小白学Java:I/O流
小白学Java:I/O流
流,表示任何有能力产生数据的数据源对象或者是有能力接收数据的接收端对象,它屏蔽了实际的I/O设备中处理数据的细节。
基本分类
- 根据方向
- 输入流:数据从外部流向程序,例如从文件中读取数据。
- 输出流:数据从程序流向外部,例如向文件中写数据。
- 根据形式
- 字符流:字符类文件,如 txt、 java、 html。
- 字节流:图片、视频、音频 。
- 根据功能
- 节点流:直接从数据源进行数据读写
- 处理流:封装其他的流,来提供增强流的功能。
| 输入流 | 输出流 | |
|---|---|---|
| 字符流 | Reader | Writer |
| 字节流 | InputStream | OutputStream |
- 上面四大基本流都是抽象类,都不能直接创捷对象。
- 数据的来源/目的地:磁盘、网络、内存、外部设备。
发展史
java1.0版本中,I/O库中与输入有关的所有类都将继承
InputStream,与输出有关的所有类继承OutputStream,用以操作二进制数据。java1.1版本对I/O库进行了修改:
- 在原先的库中新增了新类,如
ObjectInputStream和ObjectOutputStream。 - 增加了Reader和Writer,提供了兼容Unicode与面向字符的I/O功能。
- 在Reader和Writer类层次结构中,提供了使字符与字节相互转化的类,
OutputStreamWriter和InputStreamReader。
- 在原先的库中新增了新类,如
两个不同的继承层次结构拥有相似的行为,它们都提供了读(read)和写(write)的方法,针对不同的情况,提供的方法也是类似的。
java1.4版本的java.nio.*包中引入新的I/O类库,这部分以后再做学习。
文件字符流
- 文件字符输出流
FileWriter:自带缓冲区,数据先写到到缓冲区上,然后从缓冲区写入文件。 - 文件字符输入流
FileReader:没有缓冲区,可以单个字符的读取,也可以自定义数组缓冲区。
输出的基本结构
在实际应用中,异常处理的方式都需要按照下面的结构进行,本篇为了节约篇幅,之后都将采用向上抛出的方式处理异常。
//将流对象放在try之外声明,并附为null,保证编译,可以调用close
FileWriter writer = null;
try {
//将流对象放在里面初始化
writer = new FileWriter("D:\\b.txt");
writer.write("abc");
//防止关流失败,没有自动冲刷,导致数据丢失
writer.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
//判断writer对象是否成功初始化
if(writer!=null) {
//关流,无论成功与否
try {
writer.close();
} catch (IOException e) {
e.printStackTrace();
}finally {
//无论关流成功与否,都是有意义的:标为垃圾对象,强制回收
writer = null;
}
}
}
- 并不会直接将数据写入文件中,而是先写入缓冲区,待缓冲区满了之后才将缓冲区的数据写入文件。
- 假设数据写入缓冲区时且缓冲区还没满,数据还没能够写入文件时,程序就已经结束,会导致数据惨死缓冲区,这时需要手动冲刷缓冲区,将缓冲区内的数据冲刷进文件中。
writer.flush();。 - 数据写入完毕,释放文件以允许别的流来操作该文件。关闭流可以调用
close()方法,值得注意的是,在close执行之前,流会自动进行一次flush的操作以避免数据还残存在缓冲区中,但这并不意味着flush操作是多余的。
流中的异常处理
- 无论流操作成功与否,关流操作都需要进行,所以需要将关流操作放到finally代码块中。
- 为了让流对象再finally中以然能够使用,所以需要将流对象放在try之外声明并且赋值为null,然后在try之内进行实际的初始化过程。
- 在关流之前要判断流对象是否初始化成功,实际就是判断流对象是否为null。
writer!=null时才执行关流操作。 - 关流可能会失败,此时流依然会占用文件,所以需要将流对象置为null,标记为垃圾对象进行强制回收以释放文件。
- 如果流有缓冲区,为了防止关流失败导致没有进行自动冲刷,所以需要手动冲刷一次,以防止有数据死在缓冲区而产生数据的丢失。
异常处理新方式
JDK1.7提出了对流进行异常处理的新方式,任何AutoCloseable类型的对象都可以用于try-with-resourses语法,实现自动关闭。
要求处理的对象的声明过程必须在try后跟的()中,在try代码块之外。
try(FileWriter writer = new FileWriter("D:\\c.txt")){
writer.write("abc");
}catch (IOException e){
e.printStackTrace();
}
读取的基本结构
处理异常的正确方式在输入的结构中已说明,这边就不进行繁杂的异常处理,执行直接向上抛出的不负责任的操作。
public static void main(String[] args) throws IOException {
FileReader reader = new FileReader("D:\\b.txt");
//定义一个变量记录每次读取的字符
int m;
//读取到末尾为-1
while((m = reader.read())!=-1){
System.out.print(m);
}
reader.close();
}
- 文件字符输入流没有缓冲区。
