Pytorch之训练器设置
Pytorch之训练器设置
改动
2019年4月26日21:32:35
# 这里坑了我好久,对于python的语法掌握的还是不行,若是使用之前那样的`[AvgMeter()]*256`的书写
# 得到的是256个相同地址的类,实际上就是同一个类,每次修改都会互相影响,会导致最终的结果错误
pres = [AvgMeter() for _ in range(256)]
recs = [AvgMeter() for _ in range(256)]
引言
深度学习训练的时候有很多技巧, 但是实际用起来效果如何, 还是得亲自尝试.
这里记录了一些个人尝试不同技巧的代码.
tensorboardX
说起tensorflow, 我就一阵头大, google强力的创造了一门新的语言! 自从上手Pytorch后, 就再也不想回去了. 但是tensorflow的生态不是一般的好, 配套设施齐全, 尤其是可视化神器tensorboard, 到了Pytorch这边, 幸好还有visdom和tensorboardX, 但是前者实在是有些捉摸不透... 到时tensorboardX让我感觉更为亲切些...
tensorboard的使用, 需要连带tensorflow一起装好, 也就是说, 想要用pytorch的tensorboardX, 你还是得装好tensorflow...
使用from tensorboardX import SummaryWriter导入核心类(似乎这个包里只有这个类), 具体的用法也很简单, 详见https://github.com/lanpa/tensorboardX/tree/master/examples, 以及 https://tensorboardx.readthedocs.io/en/latest/index.html.
我这里直接对其实例化, self.tb = SummaryWriter(self.path['tb']), 后面直接调用self.tb的方法就可以了. 在这里, 我显示了很多东西. 这里需要说的有两点:
- 多个图的显示: 使用名字区分, 如
'data/train_loss_avg'与'data/train_loss_avg' - 多个图片的显示: 这里使用了pytorch自带的一个处理张量的方法
make_grid来得到可以用tensorboard显示的图像.
if self.args['tb_update'] > 0 and curr_iter % self.args['tb_update'] == 0:
self.tb.add_scalar('data/train_loss_avg', train_loss_record.avg, curr_iter)
self.tb.add_scalar('data/train_loss_avg', train_iter_loss, curr_iter)
self.tb.add_scalar('data/train_lr', self.opti.param_groups[1]['lr'], curr_iter)
self.tb.add_text('train_data_names', str(train_names), curr_iter)
tr_tb_out_1 = make_grid(otr_1, nrow=train_batch_size, padding=5)
self.tb.add_image('train_output1', tr_tb_out_1, curr_iter)
tr_tb_out_2 = make_grid(otr_2, nrow=train_batch_size, padding=5)
self.tb.add_image('train_output2', tr_tb_out_2, curr_iter)
tr_tb_out_4 = make_grid(otr_4, nrow=train_batch_size, padding=5)
self.tb.add_image('train_output4', tr_tb_out_4, curr_iter)
tr_tb_out_8 = make_grid(otr_8, nrow=train_batch_size, padding=5)
self.tb.add_image('train_output8', tr_tb_out_8, curr_iter)
tr_tb_out_16 = make_grid(otr_16, nrow=train_batch_size, padding=5)
self.tb.add_image('train_output16', tr_tb_out_16, curr_iter)
tr_tb_label = make_grid(train_labels, nrow=train_batch_size, padding=5)
self.tb.add_image('train_labels', tr_tb_label, curr_iter)
tr_tb_indata = make_grid(train_inputs, nrow=train_batch_size, padding=5)
self.tb.add_image('train_data', tr_tb_indata, curr_iter) # 我这里的图像显示的预处理之后要输入网络的图片
