sparkContext().setLogLevel("ERROR");
spark.sparkContext().setLocalProperty("spark.scheduler.pool", "production");
String t2 = "(select id, name from test1) tmp";//这里需要有个别名
String createSql = "create table if not exists default.test1 (\r\n" +
"id string,\r\n" +
"name string\r\n" +
")ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' stored as TEXTFILE";
spark.sql(createSql);
spark.read().format("jdbc")
.option("url", "jdbc:postgresql://ip address/database")
.option("dbtable", t2).option("user", "login user").option("password", "login passwd")
.option("fetchsize", "1000")
.load()
.createOrReplaceTempView("test1_tmp");
spark.sql("insert overwrite table default.test1 select * from test1_tmp").show();
}
}
另外:如果对于hive表的存储格式没有要求,可以更简洁,如下:
spark.read().format("jdbc")
.option("url", "jdbc:postgresql://ip address/database")
.option("dbtable", t2).option("user", "login user").option("password", "login passwd")
.option("fetchsize", "1000")
.load().write().mode(SaveMode.Overwrite).saveAsTable("default.test");
至于基于哪种保存模式(SaveMode.Overwrite)可以结合实际场景;另外spark saveAsTable()默认是以parquet+snappy的形式写数据(生成的文件名.snappy.parquet),当然,也可以通过format()传入参数,使用orc等格式,并且可以指定其他压缩方式。
2. spark通过JDBC读取外部数据库的源码实现
2.1 最简洁的api,单分区
源码如下:
/**
* Construct a `DataFrame` representing the database table accessible via JDBC URL
* url named table and connection properties.
*
* @since 1.4.0
*/
def jdbc(url: String, table: String, properties: Properties): DataFrame = {
assertNoSpecifiedSchema("jdbc")
// properties should override settings in extraOptions.
this.extraOptions ++= properties.asScala
// explicit url and dbtable should override all
this.extraOptions += (JDBCOptions.JDBC_URL -> url, JDBCOptions.JDBC_TABLE_NAME -> table)
format("jdbc").load()
}
2.2 指定表某个字段的上下限值(数值类型),生成相对应的where条件并行读取,源码如下:
/**
* Construct a `DataFrame` representing the database table accessible via JDBC URL
* url named table. Partitions of the table will be retrieved in parallel based on the parameters
* passed to this function.
*
* Don't create too many partitions in parallel on a large cluster; otherwise Spark might crash
* your external database systems.
*
* @param url JDBC database url of the form `jdbc:subprotocol:subname`.
* @param table Name of the table in the external database.
* @param columnName the name of a column of integral type that will be used for partitioning.
* @param lowerBound the minimum value of `columnName` used to decide partition stride.
* @param upperBound the maximum value of `columnName` used to decide partition stride.
* @param numPartitions the number of partitions. This, along with `lowerBound` (inclusive),
* `upperBound` (exclusive), form partition strides for generated WHERE
* clause expressions used to split the column `columnName` evenly. When
* the input is less than 1, the number is set to 1.
* @param connectionProperties JDBC database connection arguments, a list of arbitrary string
* tag/value. Normally at least a "user" and "password" property
* should be included. "fetchsize" can be used to control the
* number of rows per fetch.
* @since 1.4.0
*/
def jdbc(
url: String,
table: String,
columnName: String,
lowerBound: Long,
upperBound: Long,
numPartitions: Int,
connectionProperties: Properties): DataFrame = {
// columnName, lowerBound, upperBound and numPartitions override settings in extraOptions.
this.extraOptions ++= Map(
JDBCOptions.JDBC_PARTITION_COLUMN -> columnName,
JDBCOptions.JDBC_LOWER_BOUND -> lowerBound.toString,
JDBCOptions.JDBC_UPPER_BOUND -> upperBound.toString,
JDBCOptions.JDBC_NUM_PARTITIONS -> numPartitions.toString)
jdbc(url, table, connectionProperties)
}
2.3 通过predicates: Array[String],传入每个分区的where子句中的谓词条件,并行读取,比如 :
String[] predicates = new String[] {"date <= '20180501'","date > '20180501' and date <= '20181001'","date > '20181001'"};
/**
* Construct a `DataFrame` representing the database table accessible via JDBC URL
* url named table using connection properties. The `predicates` parameter gives a list
* expressions suitable for inclusion in WHERE clauses; each one defines one partition
* of the `DataFrame`.
*
* Don't create too many partitions in parallel on a large cluster; otherwise Spark might crash
* your external database systems.
*
* @param url JDBC database url of the form `jdbc:subprotocol:subname`
* @param table Name of the table in the external database.
* @param predicates Condition in the where clause for each partition.
* @param connectionProperties JDBC database connection arguments, a list of arbitrary string
* tag/value. Normally at least a "user" and "password" property
* should be included. "fetchsize" can be used to control the
* number of rows per fetch.
