Python-线程(2)
GIL全局解释器锁
在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。>有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL
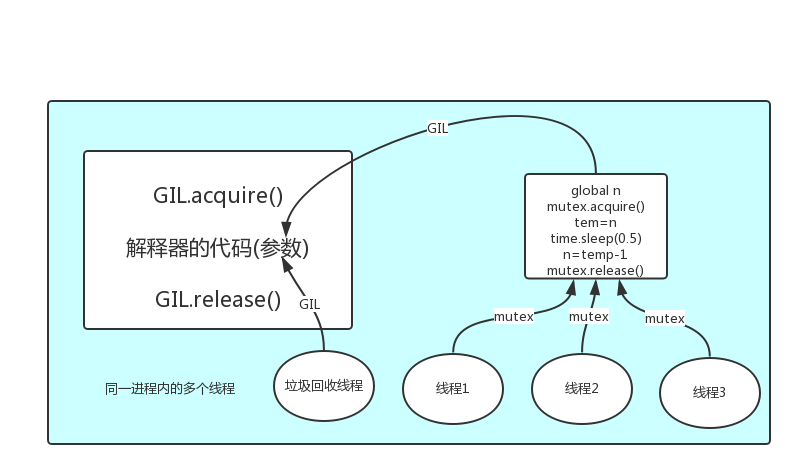
GIL 本质上就是一把互斥锁,将并发运行编程串行,以此来控制同一时间内共享的数据只能被一个任务锁修改,进而保证数据的安全
可以肯定的是,保护数据的安全,就应该加锁
'''
验证全局解释器锁
'''
import time
from threading import Thread,current_thread
n = 100
def task():
global n
n2 = n
# 全局解释器锁碰到 IO阻塞就切换cpu执行并解锁
time.sleep(1)
n = n2 - 1
print(n,current_thread().name)
for line in range(100):
t = Thread(target=task)
t.start()
GIL 与 Lock
为什么有了解释器的锁来保证同一时间只能有一个线程来执行,为什么还需要有线程的lock锁?
首先,我们要达成共识,锁的目的就是为了保护数据,同一时间只能有一个线程来修改共享的数据
然后,我们就可以得到结论:保护不同的数据我们需要加不同的锁
那么 GIL 与Lock是两把锁,保护的数据不一样,GIL是解释器里的,保护的是解释器级别的数据,比如垃圾回收的数据,Lock是保护用户自己开发的应用程序的数据,很明显GIL自己不负责这件事,只能用户自定义加锁处理,即Lock
当我们在没有IO的程序里面(纯计算)不加锁不会存在锁的错乱问题,因为GIL限制了同一时刻只能让一个线程执行,所以不用加锁
当我们在IO密集的程序里面,不加锁会导致数据安全问题,因为程序遇到IO cpu会切断使用权,让另一个线程执行,那么这时候另一个线程拿到的数据还是之前的一份,不是最新的,导致所有线程修改数据不是正确的,引起数据安全问题,所以这个时候加上线程锁来保证这个数据安全
多进程 VS 多线程
站在两个角度看问题
计算密集型:
单核:
开启进程:消耗资源大
开启线程:消耗资源小于进程
多核:
开启进程:并行执行,效率高
开启线程:并发执行,效率低
IO密集型:
单核:
开启进程:消耗资源大
开启线程:消耗资源小于进程
多核:
开启进程:并行执行,效率小于多线程,因为遇到IO会立即切换CPU的执行权限
开启线程:并发执行,效率高于多进程
# coding=utf-8
from multiprocessing import Process
from threading import Thread
import os
import time
# 计算密集型
def work1():
num = 0
for i in range(40000000):
num += 1
# IO密集型
def work2():
time.sleep(1)
if __name__ == '__main__':
# 测试计算密集型
start_time = time.time()
ls = []
for i in range(10):
# 测试多进程
p = Process(target=work1) # 程序执行时间为7.479427814483643
# 测试多线程
# p = Thread(target=work1) # 程序执行时间为28.56563377380371
ls.append(p)
p.start()
for l in ls:
l.join()
end_time = time.time()
print(f"程序执行时间为{end_time - start_time}")
# 测试计算密集型结论:
# 在计算较小数据时候使用多线程效率高
# 在计算较大数据时候使用多进程效率高
# 测试IO密集型
start_time = time.time()
ls = []
for i in range(10):
# 测试多进程
# p = Process(target=work2) # 程序执行时间为2.749157190322876
# 测试多线程
p = Thread(target=work2) # 程序执行时间为1.0130579471588135
ls.append(p)
p.start()
for l in ls:
l.join()
end_time = time.time()
print(f"程序执行时间为{end_time - start_time}")
# 测试IO密集型结论:
# 使用多线程效率要比使用多进程效率高
计算密集型情况下:
