Spring源码分析之-加载IOC容器
本文接上一篇文章 SpringIOC 源码,控制反转前的处理(https://mp.weixin.qq.com/s/9RbVP2ZQVx9-vKngqndW1w) 继续进行下面的分析
首先贴出 Spring bean容器的刷新的核心 11个步骤进行祭拜(一定要让我学会了...阿门)
// 完成IoC容器的创建及初始化工作
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// 1: 刷新前的准备工作。
prepareRefresh();
// 告诉子类刷新内部bean 工厂。
// 2:创建IoC容器(DefaultListableBeanFactory),加载解析XML文件(最终存储到Document对象中)
// 读取Document对象,并完成BeanDefinition的加载和注册工作
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// 3: 对IoC容器进行一些预处理(设置一些公共属性)
prepareBeanFactory(beanFactory);
try {
// 4: 允许在上下文子类中对bean工厂进行后处理。
postProcessBeanFactory(beanFactory);
// 5: 调用BeanFactoryPostProcessor后置处理器对BeanDefinition处理
invokeBeanFactoryPostProcessors(beanFactory);
// 6: 注册BeanPostProcessor后置处理器
registerBeanPostProcessors(beanFactory);
// 7: 初始化一些消息源(比如处理国际化的i18n等消息源)
initMessageSource();
// 8: 初始化应用事件多播器
initApplicationEventMulticaster();
// 9: 初始化一些特殊的bean
onRefresh();
// 10: 注册一些监听器
registerListeners();
// 11: 实例化剩余的单例bean(非懒加载方式)
// 注意事项:Bean的IoC、DI和AOP都是发生在此步骤
finishBeanFactoryInitialization(beanFactory);
// 12: 完成刷新时,需要发布对应的事件
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// 销毁已经创建的单例避免占用资源
destroyBeans();
// 重置'active' 标签。
cancelRefresh(ex);
// 传播异常给调用者
throw ex;
}
finally {
// 重置Spring核心中的常见内省缓存,因为我们可能不再需要单例bean的元数据了...
resetCommonCaches();
}
}
}
下面来分析上述流程中的第二个步骤: 创建并解析IOC容器
我们开始进入分析,首先会调用到 AbstractApplicationContext 中的 obtainFreshBeanFactory 方法,此方法会进行IOC容器的刷新并取出BeanFactory,代码如下
// 告诉内部子类刷新内部的bean factory
protected ConfigurableListableBeanFactory obtainFreshBeanFactory() {
// 主要是通过该方法完成IoC容器的刷新
// ClassPathXmlApplicationContext.refreshBeanFactory 调用的是 AbstractRefreshApplicationContext
// AnnotationConfigApplicationContext.refreshBeanFactory调用的是GenericApplicationContext
refreshBeanFactory();
ConfigurableListableBeanFactory beanFactory = getBeanFactory();
...
