全文检索 java Lucene
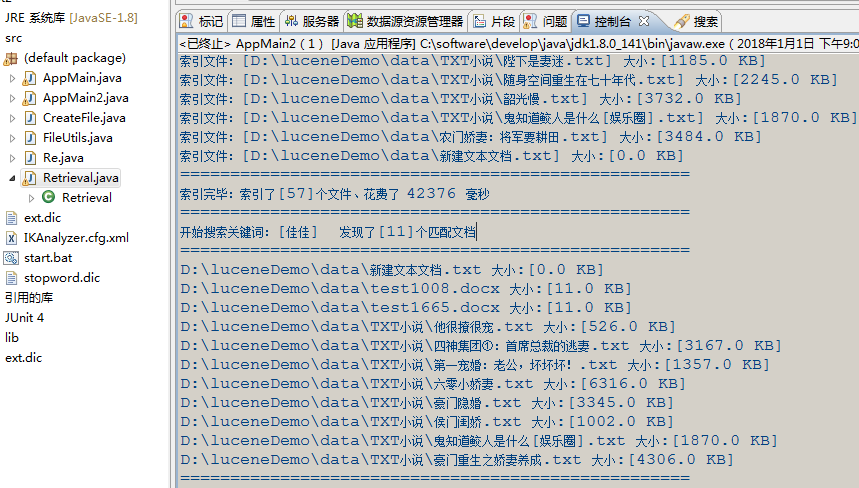
索引文件:[D:\luceneDemo\data\TXT小说\陛下是妻迷.txt] 大小:[1185.0 KB]
索引文件:[D:\luceneDemo\data\TXT小说\随身空间重生在七十年代.txt] 大小:[2245.0 KB]
索引文件:[D:\luceneDemo\data\TXT小说\韶光慢.txt] 大小:[3732.0 KB]
索引文件:[D:\luceneDemo\data\TXT小说\鬼知道鲛人是什么[娱乐圈].txt] 大小:[1870.0 KB]
索引文件:[D:\luceneDemo\data\农门娇妻:将军要耕田.txt] 大小:[3484.0 KB]
索引文件:[D:\luceneDemo\data\新建文本文档.txt] 大小:[0.0 KB]
===================================================
索引完毕:索引了[57]个文件、花费了 42376 毫秒
===================================================
开始搜索关键词:[佳佳] 发现了[11]个匹配文档
===================================================
D:\luceneDemo\data\新建文本文档.txt 大小:[0.0 KB]
D:\luceneDemo\data\test1008.docx 大小:[11.0 KB]
D:\luceneDemo\data\test1665.docx 大小:[11.0 KB]
D:\luceneDemo\data\TXT小说\他很撩很宠.txt 大小:[526.0 KB]
D:\luceneDemo\data\TXT小说\四神集团①:首席总裁的逃妻.txt 大小:[3167.0 KB]
D:\luceneDemo\data\TXT小说\第一宠婚:老公,坏坏坏!.txt 大小:[1357.0 KB]
D:\luceneDemo\data\TXT小说\六零小娇妻.txt 大小:[6316.0 KB]
D:\luceneDemo\data\TXT小说\豪门隐婚.txt 大小:[3345.0 KB]
D:\luceneDemo\data\TXT小说\侯门闺娇.txt 大小:[1002.0 KB]
D:\luceneDemo\data\TXT小说\鬼知道鲛人是什么[娱乐圈].txt 大小:[1870.0 KB]
D:\luceneDemo\data\TXT小说\豪门重生之娇妻养成.txt 大小:[4306.0 KB]
===================================================
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Reader;
import java.io.StringReader;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopScoreDocCollector;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.poi.EmptyFileException;
import org.apache.poi.POIXMLDocument;
import org.apache.poi.POIXMLTextExtractor;
import org.apache.poi.hwpf.extractor.WordExtractor;
import org.apache.poi.openxml4j.exceptions.OpenXML4JException;
import org.apache.poi.xwpf.extractor.XWPFWordExtractor;
import org.apache.xmlbeans.XmlException;
import org.wltea.analyzer.lucene.IKAnalyzer; public class Retrieval { IndexWriter writer = null;
Directory dir = null;
Analyzer analyzer = null;
IndexWriterConfig config = null; // 文件目录
// 查询字符串
public List<String> RunRetrieval(String fileDir, String querystr) { // 添加到ext.dic
// appendMethodB(EXT_DIC_PATH,querystr); // 搜索结果
List<String> resFile = new ArrayList<String>(); String uuid = UUID.randomUUID().toString();
// 索引目录
String indexDir = fileDir + "\\..\\temp_" + uuid;
try {
long start = System.currentTimeMillis(); // 智能中文分析器
analyzer = new IKAnalyzer();
// 中文分词器
// analyzer=new SmartChineseAnalyzer();
// 实例化分析器
// analyzer = new StandardAnalyzer(); // 实例化IndexWriterConfig
config = new IndexWriterConfig(analyzer);
// 得到索引所在目录的路径
dir = FSDirectory.open(Paths.get(indexDir));
// 实例化IndexWriter
writer = new IndexWriter(dir, config);
// 定义文件数组,循环得出要加索引的文件
File[] files = new File(fileDir).listFiles();
if (null == files) {
System.out.println("没有文件");
return null;
}
for (File file : files) {
recursionDir(file);
} writer.commit(); // 返回索引了多少个文件,有几个文件返回几个
long end = System.currentTimeMillis();
System.out.println("===================================================");
System.out.println("索引完毕:索引了[" + writer.numDocs() + "]个文件、花费了 " + (end - start) + " 毫秒");
System.out.println("==================================================="); int hitsPerPage = 100; IndexReader reader = DirectoryReader.open(dir);
IndexSearcher searcher = new IndexSearcher(reader);
Term term = new Term("contents", querystr);
// Query q = new QueryParser("contents", analyzer).parse(querystr);
