python3编写网络爬虫23-分布式爬虫
一、分布式爬虫
前面我们了解Scrapy爬虫框架的基本用法 这些框架都是在同一台主机运行的 爬取效率有限 如果多台主机协同爬取 爬取效率必然成倍增长
这就是分布式爬虫的优势
1. 分布式爬虫基本原理
1.1 分布式爬虫架构
Scrapy 单机爬虫中有一个本地爬取队列Queue 这个队列是利用 deque 模块实现的 如果新的 Request 生成就会放在队列里面 随后 Request被
Scheduler调度 之后 Request 交给 Downloader 执行爬取 简单的调度架构如图 单主机爬虫架构

如果两个 Scheduler同时从队列中取 Request 每个 Scheduler 都有其对应的 Downloader 那么在带宽足够 正常爬取且不考虑队列存取压力
的情况下 爬取效率会翻倍
这样 Scheduler 可以拓展多个 Downloader 也可以多拓展几个 而爬取队列Queue 必须始终为一 也就是所谓的 共享爬取队列 这样才能保证
Scheduler 从队列里调度某个 Request 之后其他 Scheduler 不会重复调度此 Request 就可以多个 Scheduler 同步爬取 这就是分布式爬虫的雏形
简单的调度架构如图 分布式爬虫架构
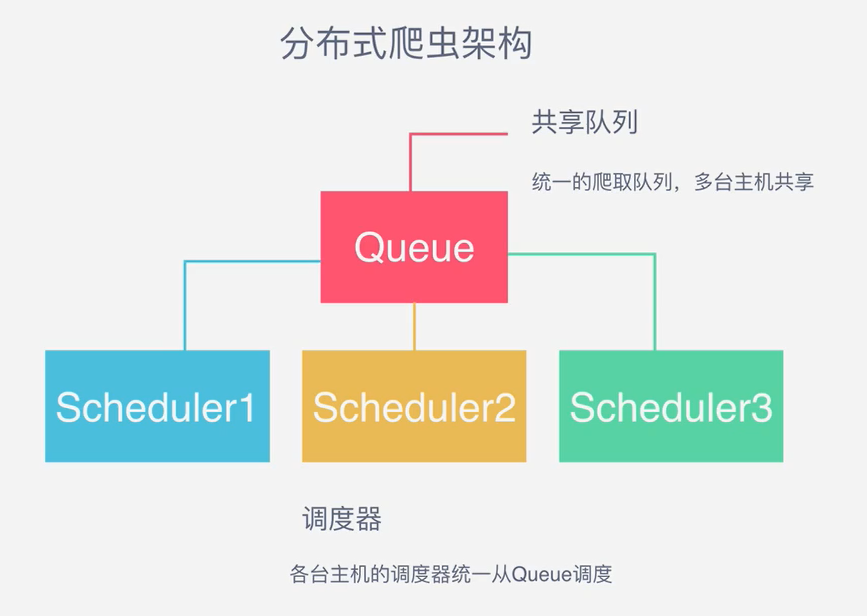
需要多台主机同时运行爬虫任务协同爬取 而协同爬取的前提就是共享爬取队列 这样各台主机就不要各自维护爬取队列 而从共享爬取队列存取
Request 但是各台主机还是与各自的 Scheduler 和 Downloader 所以调度和下载功能分别完成 不考虑队列存取性能消耗 爬取效率还是会成倍提高
如图 主机与从机

1.2 维护爬取队列
队列用什么维护 首先考虑的就是性能问题 基于内存存储的Redis 支持多种数据结构 例如 列表 集合 有序集合 等 存取操作也相对简单
redis 支持的这几种数据结构存储各有优点
列表 有 lpush() lpop() rpush() rpop() 方法 我们可以用它来实现先进先出式爬取队列 也可以实现先进后出栈式爬取队列
集合 元素是无序不重复的 可以非常方便的实现随机排序且不重复的爬取队列
有序集合 带有分数标识 而 Scrapy 的 Request 也有优先级的控制 可以用它来实现带优先级的调度队列
需要根据具体爬虫的需求灵活选择不同队列
1.3 如何去重
scrapy 有自动去重 使用了python中的集合 集合记录了 Scrapy中每个 Request的指纹
其内部使用的是hashlib 的 sha1 方法 计算的字段包括 Request 的 method URL Body Headers
这里面只要有一点不同 那么计算的结果就不同 计算得到的结果是加密后的字符串 也就是指纹
每个Request 都有独有的指纹 指纹就是一个字符串 判断字符串是否重复比判断 Request 对象是否重复容易的多
scrapy中实现
def __init__(self):
self.fingerprints = set() def request_seen(self,request):
fp = self.request_fingerprints(request)
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
对于分布式爬虫 肯定不能利用每个爬虫各自的集合来去重 这样做还是每个主机单独维护自己的集合 不能做到共享 多台主机
如果生成了相同的request 只能各自去重 各个主机之间就无法做到去重
redis集合
redis提供集合数据结构 在redis集合中存储每个 Request的指纹
在向 Request 队列中加入 Request 前首先验证这个 Request的指纹是否已经加入集合中
