SQL Server 深入解析索引存储(聚集索引)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/堆/聚集索引
概述
最近要分享一个课件就重新把这块知识整理了一遍出来,篇幅有点长,想要理解的透彻还是要上机实践。
聚集索引
--创建测试数据库
CREATE DATABASE Ixdata
GO
USE [Ixdata]
GO
---创建测试表
CREATE TABLE Orders
(ID INT PRIMARY KEY IDENTITY(1,1),
NAME CHAR(80)NOT NULL,
IDATE DATETIME NOT NULL DEFAULT(GETDATE())
);
GO
---插入1000条测试数据
DECLARE @ID INT=1
WHILE(@ID<=1000)
BEGIN
INSERT INTO Orders(NAME)VALUES('商品'+CONVERT(NVARCHAR(20),@ID))
SET @ID=@ID+1
END
GO
SELECT * FROM Orders
GO
分析新创建的表的页的信息
---显示跟踪标志的状态
DBCC TRACESTATUS ---开启跟踪标志
DBCC TRACEON(3604,2588)
--DBCC TRACEOFF(3604,2588)
---获取对象的数据页,结构:数据库、对象、显示
DBCC IND(Ixdata,Orders,-1)
/*
1:显示所有分页的信息,包括IAM分页,数据分页,所有存在的LOB分页和行溢出页,索引分页
-1: 显示所有IAM、数据分页、及指定对象上全部索引的索引分页.
-2: 显示指定对象的所有IAM分页
0:显示所有IAM、数据分页.
*/
DBCC IND的表结构

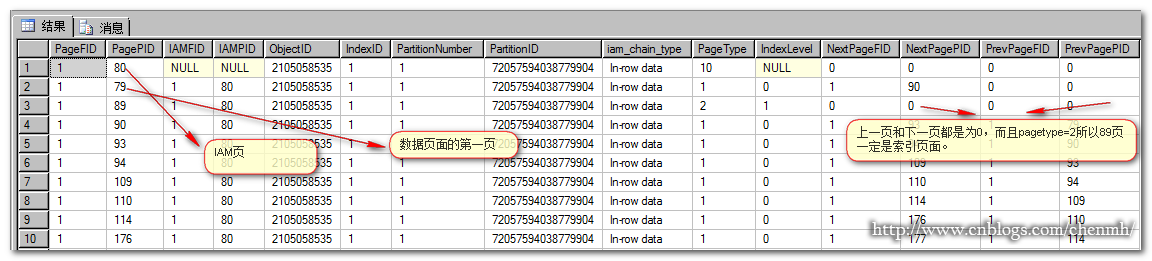
还可以通过另一种方法来测试:
SELECT DISTINCT so.name, so.object_id,i.name AS index_name,sp.index_id,internals.type_desc,internals.total_pages, internals.used_pages, internals.data_pages,first_iam_page, first_page, root_page
FROM sys.objects so
INNER JOIN sys.partitions sp ON so.object_id = sp.object_id
INNER JOIN sys.allocation_units sa ON sa.container_id = sp.hobt_id
INNER JOIN sys.system_internals_allocation_units internals ON internals.container_id = sa.container_id
LEFT JOIN sys.indexes i ON so.object_id=i.object_id AND sp.index_id=i.index_id
WHERE so.object_id = object_id('orders')

最后三个字段分别是IAM页,根页,和第一个数据页;它们分别用16进制来表示,拿first_iam_page来分析,首先将编码从右往左一个字节接着一个字节反过来排行(0X代表16进制),结果就是0X,00 01,00 00 00 50;前两个字节代表文件组号,最后4个字节代表页号。16进制的0001转换成10进制就是1;16进制的00 00 00 50转换成10进制就是5*16的1次方=5*16=80,所以第一个数据页是4*16+15=79,根页是5*16+9=89 结果和前面的查询出来的结果是一样的。从表格的otal_pages,used_pages,data_pages得到的结果也和前面查询出来的结果是一致的,总分配了17个页,使用了15个页包括13个数据页+1个IAM页+1个索引页。
手绘一张当前表格的聚集索引体系结构图:

分析索引页
---DBCC page的格式为(数据库,文件id,页号,显示)
DBCC page(Ixdata,1,89,3)

分析结果89页下面的子页总共有13页,每页80条记录,89索引页记录了每页的的键值的最小值,第一页就是id为1-80,第二页81-160,所以当你要找ID为150的数据的时候直接就可以去第90页里面找了。
PAGE HEADER

分析数据页

通过这些数据我们基本上可以知道90页的基本情况了,包括它的字段长度,上一页、下一页,还有该页的所以记录(这里没有截图出来).
插入20万条记录分析索引结构
--插入20万条记录分析索引结构
DECLARE @ID INT=1
WHILE(@ID<=200000)
BEGIN
INSERT INTO Orders(NAME)VALUES('商品'+CONVERT(NVARCHAR(20),@ID))
SET @ID=@ID+1
END CREATE TABLE Page
(
PageFID TINYINT,
PagePID INT,
IAMFID TINYINT,
IAMPID INT,
ObjectID INT,
IndexID TINYINT,
PartitionNumber TINYINT,
PartitionID BIGINT,
iam_chain_type VARCHAR(30),
PageType TINYINT,
IndexLevel TINYINT,
NextPageFID TINYINT,
NextPagePID INT,
PrevPageFID TINYINT,
PrevPagePID INT
);
GO
INSERT INTO Page EXEC('DBCC IND(Ixdata,Orders,-1)') ---查询索引页
SELECT [PageFID]
,[PagePID]
,[IAMFID]
,[IAMPID]
,[ObjectID]
,[IndexID]
,[PartitionNumber]
,[PartitionID]
,[iam_chain_type]
,[PageType]
,[IndexLevel]
,[NextPageFID]
,[NextPagePID]
,[PrevPageFID]
,[PrevPagePID]
FROM [Ixdata].[dbo].[Page]
WHERE PageType=2
go
select so.name, so.object_id, sp.index_id, internals.total_pages, internals.used_pages, internals.data_pages,first_iam_page,
first_page, root_page
from sys.objects so
inner join sys.partitions sp on so.object_id = sp.object_id
inner join sys.allocation_units sa on sa.container_id = sp.hobt_id
inner join sys.system_internals_allocation_units internals on internals.container_id = sa.container_id
where so.object_id = object_id('orders')
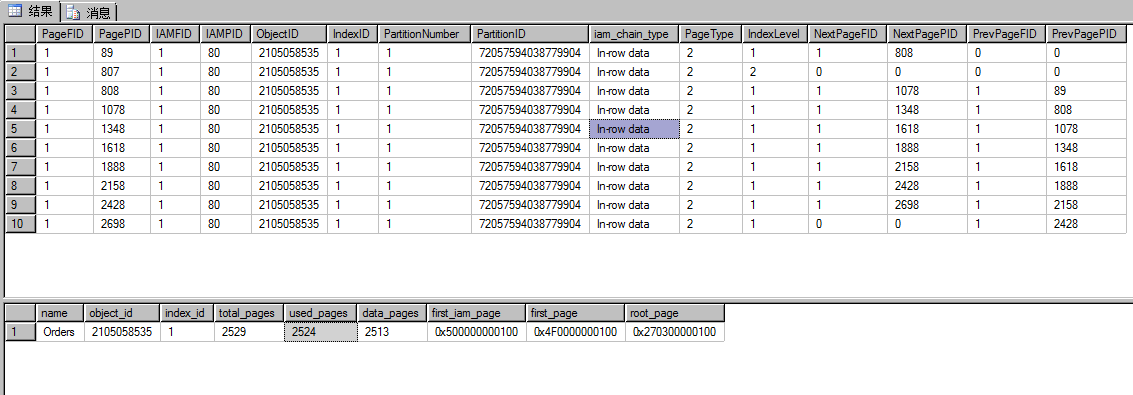
通过两种方法查询到的索引页的数量是一样的,下面的这种计算方法是2524-2513-1(IAM页)=10,其中807页是root_page页它在第二级,其它的是中间级索引页页就是第一级;页可以通过下面的16进制计算出来,IAM=5*16=80,ROOT_PAGE=3*16*16+2*16+7=807
再分析89页
---DBCC page的格式为(数据库,文件id,页号,显示)
DBCC page(Ixdata,1,89,3)
查询结果总共有269行,页就是269个数据页,orders表总共插入了201000条记录,一个页面存80条记录,就需要2513个页面和上面查询到的data_page是一样的。每个索引页存储269个数据页面就需要(‘select 2513*1.0/269’除不尽加1)10个索引页,查询最后一个索引页2698发现它还没分页共存储了361条记录,总共8*269+361=2513
手绘存储结构