TermQuery query = new TermQuery(term); TopScoreDocCollector collector = TopScoreDocCollector.create(hitsPerPage);
System.out.print("开始搜索关键词:[" + querystr + "] ");
searcher.search(query, collector);
ScoreDoc[] hits = collector.topDocs().scoreDocs; System.out.println("发现了[" + hits.length + "]个匹配文档");
System.out.println("===================================================");
for (int i = 0; i < hits.length; ++i) {
int docId = hits[i].doc;
Document doc = searcher.doc(docId); // System.out.println(doc.get("contents"));
// System.out.print(doc.get("FileName"));
System.out.print(doc.get("fullPath") + " 大小:[" + doc.get("size") + " KB]");
resFile.add(doc.get("fullPath")); // displayTokens(analyzer, txt2String(new File(doc.get("fullPath"))), querystr);
System.out.println();
// System.out.print(" "+doc.get("size"));
}
reader.close();
System.out.println("===================================================");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (null != writer) {
// 删除索引
writer.deleteAll();
writer.close();
// 删除索引文件(不是程序运行所必须的)
deleteDir(new File(indexDir));
}
} catch (IOException e) {
e.printStackTrace();
}
}
return resFile;
} private void writeToIndex(File file) { WordExtractor extractorForDoc = null;
POIXMLTextExtractor extractorForDocx = null; try { if (file.length() == 0) {
return;
} double fileLength = file.length() / 1000; // 从这开始,对每个文件加索引
System.out.println("索引文件:[" + file.getCanonicalPath() + "] 大小:[" + fileLength + " KB]");
// 索引要一行一行的找,,在数据中为文档,所以要得到所有行,即文档
// 实例化Document
Document document = new Document();
String prefix = file.getName().substring(file.getName().lastIndexOf(".") + 1); // 如果是Word
if (prefix.equals("docx")) {
extractorForDocx = new XWPFWordExtractor(POIXMLDocument.openPackage(file.getAbsolutePath()));
Reader contents = new StringReader(extractorForDocx.getText());
// add():把设置好的索引加到Document里,以便在确定被索引文档。
document.add(new TextField("contents", contents));
} else if (prefix.equals("doc")) {
FileInputStream inputStream = new FileInputStream(file.getAbsolutePath());
extractorForDoc = new WordExtractor(inputStream);
Reader contents = new StringReader(extractorForDoc.getText());
// add():把设置好的索引加到Document里,以便在确定被索引文档。
document.add(new TextField("contents", contents));
} else if (prefix.equals("txt")) {
// add():把设置好的索引加到Document里,以便在确定被索引文档。
document.add(new TextField("contents", new FileReader(file)));
}
// Field.Store.YES:把文件名存索引文件里,为NO就说明不需要加到索引文件里去
document.add(new StringField("FileName", file.getName(), Field.Store.YES));
// 把完整路径存在索引文件里
document.add(new StringField("fullPath", file.getCanonicalPath(), Field.Store.YES)); // document.add(new TextField("size", file.getTotalSpace() + " bytes",
// Field.Store.YES));
document.add(new TextField("size", String.valueOf(fileLength), Field.Store.YES)); // 开始写入,就把文档写进了索引文件里去了;
writer.addDocument(document); } catch (EmptyFileException e) { } catch (IOException e) {
e.printStackTrace();
} catch (XmlException e) {
e.printStackTrace();
} catch (OpenXML4JException e) {
e.printStackTrace();
} finally {
try {
if (null != extractorForDoc) {
extractorForDoc.close();
}
if (null != extractorForDocx) {
extractorForDocx.close();
}
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
} @SuppressWarnings("unused")
private void recursionDir(File f) {
if (f != null) {