如果已存在 则不添加 Request到队列 如果不存在 则将 Request 添加入队列并将指纹加入集合
利用同样的原理 不同的存储结构 实现了分布式 Request的去重
1.4 防止中断
在 scrapy中 爬虫运行时的Request队列放在内存中 爬虫运行中断后 这个队列空间就被释放了 队列就被销毁了 所以爬虫一旦运行中断
爬虫再次运行就相当于全新的爬取过程
要做到中断后继续爬取 可以将队列保存起来 下次爬取 直接读取保存数据即可获取上次爬取队列 在scrapy中指定爬取队列存储路径即可
路径使用JOB_DIR变量标识 可以使用命令实现
scrapy crawl spider -s JOB_DIR=crawlS/spider
详细设置 参考官方文档 https://doc.scrapy.org/en/latest/topics/jobs.html
在 scrapy 实际把爬取队列保存到本地 第二次爬取直接读取并恢复队列 分布式中爬取队列本身就是数据库保存 如果中断了
数据库中request依然存在 下次启动就会接着上次中断的地方继续爬取
1.5 架构实现
实现这个架构 首先要实现共享的爬取队列 还要实现去重 重写 Scheduler 可以从共享爬取队列存储 Request
Scrapy-Redis 提供了分布式的队列 调度器 去重等功能 GitHub地址
https://github.com/rmax/scrapy-redis
2. Scrapy-Redis 源码解析
首先下载 源代码
核心源码在
scrapy-redis/src/scrapy_redis
2.1 爬取队列
源码文件为 queue.py
父类Base 中 _encode_request 和 _decode_request 分别可以实现序列化和反序列化
原因 把Request对象存储到数据库中 数据库无法直接存储对象 需要先将 Request 序列化转成字符串
父类中__len__ push pop 都是未实现的 直接使用会报异常
源码中有三个子类实现
FifoQueue 类 继承父类 重写三个方法 都是对server 对象的操作 此爬取队列使用了Redis的列表 序列化后的 Request存入列表中
push调用 lpush 从列表左侧存储数据 pop调用rpop 操作 从列表右侧取出数据
Request 在列表中存取顺序是 左侧进 右侧出 是有序的进出 先进先出
LifoQueue 类 与 FifoQueue相反 使用lpop操作 左侧出 push 依然使用lpush 左侧入 先进后出 后进先出 存取方式类似栈
PriorityQueue 类 优先级队列 存储结果是有序集合
2.2 去重过滤
源码文件 dupefilter.py
使用的是redis中的集合数据结构
request_seen 和 scrapy中 request_seen 方法类似 使用的是数据库存储方式
鉴别重复方式还是使用指纹 依靠request_fingerprint 方法获取 直接向集合添加指纹 添加成功返回1 表示指纹不存在集合中
代码中最后返回结果判定添加结果是否为0 如果返回1 判定false 不重复 否则判定重复
2.4 调度器
源码文件 scheduler.py
核心方法存取方法
enqueue_request向队列中添加 Request 调用 Queue 的push 操作 还有统计和日志操作
next_request 从队列取出 Request 调用 Queue 的pop操作 此队里中如果还有 Request 则直接取出 爬取继续 如果为空 爬取重新开始
总结
1.爬取队列的实现 提供三种队列 使用redis的列表或者集合来维护
2.去重的实现 使用redis集合来保存 Request 的指纹 提供重复过滤
3.中断就重新爬取的实现 中断后 reids的队列没有清空 爬取再次启动 调度器 next_request 会从队列中取到下一个 Request 爬取继续