下面是显示的结果:
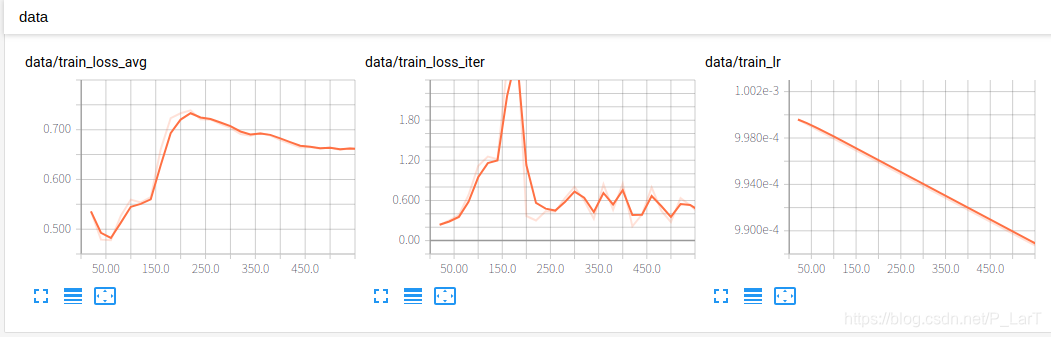
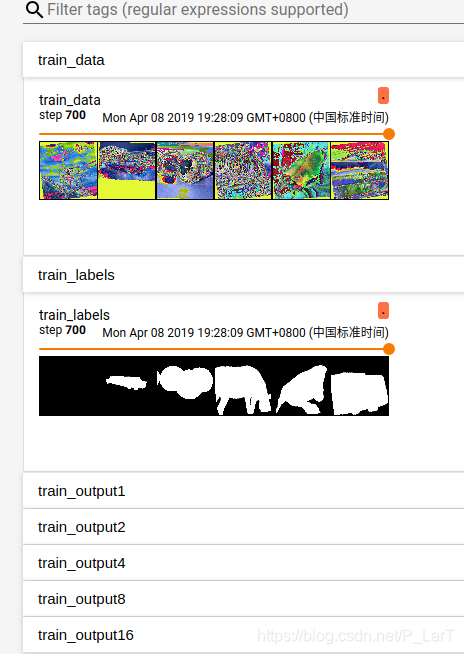
优化器
这里关于学习率的设定, 根据参数名字中是否保安bias(是否为偏置项)来分别设置.
self.opti = optim.SGD(
[
# 不对bias参数执行weight decay操作,weight decay主要的作用就是通过对网络
# 层的参数(包括weight和bias)做约束(L2正则化会使得网络层的参数更加平滑)达
# 到减少模型过拟合的效果。
{'params': [param for name, param in self.net.named_parameters()
if name[-4:] == 'bias'],
'lr': 2 * self.args['lr']},
{'params': [param for name, param in self.net.named_parameters()
if name[-4:] != 'bias'],
'lr': self.args['lr'],
'weight_decay': self.args['weight_decay']}
],
momentum=self.args['momentum'])
self.sche = self.__make_schedular()
self.warmup_iters = self.args['warmup_epoch'] * len(self.tr_loader)
这里实现了学习率预热和几个学习率衰减设定, 关键的地方在于使用学习率预热的时候要注意对应的周期(迭代次数)如何设定, 要保证与正常的学习率衰减之间的平滑过渡.
def __lr_warmup(self, curr_iter):
"""
实现学习率预热, 在self.args['warmup_epoch']设定对应的恢复时对应的周期
"""
warmup_lr = self.args['lr'] / self.warmup_iters
self.opti.param_groups[0]['lr'] = 2 * warmup_lr * curr_iter
self.opti.param_groups[1]['lr'] = warmup_lr * curr_iter
def __make_schedular(self):
if self.args['warmup_epoch'] > 0:
epoch_num = self.args['epoch_num'] - self.args['warmup_epoch'] + 1
else:
epoch_num = self.args['epoch_num']
# 计算总的迭代次数, 一个周期batch数量为len(self.tr_loader)
iter_num = epoch_num * len(self.tr_loader)
if self.args['lr_type'] == 'exp':
lamb = lambda curr_iter: pow((1 - (curr_iter / iter_num)), self.args['lr_decay'])
scheduler = optim.lr_scheduler.LambdaLR(self.opti, lr_lambda=lamb)
elif self.args['lr_type'] == 'cos':
scheduler = optim.lr_scheduler.CosineAnnealingLR(
self.opti,
T_max=iter_num - 1,
eta_min=4e-08)
else:
raise RuntimeError('没有该学习率衰减设定')
return scheduler
模型保存与恢复
主要是根据训练损失最小的时候进行所谓best模型的保存. 以及在训练结束的时候保存模型.
if self.args['save_best']:
old_diff = val_loss_avg if self.args['has_val'] else train_loss_record.avg
if old_diff < self.old_diff:
self.old_diff = old_diff
torch.save(self.net.state_dict(), self.path['best_net'])
torch.save(self.opti.state_dict(), self.path['best_opti'])
tqdm.write(f"epoch {epoch} 模型较好, 已保存")
# 所有的周期迭代结束
torch.save(self.net.state_dict(), self.path['final_net'])
torch.save(self.opti.state_dict(), self.path['final_opti'])
对于模型恢复, 可以如下设定, 但是要注意, 想要继续训练, 需要注意很多地方, 例如tensorboard继续显示还是删除后重新显示, 注意学习率的设定, 重新开始是否要使用学习率预热, 学习率如何衰减等等细节.