if (f.isDirectory()) {
File[] fileArray = f.listFiles();
if (fileArray != null) {
for (int i = 0; i < fileArray.length; i++) {
// 递归调用
recursionDir(fileArray[i]);
}
}
} else {
writeToIndex(f);
}
}
} private void displayTokens(Analyzer analyzer, String text, String keyword) throws Exception { // System.out.println("当前使用的分词器:" + analyzer.getClass().getName()); // 分词流,即将对象分词后所得的Token在内存中以流的方式存在,也说是说如果在取得Token必须从TokenStream中获取,而分词对象可以是文档文本,也可以是查询文本。
TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(text));
// 表示token的首字母和尾字母在原文本中的位置。比如I'm的位置信息就是(0,3),需要注意的是startOffset与endOffset的差值并不一定就是termText.length(),
// 因为可能term已经用stemmer或者其他过滤器处理过;
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
// 这个有点特殊,它表示tokenStream中的当前token与前一个token在实际的原文本中相隔的词语数量,用于短语查询。比如:
// 在tokenStream中[2:a]的前一个token是[1:I'm ],
// 它们在原文本中相隔的词语数是1,则token="a"的PositionIncrementAttribute值为1;
PositionIncrementAttribute positionIncrementAttribute = tokenStream
.addAttribute(PositionIncrementAttribute.class); CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class); // 表示token词典类别信息,默认为“Word”,比如I'm就属于<APOSTROPHE>,有撇号的类型;
TypeAttribute typeAttribute = tokenStream.addAttribute(TypeAttribute.class);
tokenStream.reset(); int position = 0;
while (tokenStream.incrementToken()) {
int increment = positionIncrementAttribute.getPositionIncrement();
if (increment > 0) {
position = position + increment;
}
int startOffset = offsetAttribute.startOffset();
int endOffset = offsetAttribute.endOffset();
String term = charTermAttribute.toString();
// System.out.println("第" + position + "个分词:TYPE:" + typeAttribute.type() + "、["
// + term + "]" + "、位置:["
// + startOffset + "-->" + endOffset + "]");
if (term.equals(keyword)) {
System.out.println("第" + position + "个分词:TYPE:" + typeAttribute.type() + "、[" + term + "]" + "、位置:["
+ startOffset + "-->" + endOffset + "]");
}
}
tokenStream.close();
} /**
* 读取txt文件的内容
*
* @param file
* 想要读取的文件对象
* @return 返回文件内容
*/
public static String txt2String(File file) {
StringBuilder result = new StringBuilder();
try {
BufferedReader br = new BufferedReader(new FileReader(file));// 构造一个BufferedReader类来读取文件
String s = null;
while ((s = br.readLine()) != null) {// 使用readLine方法,一次读一行
result.append(System.lineSeparator() + s);
}
br.close();
} catch (Exception e) {
e.printStackTrace();
}
return result.toString();
} /**
* 递归删除目录下的所有文件及子目录下所有文件
*
* @param dir
* 将要删除的文件目录
*
*/
private static boolean deleteDir(File dir) {
if (dir.isDirectory()) {
String[] children = dir.list();
for (int i = 0; i < children.length; i++) {
boolean success = deleteDir(new File(dir, children[i]));
if (!success) {
return false;
}
}
}
// 目录此时为空,可以删除
return dir.delete();
} /**
* B方法追加文件:使用FileWriter
*/
public static void appendMethodB(String fileName, String content) {
try {
// 打开一个写文件器,构造函数中的第二个参数true表示以追加形式写文件
FileWriter writer = new FileWriter(fileName, true);
// FileWriter writer = new FileWriter(fileName, false);
writer.write("\r\n");
// content=new String(content.getBytes("ISO-8859-1"),"UTF-8");
System.out.println("写入新词汇到ext.dic:[" + content + "]");
writer.write(content);
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
全文检索 java Lucene的更多相关文章
- JAVAEE——Lucene基础:什么是全文检索、Lucene实现全文检索的流程、配置开发环境、索引库创建与管理
1. 学习计划 第一天:Lucene的基础知识 1.案例分析:什么是全文检索,如何实现全文检索 2.Lucene实现全文检索的流程 a) 创建索引 b) 查询索引 3.配置开发环境 4.创建索引库 5 ...
