从零构建Flink SQL计算平台 - 1平台搭建
一、理想与现实
Apache Flink 是一个分布式流批一体化的开源平台。Flink 的核心是一个提供数据分发、通信以及自动容错的流计算引擎。Flink 在流计算之上构建批处理,并且原生的支持迭代计算,内存管理以及程序优化。
实时计算(Alibaba Cloud Realtime Compute,Powered by Ververica)是阿里云提供的基于 Apache Flink 构建的企业级大数据计算平台。在 PB 级别的数据集上可以支持亚秒级别的处理延时,赋能用户标准实时数据处理流程和行业解决方案;支持 Datastream API 作业开发,提供了批流统一的 Flink SQL,简化 BI 场景下的开发;可与用户已使用的大数据组件无缝对接,更多增值特性助力企业实时化转型。
Apache Flink 社区迎来了激动人心的两位数位版本号,Flink 1.10.0 正式宣告发布!作为 Flink 社区迄今为止规模最大的一次版本升级,Flink 1.10 容纳了超过 200 位贡献者对超过 1200 个 issue 的开发实现,包含对 Flink 作业的整体性能及稳定性的显著优化、对原生 Kubernetes 的初步集成以及对 Python 支持(PyFlink)的重大优化。
Flink 1.10 同时还标志着对 Blink的整合宣告完成,随着对 Hive 的生产级别集成及对 TPC-DS 的全面覆盖,Flink 在增强流式 SQL 处理能力的同时也具备了成熟的批处理能力。
在过去的2019年,大数据领域的Flink异常火爆,从年初阿里巴巴高调收购Flink的母公司,到秋天发布的1.9以及最近的1.10版本完成整合阿里Blink分支,各类分享文章和一系列国内外公司应用案例,都让人觉得Flink是未来大数据领域统一计算框架的趋势。尤其是看过阿里云上的实时计算平台,支持完善的SQL开发和批流都能处理的模式让人印(直)象(流)深(口)刻(水)。但是相对于公有云产品,稍微有点规模的公司都更愿意使用开源产品搭建自己的平台,可是仔细研究Flink的官方文档和源码,准备撸起袖子开干时,才发现理想和现实的差距很大……
首先是阿里实时计算平台产品的SQL开发界面:
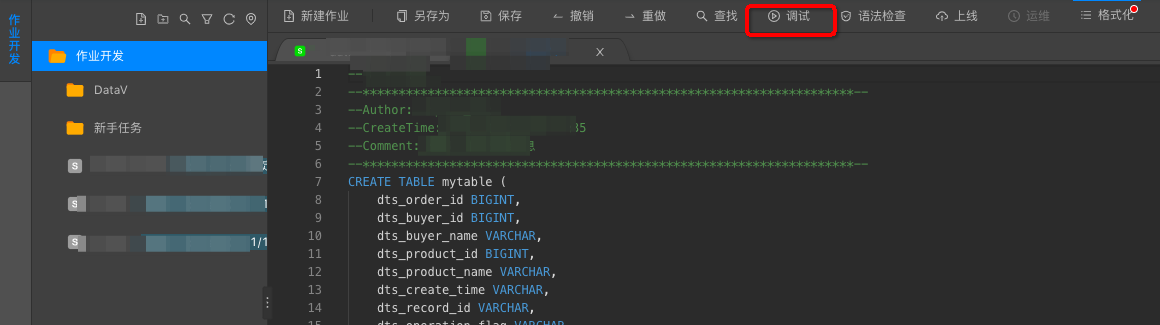
然而现实中Flink所支持的SQL开发API是这样的:
// create a TableEnvironment for specific planner batch or streaming
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// register a Table
tableEnv.registerTable("table1", ...) // or
tableEnv.registerTableSource("table2", ...); // or
tableEnv.registerExternalCatalog("extCat", ...);
// register an output Table
