JVM性能分析 | 一次生产系统Full GC问题分析与排查总结
一次生产系统Full GC问题分析与排查总结
背景
最近某线上业务系统生产环境频频CPU使用率过低,频繁告警,通过重启可以缓解,但是过了一段时间又会继续预警,线上两个服务节点相继出现CPU资源紧张,导致服务器卡死不可用,通过告警信息可以看到以下问题:
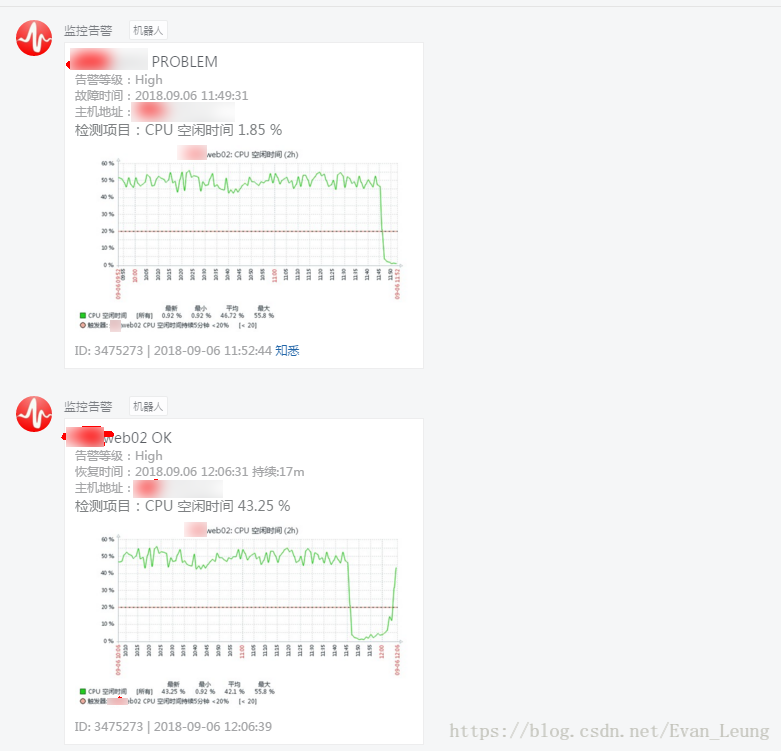
从上图可以看到,目前zabbix监控展示CPU空闲时间已经低于预警线,证明目前CPU资源占用过高,考虑到最近并没有特别开发任务上线,但是最近有发布过一个新的营销活动,有可能是因为突然用户量增长进一步凸显该问题。
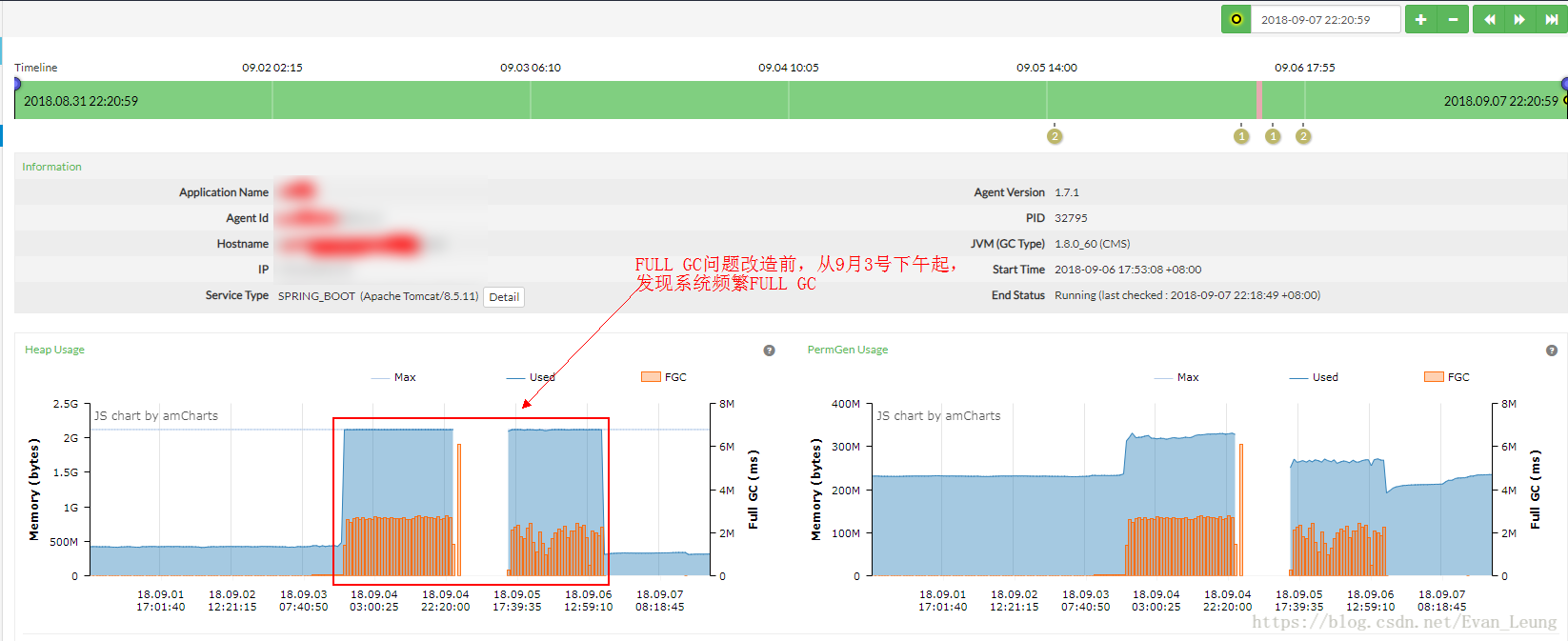
从Pinpoint APM监控工具看到,从9月3号下午开始,系统开始出现频繁full gc的情况,而刚好9月3号下午发布了一个新活动,基本可以断定这可能是用户量突然激增,凸显潜伏已久的系统问题,于是接下来方向就可以往full gc方向去排查,找出引起full gc的代码。
侦查思路
往FULL GC方向侦查,怀疑存在内存泄露
排查路线:
既然上面已经定位到是FULL GC问题,我们就可以用常用FULL GC的手段去解决。在这次故障分析我们是利用MAT去做分析,主要对以下几点做排查:
- 程序是否内存泄露
- 程序中是否存在不合理的大对象占用
- 程序中部分对象产生内存是否可以优化
导出JVM dump文件和jstack线程日志,保留案发现场
因为公司不允许个人访问线上服务器,于是让运维同学在服务器出现故障时导出jvm dump文件和jstack线程日志,如果自己有权限去生产服务器的话,可以通过以下指令导出jvm dump文件
