Apache Spark技术实战之6 --Standalone部署模式下的临时文件清理
问题导读
1.在Standalone部署模式下,Spark运行过程中会创建哪些临时性目录及文件?
2.在Standalone部署模式下分为几种模式?
3.在client模式和cluster模式下有什么不同?

概要
部署时的第三方依赖
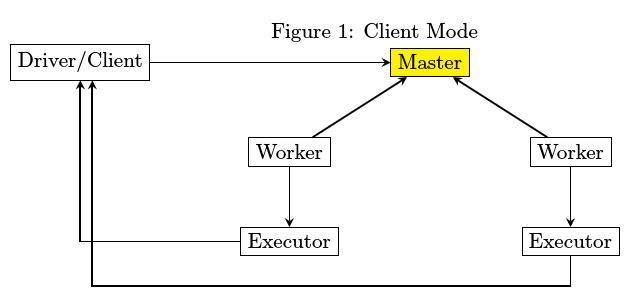
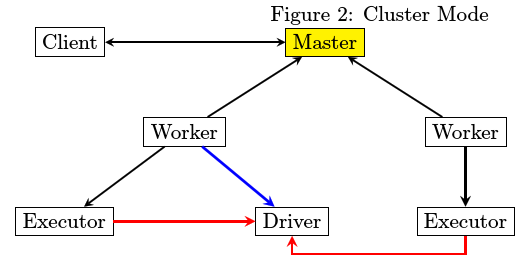 spark访问cassandra
spark访问cassandra
- Master进程最为简单,除了spark jar包之外,不存在第三方库依赖
- Driver和Executor在运行的时候都有可能存在第三方包依赖,分开来讲
- Driver比较简单,spark-submit在提交的时候会指定所要依赖的jar文件从哪里读取
- Executor由worker来启动,worker需要下载Executor启动时所需要的jar文件,那么从哪里下载呢。
HttpFileServer存储第三方jar包,然后由worker从HttpFileServer来获取。为此HttpFileServer需要创建
相应的目录,而Worker也需要创建相应的目录。