return beanFactory;
}
- 首先第一步,
refreshBeanFactory,刷新Bean工厂,refreshBeanFactory是一个接口,此接口在 AbstractApplicationContext 中进行定义,先看一下这个JavaDoc对这个接口的定义
/**
* 子类必须实现这个方法才能执行实际的配置加载。此方法在任何其他初始化工作开始之前由refresh()方法调用
* 一个子类创建了一个新的 bean factory 并且持有对它的引用,或者返回它拥有的单个BeanFactory实例。
* 在后一种情况下,如果多次刷新上下文,它通常会抛出 IllegalStateException。
*/
protected abstract void refreshBeanFactory() throws BeansException, IllegalStateException;

它有两个实现类,默认的是 AbstractRefreshableApplicationContext 类,它的refreshBeanFactory方法如下
@Override
protected final void refreshBeanFactory() throws BeansException {
// 如果之前有IoC容器,则销毁
if (hasBeanFactory()) {
destroyBeans();
closeBeanFactory();
}
try {
// 创建IoC容器,也就是 DefaultListableBeanFactory, 初始化AbstractBeanFactory
// 注册BeanNameAware,BeanClassLoaderAware,BeanFactoryAware, 设置当前BeanFactory
DefaultListableBeanFactory beanFactory = createBeanFactory();
beanFactory.setSerializationId(getId());
// 设置工厂的属性:是否允许BeanDefinition覆盖和是否允许循环依赖
customizeBeanFactory(beanFactory);
// 调用载入BeanDefinition的方法,在当前类中只定义了抽象的loadBeanDefinitions方法,具体的实现调用子类容器
loadBeanDefinitions(beanFactory);
synchronized (this.beanFactoryMonitor) {
this.beanFactory = beanFactory;
}
}
catch (IOException ex) {
throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex);
}
}
如果之前有IOC容器的话,就进行销毁,并且关闭容器。适用于第二次调用ClassPathXmlApplicationContext("配置文件"),由于是第一次加载配置文件,还未创建BeanFactory,所以hasBeanFactory()返回false。
下面这一步就是创建IOC容器,也就是DefaultListableBeanFactory
// 为上下文创建一个内部工厂,默认的实现创建了一个内部的DefaultListableBeanFactory.getInternalParentBeanFactory(),
// 在子类中被重写,例如自定义DefaultListableBeanFactory的设置。
protected DefaultListableBeanFactory createBeanFactory() {
return new DefaultListableBeanFactory(getInternalParentBeanFactory());
}
上述方法传递的是一个getInternalParentBeanFactory()方法,我们先来看一下这个方法:
protected BeanFactory getInternalParentBeanFactory() {
return (getParent() instanceof ConfigurableApplicationContext) ?
((ConfigurableApplicationContext) getParent()).getBeanFactory() : getParent();
}
getParent()这个方法会返回父类上下文,如果没有(父类)的话,返回null(也就表明这个上下文是继承树的根节点。)这句代码的意思也就是说如果它实现了 ConfigurableApplicationContext,则返回父类上下文的BeanFactory,如果没有的话,就返回父上下文本身。因为没有设置过父节点上下文,所以此时的getInternalParentBeanFactory()方法返回为null。
下一步返回一个DefaultListableBeanFactory,首先来看一下DefaultListableBeanFactory的继承体系
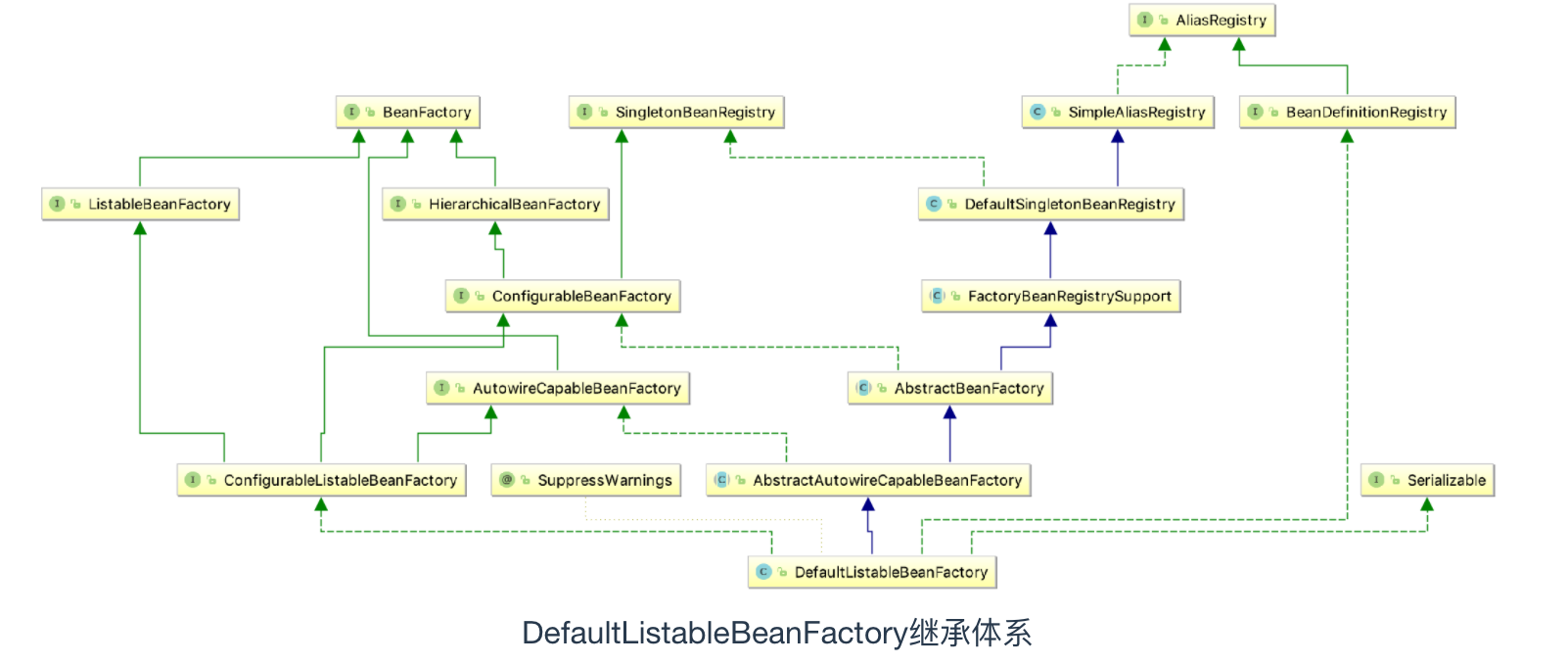
它的调用流程如下:
- 在
AbstractRefreshableApplicationContext类中返回一个DefaultListableBeanFactory的构造函数 DefaultListableBeanFactory构造函数中调用AbstractAutowireCapableBeanFactory的构造函数AbstractAutowireCapableBeanFactory带参数的构造函数会调用AbstractAutowireCapableBeanFactory无参数的构造函数,并注册了BeanNameAware、BeanFactoryAware、BeanClassLoaderAware接口。并设置setParentBeanFactory(parentBeanFactory) 为null(parentBeanFactory就是上面getInternalParentBeanFactory()方法的返回值);
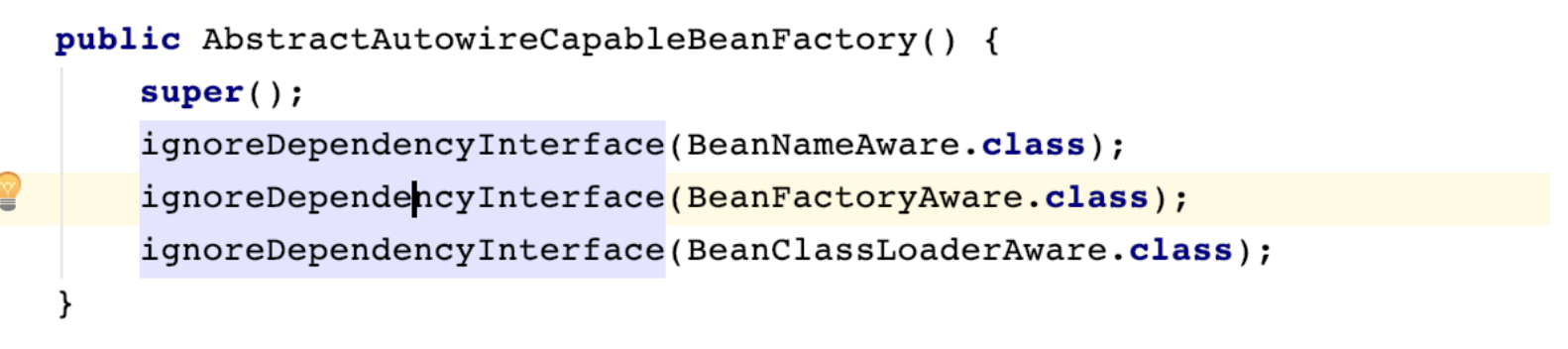
AbstractAutowireCapableBeanFactory会调用父类AbstractBeanFactory无参构造方法并初始化。
此时的DefaultListableBeanFactory会带上一系列的初始化字段。Bean工厂说的也就是DefaultListableBeanFactory
- 在createBeanFactory()之后,会给ClassPathXmlApplicationContext设置全局唯一Id
beanFactory.setSerializationId(getId());
- 第三步,设置
DefaultListableBeanFactory的属性,是否允许重写Bean的定义信息和是否允许循环依赖。没有设置,默认为null
/*
* 通过上下文自定义内部bean工厂。 尝试调用每一个refresh 方法。
* 默认实现应用此上下文setAllowBeanDefinitionOverriding 是否允许Bean定义重写
* 和 setAllowCircularReferences 是否允许循环依赖设置。
* 如果特殊情况,可以在子类中重写以任何自定义DefaultListableBeanFactory 设置。
*/
protected void customizeBeanFactory(DefaultListableBeanFactory beanFactory) {
if (this.allowBeanDefinitionOverriding != null) {
beanFactory.setAllowBeanDefinitionOverriding(this.allowBeanDefinitionOverriding);
