Python开发——14.threading模块和multiprocess模块
一、threading模块
1.threading类的两种创建方法
(1)直接创建
import time
import threading
def Hi(num):
print("hello,%d"%num)
time.sleep(3)
if __name__ == "__main__":
t1 = threading.Thread(target=Hi,args=(10,))
t2 = threading.Thread(target=Hi,args=(9,)) t1.start()
t2.start()
print("ending")
(2)通过继承的方式创建
import threading,time
class MyThread(threading.Thread):
def __init__(self,num):
threading.Thread.__init__(self)
self.num = num
def run(self):
print("运行线程%s"%self.num)
time.sleep(3)
t1 = MyThread(1)
t2 = MyThread(2) t1.start()
t2.start()
print("ending")
2.thread类的实例方法
(1)join()方法
在子线程完成运行之前,这个子线程的父线程将一直被阻塞。
import threading,time def music():
print("start to listen music %s"%time.ctime())
time.sleep(3)
print("stop to listen music %s"%time.ctime()) def game():
print("start to play game %s"%time.ctime())
time.sleep(5)
print("stop to play game %s"%time.ctime()) if __name__ == "__main__":
t1 = threading.Thread(target=music)
t2 = threading.Thread(target=game)
t1.start()
t1.join() t2.start()
t2.join()
print("ending")
(2)setDaemen
将线程声明为守护线程,必须在start() 方法调用之前设置,
在程序运行中,执行一个主线程,如果主线程又创建一个子线程,主线程和子线程 就分兵两路,分别运行,那么当主线程完成想退出时,会检验子线程是否完成。如果子线程未完成,则主线程会等待子线程完成后再退出,如果想要
主线程完成了,不管子线程是否完成,都要和主线程一起退出,就需要设置setDaemon()
import threading,time def music():
print("start to listen music %s"%time.ctime())
time.sleep(3)
print("stop to listen music %s"%time.ctime()) def game():
print("start to play game %s"%time.ctime())
time.sleep(5)
print("stop to play game %s"%time.ctime()) t1 = threading.Thread(target=music)
t2 = threading.Thread(target=game) if __name__ == "__main__":
t2.setDaemon(True)
t1.start()
t1.join() t2.start()
# t2.join()
print("ending")
(3)其他方法
import threading,time def music():
print("start to listen music %s"%time.ctime())
time.sleep(3)
print("stop to listen music %s"%time.ctime()) def game():
print("start to play game %s"%time.ctime())
time.sleep(5)
print("stop to play game %s"%time.ctime()) t1 = threading.Thread(target=music)
t2 = threading.Thread(target=game)
if __name__ == "__main__":
t1.start()
#Thread实例对象的方法
print(t1.isAlive())#返回线程是否活动的
t1.setName("t1111")#设置线程名
print(t1.getName())#返回线程名
t1.join() t2.start()
#threading模块提供的一些方法:
print(threading.currentThread())#返回当前的线程变量
print(threading.enumerate())#返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程
print(threading.active_count())#返回正在运行的线程数量,与len(threading.enumerate())有相同的结果
print("ending")
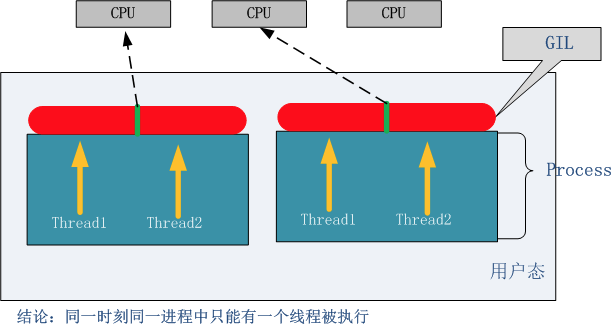
3.GIL(全局解释器锁)

(1)什么是GIL
在一个线程拥有了解释器的访问权之后,其他的所有线程都必须等待它释放解释器的访问权,即使这些线程的下一条指令并不会互相影响。
GIL缺点:多处理器退化为单处理器;优点:避免大量的加锁解锁操作
因为GIL的存在,只有IO Bound场景下得多线程会得到较好的性能
(2)GIL的影响
无论启多少个线程,有多少个cpu, Python在执行一个进程的时候同一时刻只允许一个线程运行。所以,python是无法利用多核CPU实现多线程的。
这样,python对于计算密集型的任务开多线程的效率甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。
(3)解决方案
用multiprocessing,它完整的复制了一套thread所提供的接口方便迁移,它使用了多进程而不是多线程,每个进程有自己的独立的GIL,因此不会出现进程之间的GIL争抢。
import multiprocessing
import time
def run(a1):
time.sleep(3)
print(a1) if __name__ == '__main__':
t1 = multiprocessing.Process(target=run, args=(12,))
t1.daemon = True # 将daemon设置为True,则主线程不比等待子进程,主线程结束则所有结束
t1.start() t2 = multiprocessing.Process(target=run, args=(13,))
t2.daemon = True
