python探索微信朋友信息
一、itchat
itchat是一个开源的微信个人号接口,这一次就用它来来玩玩。
在使用之前,先下载,老规矩通过 pip install itchat 即可安装。
想要获取朋友圈信息,只需要几行代码就可以获取。为减少登录次数,将获取到的信息保存到 json 文件中即可。
itchat.login() # 通过二维码连接登录账号
friend_msg = itchat.get_friends(update=True)[0:] # 获取微信好友信息 # 将微信好友信息保存起来,减少登录的次数
with open('./friend_message.json', 'w', encoding='utf-8') as file:
json.dump(friend_msg, file, ensure_ascii=False) file.close()
二、读取文件获取信息
我们只需要关注里面其中的主要信息,按照需求获取。由于只是玩玩而已,就只单单获取性别和城市信息。
先获取性别信息
def get_gender(message):
sex_dic = {}
sex_list = [] for i in range(1, len(message)):
sex = message[i]['Sex']
if sex == 1:
sex_dic['Male'] = sex_dic.get('Male', 0) + 1
sex_list.append("男")
elif sex == 2:
sex_dic['Female'] = sex_dic.get('Female', 0) + 1
sex_list.append("女")
else:
sex_dic['Unknown'] = sex_dic.get('Unknown', 0) + 1
sex_list.append("Unknown") return sex_dic, sex_list
再获取城市信息
def get_city(message):
city_list = [] for i in range(1, len(message)):
city = message[i]['City']
if city == '':
city_list.append(None)
else:
city_list.append(city) return city_list
三、可视化
将性别绘制成饼状图,城市分布绘制成柱状图。具体绘制的代码就不上了,详情请前往 GitHub
with open("./friend_message.json", 'r', encoding='utf-8') as file:
f_msg = json.load(file)
file.close()
sex_dic, sex_list = getData.get_gender(f_msg)
city_list = getData.get_city(f_msg)
# 将三个属性组成 DataFrame
data = pd.DataFrame({'gender': sex_list, 'city': city_list})
# 获取城市前十的数量
city_dict = data['city'].value_counts()[:15].to_dict()
# 绘制性别环状图
draw_pie(sex_dic)
# 绘制城市柱状图
draw_bar(city_dict)
四、总结

说实话,这里面的男生绝对大部分是在大学认识的,毕竟理工科学校可不是闹着玩儿的;还有这 6.58% 不明性别的人不知道怎么设置的,为什么我没办法不设置,还是说......
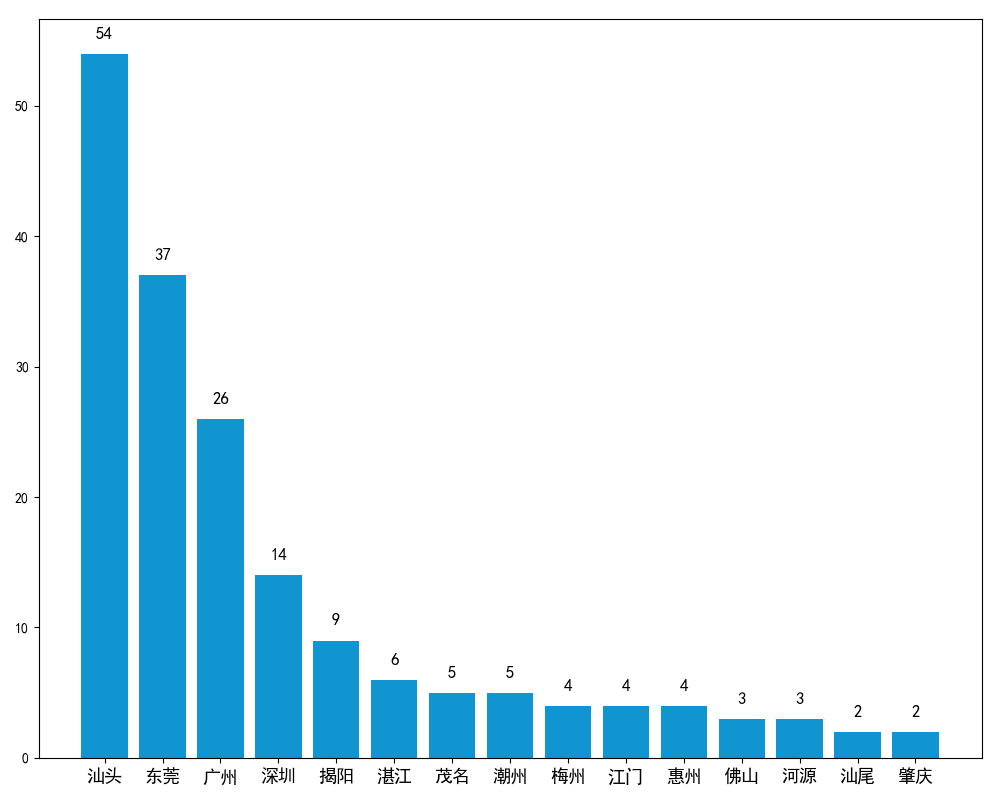
作为一个在东莞上学的广东汕头人,这样的分布确实是在意料之中。毕竟汕头是我生活了那么久的地方,在东莞也快度过三个年头了,不知不觉要大四了,最近的压力已经逐渐增加了,无力吐槽。
这只是玩玩而已,如果你有什么脑洞或者想要挖掘更多个人好友信息,可以使用 itchat 接着玩。
python探索微信朋友信息的更多相关文章
- 如何利用Python网络爬虫抓取微信朋友圈的动态(上)
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门.不过不要慌 ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- python爬虫24 | 搞事情了,用 Appium 爬取你的微信朋友圈。
昨天小帅b看到一些事情不顺眼 有人偷换概念 忍不住就写了一篇反讽 996 的 看不下去了,我支持996,年轻人就该996! 没想到有些人看不懂 这就算了 还来骂我 早些时候关注我的小伙伴应该知道我第一 ...
