HBase的replication原理及部署
一、hbase replication原理
hbase 的复制方式是 master-push 方式,即主集群推的方式,主要是因为每个rs都有自己的WAL。 一个master集群可以复制给多个从集群,复制是异步的,运行集群分布在不同的地方,这也意味着从集群和主集群的数据不是完全一致的,它的目标就是最终一致性。
1. Replication 总体结构
我们直接引用社区的架构图如下,主集群的hlog中记录了所有针对table的变更(目前的ddl不同步),通过实时读取hlog中的entry来解析变更的数据然后发送到从集群中去。
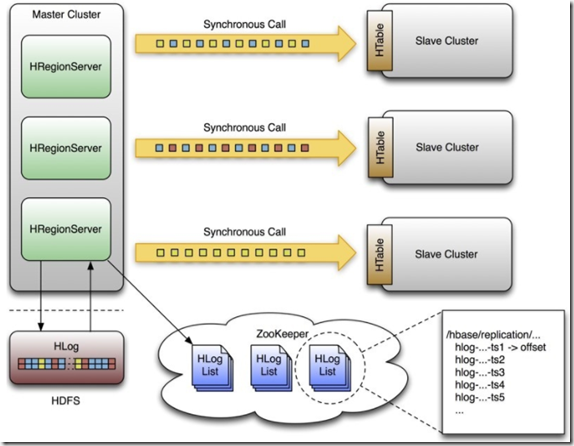
2. Replication 工作流程
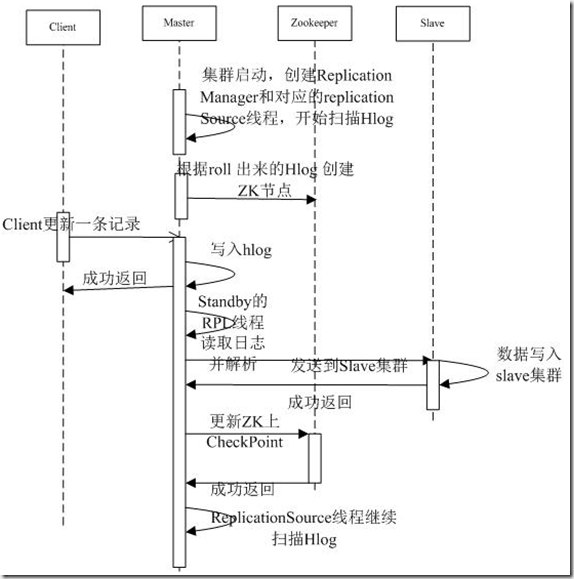
3. Replication Zookeeper上的结构
示例图如下(此图主要目的为展示结构,图中文字信息仅供参考,以下文解释说明部分为准):
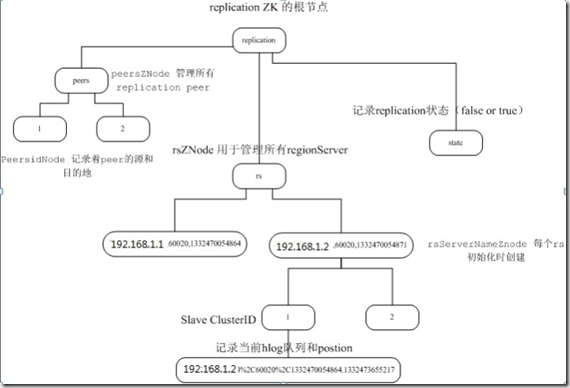
【解释说明】
hbase复制的状态都存储在zookeeper中,默认情况下存储到 /hbase/replication,这个目录有三个子节点: peers znode、rs znode和state。peer 节点管理slave集群在zk上的配置;state节点记录replication运行的状态;rs 节点记录着本集群rs中对应的hlog同步的信息,包括check point信息。(如果人为的删除 /hbase/replication 节点,会造成复制丢失数据)
peers znode:
存储在 zookeeper中/hbase/replication/peers 目录下,这里存储了所有的replication peers,还有他们的状态。peer的值是它的cluster的key,key包括了cluster的信息有: zookeeper,zookeeper port以及hbase在hdfs的目录。
/hbase/replication/peers/1 [Value: zk1.host.com,zk2.host.com,zk3.host.com:2181:/hbase]/2 [Value: zk5.host.com,zk6.host.com,zk7.host.com:2181:/hbase]
每个peer都有一个子节点,标示replication是否激活,这个节点没有任何子节点,只有一个boolean值。
/hbase/replication/peers/1/peer-state [Value: ENABLED]/2/peer-state [Value: DISABLED]
rs znode:
rs node包含了哪些WAL是需要复制的,包括:rs hostname,client port以及start code。
/hbase/replication/rs/hostname.example.org,6020,1234/hostname2.example.org,6020,2856
每一个rs znode包括一个WAL replication 队列,
/hbase/replication/rs/hostname.example.org,6020,1234/1/2
[说明] hostname.example.org的start code为1234的wal需要复制到peer 1和peer 2。
每一个队列都有一个znode标示每一个WAL上次复制的位置,每次复制的时候都会更新这个值。
/hbase/replication/rs/hostname.example.org,6020,1234/123522342.23422 [VALUE: 254]12340993.22342 [VALUE: 0]
二、replication的配置部署
1. 准备
既然是集群间的备份那么我们至少需要准备两个HBase集群来进行试验,并且需要满足:
- 集群间版本需要一致
- 集群间服务器需要互通
- 相关表及表结构在两个集群上存在且相同
2.启用replication步骤
1> HBase默认此特性是关闭的,需要在集群上(所有集群)进行设定并重启集群,通过手动修改或ambari界面管理在hbase-site.xml配置文件中将hbase.replication参数设定为true。
【参考】
master集群配置文件