在计算较小数据时候使用多线程效率高
在计算较大数据时候使用多进程效率高
IO密集型情况下:
使用多线程效率要比使用多进程效率高
高效执行程序:
使用多线程和多进程
这里打个比方:
一个工人相当于cpu,工厂原材料就相当于线程。
此时计算相当于工人在干活,I/O阻塞相当于为工人干活提供所需原材料的过程,工人干活的过程中如果没有原材料了,则工人干活的过程需要停止,直到等待原材料的到来。
如果你的工厂干的大多数任务都要有准备原材料的过程(I/O密集型),那么你有再多的工人,意义也不大,还不如一个人,在等材料的过程中让工人去干别的活,
反过来讲,如果你的工厂原材料都齐全,那当然是工人越多,效率越高
结论:
对计算机来说:CPU越多越好,但是对于IO来说,再多的CPU也没用
对于程序来说:随着CPU的增多执行效率肯定会有所提高(不管提高多大,总会有所提高)
假设我们有四个任务需要处理,处理方式肯定是要玩出并发的效果,解决方案可以是:
方案一:开启四个进程
方案二:一个进程下,开启四个线程
结果:
单核:
若四个任务是计算密集型,方案一增加了创建进程时间,方案二远小于方案一,方案二胜
若四个任务是I/O密集型,方案一也增加了创建进程时间,且进程切换速度还不如线程,所以方 案二又胜
多核:
若四个任务是计算密集型,多核 开多个进程一起计算是并行计算,在线程中执行用不上多核, 那么方案一效率高,方案一胜
若四个任务是I/O密集型,再多的核也解决不了I/O问题,方案二胜
结论:
现在的计算机基本上都是多核,python对于计算密集型的程序来说,开多线程的效率并不能带来多 大性能的提升,甚至还不如串行,但是对于I/O密集型的程序来说,开多线程效率就明显提升
多线程用于I/O密集型:例如Socket、爬虫、Web
多进程用于计算密集型,如金融分析,数据分析
死锁现象
# coding=utf-8
from threading import Lock,Thread,current_thread
import time
mutex_a = Lock()
mutex_b = Lock()
class MyThread(Thread):
# 线程执行任务
def run(self):
self.work1()
self.work2()
def work1(self):
mutex_a.acquire()
print(f"{self.name} 抢到了锁a")
mutex_b.acquire()
print(f"{self.name} 抢到了锁b")
mutex_b.release()
print(f"{self.name} 释放了锁b")
mutex_a.release()
print(f"{self.name} 释放了锁a")
def work2(self):
mutex_b.acquire()
print(f"{self.name} 抢到了锁b")
# 模拟IO操作
time.sleep(1)
mutex_a.acquire()
print(f"{self.name} 抢到了锁a")
mutex_a.release()
print(f"{self.name} 释放了锁a")
mutex_b.release()
print(f"{self.name} 释放了锁b")
for i in range(2):
t = MyThread()
t.start()
Thread-1 抢到了锁a
Thread-1 抢到了锁b
Thread-1 释放了锁b
Thread-1 释放了锁a
Thread-1 抢到了锁b
Thread-2 抢到了锁a
.....卡主了
开启两个线程之后,每个线程会抢cpu执行,
第一个线程抢到了,执行work1,抢到锁a、b,释放a、b
再回来执行work2,抢到锁b,碰到有IO阻塞,切换线程执行
到第二个线程,可以抢到锁a,但是锁还在第一个线程手里拿着
锁b么有被释放,线程二拿不到锁b,于是卡主了
递归锁
解决死锁问题,需要用到递归锁
RLock:只有一把钥匙,可以提供多个线程去使用,每次使用会计数+1,只有计数为0 的时候 才能真正释放让另一个线程使用
可以理解为遇到IO操作之后,如果身上有这个递归锁,必须先把这个递归锁解开之后然后你再去做其他事情。
# coding=utf-8
from threading import Lock,Thread,current_thread,RLock
import time
# mutex_a = Lock()
# mutex_b = Lock()
mutex_a = mutex_b = RLock()
class MyThread(Thread):
# 线程执行任务
def run(self):
self.work1()
self.work2()