t2.start() print('end') # 默认情况下等待所有子进程结束,主进程才结束
4.同步锁
import time def sub():
global num
lock.acquire()
temp = num
time.sleep(0.001)
num = temp -1
lock.release() num = 100
lock = threading.Lock()
l = []
for i in range(100):
t = threading.Thread(target = sub)
t.start()
l.append(t) for t in l:
t.join()
print(num)
5.死锁和递归锁
(1)死锁
死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。
import threading,time
class MyThread(threading.Thread):
def actionA(self):
A.acquire()
print(self.name,"gotA",time.ctime())
time.sleep(2) B.acquire()
print(self.name,"gotB",time.ctime())
time.sleep(1) B.release()
A.release() def actionB(self):
B.acquire()
print(self.name, "gotB", time.ctime())
time.sleep(2) A.acquire()
print(self.name, "gotA", time.ctime())
time.sleep(1) A.release()
B.release() def run(self):
self.actionA()
self.actionB() if __name__ == "__main__":
A = threading.Lock()
B = threading.Lock()
l = []
for i in range(5):
t = MyThread()
t.start()
l.append(t)
for i in l:
i.join()
print("ending....")
(2)递归锁
可重入锁RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。
import threading,time
class MyThread(threading.Thread):
def actionA(self):
r_lock.acquire()
print(self.name,"gotA",time.ctime())
time.sleep(2) r_lock.acquire()
print(self.name,"gotB",time.ctime())
time.sleep(1) r_lock.release()
r_lock.release() def actionB(self):
r_lock.acquire()
print(self.name, "gotB", time.ctime())
time.sleep(2) r_lock.acquire()
print(self.name, "gotA", time.ctime())
time.sleep(1) r_lock.release()
r_lock.release() def run(self):
self.actionA()
self.actionB() if __name__ == "__main__":
r_lock = threading.RLock()
l = []
for i in range(5):
t = MyThread()
t.start()
l.append(t)
for i in l:
i.join()
print("ending....")
6.event对象
(1)方法
event.isSet():返回event的状态值; event.wait():如果 event.isSet()==False将阻塞线程; event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度; event.clear():恢复event的状态值为False。
(2)用法
在初始情况下,Event对象中的信号标志被设置为假。如果有线程等待的一个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。
wait方法可接受一个超时参数,加入这个超时参数之后,如果阻塞时间超过这个参数设定的值之后,wait方法会返回。
(3)实例
import threading,time
class Teacher(threading.Thread):
def run(self):
print("teacher:拖堂两分钟哈")
print(event.isSet())
event.set()
time.sleep(5)
print("teacher下课!!!")
print(event.isSet())
event.set()
class Students(threading.Thread):
def run(self):
event.wait()
print("students:啊啊啊啊啊!")
time.sleep(3)
event.clear()
event.wait()
print("students:又上课了!!!!!") if __name__ == "__main__":
event = threading.Event()
threads = [] for i in range(5):
threads.append(Students())
threads.append(Teacher())
for t in threads:
t.start()
for t in threads:
t.join()
print("ending")
7.信号量(semaphore)
(1)用法
Semaphore管理一个内置的计数器,每当调用acquire()时内置计数器-1;调用release() 时内置计数器+1;计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
(2)实例
import threading,time
semaphore = threading.Semaphore(5)
def func():
if semaphore.acquire():
print(threading.currentThread().getName())
time.sleep(2)
semaphore.release()
if __name__ == "__main__":
for i in range(20):
t1 = threading.Thread(target=func)
t1.start()
'''
import threading,time
class MyThread(threading.Thread):
def run(self):
if semaphore.acquire():
print(self.name)
time.sleep(3)
semaphore.release()