<property><name>hbase.replication</name><value>true</value><description> 打开replication功能</description></property><property><name>replication.source.nb.capacity</name><value>5000</value><description> 主集群每次像备集群发送的entry最大的个数,推荐5000.可根据集群规模做出适当调整,slave集群服务器如果较多,可适当增大</description></property><property><name>replication.source.size.capacity</name><value>4194304</value><description> 主集群每次像备集群发送的entry的包的最大值大小,不推荐过大</description></property><property><name>replication.source.ratio</name><value>1</value><description> 主集群里使用slave服务器的百分比</description></property><property><name>hbase.regionserver.wal.enablecompression</name><value>false</value><description> 主集群关闭hlog的压缩</description></property><property><name> replication.sleep.before.failover</name><value>5000</value><description> 主集群在regionserver当机后几毫秒开始执行failover</description></property>
slave 集群配置文件
<property><name>hbase.replication</name><value>true</value><description> 打开replication功能</description></property>
2>在主/源集群上和从/目标集群上都新建表:
create 'usertable', 'family'
3>在主集群上设定需要向哪个集群上replication数据
add_peer:增加一个slave集群,一旦add,那么master集群就会向这个slave集群上replication那些在master集群上表列族制定了REPLICATION_SCOPE=>'1'的信息。
[Addpeer] hbase> add_peer '1',"zk1,zk2,zk3:2182:/hbase-prod" (zk的地址,端口和Slave的zk address)示例:add_peer '1','xufeng-1:2181:/hbase_backup' //重要#set_peer_tableCFs '1','usertable'
4>在主集群上打开表student的复制特性
disable 'usertable'alter 'usertable',{NAME => 'family',REPLICATION_SCOPE => '1'} //重要enable 'usertable'
5>测试replication功能
//上面配置好replication功能后,执行此三条命令会发现slave集群相应的跟着发生了相同变化put 'usertable','row1','family:info','zzzz'scan 'usertable',{STARTROW=>'row1',ENDROW=>'row1'}delete 'usertable','row1','family:info'
6>附:相关命令
shell环境为我们提供了很多方法去操作replication特性。
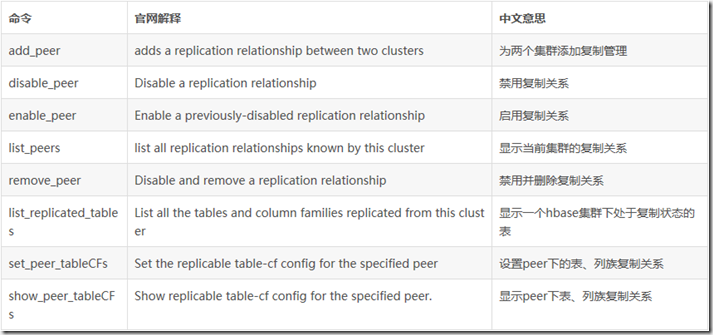
set_peer_tableCFs:重新设定想slave集群replication哪些表的哪些列族,只对列族REPLICATION_SCOPE=>'1'有效
show_peer_tableCFs:观察某个slave集群上呗replication的表和列族信息
append_peer_tableCFs:与set_peer_tableCFs相比是增量设定,不会覆盖原有信息。
remove_peer_tableCFs:与append_peer_tableCFs操作相反。
list_replicated_tables:列出在master集群上所有设定为REPLICATION_SCOPE=>'1'的信息