手绘的有点难看,但是意思差不多表达出来了。
大型对象 (LOB) 列
根据聚集索引中的数据类型,每个聚集索引结构将有一个或多个分配单元,将在这些单元中存储和管理特定分区的相关数据。每个聚集索引的每个分区中至少有一个 IN_ROW_DATA 分配单元。如果聚集索引包含大型对象 (LOB) 列,则它的每个分区中还会有一个 LOB_DATA 分配单元。如果聚集索引包含的变量长度列超过 8,060 字节的行大小限制,则它的每个分区中还会有一个 ROW_OVERFLOW_DATA 分配单元。
---创建测试表
CREATE TABLE Orderslob
(ID INT PRIMARY KEY IDENTITY(1,1),
NAME CHAR(80)NOT NULL,
Product NVARCHAR(MAX) NOT NULL,
IDATE DATETIME NOT NULL DEFAULT(GETDATE())
);
GO
---插入1000条测试数据
DECLARE @ID INT=1
WHILE(@ID<=1000)
BEGIN
INSERT INTO Orderslob(NAME,Product)VALUES(CONVERT(NVARCHAR(20),@ID)+'商品',REPLICATE(@ID,2))
SET @ID=@ID+1
END
--REPLICATE(@ID,200)
GO DBCC IND(Ixdata,Orderslob,1)

--查看2719数据页的信息
DBCC page(Ixdata,1,2719,1)