实验1

运行中的临时文件
实验2:不进行RDD Cache

进入spark-shell之后运行
- spark-shell>sc.textFile(“README.md”).flatMap(l=>l.split(“ “)).map(w=>(w,1)).reduceByKey(_ + _).foreach(println)
复制代码
实验3: 进行RDD Cache
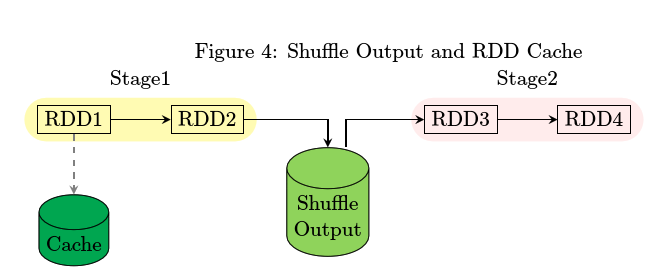
- spark-shell>val rdd1 = sc.textFile(“README.md”).flatMap(l=>l.split(“ “)).map(w=>(w,1)).reduceByKey(_ + _)
- spark-shell> rdd1.persist(MEMORY_AND_DISK_SER)
- spark-shell>rdd1.foreach(println)
复制代码
配置项
文件的清理
下的产生的文件夹,确实会在应用程序退出的时候自动清理掉,如果观察仔细的话,还会发现在spark_local_dirs目录有有诸如*_cache
和*_lock的文件,它们没有被自动清除。这是一个BUG,可以会在spark 1.3中加以更正。有关该BUG的具体描述,参考spark-4323
https://issues.apache.org/jira/browse/SPARK-4323
下的*_cache文件是为了避免同一台机器中多个executor执行同一application时多次下载第三方依赖的问题而引进的patch,详见
JIRA case spark-2713. 对就的代码见spark/util/Utils.java中的fetchFile函数。https://issues.apache.org/jira/browse/SPARK-2713
- find $SPARK_LOCAL_DIRS -max-depth 1 -type f -mtime 1 -exec rm -- {} \;
复制代码
而SPARK_WORK_DIR目录下的形如app-timestamp-seqid的文件夹默认不会自动清除。
那么可以设置哪些选项来自动清除已经停止运行的application的文件夹呢?当然有。
在spark-env.sh中加入如下内容
- SPARK_WORKER_OPTS=”-Dspark.worker.cleanup.enabled=true”
复制代码
实验4
- import org.apache.spark._
- import org.apache.spark.{SparkConf, SparkContext}
- import org.apache.spark.SparkContext._
- import java.util.Date
- object HelloApp {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf()
- val sc = new SparkContext()
- val fileName = "$SPARK_HOME/README.md"
- val rdd1 = sc.textFile(fileName).flatMap(l => l.split(" ")).map(w => (w, 1))
- rdd1.reduceByKey(_ + _).foreach(println)
- var i: Int = 0
- while ( i < 10 ) {
- Thread.sleep(10000)
- i = i + 1
- }
- }
- }
复制代码
提交运行
- spark-submit –class HelloApp –master spark://127.0.0.1:7077 --deploy-mode cluster HelloApp.jar
复制代码
小结
相关文章
Spark技术实战之1 -- KafkaWordCount
http://www.aboutyun.com/thread-9580-1-1.html
Spark技术实战之2 -- Spark Cassandra Connector的安装和使用
http://www.aboutyun.com/thread-9582-1-1.html
Spark技术实战之3 -- 利用Spark将json文件导入Cassandra
http://www.aboutyun.com/thread-9583-1-1.html
Apache Spark技术实战之4 -- SparkR的安装及使用
http://www.aboutyun.com/thread-10082-1-1.html
Apache Spark技术实战之5 -- spark-submit常见问题及其解决
http://www.aboutyun.com/thread-10083-1-1.html
Apache Spark技术实战之6 --Standalone部署模式下的临时文件清理
http://www.aboutyun.com/thread-11862-1-1.html
http://www.tuicool.com/articles/RV3MFz
Apache Spark技术实战之6 --Standalone部署模式下的临时文件清理的更多相关文章
- Apache Spark技术实战之8:Standalone部署模式下的临时文件清理
未经本人同意严禁转载,徽沪一郎. 概要 在Standalone部署模式下,Spark运行过程中会创建哪些临时性目录及文件,这些临时目录和文件又是在什么时候被清理,本文将就这些问题做深入细致的解答. 从 ...
- Apache Spark源码走读之15 -- Standalone部署模式下的容错性分析
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文就standalone部署方式下的容错性问题做比较细致的分析,主要回答standalone部署方式下的包含哪些主要节点,当某一类节点出现问题时,系统是如 ...
- Apache Spark技术实战之4 -- 利用Spark将json文件导入Cassandra
欢迎转载,转载请注明出处. 概要 本文简要介绍如何使用spark-cassandra-connector将json文件导入到cassandra数据库,这是一个使用spark的综合性示例. 前提条件 假 ...
- Apache Spark技术实战之3 -- Spark Cassandra Connector的安装和使用
欢迎转载,转载请注明出处,徽沪一郎. 概要 前提 假设当前已经安装好如下软件 jdk sbt git scala 安装cassandra 以archlinux为例,使用如下指令来安装cassandra ...
- Apache Spark技术实战之9 -- 日志级别修改
摘要 在学习使用Spark的过程中,总是想对内部运行过程作深入的了解,其中DEBUG和TRACE级别的日志可以为我们提供详细和有用的信息,那么如何进行合理设置呢,不复杂但也绝不是将一个INFO换为TR ...
- Apache Spark技术实战之6 -- spark-submit常见问题及其解决
除本人同意外,严禁一切转载,徽沪一郎. 概要 编写了独立运行的Spark Application之后,需要将其提交到Spark Cluster中运行,一般会采用spark-submit来进行应用的提交 ...
- Apache Spark技术实战之1 -- KafkaWordCount
欢迎转载,转载请注明出处,徽沪一郎. 概要 Spark应用开发实践性非常强,很多时候可能都会将时间花费在环境的搭建和运行上,如果有一个比较好的指导将会大大的缩短应用开发流程.Spark Streami ...
- Apache Spark技术实战之7 -- CassandraRDD高并发数据读取实现剖析
未经本人同意,严禁转载,徽沪一郎. 概要 本文就 spark-cassandra-connector 的一些实现细节进行探讨,主要集中于如何快速将大量的数据从cassandra 中读取到本地内存或磁盘 ...
- Apache Spark技术实战之5 -- SparkR的安装及使用
欢迎转载,转载请注明出处,徽沪一郎. 概要 根据论坛上的信息,在Sparkrelease计划中,在Spark 1.3中有将SparkR纳入到发行版的可能.本文就提前展示一下如何安装及使用SparkR. ...
随机推荐
- C#实现给图片加边框的方法
Bitmap bit= new Bitmap(@"" + Path);//给图片加边框 //Bitmap bit = new Bitmap(Screen.AllScreens[0] ...
- mysql数据表的基本操作
好久没梳理下Mysql基础命令了.今天抽空整理了下,虽然很简单...但是还是有必要巩固下基础滴啦 1.创建表:之前需要use database database_name 然后create table ...
- SpringBoot登录登出切面开发
阅读本文约“2.5分钟” 本文开发环境是SpringBoot2.X版本. 对于系统而言(这里多指管理系统或部分具备登录登出功能的系统),登录登出是一个类权限验证的过程,现在一般是以token进行校验, ...
- QueryRunner使用之可变条件的处理
在三层架构的Dao层中,需要通过不确定的条件,从数据库查询结果. 可以利用List集合作为容器将条件存储起来. 实际开发中的代码: public List<Hotel> searchByF ...
- webpack4 系列教程(十二):处理第三方JavaScript库
教程所示图片使用的是 github 仓库图片,网速过慢的朋友请移步<webpack4 系列教程(十二):处理第三方 JavaScript 库>原文地址.或者来我的小站看更多内容:godbm ...
- canvas学习笔记之2d画布基础的实现
一. Canvas是啥 < canvas > 是一个可以使用脚本(通常是js)来绘图的HTML元素 < canvas > 最早由Apple引入WebKit,用于Mac OS X ...
- angular 过滤器(日期转换,时间转换,数据转换等)
(function() { 'use strict'; /** * myApp Module * * Description */ angular.module('myApp') .filter('i ...
- JS怎样实现图片的懒加载以及jquery.lazyload.js的使用
在项目中有时候会用到图片的延迟加载,那么延迟加载的好处是啥呢? 我觉得主要包括两点吧,第一是在包含很多大图片长页面中延迟加载图片可以加快页面加载速度:第二是帮助降低服务器负担. 下面介绍一下常用的延迟 ...
- 照葫芦画瓢系列之Java --- Maven的配置
一.Maven仓库分类 Maven中,仓库只分为两类:本地仓库和远程仓库.当Maven根据坐标寻找构件的时候,它首先去查看本地仓库,如果本地仓库有此构件,则直接使用,如果本地仓库不存在此构件,或者需要 ...
- java设计模式之模板模式以及钩子方法使用
1.使用背景 模板方法模式是通过把不变行为搬到超类,去除子类里面的重复代码提现它的优势,它提供了一个很好的代码复用平台.当不可变和可变的方法在子类中混合在一起的时候, 不变的方法就会在子类中多次出现, ...