list_peers:显示当前master集群一共向哪些集群进行replication
hbase(main):009:0> list_peersPEER_ID CLUSTER_KEY STATE TABLE_CFS1 xufeng-1:2181:/hbase_backup ENABLED1 row(s) in 0.0110 seconds
disable_peer:停止向某个slave集群进行replication
hbase(main):010:0> disable_peer '1'0 row(s) in 0.0110 secondshbase(main):011:0> list_peersPEER_ID CLUSTER_KEY STATE TABLE_CFS1 xufeng-1:2181:/hbase_backup DISABLED1 row(s) in 0.0070 seconds
enable_peer:与disable_peer意义相反
hbase(main):031:0> enable_peer '1'0 row(s) in 0.0070 secondshbase(main):032:0> list_peersPEER_ID CLUSTER_KEY STATE TABLE_CFS1 xufeng-1:2181:/hbase_backup ENABLED1 row(s) in 0.0080 seconds
三、运维经验及遇到的问题
- replication不会根据实际插入的顺序来进行,只保证和master集群最终一致性。
- 所有对于replication的shell操作,只对列族为REPLICATION_SCOPE=>'1'才有效。
- 如果写入量较大,Slave 集群必须做好table 的region提前分配,防止写入全部落入1台服务器。
- 暂停服务和重新服务期间的数据还是可以被同步到slave中的,而停止服务和启动服务之间的数据不会被同步。也即同步是针对配置replication后复制的新数据,旧数据需要手动迁移
- 主集群对于同步的数据大小和个数采用默认值较大,容易导致备集群内存被压垮。建议配置减少每次同步数据的大小
replication.source.size.capacity4194304
replication.source.nb.capacity2000
- replication目前无法保证region级别的同步顺序性。需要在slave 集群需要打开KEEP_DELETED_CELLS=true,后续可以考虑在配置检测到属于slave集群就直接把这个值打开
- stop_replication后再start_replication,如果当前写的hlog没有滚动,停止期间的日志会被重新同步过去,类似的如果stop replication后进行了rollhlog操作(手动或重启集群),重新startreplication,新写入的数据不能被马上动态同步过去,需要再rollhlog一次。
- replication.source.ratio 默认值为0.1,这样导致slave集群里只有10%对外提供转发服务,导致这一台压力过大,建议测试环境将此值改为1。
- 目前replication 对于压缩的hlog的wal entry 无法解析,导致无法同步配置压缩hlog 集群的数据。这是有数据字典引起的,目前建议主集群中的配置hbase.regionserver.wal.enablecompression设false。
- 不要长时间使得集群处于disable状态,这样hlog会不停的roll后在ZK上增加节点,最终使得zk节点过多不堪重负。
。。。。待修整完善
参考网址:
https://blog.csdn.net/shenliang1985/article/details/51420112(好)
https://www.cnblogs.com/ios123/p/6410986.html?utm_source=itdadao&utm_medium=referral
http://lib.csdn.net/article/hbase/43717
https://blog.csdn.net/baiyangfu_love/article/details/38682349
HBase的replication原理及部署的更多相关文章
- HBase高可用原理与实践
前言 前段时间有套线上HBase出了点小问题,导致该套HBase集群服务停止了2个小时,从而造成使用该套HBase作为数据存储的应用也出现了服务异常.在排查问题之余,我们不禁也在思考,以后再出现类似的 ...