if len(self.args['snapshot']) > 0:
print('training resumes from ' + self.args['snapshot'])
assert int(self.args['snapshot']) == self.args['start_epoch']
net_path = osp.join(self.path['pth_log'], self.args['snapshot'] + '.pth')
opti_path = osp.join(self.path['pth_log'], self.args['snapshot'] + '_optim.pth')
self.net.load_state_dict(torch.load(net_path))
self.opti.load_state_dict(torch.load(opti_path))
# bias的学习率大于weights的
# 继续训练的时候, 直接使用了最大的学习率
self.opti.param_groups[0]['lr'] = 2 * self.args['lr']
self.opti.param_groups[1]['lr'] = self.args['lr']
进度展示
这里使用了tqdm这个包, 来对训练, 测试进度进行展示. 主要使用了trange和tqdm以及tqdm.write来显示.
导入: from tqdm import tqdm, trange.
使用如下:
def train(self):
tqdm_trange = trange(self.start_epoch, self.end_epoch, ncols=100)
for epoch in tqdm_trange:
tqdm_trange.set_description(f"tr=>epoch={epoch}")
train_loss_record = AvgMeter()
batch_tqdm = tqdm(enumerate(self.tr_loader), total=len(self.tr_loader),
ncols=100, leave=False)
for train_batch_id, train_data in batch_tqdm:
batch_tqdm.set_description(f"net=>{self.args[self.args['NET']]['exp_name']}"
f"lr=>{self.opti.param_groups[1]['lr']}")
...
tqdm.write(f"epoch {epoch} 模型较好, 已保存")
显示如下:

整体代码
import os
import os.path as osp
from datetime import datetime
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from PIL import Image
from tensorboardX import SummaryWriter
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.utils import make_grid
from tqdm import tqdm, trange
from models.NearLoss import NearLoss
from models.NearLossV2 import NearLossV2
from models.SLoss import SLoss
from utils import joint_transforms
from utils.config import arg_config, path_config
from utils.datasets import ImageFolder
from utils.misc import (AvgMeter, cal_fmeasure, cal_pr_mae_fm, check_mkdir, make_log)
torch.manual_seed(2019)
torch.multiprocessing.set_sharing_strategy('file_system')
class Trainer():
def __init__(self, args, path):
super(Trainer, self).__init__()
# 无依赖属性
self.args = args
self.path = path
self.dev = torch.device(
"cuda:0" if torch.cuda.is_available() else "cpu")
self.to_pil = transforms.ToPILImage()
self.old_diff = 100 # 设定一个足够大的数, 来保存后期的损失
# 删除之前的文件夹, 如果要刷新tensorboard, 最好是重新启动一下tensorboard
check_mkdir(self.path['pth_log'])
if len(self.args['snapshot']) == 0:
# if os.path.exists(self.path['tb']):
# print(f"rm -rf {self.path['tb']}")
# os.system(f"rm -rf {self.path['tb']}")
check_mkdir(self.path['tb'])
if self.args['save_pre']:
if os.path.exists(self.path['save']):
print(f"rm -rf {self.path['save']}")
os.system(f"rm -rf {self.path['save']}")
check_mkdir(self.path['save'])
# 依赖与前面属性的属性
self.pth_path = self.path['best_net'] \
if osp.exists(self.path['best_net']) else self.path['final_net']
if self.args['tb_update'] > 0:
self.tb = SummaryWriter(self.path['tb'])
self.tr_loader, self.val_loader, self.te_loader = self.__make_loader()
self.net = self.args[self.args['NET']]['net']().to(self.dev)
# 学习率相关
self.opti = optim.SGD(
[
# 不对bias参数执行weight decay操作,weight decay主要的作用就是通过对网络
# 层的参数(包括weight和bias)做约束(L2正则化会使得网络层的参数更加平滑)达
# 到减少模型过拟合的效果。
{'params': [param for name, param in self.net.named_parameters()
if name[-4:] == 'bias'],
'lr': 2 * self.args['lr']},
{'params': [param for name, param in self.net.named_parameters()