jmap -dump:format=b,file=文件名 [服务进程ID]结合MAT分析工具,找出可疑对象
使用MAT前,先简单介绍下MAT的一些常用的指标和功能概念:
Shallow Heap指标:对象本身占用内存的大小,不包含对其他对象的引用,也就是对象头加成员变量(不是成员变量的值)的总和
Retained Heap指标:是该对象自己的shallow size,加上从该对象能直接或间接访问到对象的shallow size之和。换句话说,retained size是该对象被GC之后所能回收到内存的总和。
- Histogram动作:列出每个类的实例数
- Dominator Tree动作:列出
最大的对象以及它们保存的内容 - Top Consumers动作: 按照类和包分组打印花费最高的实例
- Duplicate Classes动作: 检测由多个类加载器加载的类
- Leak Suspects报告: 包括泄密嫌疑人和系统概述
- Top Components报告:列出大于总堆的1%的组件的报告
通过Leak Suspects排查内存泄露
在Ecplise Memory Analyzer导入JVM dump文件,点击工具栏上的 Leak Suspects 菜单项来生成内存泄露分析报告,也可以直接点击饼图下方的 Reports->Leak Suspects链接来生成报告。如图:
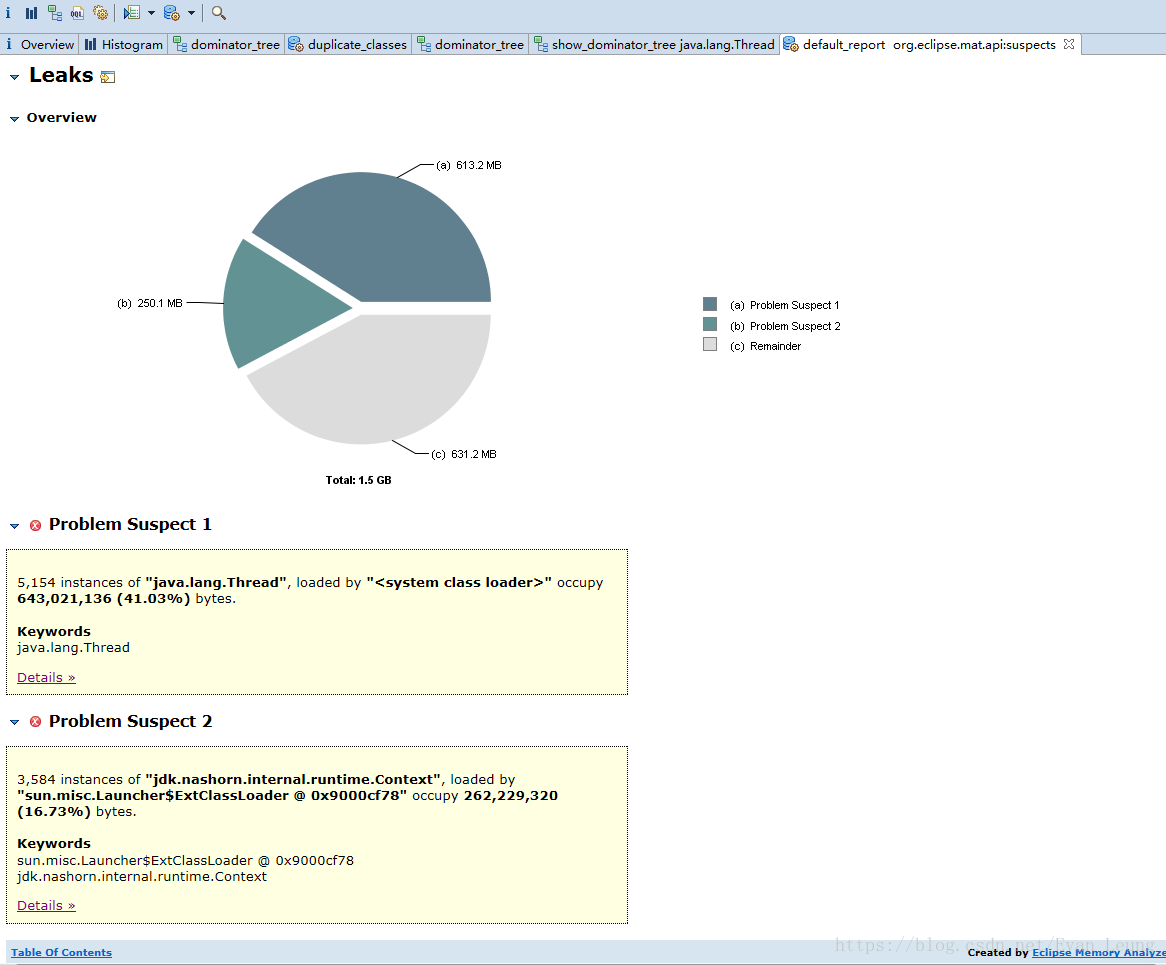
MAT工具分析了heap dump后在界面上非常直观的展示了一个饼图,该图深色区域被怀疑有内存泄漏,可以发现整个heap才1.5G内存,深色区域就占了57.76%。接下来是一个简短的描述,MAT告诉我们存在两个可疑问题
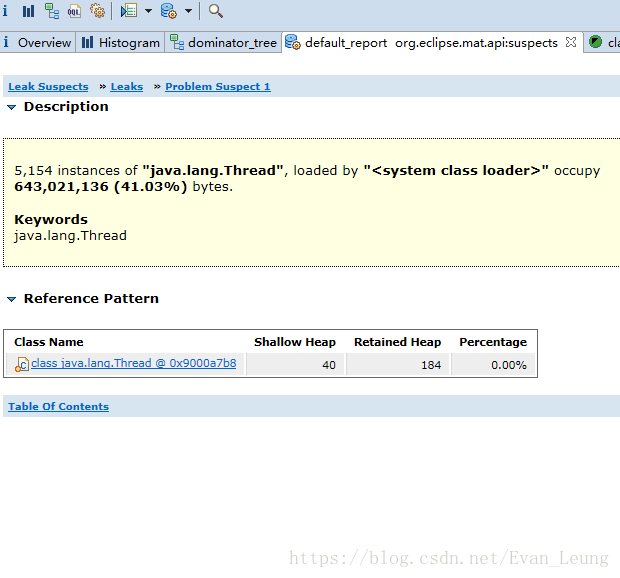