- Hbase架构与原理
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就 ...
- Hbase架构与原理(转)
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”.就像Bigtable利 ...
- Hbase的架构原理、核心概念
Hbase的架构原理.核心概念 1.Hbase的表.行.列.列族 2.核心组件: Table和region Table在行的方向上分割为多个HRegion, 一个region由[startkey,en ...
- Flink 集群运行原理兼部署及Yarn运行模式深入剖析
1 Flink的前世今生(生态很重要) 原文:https://blog.csdn.net/shenshouniu/article/details/84439459 很多人可能都是在 2015 年才听到 ...
- HBase的概述和安装部署
一.HBase概述 1.HBase是Hadoop数据库,是一个分布式.可扩展的大数据存储. HBase是用于对大数据进行随机.实时读写访问的非关系型数据库,它的目标托管非常大的表——数十亿行N百万列. ...
- 架构师成长之路3.1-Cobber原理及部署
点击返回架构师成长之路 架构师成长之路3.1-Cobber原理及部署 Cobbler是一个Linux服务器安装的服务,可以通过网络启动(PXE)的方式来快速安装.重装物理服务器和虚拟机,同时还可以管理 ...
- HBase底层存储原理
HBase底层存储原理——我靠,和cassandra本质上没有区别啊!都是kv 列存储,只是一个是p2p另一个是集中式而已! 首先HBase不同于一般的关系数据库, 它是一个适合于非结构化数据存储的数 ...
- hbase高可用集群部署(cdh)
一.概要 本文记录hbase高可用集群部署过程,在部署hbase之前需要事先部署好hadoop集群,因为hbase的数据需要存放在hdfs上,hadoop集群的部署后续会有一篇文章记录,本文假设had ...
随机推荐
- pytorch 学习--60分钟入个门
pytorch视频教程 标量(Scalar)是只有大小,没有方向的量,如1,2,3等 向量(Vector)是有大小和方向的量,其实就是一串数字,如(1,2) 矩阵(Matrix)是好几个向量拍成一排合 ...
- ArcGis辅助编号(半自动)功能的插件式实现
应邀写了一个ArcGis(ArcMap更确切一些)的辅助编号功能,其实只要想通了实现逻辑,实现的过程蛮简单的.相比挨个儿点要素写进编号或者借助“按键精灵”写入,直接操作宿主真是爽快得不能自已.无图言屌 ...
- tensorflow---alexnet training (tflearn)
# 输入数据 import input_data mnist = input_data.read_data_sets("/tmp/data/", one_hot=True) imp ...
- Expression 生成 Lambda
public static event Func<Student, bool> myevent; public delegate void del(int i, int j); stati ...
- Linux top 命令详解
Top top 查看资源占用 top -p pid# 查看某个进程PID 的内存占用: PID:进程的ID USER:进程所有者 PR:进程的优先级别,越小越优先被执行 NInice:值 VIRT: ...
- 使用X.509数字证书加密解密实务(一)-- 证书的获得和管理
http://www.cnblogs.com/chnking/archive/2007/08/18/860983.html
- Python 13 简单项目-堡垒机
本节内容 项目实战:运维堡垒机开发 前景介绍 到目前为止,很多公司对堡垒机依然不太感冒,其实是没有充分认识到堡垒机在IT管理中的重要作用的,很多人觉得,堡垒机就是跳板机,其实这个认识是不全面的,跳板功 ...
- Mybatis(一)入门介绍
一.MyBatis的发展 MyBatis 是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation迁移到google code, 并且改名M ...
- 20165234 《Java程序设计》第六周学习总结
第六周学习总结 教材学习内容总结 第八章 常用实用类 String类 Java专门提供了用来处理字符序列的 String 类.String类在java.lang包中,由于 java.lang 包中的类 ...
- openstack Q版部署-----虚拟机创建(8)
一 .创建网络环境 环境变量生效一下 创建一个网络: openstack network create --share --external \ --provider-physical-network ...