if __name__ == '__main__':
semaphore = threading.Semaphore(5)
thrs = []
for i in range(20):
thrs.append(MyThread())
for t in thrs:
t.start()
8.队列(queue)
(1)方法
import Queue
q = queue.Queue(maxsize = 10)
# 创建一个“队列”对象
# queue.Queue类即是一个队列的同步实现。队列长度可为无限或者有限。
# 可通过Queue的构造函数的可选参数maxsize来设定队列长度。如果maxsize小于1就表示队列长度无限。 q.put(10)
# 将一个值放入队列中
# 调用队列对象的put()方法在队尾插入一个项目。
# put()有两个参数,第一个item为必需的,为插入项目的值;第二个block为可选参数,默认为1。
# 如果队列当前为空且block为1,put()方法就使调用线程暂停,直到空出一个数据单元。
# 如果block为0,put方法将引发Full异常。 q.get()
# 将一个值从队列中取出
# 调用队列对象的get()方法从队头删除并返回一个项目。可选参数为block,默认为True。
# 如果队列为空且block为True,get()就使调用线程暂停,直至有项目可用。
# 如果队列为空且block为False,队列将引发Empty异常。
(2)其他方法
q.qsize() #返回队列的大小
q.empty() #如果队列为空,返回True,反之False
q.full() #如果队列满了,返回True,反之False
q.full #与 maxsize 大小对应
q.get([block[, timeout]]) #获取队列,timeout等待时间
q.get_nowait() #相当q.get(False)非阻塞
q.put(item)# 写入队列,timeout等待时间
q.put_nowait(item) #相当于q.put(item, False)
q.task_done() #在完成一项工作之后,q.task_done() 函数向任务已经完成的队列发送一个信号
q.join() #实际上意味着等到队列为空,再执行别的操作
(3)实例
a.先进先出
import queue
q = queue.Queue()
q.put(1)
q.put("he")
q.put({"name":"chouzi"}) while True:
data = q.get()
print(data)
print("$$$$$$$$$$$$$$$$$")
b.先进后出
import queue
q = queue.LifoQueue()
q.put(1)
q.put("he")
q.put({"name":"chouzi"}) while True:
data = q.get()
print(data)
print("$$$$$$$$$$$$$$$$$")
c.指定优先级
import queue
q = queue.PriorityQueue()
q.put([2,1])
q.put([1,"he"])
q.put([3,{"name":"chouzi"}]) while True:
data = q.get()
print(data[1])
print(data[0])
print("$$$$$$$$$$$$$$$$$")
d.task_done()
import queue
q = queue.Queue(5)
q.put(10)
q.put(20)
print(q.get())
q.task_done()
print(q.get())
q.task_done()
q.join()
print("ending!")
e.其他方法
import queue
q = queue.Queue(4)#FIFO
q.put(1)
q.put("he")
q.put({"name":"chouzi"})
q.put_nowait("hh")#put(block = False) get_nowait与其类似 print(q.qsize())
print(q.empty())
print(q.full())
9.生产者消费者模型
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者通过阻塞队列来进行通讯,所以生产者生产完数据之后直接扔给阻塞队列,消费者直接从阻塞队列里取。阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
import time,threading,queue
q = queue.Queue() def Producer(name):
count = 0
while count< 10 :
print("making GSCM")
time.sleep(5)
q.put(count)
print("%s 把做好了GSCM%s" %(name,count))
count += 1
q.task_done()
print("吃吧!!!!") def Consumer(name):
count = 0
while count < 10 :
time.sleep(6)
q.join()
data = q.get()
print("%s 把 GSCM%s吃了。"%(name,count)) p1 = threading.Thread(target=Producer,args=("hechouzi",))
c1 = threading.Thread(target=Consumer,args = ("nuannuan",))
c2 = threading.Thread(target=Consumer,args=("hanna",))
c3 = threading.Thread(target=Consumer,args=("wujiao",)) p1.start()
c1.start()
c2.start()
c3.start()
生产者与消费者模型
10.一个比喻
计算机的核心是CPU,它承担了所有的计算任务。它就像一座工厂,时刻在运行。假定工厂的电力有限,一次只能供给一个车间使用。也就是说,一个车间开工的时候,其他车间都必须停工。背后的含义就是,单个CPU一次只能运行一个任务。进程就好比工厂的车间,它代表CPU所能处理的单个任务。任一时刻,CPU总是运行一个进程,其他进程处于非运行状态。一个车间里,可以有很多工人。他们协同完成一个任务。线程就好比车间里的工人。一个进程可以包括多个线程。车间的空间是工人们共享的,比如许多房间是每个工人都可以进出的。这象征一个进程的内存空间是共享的,每个线程都可以使用这些共享内存。可是,每间房间的大小不同,有些房间最多只能容纳一个人,比如厕所。里面有人的时候,其他人就不能进去了。这代表一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。一个防止他人进入的简单方法,就是门口加一把锁。先到的人锁上门,后到的人看到上锁,就在门口排队,等锁打开再进去。这就叫"互斥锁"(Mutual exclusion,缩写 Mutex),防止多个线程同时读写某一块内存区域。还有些房间,可以同时容纳n个人,比如厨房。也就是说,如果人数大于n,多出来的人只能在外面等着。这好比某些内存区域,只能供给固定数目的线程使用。这时的解决方法,就是在门口挂n把钥匙。进去的人就取一把钥匙,出来时再把钥匙挂回原处。后到的人发现钥匙架空了,就知道必须在门口排队等着了。这种做法叫做"信号量"(Semaphore),用来保证多个线程不会互相冲突。