* @since 1.4.0
*/
def jdbc(
url: String,
table: String,
predicates: Array[String],
connectionProperties: Properties): DataFrame = {
assertNoSpecifiedSchema("jdbc")
// connectionProperties should override settings in extraOptions.
val params = extraOptions.toMap ++ connectionProperties.asScala.toMap
val options = new JDBCOptions(url, table, params)
val parts: Array[Partition] = predicates.zipWithIndex.map { case (part, i) =>
JDBCPartition(part, i) : Partition
}
val relation = JDBCRelation(parts, options)(sparkSession)
sparkSession.baseRelationToDataFrame(relation)
}
spark通过JDBC读取外部数据库,过滤数据的更多相关文章
- 读取mysql数据库的数据,转为json格式
# coding=utf-8 ''' Created on 2016-10-26 @author: Jennifer Project:读取mysql数据库的数据,转为json格式 ''' import ...
- spring(读取外部数据库配置信息、基于注解管理bean、DI)
###解析外部配置文件在resources文件夹下,新建db.properties(和数据库连接相关的信息) driverClassName=com.mysql.jdbc.Driverurl=jdbc ...
- 读取mysq数据库l数据,并使用dataview显示
来自<sencha touch权威指南>,约198页开始 通过php脚本,可以将mysql数据库的数据作为json数据格式进行读取. (1)php代码(bookinfo.php): < ...
- AndroidStudio 中查看获取MD5和SHA1值以及如何查看手机应用信息以及读取*.db数据库里面数据
查看获取MD5和SHA1值具体操作方式链接 查看获取MD5和SHA1值实际操作命令CMD语句: C:\Users\Administrator>cd .android C:\Users\Admin ...
- C# 读取Oracle数据库视图数据异常问题处理
会出现类似现在这种提示的错误 System.Data.OracleClient 需要 Oracle 客户端软件 version 8.1.7 或更高版本 情况1.开发过程中遇到这种问题解决 由于.net ...
- 在jsp页面直接读取mysql数据库显示数据
闲来无事,学学java,虽说编程语言相通,但是接触一门新知识还是有些疑惑,边学边记录,方便以后温故. 直接给出代码: <%@page import="java.sql.ResultSe ...
- Excel2003读取sqlserver数据库表数据(图)
- 使用JDBC在MySQL数据库中快速批量插入数据
使用JDBC连接MySQL数据库进行数据插入的时候,特别是大批量数据连续插入(10W+),如何提高效率呢? 在JDBC编程接口中Statement 有两个方法特别值得注意: void addBatch ...
- [原创]java使用JDBC向MySQL数据库批次插入10W条数据测试效率
使用JDBC连接MySQL数据库进行数据插入的时候,特别是大批量数据连续插入(100000),如何提高效率呢?在JDBC编程接口中Statement 有两个方法特别值得注意:通过使用addBatch( ...
随机推荐
- 牛客小白月赛16 E 小雨的矩阵 ( 暴搜)
链接:https://ac.nowcoder.com/acm/contest/949/E来源:牛客网 时间限制:C/C++ 1秒,其他语言2秒 空间限制:C/C++ 262144K,其他语言52428 ...
- 【小家Spring】聊聊Spring中的数据绑定 --- DataBinder本尊(源码分析)
每篇一句 唯有热爱和坚持,才能让你在程序人生中屹立不倒,切忌跟风什么语言或就学什么去~ 相关阅读 [小家Spring]聊聊Spring中的数据绑定 --- 属性访问器PropertyAccessor和 ...
- Zeppelin0.5.6使用spark解释器
Zeppelin为0.5.6 Zeppelin默认自带本地spark,可以不依赖任何集群,下载bin包,解压安装就可以使用. 使用其他的spark集群在yarn模式下. 配置: vi zeppelin ...
- 解决springboot项目请求出现非法字符问题 java.lang.IllegalArgumentException:Invalid character found in the request target. The valid characters are defined in RFC 7230 and RFC 3986
springboot版本: 2.1.5 最近使用springboot搭建了一个App后台服务的项目,开发接口的时候在本机使用postman工具做请求测试,请求返回一直很正常,但是在前端开发使用h5请求 ...
- 个人永久性免费-Excel催化剂功能第99波-手机号码归属地批量查询
高潮过往趋于平静,送上简单的手机号码归属地查询,因接口有数量限制,仅能满足少量数据需求,如有大规模数据却又想免费获得,这就成为无解了,数据有价,且用且珍惜. 业务使用场景 除了日常自带的手机各种管家为 ...
- 个人永久性免费-Excel催化剂功能第23波-非同一般地批量拆分工作表
工作薄的合并,许多Excel插件已有提供,Excel催化剂也提供了最佳的解决方案,另外还有工作薄的拆分和工作表的拆分,同样也是各大插件必备功能. 至于工作薄拆分,那是伪需求,Excel催化剂永远只会带 ...
- python常见模块-collections-time-datetime-random-os-sys-序列化反序列化模块(json-pickle)-subprocess-03
collections模块-数据类型扩展模块 ''' 在内置数据类型(dict.list.set.tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter.deque ...
- Centos7配置BIND开机自启动
Centos7上面已经把/etc/init.d/服务的启动方式更改为systemctl启动. 当然编译安装仍然可以/etc/init.d/手动启动但是chkconfig –add named就用不了. ...
- GStreamer基础教程06 - 获取媒体信息
摘要 在常见的媒体文件中,通常包含一些数据(例如:歌手,专辑,编码类型等),用于描述媒体文件.通常称这些数据为元数据(Metadata:data that provides information a ...
- js实现3D切换效果
今天分享一个3d翻转动画效果,js+css3+h5实现,没有框架. 先看下html部分: <div class="box"> <ul> <li> ...