- read方法用来从文件中读取字符,每次只读取一个。
- 定义变量m记录读取的字符,以达到末尾为终止条件。
m!=-1时,终止循环。 - 读取结束,执行关流操作。
当然,每次读取一个字符,怪麻烦的,我们可以改进一下:
//定义数组作为缓冲区
char[] cs = new char[5];
//定义变量记录读取字符的个数
int len;
while ((len = reader.read(cs)) != -1) {
System.out.println(new String(cs, 0, len));
}
reader.close();
运用输入与输出
运用文件字符输入与输出的小小案例:
public static void copyFile(FileReader reader, FileWriter writer) throws IOException {
//利用字符数组作为缓冲区
char[] cs = new char[5];
//定义变量记录读取到的字符个数
int m;
while((m = reader.read(cs))!=-1){
//将读取到的内容写入新的文件中
writer.write(cs,0,m);
}
reader.close();
writer.close();
}
文件字节流
- 文件字节输出流
FileOutputStream在输出的时候没有缓冲区,所以不需要进行flush操作。
public static void main(String[] args) throws Exception {
FileOutputStream out = new FileOutputStream("D:\\b.txt");
//写入数据
//字节输出流没有缓冲区
out.write("天乔巴夏".getBytes());
//关流是为了释放文件
out.close();
}
- 文件字节输入流
FileInputStream,可以定义字节数组作为缓冲区。
public static void main(String[] args) throws Exception{
FileInputStream in = new FileInputStream("E:\\1myblog\\Node.png");
//1.读取字节
int i = in.read();
int i;
while((i=in.read())!=-1)
System.out.println(i);
//2.定义字节数组作为缓冲区
byte[] bs = new byte[10];
//定义变量记录每次实际读取的字节个数
int len;
while((len = in.read(bs))!=-1){
System.out.println(new String(bs,0,len));
}
in.close();
}
缓冲流
字符缓冲流
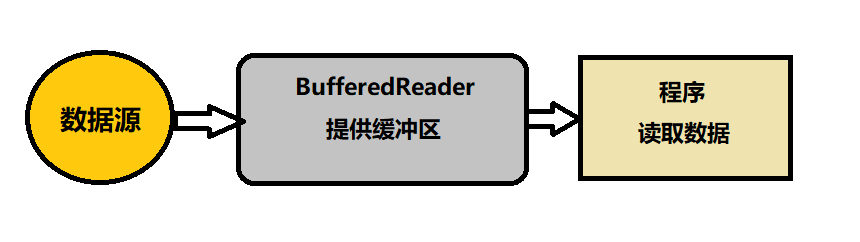
- BufferedReader:在构建的时候需要传入一个Reader对象,真正读取数据依靠的是传入的这个Reader对象,
BufferedRead从Reader对象中获取数据提供缓冲区。
public static void main(String[] args) throws IOException {
//真正读取文件的流是FileReader,它本身并没有缓冲区
FileReader reader = new FileReader("D:\\b.txt");
BufferedReader br = new BufferedReader(reader);
//读取一行
//String str = br.readLine();
//System.out.println(str);
//定义一个变量来记录读取的每一行的数据(回车)
String str;
//读取到末尾返回null
while((str = br.readLine())!=null){
System.out.println(str);
}
//关外层流即可
br.close();
}
- BufferedWriter:提供了一个更大的缓冲区,提供了一个
newLine的方法用于换行,以屏蔽不同操作系统的差异性。
public static void main(String[] args) throws Exception {
//真正向文件中写数据的流是FileWriter,本身具有缓冲区
//BufferedWriter 提供了更大的缓冲区
BufferedWriter writer = new BufferedWriter(new FileWriter("E:\\b.txt"));
writer.write("天乔");
//换行: Windows中换行是 \r\n linux中只有\n
//提供newLine() 统一换行
writer.newLine();
writer.write("巴夏");
writer.close();
}
装饰设计模式
缓冲流基于装饰设计模式,即利用同类对象构建本类对象,在本类中进行功能的改变或者增强。
例如,BufferedReader本身就是Reader对象,它接收了一个Reader对象构建自身,自身提供缓冲区和其他新增方法,通过减少磁盘读写次数来提高输入和输出的速度。
除此之外,字节流同样也存在缓冲流,分别是BufferedInputStream和BufferedOutputStream。
转换流(适配器)
利用转换流可以实现字符流和字节流之间的转换。
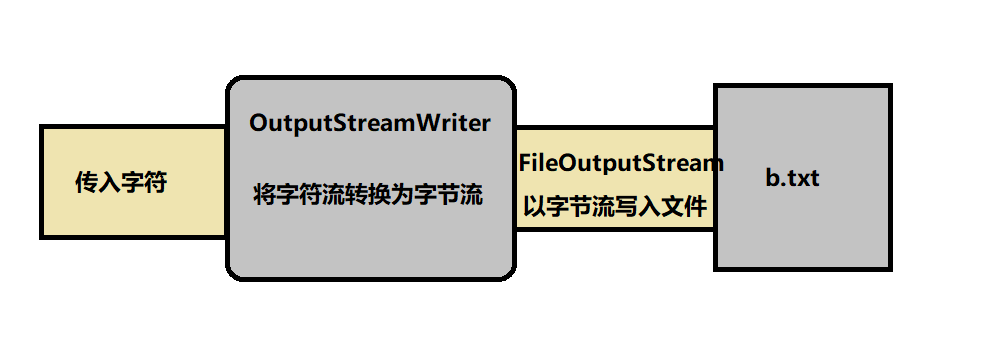
- OutputStreamWriter