- Problem Suspect 1:告诉我们java.lang.Thread线程实例占用了大量内存,一共存在5154个实例,并且明确指出system class loader加载的java.lang.Thread实例占据了643,021,136 (41.03%)字节 ,并建议用关键字”java.lang.Thread”进行检查。所以,MAT通过简单的两句话就说明了问题所在,就算使用者没什么处理内存问题的经验。在下面还有一个”Details”链接,MAT给了一个参考类。如图:
- Problem Suspect 2: 告诉我们
jdk.nashorn.internal.runtime.Context线程实例占用了大量内存,并且明确指出sun.misc.Launcher$ExtClassLoader @ 0x9000cf78加载的jdk.nashorn.internal.runtime.Context实例占据了262,229,320 (16.73%)字节,并建议用关键字sun.misc.Launcher$ExtClassLoader @ 0x9000cf78 jdk.nashorn.internal.runtime.Context进行检查
通过Top Consumers定位大对象
点击Actions->Top Consumers ,查看大对象有哪些
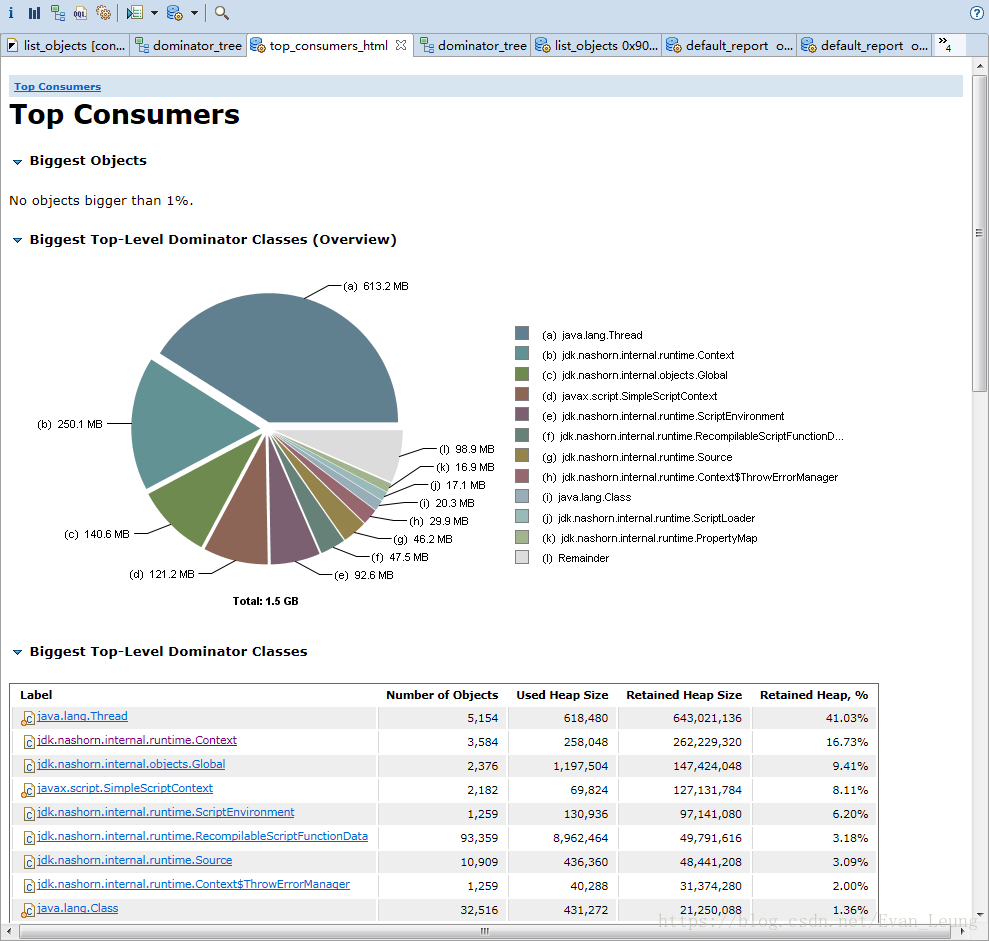
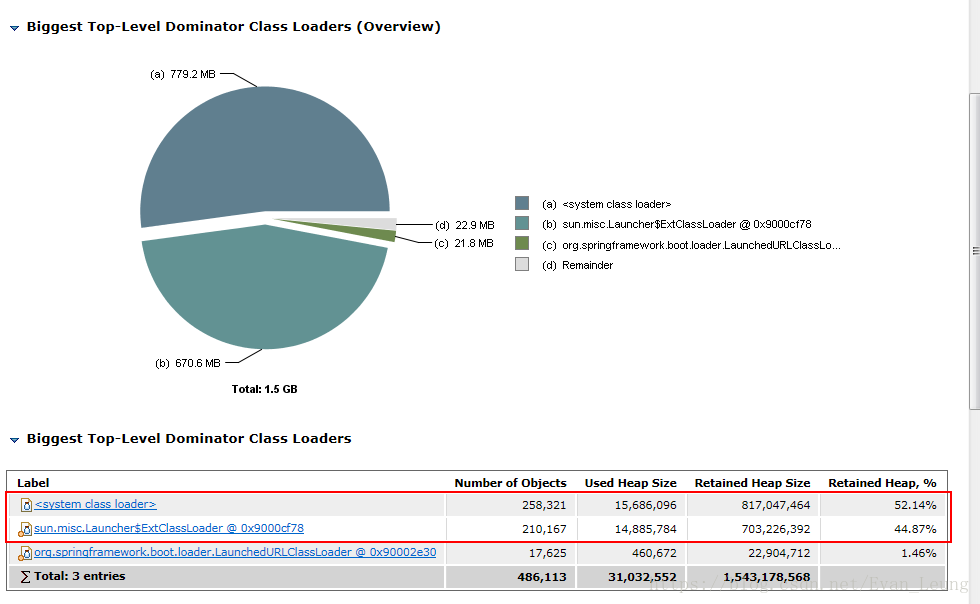
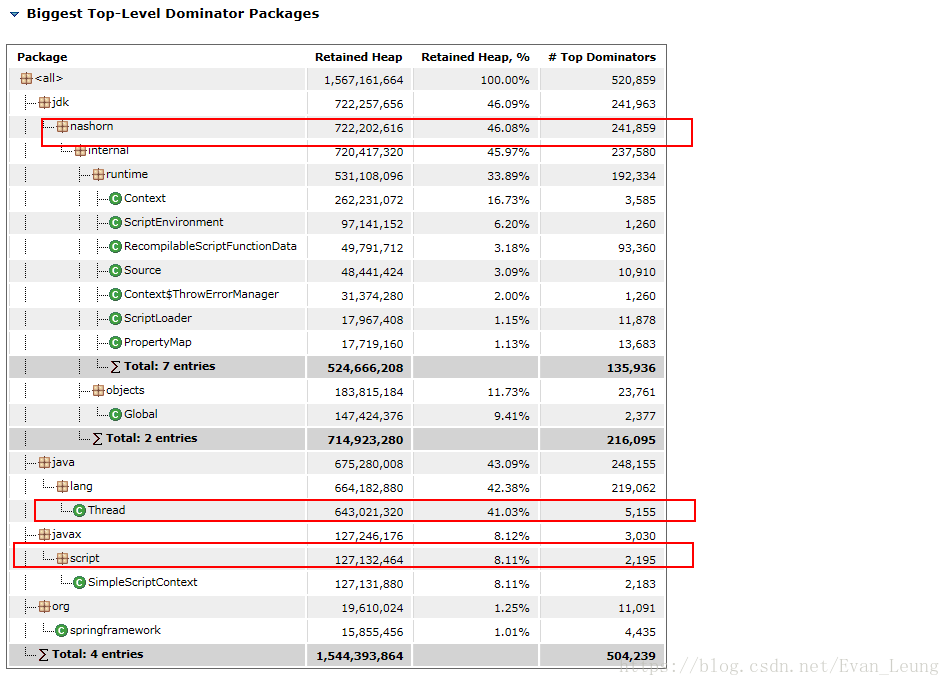
从上图可以看出,java.lang.Thread、jdk.nashorn.*和javax.script.*这些类实例占据了大部分内存