二、multiprocess模块
1.使用环境
由于GIL的存在,Python中的多线程不是真正的多线程,想要利用多核CPU,需使用多进程,由此引入multiprocess模块,该模块用法与threading模块一致。
2.调用方法
(1)Process类调用
from multiprocessing import Process
import time
def func(name):
time.sleep(1)
print("I am %s,time is%s"%(name,time.ctime()))
if __name__ == '__main__':
pro_list = []
for i in range(4):
p = Process(target=func,args=("dazui",))
pro_list.append(p)
p.start()
for i in pro_list:
i.join()
print("ending")
(2)继承Process调用
from multiprocessing import Process
import time
class MyProcess(Process):
# def __init__(self):
# super(MyProcess,self).__init__()
def run(self):
time.sleep(1)
print("I am %s,time is%s"%(self.name,time.ctime()))
if __name__ == '__main__':
pro_list = []
for i in range(4):
p = MyProcess()
# p.daemon = True
p.start()
pro_list.append(p)
for p in pro_list:
p.join()
print("ending")
3.Process类方法
构造方法:
Process([group [, target [, name [, args [, kwargs]]]]])
group: 线程组,目前还没有实现,库引用中提示必须是None;
target: 要执行的方法;
name: 进程名;
args/kwargs: 要传入方法的参数。
实例方法:
is_alive():返回进程是否在运行。
join([timeout]):阻塞当前上下文环境的进程程,直到调用此方法的进程终止或到达指定的timeout(可选参数)。
start():进程准备就绪,等待CPU调度
run():strat()调用run方法,如果实例进程时未制定传入target,这star执行t默认run()方法。
terminate():不管任务是否完成,立即停止工作进程
属性:
daemon:和线程的setDeamon功能一样
name:进程名字
pid:进程号
4.进程间通讯
(1)进程队列(Queue)
存在数据复制
import queue,time
import multiprocessing
def foo(q):
time.sleep(3)
print("son process",id(q))
q.put(123)
q.put("dazui")
if __name__ == '__main__':
q = multiprocessing.Queue()
p = multiprocessing.Process(target=foo,args=(q,))
p.start()
p.join()
print("main process",id(q))
print(q.get())
print(q.get())
(2)管道(Pipe)
Pipe()返回的两个连接对象代表管道的两端。 每个连接对象都有send()和recv()方法(等等),如果两个进程(或线程)尝试同时读取或写入管道的同一端,管道中的数据可能会损坏。
存在数据复制
from multiprocessing import Process,Pipe
def func(conn):
conn.send([111,{"name":"dazui"},"hello world!"])
response = conn.recv()
print("response:",response)
conn.close()
print("q_ID2:",id(conn)) if __name__ == '__main__':
parent_conn,child_conn = Pipe()
print("q_ID1",id(child_conn))
p = Process(target=func,args=(child_conn,))
p.start()
print(parent_conn.recv())
parent_conn.send("hello son!")
p.join()
(3)manager
数据共享
from multiprocessing import Process,Manager def func(d,l,n):
d[n] = ""
d[''] = 2
l.append(n)
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list(range(5))
p_list = [] for i in range(10):
p = Process(target=func,args=(d,l,i))
p.start()
p_list.append(p)
for res in p_list:
res.join()
print(d)
print(l)
5.进程池
(1)运行过程
进程池内部维护一个进程序列,当使用时,去进程池中获取一个进程,如果进程池序列中没有可供使用的进程,那么程序就会等待,直到进程池中有可用进程为止。
(2)主要方法
apply:从进程池里取一个进程并执行
apply_async:apply的异步版本
terminate:立刻关闭线程池
join:主进程等待所有子进程执行完毕,必须在close或terminate之后
close:等待所有进程结束后,才关闭线程池
(3)实例
from multiprocessing import Process,Pool
import time
def Foo(i):
time.sleep(1)
print(i)
if __name__ == '__main__':
pool = Pool()
for i in range(100):
pool.apply_async(func=Foo,args=(i,))
pool.close()
pool.join()
print("end")
Python开发——14.threading模块和multiprocess模块的更多相关文章
- Python开发【第二章】:模块和运算符
一.模块初识: Python有大量的模块,从而使得开发Python程序非常简洁.类库有包括三中: Python内部提供的模块 业内开源的模块 程序员自己开发的模块 1.Python内部提供一个 sys ...