public static void main(String[] args) throws Exception {
//在构建转换流时需要传入一个OutputStream 字节流
OutputStreamWriter ow =
new OutputStreamWriter(
new FileOutputStream("D:\\b.txt"),"utf-8");
//给定字符--> OutputStreamWriter转化为字节-->以字节流形式传入文件FileOutputStream
//如果没有指定编码,默认使用当前工程的编码
ow.write("天乔巴夏");
ow.close();
}
最终与文件接触的是字节流,意味着将传入的字符转换为字节。
- InputStreamReader
public static void main(String[] args) throws IOException {
//以字节形式FileInputStream读取,经过转换InputStreamReader -->字符
//如果没有指定编码。使用的是默认的工程的编码
InputStreamReader ir =
new InputStreamReader(
new FileInputStream("D:\\b.txt"));
char[] cs = new char[5];
int len;
while((len=ir.read(cs))!=-1){
System.out.println(new String(cs,0,len));
}
ir.close();
}
最初与文件接触的是字节流,意味着将读取的字节转化为字符。
适配器设计模式
缓冲流基于适配器设计模式,将某个类的接口转换另一个用户所希望的类的接口,让原本由于接口不兼容而不能在一起工作的类可以在一起进行工作。
以OutputStreamWriter为例,构建该转换流时需要传入一个字节流,而写入的数据最开始是由字符形式给定的,也就是说该转换流实现了从字符向字节的转换,让两个不同的类在一起共同办事。
标准流/系统流
程序的所有输入都可以来自于标准输入,所有输出都可以发送到标准输出,所有错误信息都可以发送到标准错误。
标准流分类
| 对象 | 解释 | 封装类型 |
|---|---|---|
| System.in | 标准输入流 | InputStream |
| System.out | 标准输出流 | PrintStream |
| System.err | 标准错误流 | PrintStream |
可以直接使用System.out和System.err,但是在读取System.in之前必须对其进行封装,例如我们之前经常会使用的读取输入:Scanner sc = new Scanner(System.in);实际上就封装了System.in对象。
- 标准流都是字节流。
- 标准流对应的不是类而是对象。
- 标准流在使用的时候不用关闭。
/**
* 从控制台获取一行数据
* @throws IOException readLine 可能会抛出异常
*/
public static void getLine() throws IOException {
//获取一行字符数据 -- BufferedReader
//从控制台获取数据 -- System.in
//System是字节流,BufferedReader在构建的时候需要传入字符流
//将字节流转换为字符流
BufferedReader br =
new BufferedReader(
new InputStreamReader(System.in));
//接收标准输入并转换为大写
String str = br.readLine().toUpperCase();
//发送到标准输出
System.out.println(str);
}
通过转换流,将System.in读取的标准输入字节流转化为字符流,发送到标准输出,打印显示。
打印流
打印流只有输出流没有输入流
- PrintStream: 打印字节流
public static void main(String[] args) throws IOException {
//创建PrintStream对象
PrintStream p = new PrintStream("D:\\b.txt");
p.write("abc".getBytes());
p.write("def".getBytes());
p.println("abc");
p.println("def");
//如果打印对象,默认调用对象身上的toString方法
p.println(new Object());
p.close();
}
- PrintWriter:打印字符流
//将System.out转换为PrintStream
public static void main(String[] args) {
//第二个参数autoFlash设置为true,否则看不到结果
PrintWriter p = new PrintWriter(System.out,true);
p.println("hello,world!");
}
合并流
SequenceInputStream用于将多个字节流合并为一个字节流的流。- 有两种构建方式:
- 将多个合并的字节流放入一个
Enumeration中来进行。 - 传入两个
InputStream对象。
- 将多个合并的字节流放入一个
- 合并流只有输入流没有输出流。
以第一种构建方式为例,我们之前说过,Enumeration可以通过Vector容器的elements方法创建。
public static void main(String[] args) throws IOException {