}
if (this.allowCircularReferences != null) {
beanFactory.setAllowCircularReferences(this.allowCircularReferences);
}
}
- 最关键的一步,加载Bean的定义信息。所有关于Bean Definitions都会在这一步的这个方法进行解析。调用载入BeanDefinition的方法,在当前类中只定义了抽象的
loadBeanDefinitions方法,具体的实现调用子类容器AbstractXmlApplicationContext中的loadBeanDefinitions方法,具体代码如下
// 通过XmlBeanDefinitionReader 加载bean 定义信息。
@Override
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
// 创建一个BeanDefinition阅读器,通过阅读XML文件,真正完成BeanDefinition的加载和注册
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
// 配置bean 定义阅读器和上下文资源加载环境。
beanDefinitionReader.setEnvironment(this.getEnvironment());
beanDefinitionReader.setResourceLoader(this);
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
// 允许子类提供自定义初始化的reader,然后继续加载bean定义信息。
initBeanDefinitionReader(beanDefinitionReader);
// 委托给BeanDefinition阅读器去加载BeanDefinition
loadBeanDefinitions(beanDefinitionReader);
}
- 首先来看第一步,创建XmlBeanDefinitionReader并进行BeanDefinition的加载和注册。初始化XmlBeanDefinitionReader(beanFactory)构造方法,然后调用AbstractBeanDefinitionReader(BeanDefinitionRegistry registry)的构造方法,因为
DefaultListableBeanFactory实现了BeanDefinitionRegistry接口,所以就把DefaultListableBeanFactory当作一个BeanDefinitionRegistry传递进去。下面看代码
/* 通过bean 工厂创建一个新的 AbstractBeanDefinitionReader。
如果传入的bean 工厂不仅实现了BeanDefinitionRegistry 接口还实现了ResourceLoader 接口。
将会使用默认的ResourceLoader。 这是 ApplicationContext 实现的情况。
如果给定一个普通的BeanDefinitionRegistry,则默认的 ResourceLoader 会是PathMatchingResourcePatternResolver
如果传入的bean 工厂实现了 EnvironmentCapable,则此读取器将使用此环境。否则,这个读取器
将会初始化并且使用 StandardEnvironment。 所有ApplicationContext的实现都是 EnvironmentCapable,
然而通常BeanFactory 的实现则不是。
*/
protected AbstractBeanDefinitionReader(BeanDefinitionRegistry registry) {
...
