Python 爬虫实例(爬百度百科词条)
爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索。常见的爬虫框架有Scrapy等。
自定义爬虫程序一般包含:URL管理器、网页下载器、网页解析器、输出处理器。
以下我写了一个爬取百度百科词条的实例。
爬虫主程序入口
from crawler_test.html_downloader import UrlDownLoader
from crawler_test.html_outer import HtmlOuter
from crawler_test.html_parser import HtmlParser
from crawler_test.url_manager import UrlManager # 爬虫主程序入口
class MainCrawler():
def __init__(self):
# 初始值,实例化四大处理器:url管理器,下载器,解析器,输出器
self.urls = UrlManager()
self.downloader = UrlDownLoader()
self.parser = HtmlParser()
self.outer = HtmlOuter() # 开始爬虫方法
def start_craw(self, main_url):
print('爬虫开始...')
count = 1
self.urls.add_new_url(main_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print('爬虫%d,%s' % (count, new_url))
html_cont = self.downloader.down_load(new_url)
new_urls, new_data = self.parser.parse(new_url, html_cont) # 将解析出的url放入url管理器,解析出的数据放入输出器中
self.urls.add_new_urls(new_urls)
self.outer.conllect_data(new_data) if count >= 10: # 控制爬取的数量
break
count += 1
except:
print('爬虫失败一条') self.outer.output()
print('爬虫结束。') if __name__ == '__main__':
main_url = 'https://baike.baidu.com/item/Python/407313'
mc = MainCrawler()
mc.start_craw(main_url)
URL管理器
# URL管理器
class UrlManager():
def __init__(self):
self.new_urls = set() # 待爬取
self.old_urls = set() # 已爬取 # 添加一个新的url
def add_new_url(self, url):
if url is None:
return
elif url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url) # 批量添加url
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
else:
for url in urls:
self.add_new_url(url) # 判断是否有url
def has_new_url(self):
return len(self.new_urls) != 0 # 从待爬取的集合中获取一个url
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
网页下载器
from urllib import request # 网页下载器
class UrlDownLoader():
def down_load(self, url):
if url is None:
return None
else:
with request.urlopen(url) as rp: # 发请求,打开网页
if rp.status != 200:
return None
else:
return rp.read() # 读取网页内容
网页解析器
import re
from urllib import request
from bs4 import BeautifulSoup # 网页解析器,使用BeautifulSoup
class HtmlParser(): # 每个词条中,可以有多个超链接
# main_url指url公共部分,如“https://baike.baidu.com/”
def _get_new_url(self, main_url, soup):
# baike.baidu.com/
# <a target="_blank" href="/item/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%A8%8B%E5%BA%8F%E8%AE%BE%E8%AE%A1%E8%AF%AD%E8%A8%80">计算机程序设计语言</a>
new_urls = set() # 解析出main_url之后的url部分
child_urls = soup.find_all('a', href=re.compile(r'/item/(\%\w{2})+'))
for child_url in child_urls:
new_url = child_url['href'] # 再拼接成完整的url
full_url = request.urljoin(main_url, new_url)
new_urls.add(full_url)
return new_urls # 每个词条中,只有一个描述内容,解析出数据(词条,内容)
def _get_new_data(self, main_url, soup):
new_datas = {}
new_datas['url'] = main_url
# <dd class="lemmaWgt-lemmaTitle-title"><h1>计算机程序设计语言</h1>...
new_datas['title'] = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1').get_text()