tableEnv.registerTableSink("outputTable", ...);
// create a Table from a Table API query
Table tapiResult = tableEnv.scan("table1").select(...);
// create a Table from a SQL query
Table sqlResult = tableEnv.sqlQuery("SELECT ... FROM table2 ... ");
// emit a Table API result Table to a TableSink, same for SQL result
tapiResult.insertInto("outputTable");
// execute
tableEnv.execute("jobName");
最后翻遍Flink文档发现提供了一个实验性质的命令行SQL客户端:
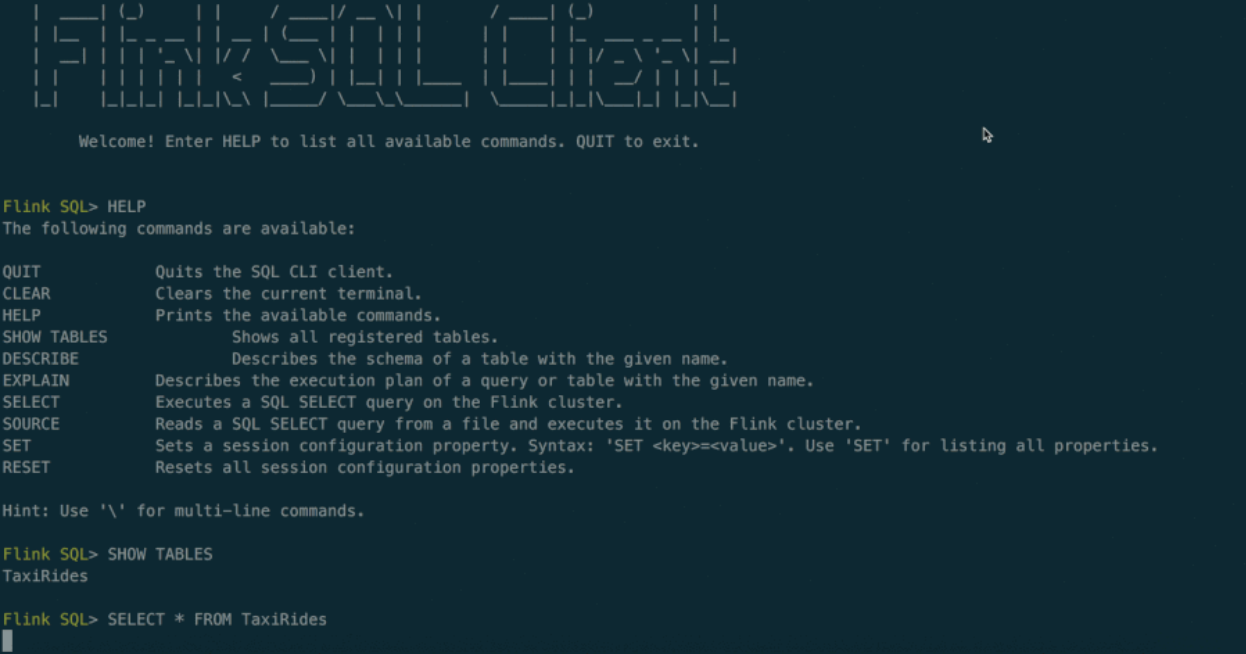
此外当我们用开源Flink代码部署一套集群后,整个集群有 JobManager 和 TaskManager 两种角色,其中 JobManager 提供了一个简单的管理界面,提供了上传Jar包执行任务的功能,以及一些简单监控界面,此外还提供一系列管理和监控的 Rest Api,可惜都没有和SQL层面直接相关的东西。
之所以有这一系列理想与现实的差异,是因为Flink更多的定位在计算引擎,在开发界面等方面暂时投入较少,但是每写一个SQL然后嵌入到代码中编译成JAR包上传到Flink集群执行是客(小)户(白)所不能接受的,这也就需要我们自己开发一套以SQL作业为中心的管理平台(对用户暴露的web系统),由该平台管理 Flink 集群,共同构成 Flink SQL 计算平台。
二、平台功能梳理
一个完整的SQL平台在产品流程上至少(第一版)需要有以下部分。
SQL作业管理:新增、调试、提交、下线SQL任务
数据源和维表管理:用DDL创建数据源表,其中维表也是一种特殊数据源
数据汇管理:用DDL创建数据结果表,即 insert into 结果表 select xxx
UDF管理:上传UDF的jar包
调度和运维:任务定时上下线、任务缩容扩容、savepoint管理
监控:日志查看、指标采集和记录、报警管理
其他:角色和权限管理、文档帮助等等……
除了作为Web系统需要的一系列增删改查和交互展示功能外,大部分Flink集群管理功能可以通过操作Flink集群提供的Rest接口实现,但是其中没有SQL相关内容,也就是前面四项功能(提交SQL、DDL、UDF,后文统称提交作业部分)都需要自己实现和 Flink 的交互代码,因此如何更好地提交作业就成了构建该平台的第一个挑战。
从零构建Flink SQL计算平台 - 1平台搭建的更多相关文章
- OPPO数据中台之基石:基于Flink SQL构建实数据仓库
小结: 1. OPPO数据中台之基石:基于Flink SQL构建实数据仓库 https://mp.weixin.qq.com/s/JsoMgIW6bKEFDGvq_KI6hg 作者 | 张俊编辑 | ...