问题分析
从上面分析报告,可疑大胆推断以下结论:
- 大量
java.lang.Thread实例,明显是线程使用不合理,怀疑有地方不断创建线程,没有使用线程池导致 - 大量
jdk.nashorn.internal.*和javax.script.*相关实例,而jdk.nashorn.*这个包是Nashorn JavaScript引擎的包,主要是nashorn用于在JVM上以原生方式运行动态的JavaScript代码来扩展Java的功能,javax.script包用于javascript与java交互操作。于是可以基本断定这是跟javascript脚本相关操作有关,应该是有地方不断创建javascript脚本相关对象没有被回收。
结合以上两点,推测应用程序线程和脚本操作部分出现问题,与该系统相关开发人员沟通,确实该系统是有大量javascript脚本操作,是通过Javascript脚本做一些特性开发,然后在在java调用执行。尝试使用包名jdk.nashorn查找运维导出的jstack线程日志,看看最接近的业务代码是什么
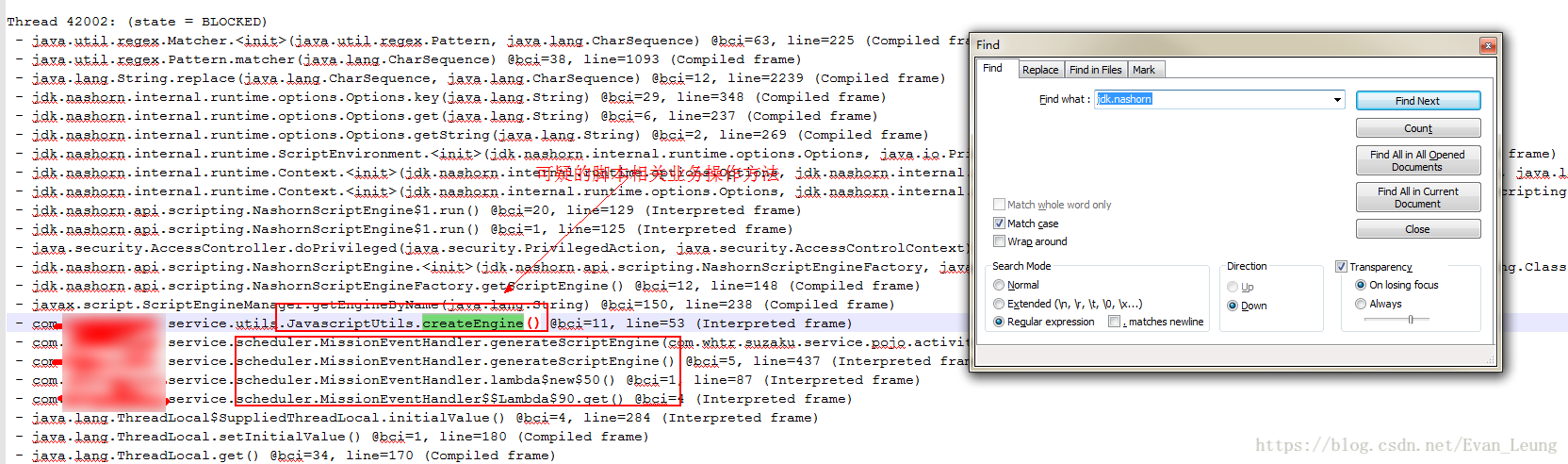
果然看到了线程日志里面找到了疑似线程操作的业务代码,通过查看源码,一步步查看调用链,发现了有个地方会每次实例初始化都会创建一份脚本引擎
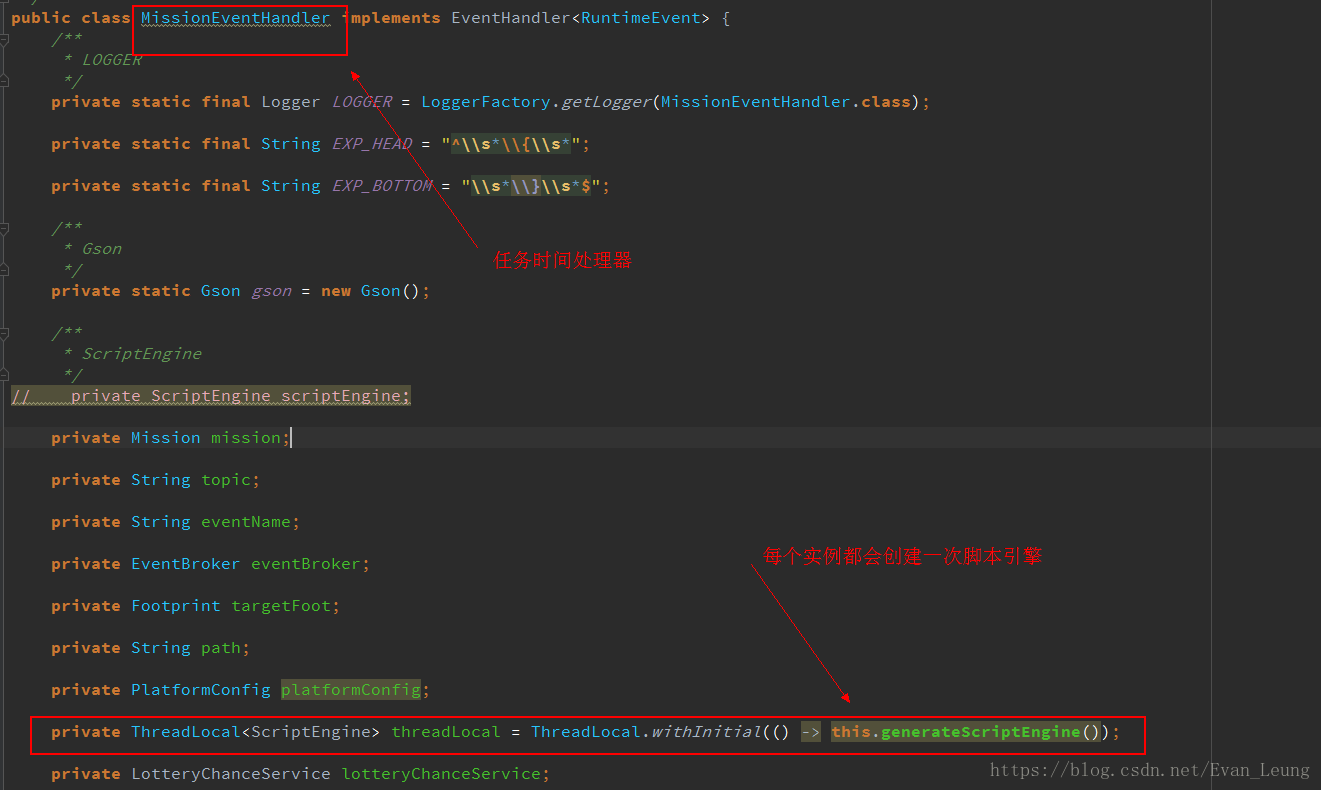
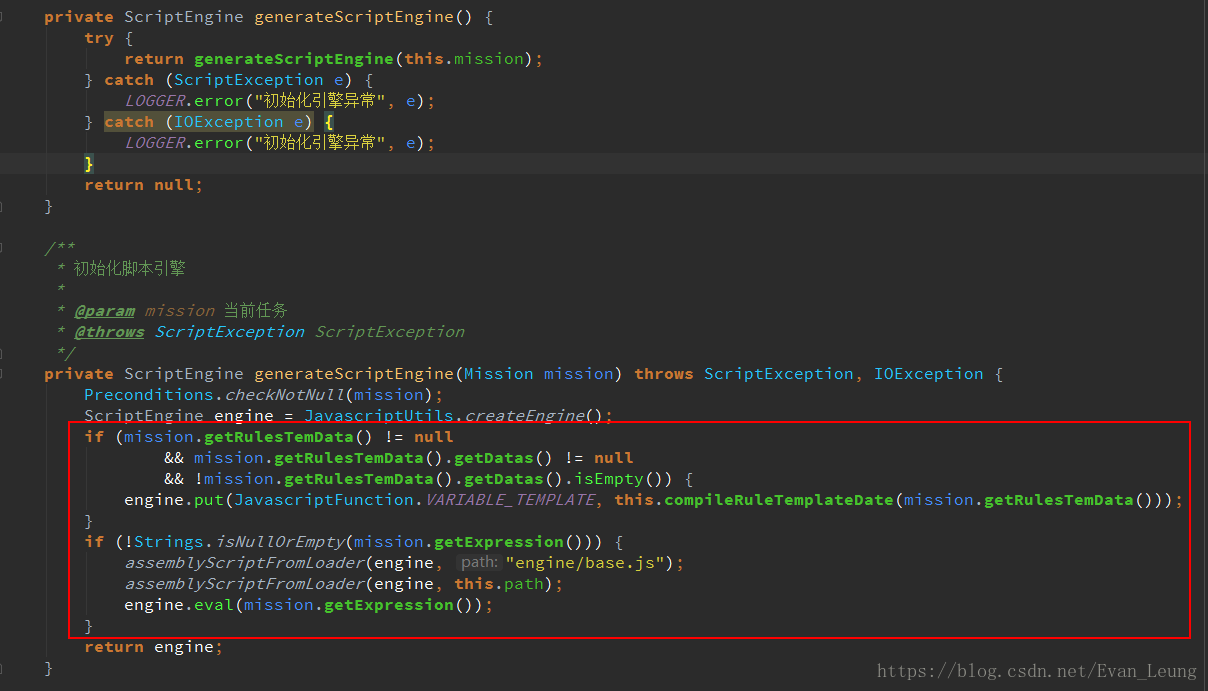
