NIO中Buffer的重要属性关系解析
Buffer 是java NIO中三个核心概念之一 缓存, 在java的实现体系中Buffer作为顶级抽象类存在
简单说,Buffer在做什么?
我们知道,在java IO中体系中, 因为InputStream和OutputStream是抽象类,而java又不可以多重继承,于是任何一个流要么只读,要么只写.而无法完成同时读写的工作
于是: Buffer来了
NIO中,对数据的读写,都是在Buffer中完成的,也就是说,同一个buffer我们可以先读后写, 它底层维护着一个数组,这个数组被三个重要的属性控制,有机的工作结合,使buffer可读可写;
此外,Buffer是线程不安全的,并发访问需要同步
三个重要属性:
- capacity: 容量
- Buffer中元素的个数
- 永远不能为负数
- 永远不会变化
- limit: 限制
- 实际上它是Buffer所维护的那个数组中的一个下标
- limit是第一个不能被读,或者第一个不能被写的元素的index
- limit永远不会是负数
- 永远不会超过capacity
- Position: 定位
- 指数组中下一个将要被读或者将要被写的元素的索引
图解,Buffer是如何维护的数组
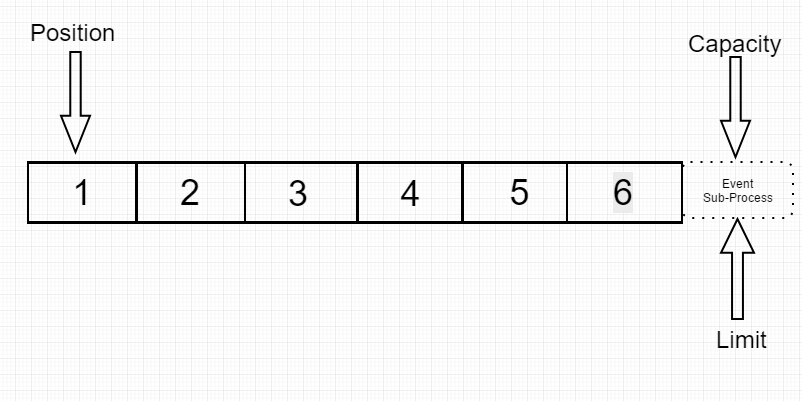
一开始: 我们初始化它的大小为6 初始状态,Capacity和Limit都在最后一个不能被读或者不能被写的位置上
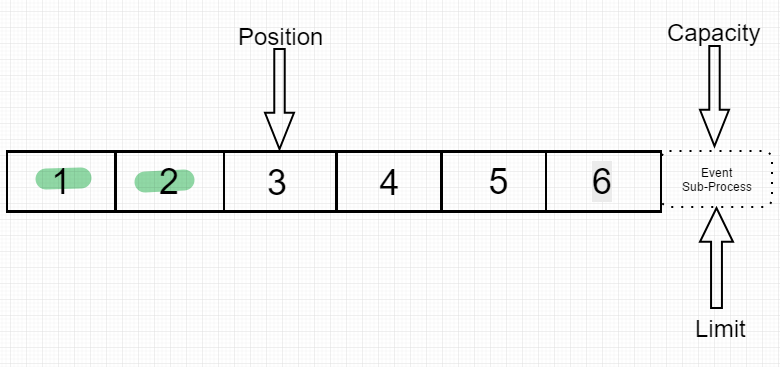
接着我们读入两个数据.position跳转到下一个将被读的index
接下来,准备写把buffer中的数据写出去两个, 于是我们需要反转数值
buffer.flip();
反转的逻辑:
limit=position;
position=0;
于是从0写 ,写到哪个位置? 写到limi前
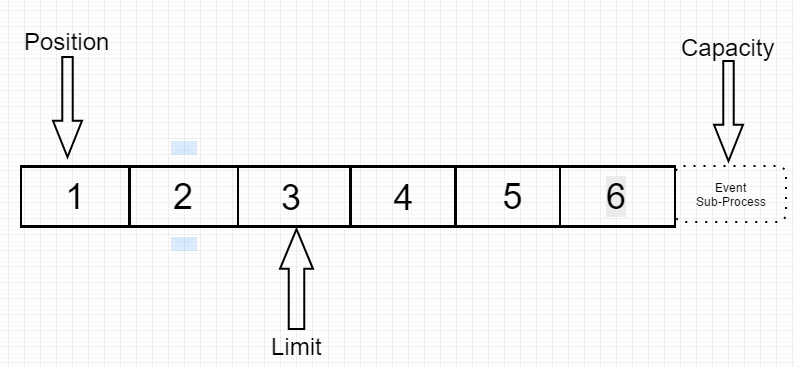
写完毕后:如下图:

现在可以看到,pisition == limit
如果再想读入新的数据,同样需要反转数据flip()
但是此时,limit仍然是刚刚position的所在的最后的位置
Buffer架构体系:
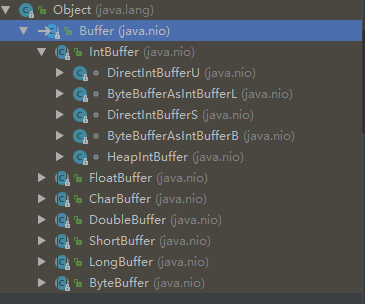
模拟Buffer实现一个相同的继承体系,进一步了解成员变量在他们之间是怎么维护的
首先,和Buufer等级一样的顶级父类
public abstract class ParentSupper {
private int position;
private int capacity;
ParentSupper(int position,int capacity){
this.position=position;
this.capacity=capacity;
