爬虫scrapy组件 请求传参,post请求,中间件
post请求
在scrapy组件使用post请求需要调用
def start_requests(self):
进行传参再回到
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse)
进行post请求 其中FormRequest()为post 请求方式
import scrapy class PostSpider(scrapy.Spider):
name = 'post'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://fanyi.baidu.com/sug'] def start_requests(self):
data = {
'kw':'dog'
}
for url in self.start_urls:
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse)
#scrapy.FormRequest() 进行post请求
def parse(self, response):
print(response.text)
请求传参
scrapy请求传参 主核心的就是
meta={'item':item}
是一个字典结构,用来存储item 等
通过回调函数的返回url进行访问
import scrapy
from moviePro.items import MovieproItem class MovieSpider(scrapy.Spider):
name = 'movie'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.4567tv.tv/frim/index1.html']
#解析详情页中的数据
def parse_detail(self,response):
#response.meta返回接收到的meta字典
item = response.meta['item']
actor = response.xpath('/html/body/div[1]/div/div/div/div[2]/p[3]/a/text()').extract_first()
item['actor'] = actor yield item def parse(self, response):
li_list = response.xpath('//li[@class="col-md-6 col-sm-4 col-xs-3"]')
for li in li_list:
item = MovieproItem()
name = li.xpath('./div/a/@title').extract_first()
detail_url = 'https://www.4567tv.tv'+li.xpath('./div/a/@href').extract_first()
item['name'] = name
#meta参数:请求传参.meta字典就会传递给回调函数的response参数
yield scrapy.Request(url=detail_url,callback=self.parse_detail,meta={'item':item}) #这里url 值定的start_urls 调用直接访问
注意:这里存储的字段一定要与items.py 创建的一致,就是以items.py的字段为主
items.py
import scrapy class MovieproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
actor = scrapy.Field()
pipelines.py
import pymysql class MovieproPipeline(object):
conn = None
cursor = None def open_spider(self,spider):
print("开始爬虫")
self.conn = pymysql.Connect(host='127.0.0.1',port=3306, user='root', password="",db='movie',charset='utf8') def process_item(self, item, spider):
self.cursor = self.conn.cursor()
try:
self.cursor.execute('insert into av values("%s","%s")'%(item['name'],item['actor']))
self.conn.commit()
except Exception as e:
self.conn.rollback() def close_spider(self,spider):
print('结束爬虫')
self.cursor.close()
self.conn.close()
在执行时可以 省去--nolog,在setting中配置LOG_LEVEL="ERROR"
也可以定义写入文件 ,在setting中配置LOG_FILE = "./log.txt"
五大核心组件
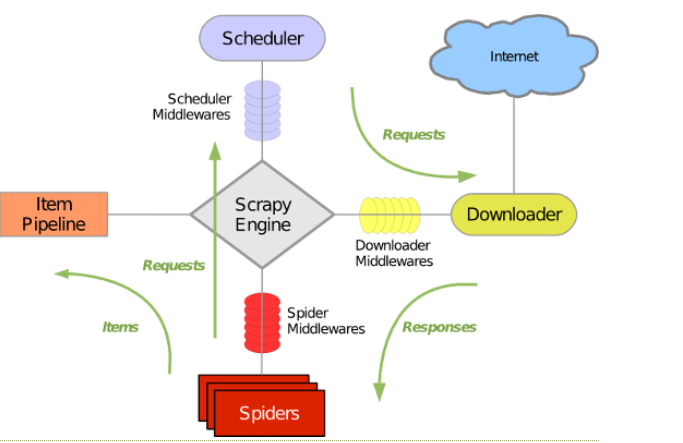
其中dowmloader 最为重要,它分为三大重要的方法
(1)
def process_request(self, request, spider):
return None
需要有返回NONE 同django的中间建,表示在访问来之前进行操作
用来范文时 ,进行user_agent 的替换, request.headers['User-Agent'] = random.choice([ ...]) (2)
def process_response(self, request, response, spider): 需要有返回respons给 spider 进行数据 处理
用作selenium 模拟访问时,倘若放在spider访问,一条数据就需要生成一个bro,所以添加到这里,一次就好
它将获取的数据
return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding='utf-8',request=request)
返回给spider 进行数据解析
return response (3)
def process_exception(self, request, exception, spider):
pass 指进行报错使用的情况
用作代理吃进行请求代理ip 的设置 request.meta['proxy'] = random.choice([]) 使用
import random class MiddleproDownloaderMiddleware(object):
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# 可被选用的代理IP
PROXY_http = [
'153.180.102.104:80',
'195.208.131.189:56055',
]
PROXY_https = [
'120.83.49.90:9000',
'95.189.112.214:35508',
]
#拦截所有未发生异常的请求
def process_request(self, request, spider): #使用UA池进行请求的UA伪装
print('this is process_request')
request.headers['User-Agent'] = random.choice(self.user_agent_list)
print(request.headers['User-Agent']) return None
#拦截所有的响应
def process_response(self, request, response, spider): return response
#拦截到产生异常的请求
def process_exception(self, request, exception, spider): print('this is process_exception!')