FileInputStream in1 = new FileInputStream("D:\\1.txt");
FileInputStream in2 = new FileInputStream("D:\\a.txt");
FileInputStream in3 = new FileInputStream("D:\\b.txt");
FileInputStream in4 = new FileInputStream("D:\\m.txt");
FileOutputStream out = new FileOutputStream("D:\\union.txt");
//准备一个Vector存储输入流
Vector<InputStream> v = new Vector<>();
v.add(in1);
v.add(in2);
v.add(in3);
v.add(in4);
//利用Vector产生Enumeration对象
Enumeration<InputStream> e = v.elements();
//利用迭代器构建合并流
SequenceInputStream s = new SequenceInputStream(e);
//读取
byte[] bs = new byte[10];
int len;
while((len = s.read(bs))!=-1){
out.write(bs,0,len);
}
out.close();
s.close();
}
序列化/反序列化流
- 序列化:将对象转化为字节数组的过程。
- 反序列化:将字节数组还原回对象的过程。
序列化对象
创建一个Person类。
//必须实现Serializable接口
class Person implements Serializable {
//序列化ID serialVersionUID
private static final long serialVersionUID = 6402392549803169300L;
private String name;
private int age;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
创建序列化流,将对象转化为字节,并写入"D:\1.data"。
public class ObjectOutputStreamDemo {
public static void main(String[] args) throws IOException {
Person p = new Person();
p.setAge(18);
p.setName("Niu");
//创建序列化流
//真正将数据写出的流是FileOutputStream
//ObjectOutputStream将对象转化为字节
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("D:\\1.data"));
out.writeObject(p);
out.close();
}
}
创建反序列化流,将从"D:\1.data"中读取的字节转化为对象。
public static void main(String[] args) throws IOException, ClassNotFoundException {
//创建反序列化流
//真正读取文件的是FileInputStream
//ObjectInputStream将读取的字节转化为对象
ObjectInputStream in = new ObjectInputStream(new FileInputStream("D:\\1.data"));
//读取数据必须进行数据类型的强制转换
Person p = (Person)in.readObject();
in.close();
System.out.println(p.getName());//Niu
System.out.println(p.getAge());//18
}
需要注意的是:
- 如果一个对象要想被序列化,那么对应的类必须实现接口
serializable,该接口没有任何方法,仅仅作为标记使用。 - 被
static或transient修饰的属性不会进行序列化。如果属性的类型没有实现serializable接口但是也没有用这两者修饰,会抛出NotSerializableException。 - 在对象序列化的时候,版本号会随着对象一起序列化出去,在反序列化的时候,对象中的版本号和类中的版本号进行比较,如果版本号一致,则允许反序列化。如果不一致,则抛出
InvalidClassException。 - 集合允许被整体序列化 集合及其中元素会一起序列化出去。
关于版本号:
一个类如果允许被序列化,那么这个类中会产生一个版本号
serialVersionUID。- 如果没有手动指定版本号,那么在编译的时候自动根据当前类中的属性和方法计算一个版本号,也就意味着一旦类中的属性发生改变,就会重新计算新的,导致前后不一致。
- 但是,手动指定版本号的好处就是,不需要再计算版本号。
版本号的意义在于防止类产生改动导致已经序列化出去的对象无法反序列化回来。版本号必须用
static final修饰,本身必须是long类型。
写在最后:如果本文有叙述错误之处,还望评论区批评指正,共同进步。
参考资料:《Java 编程思想》、《Java语言程序设计》、《大话设计模式》
小白学Java:I/O流的更多相关文章
- 小白学Java:RandomAccessFile
目录 小白学Java:RandomAccessFile 概述 继承与实现 构造器 模式设置 文件指针 操作数据 读取数据 read(byte b[])与read() 追加数据 插入数据 小白学Java ...