以上就是 scrapy-redis中的源码解析 Scrapy-Redis还提供了 Spider Item Pipline 的实现 不过它们并不是必须使用
3.分布式爬虫实现
利用 Scrapy-Redis 实现分布式对接
需要安装 Scrapy-Redis pip install scrapy-redis
验证 import scrapy_redis 无报错表示安装成功
3.1 搭建 Redis服务器
要实现分布式部署 多台主机需要共享爬取队列和去重集合 而在两部分内容都是存于 Redis数据库中的 需要搭建一个公网访问的 Redis服务器
推荐使用Linux服务器 可以购买阿里云 腾讯云 等提供的云主机 一般都会配有公网IP
需要记录redis 的运行 IP 端口 地址
3.2 配置 Scrapy-Redis
修改 settings 配置文件
将调度器的类和去重类替换为 Scrapy-Redis 提供的类
SCHEDULER = 'scrapy_redis.scheduler.Scheduler'
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
配置redis连接信息
REDIS_URL = 'redis://password@host:port'
配置调度队列 (可选)
默认使用 PriorityQueue 可在 settings中修改
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
配置持久化 (可选)
默认false 会在爬取完成后 清空爬取队列 和去重指纹集合
SCHEDULER_PERSIST = True (不清空)
在强制中断爬虫运行时 不会自动清空
配置重爬 (可选)
默认false
SCHEDULER_FLUSH_ON_START = True #每次爬取后清空队列和指纹
单机爬虫 比较方便 分布式不常用
Pipline配置 (可选)
默认不启动 scrapy-redis 实现一个存储到 Redis 的 item pipeline 如果启用 爬虫会把生成的item 存储到 redis数据库中
数据量比较大的情况下一般不这么做 因为redis是基于内存的 利用它是处理速度快的特性 存储就太浪费了
ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipline:300',}
配置存储目标
可以在服务器搭建一个MongoDB 服务 存储目标放在同一个MongoDB中
配置修改
MONGO_URL = 'mongodb://user:password@host:port'
3.3 运行
将爬虫代码部署到各台主机 即可启动爬取
每台主机启动爬虫后 就会配置redis数据库中调度request 做到爬取队列共享和指纹集合共享 同时每台主机占用各自的带宽和处理器
不会互相影响。
拓展
scrapy-redis 的去重机制是占用内存的 指纹存储到redis集合中每个指纹长度40 每一位都是16进制
每个十六进制占用4b 一个指纹占用空间20B 一亿个占用2GB 爬取数量达到上亿级别时 redis占用的内存就会变的很大 仅仅只是指纹存储
还有队列存储的占用 如果多个Scrapy项目同时爬取 内存开销就是问题
了解 Bloom Filter 中文名布隆过滤器 检测元素是否在集合中 空间利用效率非常高 大大节省存储空间
使用位数组表示带检测集合 快速用概率算法判断一个元素是否在集合中 达到去重效果
初始状态下 声明一个包含m位的为数组 所有位都是0
有一个待检测集合 表示为 S={X1,X2,...Xn}需要检测X是否已经存在集合S中 在 Bloom Filter 算法中 首先使用K个相互独立 随机的散列函数
将集合S中的每个元素 X1,X2,...Xn 映射到长度为M的位数组上 散列函数得到结果记作位置索引 然后将位数组该位置索引的位置1