if name[-4:] != 'bias'],
'lr': self.args['lr'],
'weight_decay': self.args['weight_decay']}
],
momentum=self.args['momentum'])
self.sche = self.__make_schedular()
self.warmup_iters = self.args['warmup_epoch'] * len(self.tr_loader)
# 损失相关
self.crit = nn.BCELoss().to(self.dev)
self.use_newloss = self.args['new_loss']['using']
if self.use_newloss:
if self.args['new_loss']['type'] == 'sloss':
self.crit_new = SLoss().to(self.dev)
elif self.args['new_loss']['type'] == 'nearloss':
self.crit_new = NearLoss().to(self.dev)
elif self.args['new_loss']['type'] == 'nearlossv2':
self.crit_new = NearLossV2(self.dev).to(self.dev)
print(f"使用了附加的新损失{self.crit_new}")
# 继续训练相关
self.start_epoch = self.args['start_epoch'] # 接着上次训练
if self.args['end_epoch'] < self.args['epoch_num']:
self.end_epoch = self.args['end_epoch']
else:
self.end_epoch = self.args['epoch_num']
if len(self.args['snapshot']) > 0:
print('training resumes from ' + self.args['snapshot'])
assert int(self.args['snapshot']) == self.args['start_epoch']
net_path = osp.join(self.path['pth_log'], self.args['snapshot'] + '.pth')
opti_path = osp.join(self.path['pth_log'], self.args['snapshot'] + '_optim.pth')
self.net.load_state_dict(torch.load(net_path))
self.opti.load_state_dict(torch.load(opti_path))
# bias的学习率大于weights的
# 继续训练的时候, 直接使用了最大的学习率
self.opti.param_groups[0]['lr'] = 2 * self.args['lr']
self.opti.param_groups[1]['lr'] = self.args['lr']
def train(self):
tqdm_trange = trange(self.start_epoch, self.end_epoch, ncols=100)
for epoch in tqdm_trange:
tqdm_trange.set_description(f"tr=>epoch={epoch}")
train_loss_record = AvgMeter()
batch_tqdm = tqdm(enumerate(self.tr_loader), total=len(self.tr_loader),
ncols=100, leave=False)
for train_batch_id, train_data in batch_tqdm:
batch_tqdm.set_description(f"net=>{self.args[self.args['NET']]['exp_name']}"
f"lr=>{self.opti.param_groups[1]['lr']}")
if len(self.args['snapshot']) > 0:
lr_epoch = epoch - int(self.args['snapshot'])
else:
lr_epoch = epoch
"""
仅在从头训练的时候使用学习率预热, 对于继续训练的时候, 不再使用学习率预热.
"""
curr_iter = train_batch_id + 1 + epoch * len(self.tr_loader)
if len(self.args['snapshot']) > 0:
curr_iter -= (self.start_epoch * len(self.tr_loader))
if self.args['lr_type'] == 'exp':
self.sche.step(curr_iter)
elif self.args['lr_type'] == 'cos':
self.sche.step()
else:
if epoch < self.args['warmup_epoch']:
self.__lr_warmup(curr_iter)
else:
if self.args['lr_type'] == 'exp':
self.sche.step(curr_iter - self.warmup_iters)
elif self.args['lr_type'] == 'cos':
self.sche.step()
train_inputs, train_labels, train_names = train_data
train_inputs = train_inputs.to(self.dev)
train_labels = train_labels.to(self.dev)
self.opti.zero_grad()
otr_1, otr_2, otr_4, otr_8, otr_16 = self.net(train_inputs)
tr_loss_1 = self.crit(otr_1, train_labels)
tr_loss_2 = self.crit(otr_2, train_labels)
tr_loss_4 = self.crit(otr_4, train_labels)
tr_loss_8 = self.crit(otr_8, train_labels)
tr_loss_16 = self.crit(otr_16, train_labels)
train_loss = tr_loss_1 + tr_loss_2 + tr_loss_4 + tr_loss_8 + tr_loss_16
if self.use_newloss:
train_loss += self.args['new_loss']['beta'] * self.crit_new(otr_1, train_labels)
"""
以后累加loss, 用loss.item(). 这个是必须的, 如果直接加, 那么随着训练的进行,
会导致后来的loss具有非常大的graph, 可能会超内存. 然而total_loss只是用来看的,
所以没必要进行维持这个graph!