这段代码大概作用是把每个任务的规则脚本存放在脚本引擎,然后存放在threadLocal里,每个MissionEventHandler实例初始化都会创建一个threadLocal用于存放当前线程任务脚本,以防多线程操作同一个MissionEventHandler实例会引起脚本因并发被篡改问题。而经过沿着调用链查看源码了解,这些MissionEventHandler实例只会业务人员点击任务下线的时候才会进行销毁处理,那就是只要任务不下线,这些任务会一直存活在内存中。
但是只要MissionEventHandler实例数量控制好,应该是不会出现上述大量脚本相关实例引发频繁FULL GC问题,接下来我们的侦查方向就是查看MissionEventHandler实例创建源头,是否系统存在批量创建该实例的代码?继续沿着调用链查看源代码,发现了一个异步观察者类,它是用来通知消息事件的,以下是其中一个方法
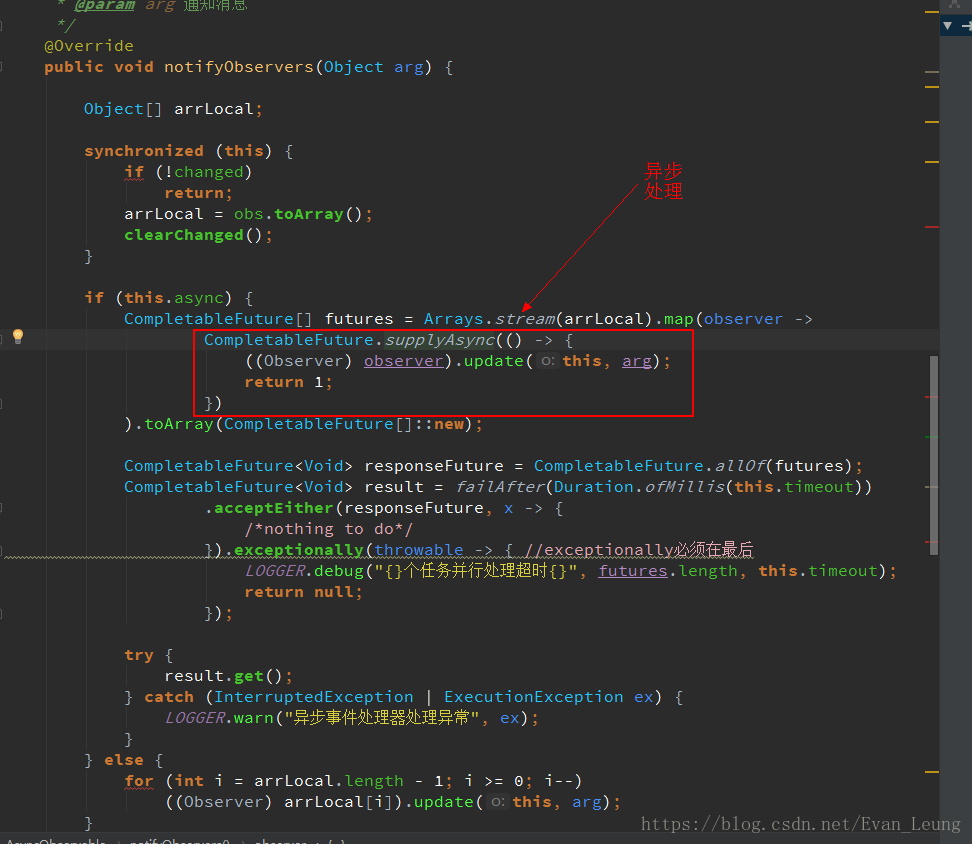
这里是使用了CompletableFuture的supplyAsync(Supplier<U> supplier)方法进行异步处理,再进一步查看supplyAsync的源码
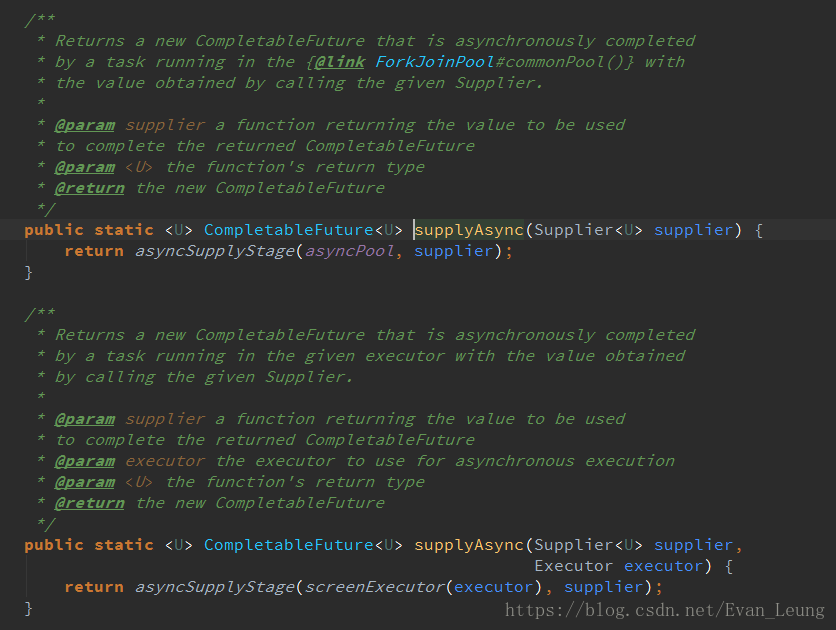
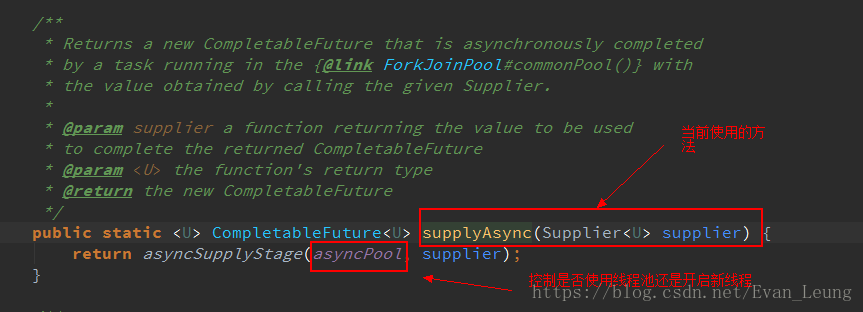
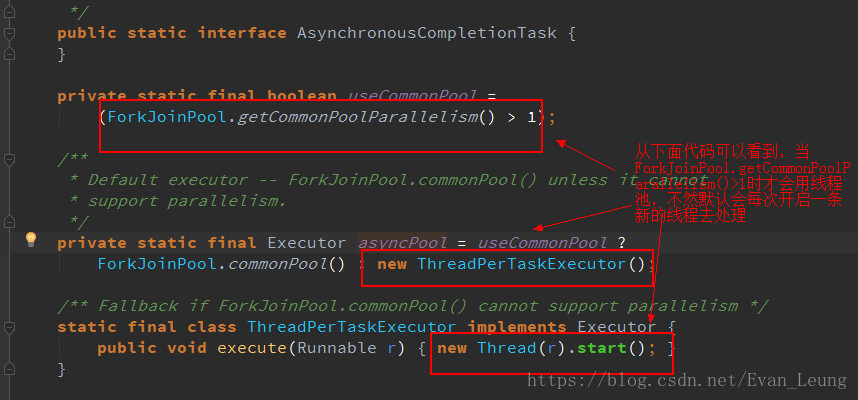
从上面代码可以看到,supplyAsync有2个重载方法,当我们不指定线程池,它默认是调用第一个方法,当ForkJoinPool.getCommonPoolParallelism() > 1才会使用commonPool线程池,否则该方法默认会每次创建一条新的线程去处理。那有没有可能是ForkJoinPool.getCommonPoolParallelism()<=1 导致每次都创建新的线程呢?