例如 取K为3 表示三个散列函数 X1经过三个散列函数映射得到 结果分别为 1,4,8, X2经过三个散列函数 映射得到结果分别为 4,6,10
位数组的 1,4,6,8,10 五位就会置1
如果有新的元素X 判断X是否在S集合 仍然用K个散列函数求X映射结果
如果所有结果对应的位数组位置均为1 那么X属于S集合 如果有一个不为1 则X不属于S集合
M,n,K 满足关系 M>nK 位数组的长度M要比集合元素n和散列函数K的乘积还要大
判断的方法很高效 可以解决Redis内存不足的问题
二、分布式爬虫的部署
将scrapy项目 放到各个主机运行时 可能采用文件上传或者GIT同步的方式 都需要各台主机都进行操作 如果有100台 1000台 工作量无法预计
1. scrapyd分布式部署
是一个运行Scrapy爬虫的服务程序提供了一系列HTTP接口 帮助部署 启动 停止 删除 爬虫程序 支持版本管理 同时可以管理多个爬虫任务
使用时需要调用接口 官方文档 https://scrapyd.readthedocs.io
daemonstatus.json 查看scrapyd服务和状态
addversion.json 部署 scrapy项目 打包Egg文件 传入项目名和版本
schedule.json 负责调度 scrapy项目运行
cancel.json 取消某个爬虫任务
listprojects.json 列出部署的项目描述
listversions.json 获取某个项目的所有版本
listspiders.json 获取某个项目的最新版本
listjobs.json 获取某个项目运行的所有任务详情
delversion.json 删除某个项目版本
delproject.json 删除某个项目
1.2版本后不会自动生成配置文件 需要手动添加 文件名scrapy.conf
内容配置 参考https://scrapyd.readthedocs.io/en/stable/config.html
2. scrapyd API的使用
对scrapyd的封装 官方文档 http://python-scrapyd-api.readthedocs.io
3. Scrapy-Client的使用
使用说明 https://github.com/scrapy/scrapyd-client#scrapyd-deploy
4. 云主机部署
很多服务商都提供云主机服务 例如 阿里云 腾讯云 Azure Amazon 等不同服务商提供了不同的批量部署云主机的方式。
python3编写网络爬虫23-分布式爬虫的更多相关文章
- Java 多线程爬虫及分布式爬虫架构探索
这是 Java 爬虫系列博文的第五篇,在上一篇 Java 爬虫服务器被屏蔽,不要慌,咱们换一台服务器 中,我们简单的聊反爬虫策略和反反爬虫方法,主要针对的是 IP 被封及其对应办法.前面几篇文章我们把 ...
- Java 多线程爬虫及分布式爬虫架构
这是 Java 爬虫系列博文的第五篇,在上一篇 Java 爬虫服务器被屏蔽,不要慌,咱们换一台服务器 中,我们简单的聊反爬虫策略和反反爬虫方法,主要针对的是 IP 被封及其对应办法.前面几篇文章我们把 ...
- python3编写网络爬虫20-pyspider框架的使用
二.pyspider框架的使用 简介 pyspider是由国人binux 编写的强大的网络爬虫系统 github地址 : https://github.com/binux/pyspider 官方文档 ...
- python3编写网络爬虫21-scrapy框架的使用
一.scrapy框架的使用 前面我们讲了pyspider 它可以快速的完成爬虫的编写 不过pyspider也有一些缺点 例如可配置化不高 异常处理能力有限对于一些反爬虫程度非常强的网站 爬取显得力不从 ...