- 全文检索框架---Lucene
一.什么是全文检索 1.数据分类 我们生活中的数据总体分为两种:结构化数据和非结构化数据. 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等. 非结构化数据:指不定长或无固定格式 ...
- 全文检索(Lucene&Solr)
全文检索(Lucene&Solr) 1)什么是全文检索?为什么需要全文检索? 结构化数据(mysql等)方便查询,而非结构化数据(如多篇文章)是难以查询到自己需要的,所以要使用全文检索. 全文 ...
- 【手把手教你全文检索】Lucene索引的【增、删、改、查】
前言 搞检索的,应该多少都会了解Lucene一些,它开源而且简单上手,官方API足够编写些小DEMO.并且根据倒排索引,实现快速检索.本文就简单的实现增量添加索引,删除索引,通过关键字查询,以及更新索 ...
- Lucene 01 - 初步认识全文检索和Lucene
目录 1 搜索简介 1.1 搜索实现方案 1.2 数据查询方法 1.2.1 顺序扫描法 1.2.2 倒排索引法(反向索引) 1.3 搜索技术应用场景 2 Lucene简介 2.1 Lucene是什么 ...
- 大型运输行业实战_day15_1_全文检索之Lucene
1.引入 全文检索简介: 非结构化数据又一种叫法叫全文数据.从全文数据(文本)中进行检索就叫全文检索. 2.数据库搜索的弊端 案例 : select * from product whe ...
- 全文检索技术---Lucene
1 Lucene介绍 1.1 什么是Lucene Lucene是apache下的一个开源的全文检索引擎工具包.它为软件开发人员提供一个简单易用的工具包(类库),以方便的在目标系统中实现 ...
- 全文检索以及Lucene的应用
全文检索 一.什么是全文检索? 就是在检索数据,数据的分类: 在计算机当中,比如说存在磁盘的文本文档,HTML页面,Word文档等等...... 1.结构化数据 格式固定,长度固定,数据类型固定等等, ...
- Java Lucene入门
1.lucene版本:7.2.1 pom文件: <?xml version="1.0" encoding="UTF-8"?> <project ...
随机推荐
- python基础--函数的命名空间and作用域
函数对象:函数是第一类对象,函数名指向的值是可以被当作参数进行传递的 1.函数名可以被传递 2.函数名可以被当作参数传递给其它函数 3.函数名可以被当作函数的返回值 4.函数名可以被当作容器类型的参数 ...
- java根据list中的对象某个属性排序
1. Collections.sort public class Test { public static void main(String[] args) throws Exception { Ci ...
- Hibernate_添加联系人练习
分析: 联系人与客户是多对一,一个客户(公司)有多个联系人,在多的这一方,即LinkMan, 1.LinkMan.java中除自身属性外,还需要 2.在hbm.xml文件中,加上 意思是建立一个外键用 ...
- 当移动数据分析需求遇到Quick BI
我叫洞幺,是一名大型婚恋网站“我在这等你”的资深老员工,虽然在公司五六年,还在一线搬砖.“我在这等你”成立15年,目前积累注册用户高达2亿多,在我们网站成功牵手的用户达2千多万.目前我们的公司在CEO ...
- jquery 调用asp.net后台代码
1.需要引用对应的命名空间 System.Web.Services 2.后台方法: 必须是static 约束 必须添加[WebMethod()] 属性 示例: <script type=&q ...
- Django 用 userena 做用户注册验证登陆
django-admin startproject userena2 cd userena2python manage.py startapp accounts vim userena2/settin ...
- js 常用事件总结
无论web端还是手机端,用户的交互总伴随着事件监听 下面是我总结的一些常用到的事件 1.监听标签内容变化 非input元素 $(dom).bind('DOMNodeInserted',function ...
- Vue源码探究-虚拟DOM的渲染
Vue源码探究-虚拟DOM的渲染 在虚拟节点的实现一篇中,除了知道了 VNode 类的实现之外,还简要地整理了一下DOM渲染的路径.在这一篇中,主要来分析一下两条路径的具体实现代码. 按照创建 Vue ...
- Linux的概述与分类
1.Linux的概述 Linux是基于Unix的开源免费的操作系统,由于系统的稳定性和安全性几乎成为程序代码运行的最佳系统环境.Linux是由Linus Torvalds(林纳斯·托瓦兹)起初开发的, ...
- 怎么用PHP+sqlite3验证登录用户名和密码
Session:在计算机中,尤其是在网络应用中,称为“会话控制”.Session 对象存储特定用户会话所需的属性及配置信息.这样,当用户在应用程序的 Web 页之间跳转时,存储在 Session 对象 ...