- Demo:基于 Flink SQL 构建流式应用
Flink 1.10.0 于近期刚发布,释放了许多令人激动的新特性.尤其是 Flink SQL 模块,发展速度非常快,因此本文特意从实践的角度出发,带领大家一起探索使用 Flink SQL 如何快速构 ...
- 使用flink Table &Sql api来构建批量和流式应用(3)Flink Sql 使用
从flink的官方文档,我们知道flink的编程模型分为四层,sql层是最高层的api,Table api是中间层,DataStream/DataSet Api 是核心,stateful Stream ...
- (二)基于商品属性的相似商品推荐算法——Flink SQL实时计算实现商品的隐式评分
系列随笔: (总览)基于商品属性的相似商品推荐算法 (一)基于商品属性的相似商品推荐算法--整体框架及处理流程 (二)基于商品属性的相似商品推荐算法--Flink SQL实时计算实现商品的隐式评分 ( ...
- Apache Flink SQL
本篇核心目标是让大家概要了解一个完整的 Apache Flink SQL Job 的组成部分,以及 Apache Flink SQL 所提供的核心算子的语义,最后会应用 TumbleWindow 编写 ...
- Flink SQL 如何实现数据流的 Join?
无论在 OLAP 还是 OLTP 领域,Join 都是业务常会涉及到且优化规则比较复杂的 SQL 语句.对于离线计算而言,经过数据库领域多年的积累,Join 语义以及实现已经十分成熟,然而对于近年来刚 ...
- [源码分析] 带你梳理 Flink SQL / Table API内部执行流程
[源码分析] 带你梳理 Flink SQL / Table API内部执行流程 目录 [源码分析] 带你梳理 Flink SQL / Table API内部执行流程 0x00 摘要 0x01 Apac ...
- [源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码生成 (修订版)
[源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码生成 (修订版) 目录 [源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码 ...
- Flink sql 之 TopN 与 StreamPhysicalRankRule (源码解析)
基于flink1.14的源码做解析 公司内有很多业务方都在使用我们Flink sql平台做TopN的计算,今天同事突然问到我,Flink sql 是怎么实现topN的 ? 蒙圈了,这块源码没看过啊 , ...
随机推荐
- 演示共享布局 Demonstrating Shared Layouts 精通ASP-NET-MVC-5-弗瑞曼 Listing 5-10
- 个人第四次作业——Alpha测试
Alpha项目测试 这个作业属于哪个课程 链接 这个作业要求在哪里 链接 团队名称 愿头发与你我同在 这个作业的目标 测试非本组的另外三组项目 姓名 张伟 学号 201731024216 测试报告 一 ...
- [CCPC2019 ONLINE]H Fishing Master
题意 http://acm.hdu.edu.cn/showproblem.php?pid=6709 思考 先考虑所有鱼的烹饪时间小于k的情况.将T从大到小排序后,煮一条鱼相当于将其时间补齐至k. 由于 ...
- Python3-ORM-Sqlalchemy
目录: ORM介绍 sqlalchemy安装 sqlalchemy基本使用 多外键关联 多对多关系 表结构设计作业 1. ORM介绍 orm英文全称object relational mapping, ...
- 关于基本布局之——Flex布局
Flex布局 1.Flex为"Flexible Box"的简称,即为弹性布局,可作用于任何容器上.给div这类块状元素元素设置display:flex或者给span这类内联元素设置 ...
- sqlserver 分页模糊查询
积少成多 ---- 仅以此致敬和我一样在慢慢前进的人儿 问题: 在sqlserver 进行模糊查询,出现问题 最初使用“concat”,进行拼串操作,如下所示: <select id = ...
- 共轭先验(conjugate prior)
共轭是贝叶斯理论中的一个概念,一般共轭要说是一个先验分布与似然函数共轭: 那么就从贝叶斯理论中的先验概率,后验概率以及似然函数说起: 在概率论中有一个条件概率公式,有两个变量第一个是A,第二个是B , ...
- ogg trail文件序列号不一致
一.Cause 在某些情况下,对于一个已经running的OGG进程,对已同步的数据(正确的同步或者错误的同步)做修改,修改完之后,需要保持一个一致点,从一致点继续同步. 这时需要人工干涉产生一个新的 ...
- MySQL5.6数据导入MySQL5.7报错:ERROR 1031 (HY000)
一.故障现象 今天将一个在MySQL5.7上的数据导入到MySQL5.6里面去,默认存储引擎都是InnoDB,导入报错如下: [root@oratest52 data]# mysql -uroot - ...
- c++中多文件的组织
参考书目:visual c++ 入门经典 第七版 Ivor Horton著 第八章 根据书中例子学习使用类的多文件项目. 首先要将类CBox定义成一个连贯的整体,在CBox.H文件中写入相关的类定义, ...