结果记录了每一条记录的偏移量。
每个人在自己的电脑上面测试页面id会不一样,但是反应的结果是一样的。
总结
本来想全部写完的,等写完这部分的时候发现篇幅已经有点长了,而且自己也有的吃不消熬到1点才写完,接下来还有中下两部分会尽快在几天内写完,欢迎关注。
|
备注: 作者:pursuer.chen 博客:http://www.cnblogs.com/chenmh 本站点所有随笔都是原创,欢迎大家转载;但转载时必须注明文章来源,且在文章开头明显处给明链接,否则保留追究责任的权利。 《欢迎交流讨论》 |
SQL Server 深入解析索引存储(聚集索引)的更多相关文章
- SQL Server临界点游戏——为什么非聚集索引被忽略!
当我们进行SQL Server问题处理的时候,有时候会发现一个很有意思的现象:SQL Server完全忽略现有定义好的非聚集索引,直接使用表扫描来获取数据.我们来看看下面的表和索引定义: CREATE ...
- SQL SERVER 读书笔记:非聚集索引
对于有聚集索引的表,数据存储在聚集索引的叶子节点,而非聚集索引则存储 索引键值 和 聚集索引键值.对于非聚集索引,如果查找的字段没有包含在索引键值,则还要根据聚集索引键值来查找详细数据,此谓 Book ...
- sql server临时删除/禁用非聚集索引并重新创建加回/启用的简便编程方法研究对比
前言: 由于新型冠状病毒影响,博主(zhang502219048)在2020年1月份从广东广州工作地回到广东揭阳产业转移工业园磐东街道(镇里有阳美亚洲玉都.五金之乡,素以“金玉”闻名)老家后,还没过去 ...
- SQL Server中通过设置非聚集索引(Non-Clustered index)来达到性能优化的目的
首先我们一下,在SQL Server 2014 Management Studio中,如何为一张表设置Non-Clustered index 具体可以参考 https://docs.microsof ...
- SQL Server 深入解析索引存储(非聚集索引)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/非聚集索引 概述 非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点: 基础表的数据行不按非 ...
- SQL Server 深入解析索引存储(下)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/非聚集索引 概述 非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点: 基础表的数据行不按非 ...
- SQL Server 性能调优2 之索引(Index)的建立
前言 索引是关系数据库中最重要的对象之中的一个,他能显著降低磁盘I/O及逻辑读取的消耗,并以此来提升 SELECT 语句的查找性能.但它是一把双刃剑.使用不当反而会影响性能:他须要额外的空间来存放这些 ...
- SQL Server 2014新特性探秘(3)-可更新列存储聚集索引
简介 列存储索引其实在在SQL Server 2012中就已经存在,但SQL Server 2012中只允许建立非聚集列索引,这意味着列索引是在原有的行存储索引之上的引用了底层的数据,因此会 ...
- SQL Server索引 (原理、存储)聚集索引、非聚集索引、堆 <第一篇>
一.存储结构 在SQL Server中,有许多不同的可用排列规则选项. 二进制:按字符的数字表示形式排序(ASCII码中,用数字32表示空格,用68表示字母"D").因为所有内容都 ...
随机推荐
- 区间dp(入门题)
区间dp:顾名思义就是在区间上进行动态规划,通过合并小区间求解一段区间上的最优解. 常见模板: for(int len=1;len<n;len++){//区间长度 for(int be=1;be ...
- linux尝试登录失败后锁定用户账户的两种方法
linux尝试登录失败后锁定用户账户的两种方法 更新时间:2017年06月23日 08:44:31 作者:Carey 我要评论 这篇文章主要给大家分享了linux尝试登录失败后锁定用户账 ...
- 不常用但是很实用的css记录
本文主旨是记录一些不常用但是非常炫酷的css属性,提升用户体验的捷径之一. 1.background-attachment 滚动视差 https://codepen.io/Chokcoco/p ...
- CentOS7 安装VNC
系统环境:CentOS Linux release 7.6.1810Kernel:3.10.0-957.el7.x86_64系统现状:最小化安装,没有安装任何图形支持软件 安装图形化支持 不建议安装G ...
- nginx新增tcp模板
最近在装nginx时,发现新增了tcp模板,装了一遍,现记录下来过程. 1.下载nginx源码包,并解压 2.下载tcp模板压缩包https://github.com/yaoweibin/nginx_ ...
- Springmvc中@RequestMapping 属性用法归纳
简介: @RequestMapping RequestMapping是一个用来处理请求地址映射的注解,可用于类或方法上.用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径. RequestM ...
- dotNet程序员的Java爬坑之旅(二)
囉里囉唆的寫了一大堆,最後還是全刪除了.哎~ 言歸正傳,最近因爲發生了很多事情,所以更新的有嗲晚了,最近也一直在學習,但是感覺效率什麽的不是很高,這是不對的,反思一下,從這篇博文開始,打起精神吧. M ...
- Java中的4个并发工具类 CountDownLatch CyclicBarrier Semaphore Exchanger
在 java.util.concurrent 包中提供了 4 个有用的并发工具类 CountDownLatch 允许一个或多个线程等待其他线程完成操作,课题点 Thread 类的 join() 方法 ...
- dede织梦后台-退出空白,注销空白,打开空白,登录返回首页,登录返回登录页面
24.php 5.4版本 后台500错误,打开空白的问题 不兼容 登录时空白 后台空白 24-1./include/userlogin.class.php 今天把电脑上的phpStudy升级到2013 ...
- 浅谈 drop、truncate和delete的区别
(1)DELETE语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存以便进行进行回滚操作. TRUNCATE TABLE 则一次性地从表中删除所有的数据并不把单独 ...