# class="lemma-summary" label-module="lemmaSummary"...
new_datas['content'] = soup.find('div', attrs={'label-module': 'lemmaSummary'},
class_='lemma-summary').get_text()
return new_datas # 解析出url和数据(词条,内容)
def parse(self, main_url, html_cont):
if main_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, 'lxml', from_encoding='utf-8')
new_url = self._get_new_url(main_url, soup)
new_data = self._get_new_data(main_url, soup)
return new_url, new_data
输出处理器
# 输出器
class HtmlOuter():
def __init__(self):
self.datas = [] # 先收集数据
def conllect_data(self, data):
if data is None:
return
self.datas.append(data)
return self.datas # 输出为HTML
def output(self, file='output_html.html'):
with open(file, 'w', encoding='utf-8') as fh:
fh.write('<html>')
fh.write('<head>')
fh.write('<meta charset="utf-8"></meta>')
fh.write('<title>爬虫数据结果</title>')
fh.write('</head>')
fh.write('<body>') fh.write(
'<table style="border-collapse:collapse; border:1px solid gray; width:80%; word-wrap:break-word; margin:20px auto;">')
fh.write('<tr>')
fh.write('<th style="border:1px solid black; width:35%;">URL</th>')
fh.write('<th style="border:1px solid black; width:15%;">词条</th>')
fh.write('<th style="border:1px solid black; width:50%;">内容</th>')
fh.write('</tr>')
for data in self.datas:
fh.write('<tr>')
fh.write('<td style="border:1px solid black">{0}</td>'.format(data['url']))
fh.write('<td style="border:1px solid black">{0}</td>'.format(data['title']))
fh.write('<td style="border:1px solid black">{0}</td>'.format(data['content']))
fh.write('</tr>')
fh.write('</table>') fh.write('</body>')
fh.write('</html>')
效果(部分):
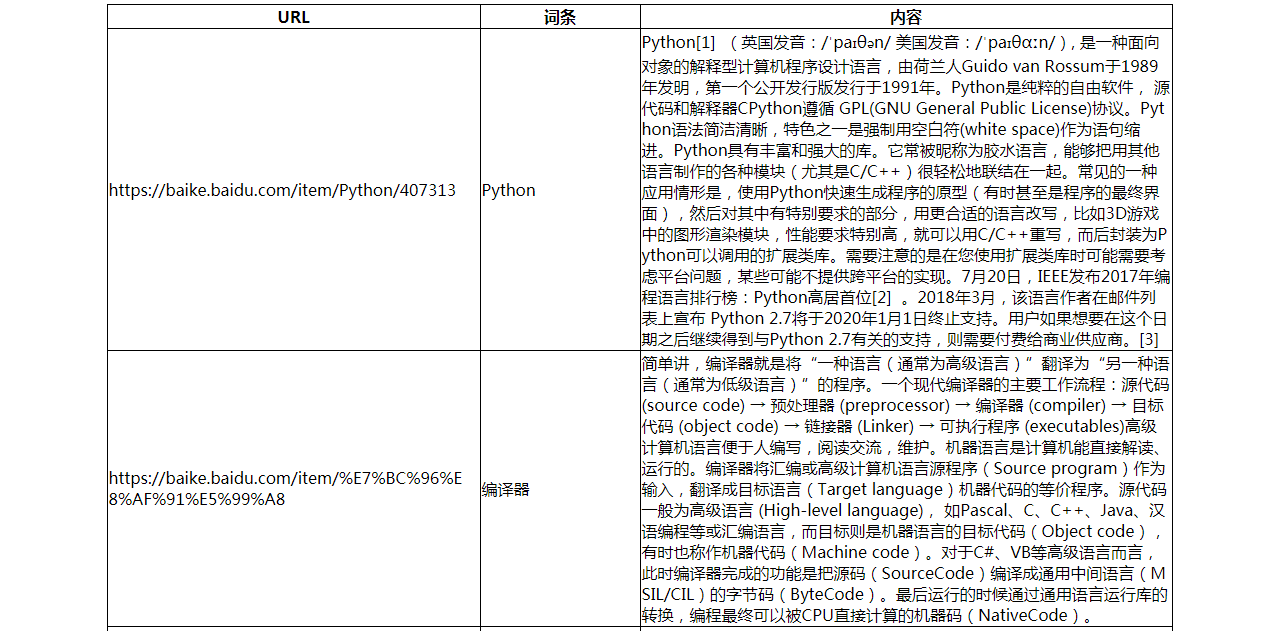
至此,转载请注明出处。

Python 爬虫实例(爬百度百科词条)的更多相关文章
- python_爬百度百科词条
如何爬取? 明确目标:爬取百度百科,定初始百度词条:python,初始URL:http://baike.baidu.com/item/Python,爬取数据量为1000条,值爬取简介,标题,和简介中u ...