我们进一步查看ForkJoinPool.getCommonPoolParallelism()源码,发现这方法使用Java 8中的ForkJoinPool.commonPool()可以使用一个特殊的ForkJoinPool。该池使用一个取决于可用内核数量的预设并行度。一般情况下,预设的并行度是CPU内核数-1,该系统在生产环境运行的服务器核数为2,那就是并行度为1,即这里的ForkJoinPool.getCommonPoolParallelism()=1,意味着CompletableFuture的supplyAsync方法在这里处理业务是每次都创建一条新的线程去处理。
总结
根据上面的分析,一切都真相大白,之前看到的大量java.lang.Thread实例就是因为处理业务时,默认每次都会开启一条新的线程,导致出现大量的线程实例,而这些大量的线程实例又会引发大量的通知消息操作,导致持有的脚本相关实例没法被回收,从而引发了大量jdk.nashorn.internal.*和javax.script.* 的实例占据堆内存。
解决方案
这里的解决方案很简单,这里引发的问题都是因为没有使用到线程池导致的,可以采取以下两种措施:
- 通过在tomcat配置jvm启动参数
-Djava.util.concurrent.ForkJoinPool.common.parallelism=2,可以让supplyAsync(Supplier<U> supplier)方法启动默认的ForkJoinPool.commonPool()去执行 - 改为调用
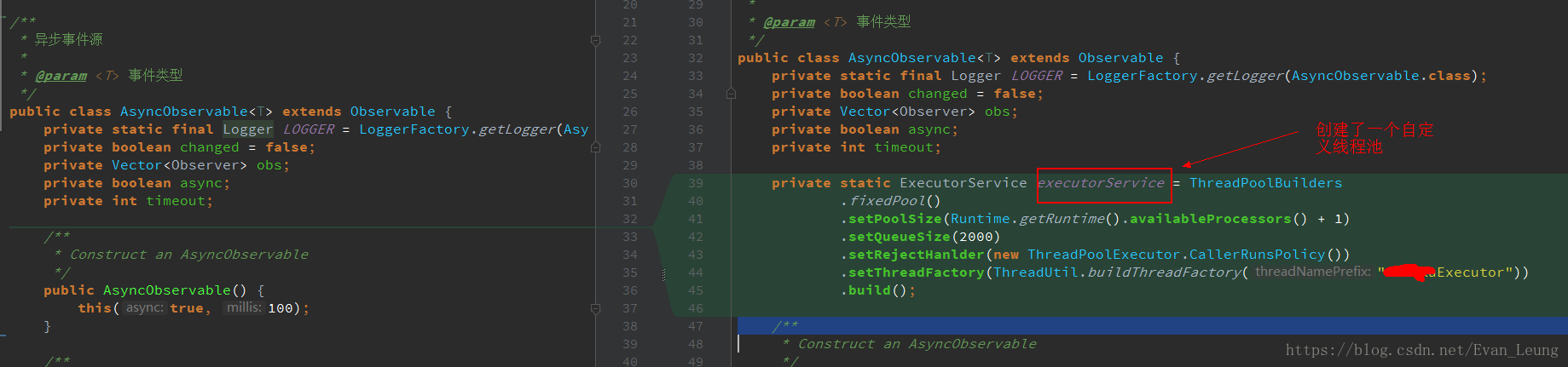
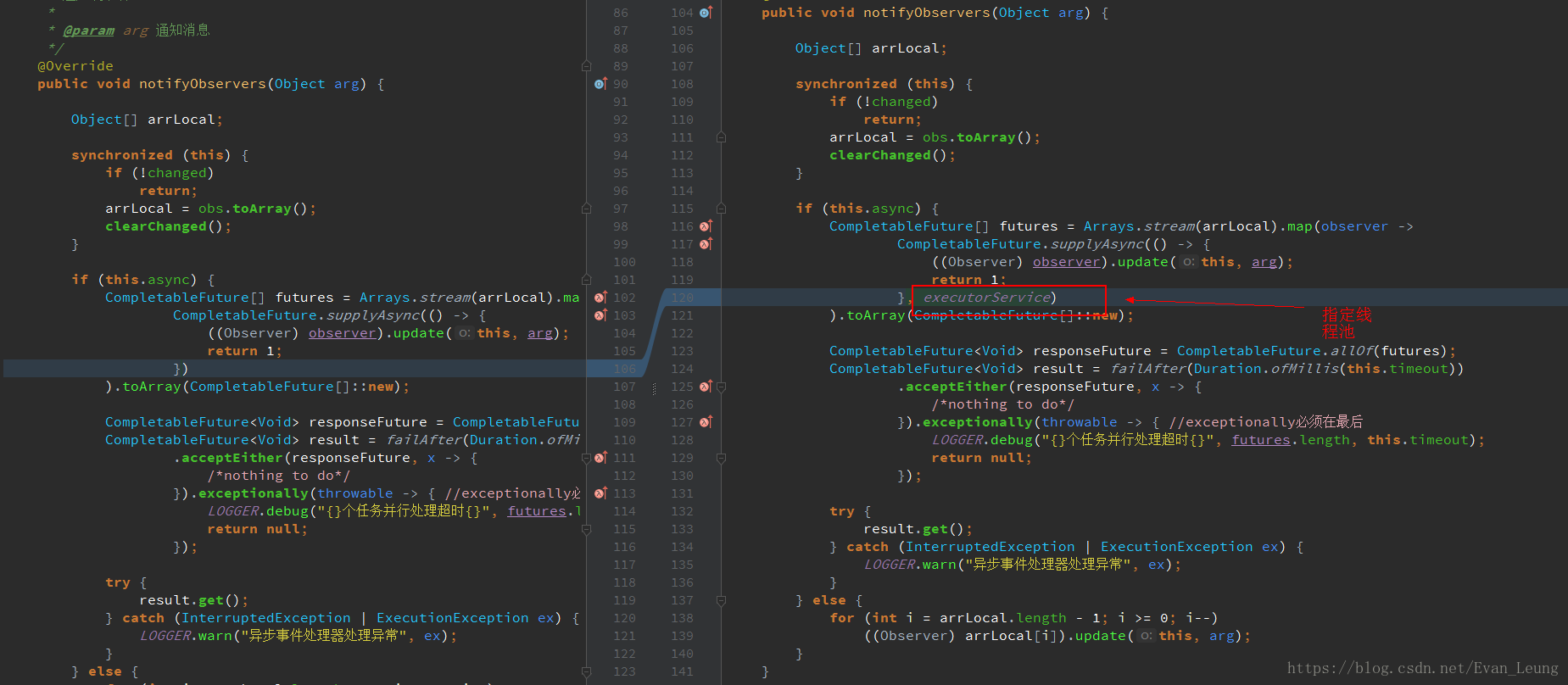
CompletableFuture<U> supplyAsync(Supplier<U> supplier,Executor executor),给方法指定线程池(推荐)
