机器学习——提升方法AdaBoost算法,推导过程
0提升的基本方法
对于分类的问题,给定一个训练样本集,求比较粗糙的分类规则(弱分类器)要比求精确的分类的分类规则(强分类器)容易的多。提升的方法就是从弱分类器算法出发,反复学习,得到一系列弱分类器(又称为基本分类器),然后组合这些弱分类器,构成一个强分类器。大多数的提升方法都是改变训练数据集的概率分布(训练数据的权值分布),针对不同的训练数据分布调用弱学习算法学习一系列弱分类器。
这样,对于提升方法来说,有两个问题需要回答:一是在每一轮如何改变训练数据的权值或概率分布,二是如何将弱分类器组合成一个强分类器。对于第一个问题,AdaBoost的做法是提高那些被前一轮弱分类器错误分类样本的权值,降低那些被正确分类的样本的权值。如此,那些被分类错误的样本将更加受到关注。对于第二个问题,AdaBoost采取多数表决的法法,具体的,加大分类误差率小的弱分类器的权值,使其的作用较大,减小那些分类错误率大的分类器的权值,使其在表决中起较小的作用。
1.AdaBoost算法
AdaBoost算法从训练数据中学习一系列弱分类器或者基本分类器,并将这些分类器进行线性组合。
输入:训练数据集T={(x1,y1),(x2,y2),(x3,y3)......},y的类别为{-1,1}
输出:最终的分类器G(x)
(1)初始化训练数据的权值分布
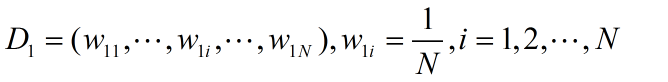
(2)对m=1,2,.....,M
(a)使用具有权值分布的Dm训练数据集进行学习,得到基本分类器
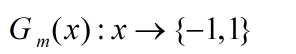
(b)计算Gm(x)在训练数据集上的分类误差率
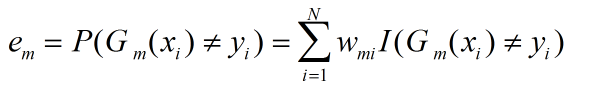
(c)计算Gm(x)的系数
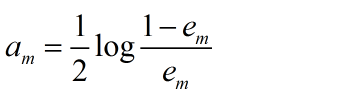
这里的对数是自然对数
(d)更新训练数据集的权值分布
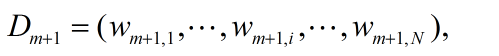
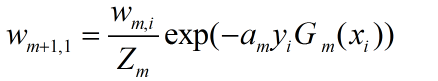
其中,Zm是归一化因子。
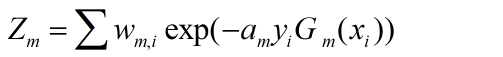
(3)构建基本的分类器的线性组合
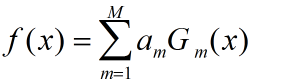
得到最终的分类器:
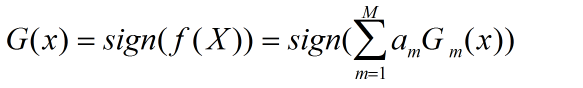
2算法详解
对于算法做如下的解释:
对于原始的数据集,假设其为均匀分布,则能够在原始数据集上面得到基本分类器。得到的权值通过改变分类误差率进而改变分类器的系数,对于基本分类器Gm(x)的系数am,am表示Gm(x)在最终分类器的重要性,当em<=0.5时,am>0,am随着em的减小而增大,所以分类误差率越小的基本分类器在最终的分类器的作用越大。
M个分类器的加权表决,系数am表示了基本分类器GM(x)的重要性,am之和并不为1,由f(x)的符号决定实例x的类,f(x)的绝对值表示分类的确信度。
机器学习——提升方法AdaBoost算法,推导过程的更多相关文章
- 机器学习理论提升方法AdaBoost算法第一卷
AdaBoost算法内容来自<统计学习与方法>李航,<机器学习>周志华,以及<机器学习实战>Peter HarringTon,相互学习,不足之处请大家多多指教! 提 ...