"""
# 反向传播使用的损失不需要item获取数据
train_loss.backward()
self.opti.step()
# 仅在累计的时候使用item()获取数据
train_iter_loss = train_loss.item()
train_batch_size = train_inputs.size(0)
train_loss_record.update(train_iter_loss, train_batch_size)
if self.args['tb_update'] > 0 and curr_iter % self.args['tb_update'] == 0:
self.tb.add_scalar('data/train_loss_avg', train_loss_record.avg, curr_iter)
self.tb.add_scalar('data/train_loss_iter', train_iter_loss, curr_iter)
self.tb.add_scalar('data/train_lr', self.opti.param_groups[1]['lr'], curr_iter)
self.tb.add_text('train_data_names', str(train_names), curr_iter)
tr_tb_out_1 = make_grid(otr_1, nrow=train_batch_size, padding=5)
self.tb.add_image('train_output1', tr_tb_out_1, curr_iter)
tr_tb_out_2 = make_grid(otr_2, nrow=train_batch_size, padding=5)
self.tb.add_image('train_output2', tr_tb_out_2, curr_iter)
tr_tb_out_4 = make_grid(otr_4, nrow=train_batch_size, padding=5)
self.tb.add_image('train_output4', tr_tb_out_4, curr_iter)
tr_tb_out_8 = make_grid(otr_8, nrow=train_batch_size, padding=5)
self.tb.add_image('train_output8', tr_tb_out_8, curr_iter)
tr_tb_out_16 = make_grid(otr_16, nrow=train_batch_size, padding=5)
self.tb.add_image('train_output16', tr_tb_out_16, curr_iter)
tr_tb_label = make_grid(train_labels, nrow=train_batch_size, padding=5)
self.tb.add_image('train_labels', tr_tb_label, curr_iter)
tr_tb_indata = make_grid(train_inputs, nrow=train_batch_size, padding=5)
self.tb.add_image('train_data', tr_tb_indata, curr_iter)
if self.args['has_val']:
tqdm.write(f'train epoch {epoch} over, val start')
self.net.eval()
val_loss_avg = self.__val(lr_epoch)
self.net.train()
if self.args['save_best']:
old_diff = val_loss_avg if self.args['has_val'] else train_loss_record.avg
if old_diff < self.old_diff:
self.old_diff = old_diff
torch.save(self.net.state_dict(), self.path['best_net'])
torch.save(self.opti.state_dict(), self.path['best_opti'])
tqdm.write(f"epoch {epoch} 模型较好, 已保存")
# 所有的周期迭代结束
torch.save(self.net.state_dict(), self.path['final_net'])
torch.save(self.opti.state_dict(), self.path['final_opti'])
def test(self):
self.net.eval()
self.net.load_state_dict(torch.load(self.pth_path))
gt_path = osp.join(self.path['test'], 'Mask')
# 这里坑了我好久,对于python的语法掌握的还是不行,若是使用之前那样的`[AvgMeter()]*256`的书写
# 得到的是256个相同地址的类,实际上就是同一个类,每次修改都会互相影响,会导致最终的结果错误
pres = [AvgMeter() for _ in range(256)]
recs = [AvgMeter() for _ in range(256)]
fams = AvgMeter()
maes = AvgMeter()
tqdm_iter = tqdm(enumerate(self.te_loader),
total=len(self.te_loader),
ncols=100, leave=True)
for test_batch_id, test_data in tqdm_iter:
tqdm_iter.set_description(
f"{self.args[self.args['NET']]['exp_name']}:"
f"te=>{test_batch_id + 1}")
in_imgs, in_names = test_data
inputs = in_imgs.to(self.dev)
with torch.no_grad():
outputs = self.net(inputs)
outputs_np = outputs.cpu().detach()
for item_id, out_item in enumerate(outputs_np):
gimg_path = osp.join(gt_path, in_names[item_id] + '.png')
gt_img = Image.open(gimg_path).convert('L')
out_img = self.to_pil(out_item).resize(gt_img.size)
gt_img = np.array(gt_img)
if self.args['save_pre']:
oimg_path = osp.join(self.path['save'], in_names[item_id] + '.png')
out_img.save(oimg_path)
out_img = np.array(out_img)
ps, rs, mae, fam = cal_pr_mae_fm(out_img, gt_img)
for pidx, pdata in enumerate(zip(ps, rs)):
p, r = pdata
pres[pidx].update(p)
recs[pidx].update(r)
maes.update(mae)
fams.update(fam)
fm = cal_fmeasure([pre.avg for pre in pres],
[rec.avg for rec in recs])
results = {'fm_thresholds': fm,
'fm': fams.avg,
'mae': maes.avg}
return results
def __val(self, lr_epoch):
val_loss_record = AvgMeter()
# fams = AvgMeter()
# maes = AvgMeter()
for val_batch_id, val_data in tqdm(enumerate(self.val_loader),