- python3编写网络爬虫18-代理池的维护
一.代理池的维护 上面我们利用代理可以解决目标网站封IP的问题 在网上有大量公开的免费代理 或者我们也可以购买付费的代理IP但是无论是免费的还是付费的,都不能保证都是可用的 因为可能此IP被其他人使用 ...
- Python3编写网络爬虫12-数据存储方式五-非关系型数据库存储
非关系型数据库存储 NoSQL 全称 Not Only SQL 意为非SQL 泛指非关系型数据库.基于键值对 不需要经过SQL层解析 数据之间没有耦合性 性能非常高. 非关系型数据库可细分如下: 键值 ...
- python3编写网络爬虫19-app爬取
一.app爬取 前面都是介绍爬取Web网页的内容,随着移动互联网的发展,越来越多的企业并没有提供Web页面端的服务,而是直接开发了App,更多信息都是通过App展示的 App爬取相比Web端更加容易 ...
- Python3编写网络爬虫11-数据存储方式四-关系型数据库存储
关系型数据库存储 关系型数据库是基于关系模型的数据库,而关系模型是通过二维表保存的,所以它的存储方式就是行列组成的表.每一列是一个字段,每一行是一条记录.表可以看作某个实体的集合,而实体之间存在联系, ...
- python3编写网络爬虫22-爬取知乎用户信息
思路 选定起始人 选一个关注数或者粉丝数多的大V作为爬虫起始点 获取粉丝和关注列表 通过知乎接口获得该大V的粉丝列表和关注列表 获取列表用户信息 获取列表每个用户的详细信息 获取每个用户的粉丝和关注 ...
随机推荐
- SQL行转列:decode函数
前言 开发中我们经常会用到行转列,这里记录一下我在项目中实现行转列的思路.需求:报表模块,统计某机房机架的不同状态(1 空闲 2 预占 3 占用)的数量(真实需求更为复杂,这里只是讨论技术,简化一 ...
- TensorFlow(2)Softmax Regression
Softmax Regression Chapter Basics generate random Tensors Three usual activation function in Neural ...
- SpringBoot中异步请求和异步调用(看这一篇就够了)
原创不易,如需转载,请注明出处https://www.cnblogs.com/baixianlong/p/10661591.html,否则将追究法律责任!!! 一.SpringBoot中异步请求的使用 ...
- mapper代理方式开发
使用mapper代理方式开发: 需要编写mapper接口,UserMapper.java需要编写映射文件,UserMapper.xml需要遵循一些开发规范,mybatis便可以自动生成mapper接口 ...
- 弹性盒模型flex
一.flex flex是flexible box的缩写,意为“弹性布局”: 定义弹性布局 display:flex; box{ display:flex; } 二.基本定义 我只简单的说一下容器和项目 ...
- HTML5效果:Canvas 实现圆形进度条并显示数字百分比
实现效果 1.首先创建html代码 <canvas id="canvas" width="500" height="500" styl ...
- iframe 标签属性解读
iframe 元素会创建包含另外一个文档的内联框架(即行内框架)
- SAP MM 物料主数据MRP2 视图’Minimum Lot Size’字段
SAP MM 物料主数据MRP2 视图’Minimum Lot Size’字段 如下物料号,MRP2视图中,维护了最小采购量为500. MRP type : PD Lot size: EX Minim ...
- Vue项目用于Ios和Android端开发
起因 前公司商城App项目使用的是H5开发,有微信公众号.Ios和Android三个版本,H5版本是自己写的一套框架,已经用了有些年头了,承载不下不断涌现出的新需求.而Ios和Android端通过we ...
- 章节三、6-Getters-Setters和this关键字part02
一.如何在一个类中创建另外一个类的对象,然后用这个类的对象的引用来访问这个对象里面的成员,如下: //如何在一个类中创建另外一个类的对象,然后用这个类的对象的引用来访问这个对象里面的成员 Car bm ...