def work1(self):
mutex_a.acquire()
print(f"{self.name} 抢到了锁a")
mutex_b.acquire()
print(f"{self.name} 抢到了锁b")
mutex_b.release()
print(f"{self.name} 释放了锁b")
mutex_a.release()
print(f"{self.name} 释放了锁a")
def work2(self):
mutex_b.acquire()
print(f"{self.name} 抢到了锁b")
# 模拟IO操作
time.sleep(1)
mutex_a.acquire()
print(f"{self.name} 抢到了锁a")
mutex_a.release()
print(f"{self.name} 释放了锁a")
mutex_b.release()
print(f"{self.name} 释放了锁b")
for i in range(2):
t = MyThread()
t.start()
Thread-1 抢到了锁a
Thread-1 抢到了锁b
Thread-1 释放了锁b
Thread-1 释放了锁a
Thread-1 抢到了锁b
Thread-1 抢到了锁a
Thread-1 释放了锁a
Thread-1 释放了锁b
Thread-2 抢到了锁a
Thread-2 抢到了锁b
Thread-2 释放了锁b
Thread-2 释放了锁a
Thread-2 抢到了锁b
Thread-2 抢到了锁a
Thread-2 释放了锁a
Thread-2 释放了锁b
信号量
Semaphore
互斥锁:只有一把锁,只能一个人去使用
信号量:可以自定义锁的数量,提供多个人使用
# coding=utf-8
from threading import Semaphore,Lock
from threading import current_thread
from threading import Thread
import time
# 信号量:提供5个锁
sm = Semaphore(5)
# 互斥锁:提供一个锁
mutex = Lock()
def task():
sm.acquire()
print(f"子线程{current_thread().name}")
time.sleep(1)
sm.release()
if __name__ == '__main__':
for i in range(10):
t = Thread(target=task)
t.start()
# 五个五个执行
子线程Thread-1
子线程Thread-2
子线程Thread-3
子线程Thread-4
子线程Thread-5
子线程Thread-6
子线程Thread-7
子线程Thread-8
子线程Thread-9
子线程Thread-10
线程队列
FIFO:先进先出
LIFO:后进先出
优先级队列:根据参数中的数字字母排序,排在前面的优先级越高,优先取出
# coding=utf-8
import queue
from multiprocessing import Queue
# FIFO队列:先进先出
q = queue.Queue()
q.put(4)
q.put(2)
q.put(3)
print(q.get())
print(q.get())
# 4
# 2
# LIFO队列:后进先出
q = queue.LifoQueue()
q.put(1)
q.put(2)
q.put(3)
print(q.get())
print(q.get())
# 3
# 2
# 优先级队列
q = queue.PriorityQueue()
q.put(3)
q.put(2)
q.put(11)
print(q.get())
# 2
Python-线程(2)的更多相关文章
- python——线程与多线程进阶
之前我们已经学会如何在代码块中创建新的线程去执行我们要同步执行的多个任务,但是线程的世界远不止如此.接下来,我们要介绍的是整个threading模块.threading基于Java的线程模型设计.锁( ...
- python——线程与多线程基础
我们之前已经初步了解了进程.线程与协程的概念,现在就来看看python的线程.下面说的都是一个进程里的故事了,暂时忘记进程和协程,先来看一个进程中的线程和多线程.这篇博客将要讲一些单线程与多线程的基础 ...
- [python] 线程简介
参考:http://www.cnblogs.com/aylin/p/5601969.html 我是搬运工,特别感谢张岩林老师! python 线程与进程简介 进程与线程的历史 我们都知道计算机是由硬件 ...