在本次改造是使用第二个方案,创建了一个自定义线程池,然后指定线程池去执行操作,代码如下
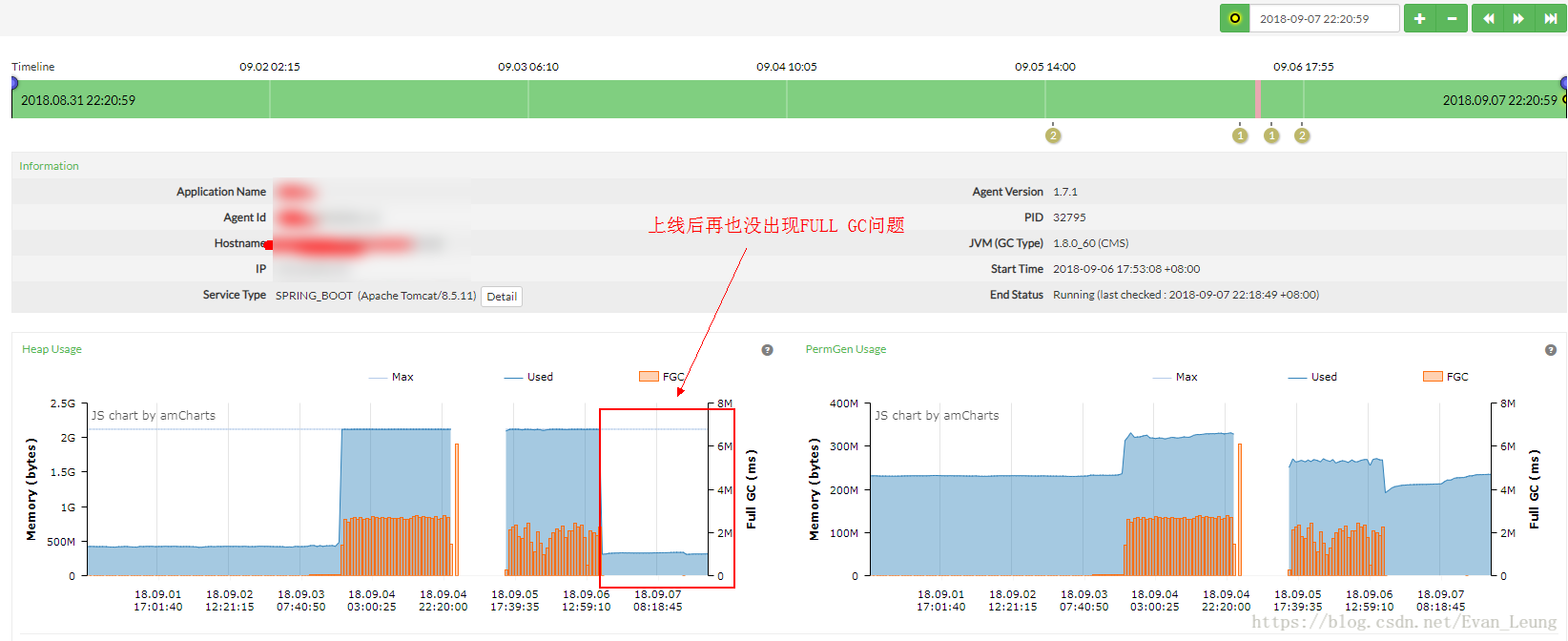
上线后观察监控
上线后通过PINPOINT观察,再也没出现FULL GC问题
Java引用法则说明
从最强到最弱,不同的引用(可到达性)级别反映了对象的生命周期。
Strong Ref(强引用):通常我们编写的代码都是Strong Ref,于此对应的是强可达性,只有去掉强可达,对象才被回收。
Soft Ref(软引用):对应软可达性,只要有足够的内存,就一直保持对象,直到发现内存吃紧且没有Strong Ref时才回收对象。一般可用来实现缓存,通过java.lang.ref.SoftReference类实现。
Weak Ref(弱引用):比Soft Ref更弱,当发现不存在Strong Ref时,立刻回收对象而不必等到内存吃紧的时候。通过java.lang.ref.WeakReference和java.util.WeakHashMap类实现。
Phantom Ref(虚引用):根本不会在内存中保持任何对象,你只能使用Phantom Ref本身。一般用于在进入finalize()方法后进行特殊的清理过程,通过 java.lang.ref.PhantomReference实现。
JVM性能分析 | 一次生产系统Full GC问题分析与排查总结的更多相关文章
- JVM性能调优的6大步骤,及关键调优参数详解
JVM性能调优方法和步骤1.监控GC的状态2.生成堆的dump文件3.分析dump文件4.分析结果,判断是否需要优化5.调整GC类型和内存分配6.不断分析和调整JVM调优参数参考 对JVM内存的系统级 ...