total=len(self.val_loader),
desc=f"val=>epoch={lr_epoch}",
ncols=100, leave=True):
val_inputs, val_labels = val_data
val_inputs = val_inputs.to(self.dev)
with torch.no_grad():
val_outputs = self.net(val_inputs)
# # 从gpu搬运到cpu后, 修改numpy结果, 不会影响gpu值
# val_outputs_np = val_outputs.cpu().detach().numpy()
# # numpy()方法会返回一个数组, 但是与原本的tensor共享存储单元, 所以一个变都会变
# # 所以使用numpy的copy方法, 这个的实现是深拷贝. 数据独立
# val_labels_np = val_labels.numpy().copy()
#
# val_outputs_np *= 255
# val_labels_np *= 255
# val_outputs_np = val_outputs_np.astype(np.uint8)
# val_labels_np = val_labels_np.astype(np.uint8)
#
# for item_id, pre_gt_item in enumerate(zip(val_outputs_np,
# val_labels_np)):
# out_item, label_item = pre_gt_item
# _, _, mae, fam = cal_pr_mae_fm(out_item, label_item)
# maes.update(mae)
# fams.update(fam)
val_labels = val_labels.to(self.dev)
# 通过item()使单元素张量转化为python标量, 因为这里不需要反向传播
val_iter_loss = self.crit(val_outputs, val_labels).item()
if self.use_newloss:
val_iter_loss += self.args['new_loss']['beta'] * \
self.crit_new(val_outputs, val_labels).item()
val_batch_size = val_inputs.size(0)
val_loss_record.update(val_iter_loss, val_batch_size)
# 每一个周期下都对应一个训练阶段与验证阶段, 所以这里使用len(val)即可
curr_iter = val_batch_id + 1 + lr_epoch * len(self.val_loader)
if self.args['tb_update'] > 0 and curr_iter % self.args['tb_update'] == 0:
self.tb.add_scalar('data/val_loss_avg', val_loss_record.avg, curr_iter)
self.tb.add_scalar('data/val_loss_iter', val_iter_loss, curr_iter)
val_tb_out = make_grid(val_outputs, nrow=val_batch_size, padding=5)
val_tb_label = make_grid(val_labels, nrow=val_batch_size, padding=5)
self.tb.add_image('val_output', val_tb_out, curr_iter)
self.tb.add_image('val_label', val_tb_label, curr_iter)
return val_loss_record.avg
def __lr_warmup(self, curr_iter):
"""
实现学习率预热, 在self.args['warmup_epoch']设定对应的恢复时对应的周期
"""
warmup_lr = self.args['lr'] / self.warmup_iters
self.opti.param_groups[0]['lr'] = 2 * warmup_lr * curr_iter
self.opti.param_groups[1]['lr'] = warmup_lr * curr_iter
def __make_schedular(self):
if self.args['warmup_epoch'] > 0:
epoch_num = self.args['epoch_num'] - self.args['warmup_epoch'] + 1
else:
epoch_num = self.args['epoch_num']
# 计算总的迭代次数, 一个周期batch数量为len(self.tr_loader)
iter_num = epoch_num * len(self.tr_loader)
if self.args['lr_type'] == 'exp':
lamb = lambda curr_iter: pow((1 - (curr_iter / iter_num)), self.args['lr_decay'])
scheduler = optim.lr_scheduler.LambdaLR(self.opti, lr_lambda=lamb)
elif self.args['lr_type'] == 'cos':
scheduler = optim.lr_scheduler.CosineAnnealingLR(
self.opti,
T_max=iter_num - 1,
eta_min=4e-08)
else:
raise RuntimeError('没有该学习率衰减设定')
return scheduler
def __make_loader(self):
train_joint_transform = joint_transforms.Compose([
joint_transforms.RandomScaleCrop(base_size=self.args['base_size'],
crop_size=self.args['crop_size']),
joint_transforms.RandomHorizontallyFlip(),
joint_transforms.RandomRotate(10)
])
train_img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
train_target_transform = transforms.ToTensor()
test_val_img_transform = transforms.Compose([
transforms.Resize((self.args['crop_size'], self.args['crop_size'])),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
val_target_transform = transforms.Compose([
transforms.Resize(
(self.args['crop_size'], self.args['crop_size'])),
transforms.ToTensor(),
])
train_set = ImageFolder(self.path['train'],
'train',
train_joint_transform,
train_img_transform,
train_target_transform)
train_loader = DataLoader(train_set,
batch_size=self.args['batch_size'],
num_workers=self.args['num_workers'],
shuffle=True,
drop_last=False,
pin_memory=True)