if (this.registry instanceof ResourceLoader) {
this.resourceLoader = (ResourceLoader) this.registry;
}
else {
this.resourceLoader = new PathMatchingResourcePatternResolver();
}
if (this.registry instanceof EnvironmentCapable) {
this.environment = ((EnvironmentCapable) this.registry).getEnvironment();
}
else {
this.environment = new StandardEnvironment();
}
}
上面代码的意思就是,如果BeanDefinitionRegistry实现了ResourceLoader接口,就会强制转换为ResourceLoader,否则,将会new 一个PathMatchingResourcePatternResolver(),如果实现了EnvironmentCapable接口,就直接获取系统环境,否则就直接new一个StandardEnvironment。
- 完成第一步之后,然后配置bean阅读器和上下文资源加载环境,允许子类提供自定义初始化的reader,然后继续加载bean定义信息。这一步希望子类实现自定义的bean加载信息。
- 最后一步进行真正意义上当bean加载,委托给BeanDefinition阅读器去加载BeanDefinition,来看具体的解析过程
// 委托给XmlBeanDefinition阅读器去加载BeanDefinition
// loadBeanDefinitions(beanDefinitionReader); ↓
@Override
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
// 将读入的XML资源进行特殊编码处理
return loadBeanDefinitions(new EncodedResource(resource));
}
// loadBeanDefinitions ↓
// loadBeanDefinitions(resources) 经过一系列的调用最终会调用到下面的代码
// XmlBeanDefinitionReader 部分代码省略
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
...
// 从InputStream中得到XML的解析源
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
// 这里是具体的读取过程
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
// doLoadBeanDefinitions ↓
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
// 通过DOM4J加载解析XML文件,最终形成Document对象
Document doc = doLoadDocument(inputSource, resource);
// 通过对Document对象的操作,完成BeanDefinition的加载和注册工作
return registerBeanDefinitions(doc, resource);
}
// registerBeanDefinitions ↓
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
// 创建BeanDefinitionDocumentReader来解析Document对象,完成BeanDefinition解析
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
// 获得容器中已经注册的BeanDefinition数量
int countBefore = getRegistry().getBeanDefinitionCount();
// 解析过程入口,BeanDefinitionDocumentReader只是个接口,具体的实现过程在DefaultBeanDefinitionDocumentReader完成
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
// 统计新的的BeanDefinition数量
return getRegistry().getBeanDefinitionCount() - countBefore;
}
到这一步仍旧只是创建了各种需要解析的阅读器对象,文档解析对象,解析之前的准备工作,
这里说一下BeanDefinitionDocumentReader 这个接口:
/*
* 每个要解析的文档实例化:实现可以在执行
* registerBeanDefinitions 方法时保存实例变量中的状态
* 例如,为文档中的所有bean定义定义的全局设置。
*/
public interface BeanDefinitionDocumentReader {
/*
* 从 DOM 文档中读取Bean 定义信息并且通过阅读器上下文环境把它们注册进registry中
*/
void registerBeanDefinitions(Document doc, XmlReaderContext readerContext)
throws BeanDefinitionStoreException;
}
它的默认实现类只有一个,就是 DefaultBeanDefinitionDocumentReader ,此类负责做真正的bean 解析工作。
下面registerBeanDefinitions之后的方法会完成真正的bean解析工作:
DefaultBeanDefinitionDocumentReader.java
// 这个实现用来解析 spring-beans 约束
// 打开DOM 文档,初始化默认<beans/>的设置;然后解析其中的bean定义信息。
@Override
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
// 获得Document的根元素<beans>标签
Element root = doc.getDocumentElement();
// 真正实现BeanDefinition解析和注册工作
doRegisterBeanDefinitions(root);
}
// doRegisterBeanDefinitions(root); ↓
protected void doRegisterBeanDefinitions(Element root) {
/*
任何嵌套的<beans>元素都将导致此方法中的递归。 为了正确传播和保留<beans>default-* 属性,跟踪当前的
父委托,可能为null。
创建新的(子)委托,引用父项以进行回退,然后最终将this.delegate重置为其原始(父)引用。 此行为模拟了一堆代理,而实际上并不需要一个代理。
*/
// 这里使用了委托模式,将具体的BeanDefinition解析工作交给了BeanDefinitionParserDelegate去完成
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
// 判断该根标签是否包含http://www.springframework.org/schema/beans默认命名空间
...