System.out.println("ParentSupper 的构造方法执行了... ");
}
final int nextPutIndex(){
if (position>=capacity){
throw new RuntimeException("索引异常");
}
return position++;
}
int i=0;
final int nextGetIndex(){
if (i >=position){
throw new RuntimeException("索引异常");
}
return i++;
}
}
接着是它的实现类, 和IntBuffer 等级一样
public abstract class Parent extends ParentSupper {
// 抽象类中的成员变量,必须放在构造方法中
final int[] arr1;
int tag;
// todo 执行父类的构造方法
Parent(int a, int[] arr1) {
// 调用父类的构造函数
super(0,a);
this.arr1 = arr1;
this.tag = a;
}
// 构造器
public static Parent allocate(int capacity) {
return new Child(capacity);
}
// 抽象的方法
public abstract int get();
public abstract void put(int number);
}
作为抽象类的它,有自己的抽象方法, get put, 同时它里面维护着 核心数组, final不可变类型的, 抽象类中的变量不能单独存在,必须依附构造函数,于是我们添加它的构造函数
再就是它的实现类:
class Child extends Parent {
public Child(int capacity) {
super(capacity,new int[capacity]);
}
// todo 重写父类的构造方法
@Override
public int get() {
return arr1[nextGetIndex()];
}
@Override
public void put(int num) {
arr1[nextPutIndex()]=num;
}
}
注意,Child的类上并没有public 修饰,意味着他只是可以包内访问
下面测试:
public class text {
public static void main(String[] args) {
// 初始化
Parent allocate = Parent.allocate(9);
for (int i=0;i<9;i++){
allocate.put(i);
}
for (int i=0;i<=8;i++){
System.out.println( allocate.get());
}
}
}
运行流程是怎样的呢?