- [Python爬虫] Selenium获取百度百科旅游景点的InfoBox消息盒
前面我讲述过如何通过BeautifulSoup获取维基百科的消息盒,同样可以通过Spider获取网站内容,最近学习了Selenium+Phantomjs后,准备利用它们获取百度百科的旅游景点消息盒(I ...
- python爬虫实例——爬取歌单
学习自<<从零开始学python网络爬虫>> 爬取酷狗歌单,保存入csv文件 直接上源代码:(含注释) import requests #用于请求网页获取网页数据 from b ...
- Python爬虫(一)爬百度贴吧
简单的GET请求: # python2 import urllib2 response = urllib2.urlopen('http://www.baidu.com') html = respons ...
- Python爬虫(二)爬百度贴吧楼主发言
爬取电影吧一个帖子里的所有楼主发言: # python2 # -*- coding: utf-8 -*- import urllib2 import string import re class Ba ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- python 使用selenium模块实现自动搜索百度百科词条(模拟人工搜索)
目标:模拟人工搜索百度百科词条,爬取相关信息,自动删除上一个关键词,输入新关键词,继续搜索,直到循环结束. 代码: from selenium import webdriver from seleni ...
随机推荐
- 使用Domain-Driven创建Hypermedia API
在现实中我们会遇到各种各样的复杂场景,"There is not a right way" 用来描述API的设计方法再合适不过了,没有一种API设计方式可以应对所有的场景.区别于& ...
- linux服务器部署tomcat和Nginx
项目需要,申请了三台测试机器,好在测试机里面光秃秃的什么都没有,我就可以好好的学习一把玩一把了!接下来以图文的形式讲一下我所碰到的坑以及小小的收获吧! 一.准备工作 首先你得有一台可以玩的linux服 ...
- SpringCloud学习6-如何创建一个服务消费者consumer
上一节如何创建一个服务提供者provider已经启动了一个provider的server,提供用户信息查询接口.接下来,我们启动另一个provider,由于是同一台机器本地测试,我们换一个端口 --s ...
- go使用rpc
RPC是远程过程调用的缩写(Remote Procedure Call),通俗地说就是调用远处的一个函数,是分布式系统中不同节点间流行的通信方式.Go语言的标准库提供了一个简单的RPC实现 serve ...
- com.mysql.jdbc.Driver 和 com.mysql.cj.jdbc.Driver
com.mysql.jdbc.Driver 是 mysql-connector-java 5中的,com.mysql.cj.jdbc.Driver 是 mysql-connector-java 6中的 ...
- You must reset your password using ALTER USER statement before executing this statement.
MySQL 5.7之后,刚初始化的MySQL实例要求先修改密码.否则会报错: mysql> create database test; ERROR 1820 (HY000): You must ...
- Python丢弃返回值
函数多个返回值 python的函数支持返回多个值.返回多个值时,默认以tuple的方式返回. 例如,下面两个函数的定义是完全等价的. def f(): return 1,2 def f(): retu ...
- Django 系列博客(六)
Django 系列博客(六) 前言 本篇博客介绍 Django 中的路由控制部分,一个网络请求首先到达的就是路由这部分,经过路由与视图层的映射关系再执行相应的代码逻辑并将结果返回给客户端. Djang ...
- Linux上安装nginx+tomcat负载均衡
1.Ngnix Nginx (发音同 engine x)是一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,并在一个BSD-like 协议下发行. 其特点是占有内 ...
- OpenCV入门之获取验证码的单个字符(字符切割)
介绍 在我们日常上网注册账号以及制作网络爬虫时,经常会遇到奇奇怪怪的验证码,有些容易,有些连人眼都无法辨识.于是,大牛们想到了用深度学习的方法来破解验证码,对于一般的验证码往往能出奇制胜,取得不俗 ...