// 在解析Bean定义之前,进行自定义的解析,增强解析过程的可扩展性
preProcessXml(root);
// 委托给BeanDefinitionParserDelegate,从Document的根元素开始进行BeanDefinition的解析
parseBeanDefinitions(root, this.delegate);
// 在解析Bean定义之后,进行自定义的解析,增加解析过程的可扩展性
postProcessXml(root);
this.delegate = parent;
}
看到这里已经真心不容易了,需要休息一下吗?怎么说呢,源码这个东西是需要耐住性子并且需要你投入大量精力的,看过一遍没有印象太正常了,并且看源码的前提是没人打扰,需要一个极度安静的环境。
tips: 戴上耳机会好很多
在回到正题之前,我先来问你一个问题,你知道代理模式和委托模式的区别吗?
我是这样理解的
委托模式是自己不做这件事情呢,而是把事情交给别人去做
代理模式是让别人搭把手,而自己是真正做这件事情的主角,因为代理实现类(实现了InvocationHandler 的类)只是个打嘴炮的人。
回到正题,在真正做解析工作的时候,会首先创建一个委托类BeanDefinitionParserDelegate ,那么先来认识一下这个类。
// 用于解析XML bean定义的有状态委托类。 旨在供主解析器和任何扩展使用
public class BeanDefinitionParserDelegate {
// 此方法也就是委托给 BeanDefinitionParserDelegate 去做的事情
protected BeanDefinitionParserDelegate createDelegate(
XmlReaderContext readerContext, Element root, @Nullable BeanDefinitionParserDelegate parentDelegate) {
BeanDefinitionParserDelegate delegate = new BeanDefinitionParserDelegate(readerContext);
delegate.initDefaults(root, parentDelegate);
return delegate;
}
}
它主要完成的事情在initDefaults 方法中,一起看下这个方法
/*
* 初始化默认的 懒加载,自动注入,依赖检查设置, 初始化方法,销毁方法和合并设置。
* 如果未在本地显式设置默认值,则通过回退到给定父级来支持嵌套的“beans”元素用例。
*/
public void initDefaults(Element root, @Nullable BeanDefinitionParserDelegate parent) {
populateDefaults(this.defaults, (parent != null ? parent.defaults : null), root);
this.readerContext.fireDefaultsRegistered(this.defaults);
}
/**
* in case the defaults are not explicitly set locally.
* 使用默认的 lazy-init,autowire,依赖检查设置,init-method,destroy-method 和 合并设置 属性 填充给定的
* DocumentDefaultsDefinition,如果未在本地显式设置默认值,则支持嵌套的'beans'元素用例,返回parentDefaults
*/
protected void populateDefaults(DocumentDefaultsDefinition defaults, @Nullable DocumentDefaultsDefinition parentDefaults, Element root) {
// default-lazy-init
String lazyInit = root.getAttribute(DEFAULT_LAZY_INIT_ATTRIBUTE);
if (DEFAULT_VALUE.equals(lazyInit)) {
// Potentially inherited from outer <beans> sections, otherwise falling back to false.
lazyInit = (parentDefaults != null ? parentDefaults.getLazyInit() : FALSE_VALUE);
}
defaults.setLazyInit(lazyInit);
// 余下的代码和lazyinit 的逻辑相同,也是解析方法注释中的各种属性。 这里碍于篇幅原因暂不贴出了
...
//
defaults.setSource(this.readerContext.extractSource(root));
}
然后方法一直返回到创建委托的入口也就是 BeanDefinitionParserDelegate parent = this.delegate;,然后是 Spring 留给开发人员的两个接口,用于开发人员自己实现
...