当我们使用
Parent.allocate(10);创建对象时,底层确实 new Child(int i), 同时把传递给Child, 而在Child()相应的构造函数中,接着调用的是spuer()方法,同时把10 传递给super也就是Parent,同时实例化了Parent的 数组, 在Supper的构造方法中,把0,和传递进来的10 传递给了SuperParent, 让他维护两个值
思考, 各个部分之间的作用
- Buffer : 维护着当前数据的 position limit 和 capaciy值,这是数组的下标值,但是Buffer却没有数组
- Buffer的直接实现类,如IntBuffer , 依然是抽象类, 它有数组作为缓存, 数组的维护它交给了它的父类Buffer, 针对数组的初始化,读写,他交给了自己的实现类
数组的维护工作是一样的,所以抽象成Buffer
- HeapIntBuffer: 它继承了IntBuffer, 同时把它的父类的数组进行了实例化,并且重写了父类的get put方法
不同类型的数据,具体的读写是有区别的,所有抽象成不同的子类
在回去看,allocate(); 显然我们得到的是最外层的子类对象,这也就意味着他是最强的那个对象,它拥有父类的数据,并且这个数据的读写由它的爷爷替自己把关,这就是Buffer的设计模式
Buffer中常见的API
Buffer的所有子类全部定义了两套关于get() 和 put()的方法
- Relative: 相对的读写, 相对的读写都是从当前的position的位置开始,每次的get/put都会是position的位置发生改变
- Avsolute: 绝对的读写 , 用户指定索引, 从指定的索引里面get,或者直接往指定的索引里面put
clear()
将buffer置为初始状态的值,实际上就是让新读入buffer中的值,覆盖掉原来的值
position=0;
limit=capacity;
flip()
反转buffer
limit = position;
positon=0;
isReadOnly()
判断是否是只读的buffer
分片Buffer
//限制前后 准备切片
byteBuffer.position(2);
byteBuffer.limit(6);
// 切片
ByteBuffer slice = byteBuffer.slice();
新得到的buffer和原buffer共享内存空间
类型化的Buffer
ByteBuffer allocate = ByteBuffer.allocate(123);
allocate.putInt(1);
allocate.putChar('你');
allocate.putDouble(123.123123);
allocate.putShort((short) 2);
allocate.putLong(3L);
allocate.flip();
System.out.println(allocate.getInt());
System.out.println(allocate.getChar());
System.out.println(allocate.getDouble());
System.out.println(allocate.getShort());
System.out.println(allocate.getLong());
类型化 的put和get 但是呢!!! 怎么存进去的 就得怎么取出来 , 否者会出现乱码
NIO拷贝文件
// 获取输入流
FileInputStream fileInputStream = new FileInputStream("123.txt");
FileOutputStream fileOutputStream = new FileOutputStream("output123.txt");
// 获取一个通道,关联上数据
FileChannel channel = fileInputStream.getChannel();
FileChannel outputStreamChannel = fileOutputStream.getChannel();
ByteBuffer byteBuffer = ByteBuffer.allocate(128);
while (true) {
// todo 每次读满一次缓存后, 重新初始化buffer
byteBuffer.clear();
// 将数据读入 缓存
int read = channel.read(byteBuffer);
System.out.println("read == "+read);
if (read == -1) {
break;
}
// 反转 limit=position position=0
byteBuffer.flip();
// 通过channel 往输出流中写入缓存的数据
outputStreamChannel.write(byteBuffer);
}
// 释放资源
fileInputStream.close();
fileInputStream.close();
System.out.println("结束...");
}
每次循环一开始,都要重置buffer,否则第一轮读取结束之后, limit==position 从而channel里面新的数据读不进去,而 limit==position也不会引发异常,随后的flip()将buffer反转,position为0, 使得当前buffer中的数据被循环写到文件中,成为死循环
NIO中Buffer的重要属性关系解析的更多相关文章
- 《精通并发与Netty》学习笔记(15 - 详解NIO中Buffer之position,limit,capacity)
一.前言熟悉NIO的人想必一定不会陌生buffer中position,limit,capacity这三个属性吧,之前在学习的时候遇到一个问题:就是当你先往缓冲区写入一部分数据,然后调用flip()方法 ...
- python中变量在内存中的存储与地址关系解析、浅度/深度copy、值传递、引用传递
---恢复内容开始--- 1.变量.地址 变量的实现方式有:引用语义.值语义 python语言中变量的实现方式就是引用语义,在变量里面保存的是值(对象)的引用(值所在处内存空间的地址).采用这种方式, ...
- NIO编程中buffer对象的理解以及API的使用
概念讲解,转自https://www.cnblogs.com/lxzh/archive/2013/05/10/3071680.html ,将的非常好! Buffer 类是 java.nio 的构造基 ...
- Java NIO之Buffer(缓冲区)
Java NIO中的缓存区(Buffer)用于和通道(Channel)进行交互.数据是从通道读入缓冲区,从缓冲区写入到通道中的. 缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存.这 ...