# drop_last=True的时候, 会把最后的不能构成一个完整batch的数据删掉, 但是这里=False
# 就不会删掉, 该batch对应会减小.
if self.args['has_val']:
val_set = ImageFolder(self.path['val'],
'val',
None,
test_val_img_transform,
val_target_transform)
val_loader = DataLoader(val_set,
batch_size=self.args['batch_size'],
num_workers=self.args['num_workers'],
shuffle=False,
drop_last=False,
pin_memory=True)
else:
val_loader = None
test_set = ImageFolder(self.path['test'],
'test',
None,
test_val_img_transform,
None)
test_loader = DataLoader(test_set,
batch_size=self.args['batch_size'],
num_workers=self.args['num_workers'],
shuffle=False,
drop_last=False,
pin_memory=True)
return train_loader, val_loader, test_loader
if __name__ == '__main__':
trainer = Trainer(arg_config, path_config)
make_log(path_config['log_txt'], f"\n{arg_config}")
print('开始训练...')
trainer.train()
print('开始测试...')
begin = datetime.now()
result = trainer.test()
end = datetime.now()
print(result)
make_log(path_config['log_txt'], f"{result}\n, 测试花费时间:{end - begin}\n")
with open('log_project.log', 'a') as log_pro:
# 每运行一次就记录一次参数设定
log_pro.write(f"\n\n{datetime.now()}\n{arg_config}\n{result}\n\n")
其中的一些工具函数:
import os
import numpy as np
class AvgMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def check_mkdir(dir_name):
if not os.path.exists(dir_name):
os.makedirs(dir_name)
def make_log(path, context):
with open(path, 'a') as log:
log.write(f'{context}' + '\n')
def count_parameters(model, bits=32):
"""
计算模型参数大致的量
:param model: 模型
:param bits: 每个参数的位数
:type bits: int
:return: MB单位的估计值
:rtype: int
"""
# `numel` Returns the total number of elements in the input tensor.
# 默认每个元素都是float32的
Bytes = bits / 8
return sum(p.numel() for p in model.parameters() if p.requires_grad) * Bytes / (1024 * 1024)
def cal_pr_mae_fm(prediction, gt):
# input should be np array with data type uint8
assert prediction.dtype == np.uint8
assert gt.dtype == np.uint8
assert prediction.shape == gt.shape
eps = 1e-4
prediction = prediction / 255.
gt = gt / 255.
# gt[gt != 0 ] = 1
# test results:{'fmeasure': 0.857414223946015, 'fam': 0.7792301650642437, 'mae': 0.04729127225177597}
# gt[gt > 0.5] = 1
# test results:{'fmeasure': 0.8569724970147757, 'fam': 0.7739958746528544, 'mae': 0.042624657291724245}
# 都不要
# test results:{'fmeasure': 0.8569724970147757, 'fam': 0.7719016419652358, 'mae': 0.042297395888889304}
mae = np.mean(np.abs(prediction - gt))
hard_gt = np.zeros(prediction.shape)
hard_gt[gt > 0.5] = 1
t = np.sum(hard_gt)
# threshold fm
binary = np.zeros_like(prediction)
threshold_fm = 2 * prediction.mean()
if threshold_fm > 1:
threshold_fm = 1
binary[prediction >= threshold_fm] = 1
tp = (binary * gt).sum()
pre = (tp + eps) / (binary.sum() + eps)
rec = (tp + eps) / (gt.sum() + eps)
fm = 1.3 * pre * rec / (0.3 * pre + rec + eps)
precision, recall = [], []
for threshold in range(256):
threshold = threshold / 255.
hard_prediction = np.zeros(prediction.shape)
hard_prediction[prediction > threshold] = 1
tp = np.sum(hard_prediction * hard_gt)
p = np.sum(hard_prediction)
precision.append((tp + eps) / (p + eps))
recall.append((tp + eps) / (t + eps))
return precision, recall, mae, fm
def cal_fmeasure(precision, recall):
assert len(precision) == 256
assert len(recall) == 256
beta_square = 0.3
max_fmeasure = max([(1 + beta_square) * p * r / (beta_square * p + r + 1e-10)
for p, r in zip(precision, recall)])
return max_fmeasure
Pytorch之训练器设置的更多相关文章
- 转pytorch中训练深度神经网络模型的关键知识点
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/weixin_42279044/articl ...