- 08_提升方法_AdaBoost算法
今天是2020年2月24日星期一.一个又一个意外因素串连起2020这不平凡的一年,多么希望时间能够倒退.曾经觉得电视上科比的画面多么熟悉,现在全成了陌生和追忆. GitHub:https://gith ...
- 统计学习方法c++实现之七 提升方法--AdaBoost
提升方法--AdaBoost 前言 AdaBoost是最经典的提升方法,所谓的提升方法就是一系列弱分类器(分类效果只比随机预测好一点)经过组合提升最后的预测效果.而AdaBoost提升方法是在每次训练 ...
- 模型提升方法adaBoost
他通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能. adaboost提高那些被前一轮弱分类器错误分类样本的权重,而降低那些被正确分类样本的权重,这样使得,那些没有得 ...
- 机器学习实战之AdaBoost算法
一,引言 前面几章的介绍了几种分类算法,当然各有优缺.如果将这些不同的分类器组合起来,就构成了我们今天要介绍的集成方法或者说元算法.集成方法有多种形式:可以使多种算法的集成,也可以是一种算法在不同设置 ...
- 提升方法-AdaBoost
提升方法通过改变训练样本的权重,学习多个分类器(弱分类器/基分类器)并将这些分类器进行线性组合,提高分类的性能. AdaBoost算法的特点是不改变所给的训练数据,而不断改变训练数据权值的分布,使得训 ...
- 《机器学习技法》---AdaBoost算法
1 AdaBoost的推导 首先,直接给出AdaBoost算法的核心思想是:在原数据集上经过取样,来生成不同的弱分类器,最终再把这些弱分类器聚合起来. 关键问题有如下几个: (1)取样怎样用数学方式表 ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
随机推荐
- [转]cron表达式的用法
cron表达式通过特定的规则指定时间,用于定时任务,本文简单记录它的部分语法和实例,并不完全,能覆盖日常大部分需求. 1. 整体结构 cron表达式是一个字符串,分为6或7个域,每两个域之间用空格分隔 ...
- mysql基础(库、表相关)
一. mysql支持的数据类型 1.1 mysql支持的数字类型: TINYINT 1 字节 (-128,127) (0,255) 小整数值 SMALLINT 2 字节 (-32 768,32 767 ...
- C# 序列类为 xml 可以使用的特性大全
本文告诉大家如何使用序列类,以及序列时可以用到的特性,特性的作用和一些容易被问的问题 最近我在把项目文件修改为 VisualStudio 2017 的格式,请看从以前的项目格式迁移到 VS2017 新 ...
- php框架thinkphp3.2.3 配置文件bug
bug:有前后台的项目部署阶段(DEBUG模式为false)中,修改应用配置文件后,无效,修改自定义配置文件,正常;(开发模式正常) //项目只有后台没有前台的(单独模块),直接写在模块配置中即可,不 ...
- 2018-2-13-C#-通配符转正则
title author date CreateTime categories C# 通配符转正则 lindexi 2018-2-13 17:23:3 +0800 2018-2-13 17:23:3 ...
- H3C IPv6地址构成
- JSON怎样添加注释
今天在写一个程序的时候发现了一个问题,在json文件中添加注释之后,程序就出现bug了 于是,去搜了一下这个问题的相关解释,在这里和大家分享一下: JSON为什么不能添加注释? 这位外国友人给出的解释 ...
- Vue中的scoped及穿透方法(修改第三方组件局部的样式)
何为scoped? 在vue文件中的style标签上,有一个特殊的属性:scoped.当一个style标签拥有scoped属性时,它的CSS样式就只能作用于当前的组件,也就是说,该样式只能适用于当前组 ...
- 为什么Redis是单线程,性能还如此高?
一. Redis为什么是单线程 注意:redis 单线程指的是网络请求模块使用了一个线程,即一个线程处理所有网络请求,其他模块仍用了多个线程. 因为CPU不是Redis的瓶颈.Redis的瓶颈最有可能 ...
- js实现new
function New(fn,...args){ let obj={} obj.__proto__=fn.prototype let result=fn.apply(obj,args) if(typ ...