// 在解析Bean定义之前,进行自定义的解析,增强解析过程的可扩展性
preProcessXml(root);
// 委托给 BeanDefinitionParserDelegate,从Document的根元素开始进行BeanDefinition的解析
parseBeanDefinitions(root, this.delegate);
// 在解析Bean定义之后,进行自定义的解析,增加解析过程的可扩展性
postProcessXml(root);
我们再来看一下 parseBeanDefinitions(root, this.delegate); 这个方法是交给刚刚创建的 BeanDefinitionParserDelegate 委托用来解析具体的 lazy-init 等属性的标签的
/**
* 解析文档对象的根目录节点: import, alias, bean
*/
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
// 加载的Document对象是否使用了Spring默认的XML命名空间(beans命名空间)
if (delegate.isDefaultNamespace(root)) {
// 获取Document对象根元素的所有子节点(bean标签、import标签、alias标签和其他自定义标签context、aop等)
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
// bean标签、import标签、alias标签,则使用默认解析规则
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
else {//像context标签、aop标签、tx标签,则使用用户自定义的解析规则解析元素节点
delegate.parseCustomElement(ele);
}
}
}
}
else {
// 如果不是默认的命名空间,则使用用户自定义的解析规则解析元素节点
delegate.parseCustomElement(root);
}
}
上述步骤主要分为三步:
- 先判断是否委托类使用Spring默认的XML命名空间(beans命名空间),在判断如果取出来的节点是bean、import、alias的话就使用默认的解析规则
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
// 解析<import>标签
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
// 解析<alias>标签
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
// 解析<bean>标签
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
// 解析内置<bean>标签
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recurse
// 递归调用
doRegisterBeanDefinitions(ele);
}
}
- 如果判断取出来的不是默认节点,则会使用自定义的默认解析规则,context标签,aop标签, tx标签则会默认使用此解析方法
@Nullable
public BeanDefinition parseCustomElement(Element ele) {
// 解析自定义标签
return parseCustomElement(ele, null);
}
@Nullable
public BeanDefinition parseCustomElement(Element ele, @Nullable BeanDefinition containingBd) {
// 获取命名空间URI(就是获取beans标签的xmlns:aop或者xmlns:context属性的值)
String namespaceUri = getNamespaceURI(ele);
if (namespaceUri == null) {
return null;
}
// 根据不同的命名空间URI,去匹配不同的NamespaceHandler(一个命名空间对应一个NamespaceHandler)
// 此处会调用DefaultNamespaceHandlerResolver类的resolve方法
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler == null) {
error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);
return null;
}
// 调用匹配到的NamespaceHandler的解析方法
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
}
- 如果不是使用 beans 的命名空间,也会使用自定义的解析方法进行解析
然后方法解析完成,一直返回到 AbstractApplicationContext 中的 刷新 bean Factory 的方法
protected ConfigurableListableBeanFactory obtainFreshBeanFactory() {
// 主要是通过该方法完成IoC容器的刷新
// ClassPathXmlApplicationContext.refreshBeanFactory 调用的是 AbstractRefreshApplicationContext
// AnnotationConfigApplicationContext.refreshBeanFactory调用的是GenericApplicationContext
refreshBeanFactory();
ConfigurableListableBeanFactory beanFactory = getBeanFactory();
if (logger.isDebugEnabled()) {
logger.debug("Bean factory for " + getDisplayName() + ": " + beanFactory);
}
return beanFactory;
}
这样取出的 Bean 对象就可以进行使用了。
下一篇文章来 解析一下第三个步骤: 对IoC容器进行一些预处理
Spring源码分析之-加载IOC容器的更多相关文章
- Spring源码分析 手写简单IOC容器
Spring的两大特性就是IOC和AOP. IOC Container,控制反转容器,通过读取配置文件或注解,将对象封装成Bean存入IOC容器待用,程序需要时再从容器中取,实现控制权由程序员向程序的 ...
- 精尽Spring Boot源码分析 - 配置加载
该系列文章是笔者在学习 Spring Boot 过程中总结下来的,里面涉及到相关源码,可能对读者不太友好,请结合我的源码注释 Spring Boot 源码分析 GitHub 地址 进行阅读 Sprin ...
- Spring Boot源码分析-配置文件加载原理
在Spring Boot源码分析-启动过程中我们进行了启动源码的分析,大致了解了整个Spring Boot的启动过程,具体细节这里不再赘述,感兴趣的同学可以自行阅读.今天让我们继续阅读源码,了解配置文 ...
- spring源码分析之玩转ioc:bean初始化和依赖注入(一)
最近赶项目,天天加班到十一二点,终于把文档和代码都整完了,接上继续整. 上一篇聊了beanProcess的注册以及对bean的自定义修改和添加,也标志着创建bean的准备工作都做好了,接下来就是开大招 ...