- Py:数据挖掘之对个人微信朋友圈好友的性别、区域、昵称、签名信息进行情感分析——Jason niu
#Py:数据挖掘之对微信朋友圈好友的性别.区域.昵称.签名信息进行情感分析——Jason niu import os import re import csv import time import j ...
- Python 实现获取微信好友信息
最近用闲余时间看了点python,在网上冲浪时发现有不少获取微信好友信息的博客,对此比较感兴趣,于是自己敲了敲顺便记录下来. 一.使用 wxpy 模块库获取好友男比例信息和城市分布. # -*- co ...
- 域名在微信朋友圈内分享需要ICP备案 杜绝不良信息传播
就在刚刚,腾讯微信团队发布公告表示域名在朋友圈内分享需要ICP备案,杜绝打击不良互联网信息的传播.公告称根据互联网管理相关规定,即日起在微信朋友圈内分享的域名,请在2014年12月31日前完成ICP备 ...
- python itchat 爬取微信好友信息
原文链接:https://mp.weixin.qq.com/s/4EXgR4GkriTnAzVxluJxmg 「itchat」一个开源的微信个人接口,今天我们就用itchat爬取微信好友信息,无图言虚 ...
- python flask获取微信用户信息报404,nginx问题
在学习flask与微信公众号时问题,发现测试自动回复/wechat8008时正常,而测试获取微信用户信息/wechat8008/index时出现404.查询资料后收发是nginx配置问题. 在loca ...
- python实现微信接口(itchat)
python实现微信接口(itchat) 安装 sudo pip install itchat 登录 itchat.auto_login() 这种方法将会通过微信扫描二维码登录,但是这种登录的方式确实 ...
随机推荐
- LoadRunner中的90%响应时间
LoadRunner中的90%响应时间是什么意思?这个值在进行性能分析时有什么作用? 为什么要有90%用户响应时间? 这个跟超女.舞林大会等比赛那样在比赛后都要去掉一个最高分一个最低分在取平均值有点类 ...
- css优先级之important
css优先级之important
- Selenium+Java(六)Selenium 强制等待、显式等待、隐实等待
前言 在实际测试过程中,由于网速或性能方面的原因,打开相应的网页后或在网页上做了相应的操作,网页上的元素可能不会马上加载出来,这个时候需要在定位元素前等待一下,等元素加载出来后再进行定位,根据实际使用 ...
- selenium处理隐藏元素的方法
<li class="navbar-nav-item "> <a href="#" id="cust"> ...
- scrapy的CrawlSpider类
了解CrawlSpider 踏实爬取一般网站的常用spider,其中定义了一些规则(rule)来提供跟进link的方便机制,也许该spider不适合你的目标网站,但是对于大多数情况是可以使用的.因此, ...
- Linux的用户切换、修改用户的用户名和密码
一.用户切换 "$":普通用户提示符 "#":root用户提示符 1.普通用户到root: 方式一:命令:su然后输入root密码 此种方式只是切换了root ...
- ASP.NET Core 2 preview 1中Program.cs,Startup.cs和CreateDefaultBuilder的探索
Exploring Program.cs, Startup.cs and CreateDefaultBuilder in ASP.NET Core 2 preview 1 ASP.NET Core 2 ...
- 网络ASI
ASIHTTPRequest 基于底层CFNetwork框架,运行效率很高 可惜作者 停止更新,有一些潜在的BUG无人去解决 老项目 ASI + SBJson 只需要用到外面的源文件 ASI还依赖于 ...
- 企业DevOps研发模式下CI/CD实践详解指南
阅读全文大概需要 10分钟. 1. 前言 借着公司今年新组建的中台研发部东风,我作为其中的主要负责人,在研发中心主导推行DevOps研发管理模式转变及质量管理创新建设,本篇文章摘取自今年9月底,笔者在 ...
- k 近邻算法解决字体反爬手段|效果非常好
字体反爬,是一种利用 CSS 特性和浏览器渲染规则实现的反爬虫手段.其高明之处在于,就算借助(Selenium 套件.Puppeteer 和 Splash)等渲染工具也无法拿到真实的文字内容. 这种反 ...