- 直通BAT必考题系列:JVM性能调优的6大步骤,及关键调优参数详解
JVM内存调优 对JVM内存的系统级的调优主要的目的是减少GC的频率和Full GC的次数. 1.Full GC 会对整个堆进行整理,包括Young.Tenured和Perm.Full GC因为需要对 ...
- Java架构师面试题——JVM性能调优
JVM内存调优 对JVM内存的系统级的调优主要的目的是减少GC的频率和Full GC的次数. 1.Full GC 会对整个堆进行整理,包括Young.Tenured和Perm.Full GC因为需要对 ...
- JVM 性能调优实战之:一次系统性能瓶颈的寻找过程
玩过性能优化的朋友都清楚,性能优化的关键并不在于怎么进行优化,而在于怎么找到当前系统的性能瓶颈.性能优化分为好几个层次,比如系统层次.算法层次.代码层次…JVM 的性能优化被认为是底层优化,门槛较高, ...
- JVM性能分析与优化
JVM性能分析与优化: http://www.docin.com/p-757199232.html
- Db2性能:系统CPU高问题分析的一些思路
Db2性能:系统CPU高问题分析的一些思路 1. 如何判断CPU高? 有很多操作系统的命令可以看出来,比如ps -elf,iostat, vmstat, top/topas, 2. 收集数据 CPU高 ...
- JVM性能优化,提高Java的伸缩性
很多程序员在解决JVM性能问题的时候,花开了很多时间去调优应用程序级别的性能瓶颈,当你读完这本系列文章之后你会发现我可能更加系统地看待这类的问题.我说过JVM的自身技术限制了Java企业级应用的伸缩性 ...
- 如何合理的规划一次jvm性能调优
https://blog.csdn.net/miracle_8/article/details/78347172 摘要: JVM性能调优涉及到方方面面的取舍,往往是牵一发而动全身,需要全盘考虑各方面的 ...
- 如何合理的规划jvm性能调优
JVM性能调优涉及到方方面面的取舍,往往是牵一发而动全身,需要全盘考虑各方面的影响.但也有一些基础的理论和原则,理解这些理论并遵循这些原则会让你的性能调优任务将会更加轻松.为了更好的理解本篇所介绍的内 ...
随机推荐
- 如何在Linux上创建,列出和删除Docker容器
本篇文章介绍的内容是关于在Linux机器上创建,列出和删除docker容器,下面我们来看具体的内容. 1.启动Docker容器 使用下面的命令启动新的Docker容器.这将启动一个新的容器,并为你提供 ...
- 洛谷$P3645\ [APIO2015]$雅加达的摩天楼 最短路
正解:最短路 解题报告: 传送门$QwQ$ 考虑暴力连边,发现最多有$n^2$条边.于是考虑分块 对于长度$p_i$小于等于$\sqrt(n)$的边,建立子图$d=p_i$.说下关于子图$d$的定义? ...
- $HDU1846\ Brave\ Game$ 博弈论
正解:博弈论 解题报告: 传送门! 巴什博奕板子题鸭$QwQ$ 就有个结论,是说当$(m+1)\mid n$时先手必败,否则必胜 这个瞎证明一下就能出来 就考虑当$(m+1)\mid 1$时,若先手取 ...
- 「BZOJ4510」「Usaco2016 Jan」Radio Contact 解题报告
无线电联系 Radio Contact 题目描述 Farmer John has lost his favorite cow bell, and Bessie the cow has agreed t ...
- 1078 字符串压缩与解压 (20分)C语言
文本压缩有很多种方法,这里我们只考虑最简单的一种:把由相同字符组成的一个连续的片段用这个字符和片段中含有这个字符的个数来表示.例如 ccccc 就用 5c 来表示.如果字符没有重复,就原样输出.例如 ...
- 侠说java8-行为参数化(开山篇)
啥是行为参数化 行为参数化的本质是不执行复杂的代码块,让逻辑清晰可用. 相信使用过js的你肯定知道,js是可以传递函数的,而在 java中也有类似的特性,那就是匿名函数. 理解:行为参数化是一种方法, ...
- 吴恩达机器学习笔记 - cost function and gradient descent
一.简介 cost fuction是用来判断机器预算值和实际值得误差,一般来说训练机器学习的目的就是希望将这个cost function减到最小.本文会介绍如何找到这个最小值. 二.线性回归的cost ...
- Win10删除桌面上的回收站、计算机、网络等图标
解决方案: 桌面上鼠标右键,选择个性化 个性化窗口左边侧栏选择主题 移动至最下方点击"桌面图标设置"即可看到系统中的五个桌面图标
- 小米6X谷歌套件
话不多说真机测试完美适配,安卓万物基于谷歌链接如下(个别MIUI版本不同谷歌商店会报错,如遇到请留言我会第一时间回复解决) 链接:https://pan.baidu.com/s/1b2Cs0u9J2b ...
- schedule of 2016-09-26~2016-10-02(Monday~Sunday)——1st semester of 2nd Grade
2016/9/26 Monday 1.make ppt for this afternoon's group meeting 2.ask teacher Xiqi&Liu some probl ...