- mybatis源码分析--如何加载配置及初始化
简介 Mybatis 是一个持久层框架,它对 JDBC 进行了高级封装,使我们的代码中不会出现任何的 JDBC 代码,另外,它还通过 xml 或注解的方式将 sql 从 DAO/Repository ...
- Spring源码分析(十九)容器的功能扩展概览
摘要: 本文结合<Spring源码深度解析>来分析Spring 5.0.6版本的源代码.若有描述错误之处,欢迎指正. 经过前面几章的分析,相信大家已经对 Spring 中的容器功能有了简单 ...
- spring源码-bean之加载-2
一.前面说了bean的容器初始化,后面当然是说bean的加载.这里还是不讲解ApplicationContext的bean的加载过程,还是通过最基础的XmlBeanFactory来进行讲解,主要是熟悉 ...
- 第一次源码分析: 图片加载框架Picasso源码分析
使用: Picasso.with(this) .load("http://imgstore.cdn.sogou.com/app/a/100540002/467502.jpg") . ...
- springboot集成mybatis源码分析-启动加载mybatis过程(二)
1.springboot项目最核心的就是自动加载配置,该功能则依赖的是一个注解@SpringBootApplication中的@EnableAutoConfiguration 2.EnableAuto ...
随机推荐
- 使用 Docker 生成 Let’s Encrypt 证书
概念 什么是 Container ? https://www.docker.com/resources/what-container https://www.docker.com/why-docker ...
- TI MSP430工程配置及2019年电赛A题编程示例(使用430 F5529)
配置 第一步:右击工程,选择Options 第二步:在General Options的Target选项卡里选择对应的器件Device,这里是MSP430G2231 第三步:在Debugger里选择FE ...
- [转载]关于ActiveMQ集群
转载于 http://blog.csdn.net/nimmy/article/details/6247289 近日因工作关系,在研究JMS,使用ActiveMQ作为提供者,考虑到消息的重要,拟采用Ac ...
- 开园第一篇---有关tensorflow加载不同模型的问题
写在前面 今天刚刚开通博客,主要想法跟之前某位博主说的一样,希望通过博客园把每天努力的点滴记录下来,也算一种坚持的动力.我是小白一枚,有啥问题欢迎各位大神指教,鞠躬~~ 换了新工作,目前手头是OCR项 ...
- 心里想的VS嘴上说的
心里想的VS嘴上说的 背景:昨天开会,在招行总行那边,今天检讨下自己不会说话,真是太难了我! 一.昨日重现 现在回想起当时的场景觉得自己也真是搞笑,这都没死,太难了我.昨天下午在五楼开会,这也是我入职 ...
- Liunx之nginx代理
一.代理 正向代理 正向代理,也就是传说中的代理,他的工作原理就像一个跳板(VPN),简单的说: 我是一个用户,我访问不了某网站,但是我能访问一个代理服务器,这个代理服务器呢,他能访问那个我不能访问的 ...
- 使用flash2print 代替 printflash 将office文档 转为flash 在页面中播放
前一些日子公司需求把用户上传的一些word等 文档 能像百度文库那样 显示给用户, 但是如果是直接显示office文档的话就需要 些控件的支持 .非常的不友好,所以 一开始我就想能不能转成pdf 来 ...
- TinyMCE使用
1.文本&文本字体颜色 与word类似不赘述 2.字体加粗&划线 与word类似不赘述 选中后 ctrl + B 加粗快捷键 选中后 ctrl + I 斜体快捷键 选中后 c ...
- Debian下Hadoop 3.12 集群搭建
Debian系统配置 我这里在Vmware里面虚拟4个Debian系统,一个master,三个solver.hostname分别是master.solver1.solver2.solver3.对了,下 ...
- python 11 迭代器
目录 1. 第一类对象的特点 2. 格式化 3.迭代器 3.1 可迭代对象 3.2 迭代器 4. 递归 1. 第一类对象的特点 #1. 函数名可以当作值被赋值给变量 def func(): print ...