- [源码解析] PyTorch分布式优化器(1)----基石篇
[源码解析] PyTorch分布式优化器(1)----基石篇 目录 [源码解析] PyTorch分布式优化器(1)----基石篇 0x00 摘要 0x01 从问题出发 1.1 示例 1.2 问题点 0 ...
- [源码解析] PyTorch分布式优化器(2)----数据并行优化器
[源码解析] PyTorch分布式优化器(2)----数据并行优化器 目录 [源码解析] PyTorch分布式优化器(2)----数据并行优化器 0x00 摘要 0x01 前文回顾 0x02 DP 之 ...
- [源码解析] PyTorch分布式优化器(3)---- 模型并行
[源码解析] PyTorch分布式优化器(3)---- 模型并行 目录 [源码解析] PyTorch分布式优化器(3)---- 模型并行 0x00 摘要 0x01 前文回顾 0x02 单机模型 2.1 ...
- opencv 构造训练器
D:/face 构造face训练器为例 一:样本创建 训练样本分为正例样本和反例样本,其中正例样本是指待检目标样本,反例样本指其它任意图片. 负样本可以来自于任意的图片,但这些图片不能包含目标特征 ...
- Windows应用程序的VC链接器设置
Windows应用程序的VC链接器设置 /*转载请注明出自 听风独奏 www.GbcDbj.com */ Windows应用程序分为GUI(Graphical User Interface)和CUI( ...
- 《python灰帽子》学习笔记:调试器设置
一.构造 C 数据类型 C Type | Python Type | ctypes Type ____________________________________________________ ...
- CodeBlocks调试器设置错误问题
错误如下: Building to ensure sources are up-to-date Selecting target: Debug ERROR: You need to specify ...
- 【U3D】播放器设置(PlayerSettings)
播放器设置 (Player Settings) 播放器设置 (Player Settings) 用于为您要在 Unity 中编译的最终游戏定义各项(特定于平台的)参数.例如,参数中的一些值用于您打开单 ...
随机推荐
- DLC 格雷码
格雷码特点 每相邻两个数,只会有一位发生变(二进制数) 异或运算 若两个运算数相同,结果为 0 若两个运算数不相同, 结果为 1
- LeetCode 147. Insertion Sort List 链表插入排序 C++/Java
Sort a linked list using insertion sort. A graphical example of insertion sort. The partial sorted l ...
- BATCH、事务、CLOB、BLOB
Batch:需要执行大量的数据时可以使用批处理 注意点: 1.尽量使用Statement,因为如果是PreParedStatement可能会因为数据量太大而存在空间问题,编译器会报错. 2.把自动提交 ...
- python大法好——Python SMTP发送邮件
Python SMTP发送邮件 SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式. py ...
- C++的正则
C++的正则封装的不丰富.只有最基础的三个主要的函数(也可能是我孤陋寡闻).要有更为丰富的功能需要自己进一步组合. 我目前只需要循环查找这个功能,并且我也不知道c++的正则支持正则的哪些功能; 代码如 ...
- 初识Scratch 3.0
之前在帮朋友搜集少儿编程教育资料的时候,发现了麻省理工开发的积木式编程语言的Scratch,最近有空玩了下,感觉很惊艳,我能想象用它做一些有趣的事情,Scratch把编程元素变成像乐高积木一样,可以通 ...
- 深入理解BERT Transformer ,不仅仅是注意力机制
来源商业新知网,原标题:深入理解BERT Transformer ,不仅仅是注意力机制 BERT是google最近提出的一个自然语言处理模型,它在许多任务 检测上表现非常好. 如:问答.自然语言推断和 ...
- 小A的位运算-(前缀和+位运算)
https://ac.nowcoder.com/acm/contest/549/D 题意:从N个数里面选出N-1个数要让它们或起来的值最大. 解题: 假设n个数分别存在a数组里. 从左到右连续或运算结 ...
- ajax原生实现
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/ ...
- Tensorflow图像处理以及数据读取
关于tensoflow的图像的处理,看到了一篇文章,个人觉得不错.https://blog.csdn.net/weiwei9363/article/details/79917942