- Python开发基础-Day14正则表达式和re模块
正则表达式 就其本质而言,正则表达式(或 re)是一种小型的.高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现.正则表达式模式被编译成一系列的字节码,然后由用 ...
- Python开发【第*篇】【模块】
模块分为三种: 自定义模块 第三方模块 内置模块 1.模块导入 import model from model.xx.xx import xx from model.xx.xx import xx a ...
- 如何在windows下的Python开发工具IDLE里安装其他模块?
以安装Httplib2模块为例 1 下载模块 到 “https://code.google.com/p/httplib2/” 下载一款适合你的压缩包“httplib2-0.4.0.zip” 2 解压下 ...
- Window上python开发--4.Django的用户登录模块User
Android系统开发交流群:484966421 OSHome. 微信公众号:oshome2015 在搭建站点和web的应用程序时,用户的登录和管理是差点儿是每一个站点都必备的. 今天主要从一个实例了 ...
- 如何在windows下的Python开发工具IDLE里安装其他模块
以安装Httplib2模块为例 1 下载模块 到 “https://code.google.com/p/httplib2/” 下载一款适合你的压缩包“httplib2-0.4.0.zip” 2 解压下 ...
- Python开发【内置模块篇】os模块
1.当前路径及路径下的文件 os.getcwd():查看当前所在路径. >>> import os >>> os.getcwd() 'E:\\test' >& ...
- Python开发【内置模块篇】日志模块
logging配置 import logging logging.basicConfig(level=logging.WARNING, format='%(asctime)s %(filename)s ...
- python 全栈开发,Day38(在python程序中的进程操作,multiprocess.Process模块)
昨日内容回顾 操作系统纸带打孔计算机批处理 —— 磁带 联机 脱机多道操作系统 —— 极大的提高了CPU的利用率 在计算机中 可以有超过一个进程 进程遇到IO的时候 切换给另外的进程使用CPU 数据隔 ...
随机推荐
- Your branch and remoteBranchName have diverged solution
(zhuan)git pull时解决分支分叉(branch diverged)问题 git pull时出现分支冲突(branch diverged) $ git status # On branch ...
- docker学习-lnmp+redis之搭建redis容器服务
1. 目录映射:/lnmp/data/redis:/data/lnmp/conf/redis/redis.conf:/etc/redis/redis.conf/lnmp/logs/redis:/var ...
- python 网络编程粘包解决方案2 + ftp上传 + socketserver
一.struct 神奇的打包工具 struct 代码: import struct num = 156 #将int类型的数据打包成4个字节的数据 num_stru = struct.pack('i', ...
- His表(简化)
门诊登记,门诊结算,门诊处方,住院登记,住院结算,住院处方,转诊登记,人员表,行政区划,登录日志,菜单,疾病,药品,诊疗,数据字典,机构,科室等
- windows server 2012R2 故障转移集群配置
配置说明: AD:10.10.1.10/24 Node-2:10.10.1.20/24 Node-3:10.10.1.30/24 zhangsan-PC:10.10.1.50/24 VIP1:10 ...
- Codeforces Round #485 (Div. 2)
Codeforces Round #485 (Div. 2) https://codeforces.com/contest/987 A #include<bits/stdc++.h> us ...
- python脚本处理下载的b站学习视频
作为常年在b站学习的我,一直以来看到有兴趣的视频,从来都是点赞收藏下载三连,但是苦于我那小钢炮iphone se屏幕大小有限,看起视频实在费劲,决定一定要找个下载电脑上下载b站视频的方法,以前用过硕鼠 ...
- L2-018 多项式A除以B(模拟)
这仍然是一道关于A/B的题,只不过A和B都换成了多项式.你需要计算两个多项式相除的商Q和余R,其中R的阶数必须小于B的阶数. 输入格式: 输入分两行,每行给出一个非零多项式,先给出A,再给出B.每行的 ...
- Linux服务器文件和windows本机文件互传方法(本地文件上传Linux,Linux文件下载到本机)
1.windows系统中下载XShell安装文件.下载地址:https://www.newasp.net/soft/384562.html 2.安装之后,新建会话输入远程linux的账号和密码. 3. ...
- 11.20 正则表达式 断言(?=exp)
今天看源代码,研究了一下qz写的这个方法: // 添加逗号分隔,返回为字符串 comma: function(length) { ) length = ; var source = ('' + thi ...