- 微软BI 之SSAS 系列 - 维度的优化,灌木丛属性关系,以及自然层次结构与非自然层次结构的概念
维度的优化 在 SSAS 开发设计过程中,维度的优化非常重要,因为它在 SSAS 分析服务性能调优的过程中往往能起到一个非常重要的作用. 一般来说,对于 Cube 的性能优化第一步可能考虑的就是查看维 ...
- Java NIO中的缓冲区Buffer(一)缓冲区基础
什么是缓冲区(Buffer) 定义 简单地说就是一块存储区域,哈哈哈,可能太简单了,或者可以换种说法,从代码的角度来讲(可以查看JDK中Buffer.ByteBuffer.DoubleBuffer等的 ...
- Java I/O(3):NIO中的Buffer
您好,我是湘王,这是我的博客园,欢迎您来,欢迎您再来- 之前在调用Channel的代码中,使用了一个名叫ByteBuffer类,它是Buffer的子类.这个叫Buffer的类是专门用来解决高速设备与低 ...
- Java NIO中的Buffer 详解
Java NIO中的Buffer用于和NIO通道进行交互.如你所知,数据是从通道读入缓冲区,从缓冲区写入到通道中的.缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存.这块内存被包装成NIO ...
- java NIO中的buffer和channel
缓冲区(Buffer):一,在 Java NIO 中负责数据的存取.缓冲区就是数组.用于存储不同数据类型的数据 根据数据类型不同(boolean 除外),提供了相应类型的缓冲区:ByteBufferC ...
随机推荐
- Vue使用Viser
最近产品经理发现antV的图表非常漂亮,想在项目里使用,看了下文档antV适用于Vue的分支叫Viser,Viser的官方文档写的有点随意,在此给出Vue中使用Viser的方法如下: 1.安装Vise ...
- Asp.Net MVC中Aplayer.js音乐播放器的使用
1.前言: Aplater.js是一款可爱.漂亮的Js音乐播放器,以前就了解过也弄过一些,现在就用mp3的格式来在.Net里面开发.管网 https://aplayer.js.org/ 2.入手: 在 ...
- NodeJS2-4环境&调试----global变量
global全局对象,希望把全局访问到的对象,属性和方法等挂到global对象上,除了用户自定义的方法外,global本身默认带着一些常用的属性和方法的 CommonJS Buffer.process ...
- 微服务架构 SpringBoot(一)
spring Boot:官网地址 https://spring.io/ 由来: 随着spring组件功能的强大,配置文件也越来越复杂繁琐,背离了spring公司的简洁快速开发原理,2015年就推出Sp ...
- 利用sklearn对多分类的每个类别进行指标评价
今天晚上,笔者接到客户的一个需要,那就是:对多分类结果的每个类别进行指标评价,也就是需要输出每个类型的精确率(precision),召回率(recall)以及F1值(F1-score). 对于 ...
- ASP.NET Core on K8S深入学习(10)K8S包管理器Helm
本篇已加入<.NET Core on K8S学习实践系列文章索引>,可以点击查看更多容器化技术相关系列文章. 一.关于Helm 1.1 为何需要Helm? 虽然K8S能够很好地组织和编排容 ...
- spingboot 2.1.3 与 elasticsearch7 兼容问题
pom 加入 elasticsearch7 的依赖, <dependency> <groupId>org.elasticsearch</groupId> < ...
- Ant Design 错误记录
Ant Design 错误记录 一: 标签页Tabs 1:设置activeKey或defaultActiveKey,绑定默认值不起作用: => 需要同时设置activeKey和defaul ...
- selectors模块的设计亮点
事件类型标志的选择 在selectors模块中的开头直接定义了事件类型的标志数字,选用的是(1 << 0)就是1代替EVENT_READ读操作:使用(1 << 1)就是2代替E ...
- 【Java并发系列】--Java内存模型
Java内存模型 1 基本概念 程序:代码,完成某一个任务的代码序列(静态概念) 进程:程序在某些数据上的一次运行(动态) 线程:一个进程有一个或多个线程组成(占有资源的独立单元) 2 JVM与线程 ...