- PYTHON线程知识再研习A
前段时间看完LINUX的线程,同步,信息号之类的知识之后,再在理解PYTHON线程感觉又不一样了. 作一些测试吧. thread:模块提供了基本的线程和锁的支持 threading:提供了更高级别,功 ...
- Python 线程(threading) 进程(multiprocessing)
*:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !important; } /* ...
- Python线程:线程的调度-守护线程
Python线程:线程的调度-守护线程 守护线程与普通线程写法上基本么啥区别,调用线程对象的方法setDaemon(true),则可以将其设置为守护线程.在python中建议使用的是thread. ...
- python 线程(一)理论部分
Python线程 进程有很多优点,它提供了多道编程,可以提高计算机CPU的利用率.既然进程这么优秀,为什么还要线程呢?其实,仔细观察就会发现进程还是有很多缺陷的. 主要体现在一下几个方面: 进程只能在 ...
- python线程同步原语--源码阅读
前面两篇文章,写了python线程同步原语的基本应用.下面这篇文章主要是通过阅读源码来了解这几个类的内部原理和是怎么协同一起工作来实现python多线程的. 相关文章链接:python同步原语--线程 ...
- Python学习——Python线程
一.线程创建 #方法一:将要执行的方法作为参数传给Thread的构造方法 import threading import time def show(arg): time.sleep(2) print ...
- Python 线程和进程和协程总结
Python 线程和进程和协程总结 线程和进程和协程 进程 进程是程序执行时的一个实例,是担当分配系统资源(CPU时间.内存等)的基本单位: 进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其 ...
随机推荐
- C89,C99: C数组&结构体&联合体快速初始化
1. 背景 C89标准规定初始化语句的元素以固定顺序出现,该顺序即待初始化数组或结构体元素的定义顺序. C99标准新增指定初始化(Designated Initializer),即可按照任意顺序对数组 ...
- 洛谷P1860——新魔法药水
传送门:QAQQAQ 题意:商店里有N种药水,每种药水都有一个售价和回收价.小S攒了V元钱,还会M种魔法,可以把一些药水合成另一种药水.他一天可以使用K次魔法,问他一天最多赚多少钱? N<=60 ...
- 洛谷P3916 图的遍历
题目链接:https://www.luogu.org/problemnew/show/P3916 题目大意 略. 分析 以终为始,逆向思维. 代码如下 #include <bits/stdc++ ...
- 剑指offer——22表示数值的字符串
题目描述 请实现一个函数用来判断字符串是否表示数值(包括整数和小数).例如,字符串"+100","5e2","-123","3.1 ...
- 搞懂这7个Maven问题,带你吊打面试官!
Java技术栈 www.javastack.cn 优秀的Java技术公众号 作者:张丰哲 www.jianshu.com/p/20b39ab6a88c 在如今的互联网项目开发当中,特别是Java领域, ...
- springDataJpa的官方API
一 . Core concepts(核心概念) 1.springdata中的中心接口是——Repository.这个接口没有什么重要的功能(原句称没什么惊喜的一个接口).主要的作用就是标记和管理.其 ...
- Java oop第08章_JDBC01(入门)
一. JDBC的概念: JDBC(Java Database Connectivity)java数据库链接,是SUN公司为了方便我们Java程序员使用Java程序操作各种数据库管理系统制定的一套标准( ...
- ASP.NET MVC easyUI-datagrid 分页
本文写的是最简单的 按照API文档来写的分页.就是插件自带的分页效果. 一.html代码:field就是代表你后台数据的对应的列名. <table id="dg" class ...
- The linux command 之存储媒介
一.常用的命令 mount:挂载文件系统 unmount:卸载文件系统 fdisk:硬盘分区命令 fdformat:格式化软盘 fsck:检查和修复文件系统 mkfs:创建文件系统 dd:转换和拷贝一 ...
- Ubuntu Apache vhost不执行php小记
运行环境: Ubuntu : 16.04 PHP: 5.6.36 Apache: 2.4.18 出现/var/www/html 文件夹下的 php文件能够执行 vhost 配置文件的DocumentR ...