if request.url.split(':')[0] == 'http':
request.meta['proxy'] = random.choice(self.PROXY_http)
else:
request.meta['proxy'] = random.choice(self.PROXY_https)
selenium的中间件使用
注意:使用中间件需要打开中间件的封印 (p56-58)
DOWNLOADER_MIDDLEWARES = {
'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543,
}
通过实例化bro对象,在请求结束后访问download中间件的 def response(self):
通过获取的数据
return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding='utf-8',request=request)
返回给spider
import scrapy
from selenium import webdriver '''
在scrapy中使用selenium的编码流程:
1.在spider的构造方法中创建一个浏览器对象(作为当前spider的一个属性)
2.重写spider的一个方法closed(self,spider),在该方法中执行浏览器关闭的操作
3.在下载中间件的process_response方法中,通过spider参数获取浏览器对象
4.在中间件的process_response中定制基于浏览器自动化的操作代码(获取动态加载出来的页面源码数据)
5.实例化一个响应对象,且将page_source返回的页面源码封装到该对象中
6.返回该新的响应对象
''' class WangyiSpider(scrapy.Spider):
name = 'wangyi'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://war.163.com/']
def __init__(self):
self.bro = webdriver.Chrome(executable_path=r'C:\Users\Administrator\Desktop\爬虫+数据\day_03_爬虫\chromedriver.exe')
def parse(self, response):
div_list = response.xpath('//div[@class="data_row news_article clearfix "]')
for div in div_list:
title = div.xpath('.//div[@class="news_title"]/h3/a/text()').extract_first()
print(title)
def closed(self,spider):
print('关闭浏览器对象!')
self.bro.quit()
def process_response(self, request, response, spider):
def process_response(self, request, response, spider):
# Called with the response returned from the downloader. # Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
print('即将返回一个新的响应对象!!!')
#如何获取动态加载出来的数据
bro = spider.bro
bro.get(url=request.url)
sleep(3)
#包含了动态加载出来的新闻数据
page_text = bro.page_source
sleep(3)
return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding='utf-8',request=request)
爬虫scrapy组件 请求传参,post请求,中间件的更多相关文章
- 爬虫开发10.scrapy框架之日志等级和请求传参
今日概要 日志等级 请求传参 今日详情 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息. - 日志 ...
- python爬虫---scrapy框架爬取图片,scrapy手动发送请求,发送post请求,提升爬取效率,请求传参(meta),五大核心组件,中间件
# settings 配置 UA USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, l ...
- scrapy模块之分页处理,post请求,cookies处理,请求传参
一.scrapy分页处理 1.分页处理 如上篇博客,初步使用了scrapy框架了,但是只能爬取一页,或者手动的把要爬取的网址手动添加到start_url中,太麻烦接下来介绍该如何去处理分页,手动发起分 ...
- 13.scrapy框架的日志等级和请求传参
今日概要 日志等级 请求传参 如何提高scrapy的爬取效率 今日详情 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是s ...
- scrapy框架的日志等级和请求传参
日志等级 请求传参 如何提高scrapy的爬取效率 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息 ...
- scrapy框架之日志等级和请求传参-cookie-代理
一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息. - 日志信息的种类: ERROR : 一般错误 ...
- 爬虫--Scrapy-参数等级和请求传参
日志等级 日志等级(种类): ERROR:错误 WARNING:警告 INFO:一般信息 DEBUG:调试信息(默认) 指定输入某一中日志信息: settings:LOG_LEVEL = ‘ERROR ...
- Scrapy的日志等级和请求传参
日志等级 日志信息: 使用命令:scrapy crawl 爬虫文件 运行程序时,在终端输出的就是日志信息: 日志信息的种类: ERROR:一般错误: WARNING:警告: INFO:一般的信息: ...
- scrapy框架post请求发送,五大核心组件,日志等级,请求传参
一.post请求发送 - 问题:爬虫文件的代码中,我们从来没有手动的对start_urls列表中存储的起始url进行过请求的发送,但是起始url的确是进行了请求的发送,那这是如何实现的呢? - 解答: ...
随机推荐
- cookie,webstorage的理解
在前两天的开发时,遇到一个问题,需要将一个网页在预加载时,优先出一个弹出框,但是再次加载时不希望它出现,在经过一段时间的搜索和尝试之后,发现了大多使用的两种方式:生成cookie和webStorage ...
- add to explorer context menu需不需要勾选
添加到鼠标右键菜单,添加以后,可以直接右键文件,直接选择这个软件打开选择的文件,建议勾选
- kettle教程---通过配置表格配置实现数据的批量增量更新(实用)
本文接上篇文章,上面文章讲的是,通过配置文件的全量更新,现在说下增量更新 如上图所示,涉及到1个转换和1个作业. 1-表增量同步(转换) 可以通过读取同步表参数这个excel表格文件,获取表名称和同步 ...
- NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver ...
显卡驱动找不到解决方案:亲测有效 step1:sudo apt-get install dkms step2: sudo dkms install -m nvidia -v 390.129 nvi ...
- react+dva 全局model中异步获取数据state在组件中取不到值
先上结论,不是取不到,是写法有问题. 全文分4部分,1是问题描述,2是一开始的解决想法(错误做法),3是问题产生原因的思考,4是正常解决方法.只想看结论直接跳4 1.问题描述 接触react dva一 ...
- js如何手写一个new
手写new 看一下正常使用new function Dog(name){ this.name = name } Dog.prototype.sayName = function(){ console. ...
- SQL查询--内连接、外连接、自连接查询
先创建2个表:学生表和教师表 1.内连接: 在每个表中找出符合条件的共有记录.[x inner join y on...] 第一种写法:只用where SELECT t.TEACHER_NAME, ...
- 使用adb安装apk到手机
[ADB]Android debug bridge.Android手机实际是基于Linux系统的.通过USB线将android手机与电脑连起来,在电脑上dos命令行中敲adb shell命令,可以登录 ...
- 【Sublime】Sublime 常用插件
1.sublime设置默认浏览器及打开网页的快捷键设置插件 名称:SideBarEnhancements 地址:https://github.com/titoBouzout/SideBarEnhanc ...
- 拎壶学python3-----(1)输出与字符转换
一.输入自己的名字打印 二.数字和字符串是不能相加的如下 怎么解决上边的问题呢? 如果是相加我们要把字符串转成数字类型如下 如果不想让他相加可以写成这样如下: ok,关于转换就先讲到这里