- 小白学Java:包装类
目录 小白学Java:包装类 包装类的继承关系 创建包装类实例 自动装箱与拆箱 自动装箱 自动拆箱 包装类型的比较 "=="比较 equals比较 自动装箱与拆箱引发的弊端 自动装 ...
- 小白学Java:老师!泛型我懂了!
目录 小白学Java:老师!泛型我懂了! 泛型概述 定义泛型 泛型类的定义 泛型方法的定义 类型变量的限定 原生类型与向后兼容 通配泛型 非受限通配 受限通配 下限通配 泛型的擦除和限制 类型擦除 类 ...
- 小白学Java:迭代器原来是这么回事
目录 小白学Java:迭代器原来是这么回事 迭代器概述 迭代器设计模式 Iterator定义的方法 迭代器:统一方式 Iterator的总结 小白学Java:迭代器原来是这么回事 前文传送门:Enum ...
- 小白学Java:奇怪的RandomAccess
目录 小白学Java:奇怪的RandomAccess RandomAccess是个啥 forLoop与Iterator的区别 判断是否为RandomAccess 小白学Java:奇怪的RandomAc ...
- 小白学Java:内部类
目录 小白学Java:内部类 内部类的分类 成员内部类 局部内部类 静态内部类 匿名内部类 内部类的继承 内部类有啥用 小白学Java:内部类 内部类是封装的一种形式,是定义在类或接口中的类. 内部类 ...
- 小白学Java:File类
目录 小白学Java:File类 不同风格的分隔符 绝对与相对路径 File类常用方法 常用构造器 创建方法 判断方法 获取方法 命名方法 删除方法 小白学Java:File类 我们可以知道,存储在程 ...
- 【重学Java】Stream流
Stream流 体验Stream流[理解] 案例需求 按照下面的要求完成集合的创建和遍历 创建一个集合,存储多个字符串元素 把集合中所有以"张"开头的元素存储到一个新的集合 把&q ...
- 【重学Java】IO流
IO流的UML类图 File类 File类概述和构造方法[应用] File类介绍 它是文件和目录路径名的抽象表示 文件和目录是可以通过File封装成对象的 对于File而言,其封装的并不是一个真正存在 ...
随机推荐
- Android TextView调用Settext()耗时的原因
当textview的宽设置为wrap_content的时候,底层会调用checkForRelayout函数,这个函数根据文字的多少重新开始布局 因此将宽度设置为固定值或者match_parent的时候 ...
- 【Docker】初识与应用场景认知
什么是Docker? Docker是一个容器化平台,它以容器的形式将您的应用程序及其所有依赖项打包在一起,以确保您的应用程序在任何环境中无缝运行. 什么是Docker容器? Docker容器包括应用程 ...
- FCKeditor使用
fckeditor - (1)资料介绍与安装 fckeditor介绍 FCKeditor是一个专门使用在网页上属于开放源代码的所见即所得文字编辑器. 1.fckeditor官网:http://ww ...
- 什么时候用for循环什么时候用while循环?
简述 for循环和while循环最大的区别在于[循环的工作量是否确定],for循环就像空房间依次办理业务,直到把[所有工作做完]才下班.但while循环就像哨卡放行,[满足条件就一直工作],直到不满足 ...
- Deep Learning ——Yann LeCun,Yoshua Bengio&Geoffrey Hinton
引言: 深度学习的本质是用多层的神经网络找到一个可以被学习的复杂的函数实现语音识别,图像识别等功能. 多层神经网络的结构: 多层神经元的组成,每一层的输入都等于上一层的输出. 应用领域:cv,nlp ...
- tag的使用
tag = True while tag: print("level") choice = input("level>>>").strip() ...
- 适配器模式 iOS
前言: 最近需求作一个公共空间的需求,最后决定用适配器模式来做. 首先,需求是什么? 在我们app中,会有很多列表,tableviewcell的样式会比较统一(当然,我之前在公司那个app不算很大,基 ...
- DEVOPS技术实践_03:Jenkins自动构建
一.提交代码自动构建 当开发人员在gitlab提交代码后,会自动触发jenkin构建 点击项目---->点击diy_maven-TEST----->点击配置--->构建触发器---- ...
- 钱包开发经验分享:ETH篇
# 钱包开发经验分享:ETH篇 [TOC] ## 开发前的准备 > 工欲善其事,必先利其器 一路开发过来,积累了一些钱包的开发利器和网站,与大家分享一下.这些东西在这行开发过的人都知道,只是给行 ...
- c++ beep 演奏一次质量不高的天空之城
beep函数用法: beep(HZ,time); hz是发出多少赫兹声音,time是发声时间(ms) 话不多说,上代码 #include <cstdio> #include <win ...