第十四节,卷积神经网络之经典网络Inception(四)
一 1x1卷积
在架构内容设计方面,其中一个比较有帮助的想法是使用 1×1 卷积。也许你会好奇,1×1 的卷积能做什么呢?不就是乘以数字么?听上去挺好笑的,结果并非如此,我们来具体看看。
过滤器为 1×1 ,这里是数字 2,输入一张 6×6×1 的图片,然后对它做卷积,过滤器大小为 1×1 ,结果相当于把这个图片乘以数字 2,所以前三个单元格分别是 2、 4、 6 等等。用 1×1 的过滤器进行卷积,似乎用处不大,只是对输入矩阵乘以某个数字。但这仅仅是对于6×6×1的一个通道图片来说, 1×1 卷积效果不佳。 
如果是一张 6×6×32 的图片,那么使用 1×1 过滤器进行卷积效果更好。具体来说, 1×1 卷积所实现的功能是遍历这 36 个单元格,计算左图中 32 个数字和过滤器中 32 个数字的元素积之和,然后应用 ReLU 非线性函数。
我们以其中一个单元为例,它是这个输入层上的某个切片,用这 36 个数字乘以这个输入层上 1×1 切片,得到一个实数,像这样把它画在输出中。
这个 1×1×32 过滤器中的 32 个数字可以这样理解,一个神经元的输入是 32 个数字(输入图片中右下角位置 32 个通道中的数字),即相同高度和宽度上某一切片上的 32 个数字,这 32 个数字具有不同通道,乘以 32 个权重(将过滤器中的 32 个数理解为权重),然后应用 ReLU 非线性函数,在这里输出相应的结果。

一般来说,如果过滤器不止一个,而是多个,就好像有多个输入单元,每个单元的输入内容为一个切片上所有数字,输出结果是 6×6 × 过滤器数量。

1×1 卷积可以从根本上理解为对这 32 个不同的位置都应用一个全连接层,全连接层的作用是输入 32 个数字,在这 36 个单元上重复此过程) ,输出结果是 6×6×#filters(过滤器数量),以便在输入层上实施一个非平凡(non-trivial)计算。

这种方法通常称为 1×1 卷积,有时也被称为 Network in Network,在林敏、陈强和杨学成的论文中有详细描述。虽然论文中关于架构的详细内容并没有得到广泛应用,但是 1×1 卷积或 Network in Network 这种理念却很有影响力,很多神经网络架构都受到它的影响,包括 Inception 网络。
举个 1×1 卷积的例子,相信对大家有所帮助,这是它的一个应用。假设这是一个 28×28×192 的输入层,你可以使用池化层压缩它的高度和宽度,这个过程我们很清楚。但如果通道数量很大,该如何把它压缩为 28×28×32 维度的层呢?你可以用 32个大小为 1×1 的过滤器,严格来讲每个过滤器大小都是 1×1×192 维,因为过滤器中通道数量必须与输入层中通道的数量保持一致。但是你使用了 32 个过滤器,输出层为 28×28×32,这就是压缩通道数的方法,对于池化层我只是压缩了这些层的高度和宽度 。

在之后我们看到在某些网络中 1×1 卷积是如何压缩通道数量并减少计算的。当然如果你想保持通道数 192 不变,这也是可行的, 1×1 卷积只是添加了非线性函数,当然也可以让网络学习更复杂的函数,比如,我们再添加一层,其输入为 28×28×192,输出为 28×28×192。 1×1 卷积层就是这样实现了一些重要功能的(doing something pretty non-trivial),它给神经网络添加了一个非线性函数,从而减少或保持输入层中的通道数量不变,当然如果你愿意,也可以增加通道数量。
二 谷歌Inception模块
GoogLeNet在2014年获得了ILSVRC竞赛的冠军,GoogLeNet除了层数增加到22层之外,主要的创新在与它的Inception,这是一种网中网(Network In Network)的结构,即原来的节点也是一个网络。用了Inception之后整个网络结构的宽度和深度都可扩大,能带来2到3倍的性能提升,并且不会过拟合。
除此之外,GoogLeNet网络去除了最后的全连接层,用全局平均池化层(即使用与图片尺寸相同的过滤器来做平均池化)来取代它。
这么做的原因是:在以往的AlexNet和VGGNet网络中,全连接层几乎占据了90%的参数,占用了过多的运算内存使用率,而且还会引起过拟合。GoogLeNet的做法去除全连接层,使得模型训练更快并且减轻了过拟合,之后的GoogLeNet的Inception还在继续发展,目前已经有v2,v3,v4版本,但所有的这些变体都建立在同一种基础的思想上,主要针对解决深层网络的以下三个问题:
- 参数太多,容易过拟合,训练数据有限
- 网络越大计算复杂度越大,难以应用
- 网络越深,梯度越往后梯度容易消失
Inception的核心思想是要通过增加网络深度和宽度的同时减少参数的方法来解决问题,深度也就是网络中的层数,宽度指每层中所用到的神经元的个数。Inception v1有22层深,比AlexNet的8层或者VGG的16,19层更深,但其计算量只用15亿浮点运算,同时只用500万的参数,仅为AlexNet的参数(6000万)的1/12,却有着更高的准确率。
下面会详细介绍Inception模块。
构建卷积层时,你要决定过滤器的大小究竟是 1×1, 3×3 还是 5×5,或者要不要添加池化层。而 Inception 网络的作用就是代替你来决定,虽然网络架构因此变得更加复杂,但网络表现却非常好,我们来了解一下其中的原理。
例如,这是 28×28×192 维度的输入, Inception 网络或 Inception 层的作用就是代替人工来确定卷积层中的过滤器类型,或者确定是否需要创建卷积层或池化层,我们演示一下。

如果使用 1×1 卷积,输出结果会是 28×28×#(某个值),假设输出为 28×28×64。

如果使用 3×3 的过滤器,那么输出是 28×28×128。然后我们把第二个值堆积到第一个值上,为了匹配维度,我们应用 same 卷积,输出维度依然是 28×28,和输入维度相同,即高度和宽度相同。

或许你会说,我希望提升网络的表现,用 5×5 过滤器或许会更好,我们不妨试一下,输出变成 28×28×32,我们再次使用 same 卷积,保持维度不变。

或许你不想要卷积层,那就用池化操作,得到一些不同的输出结果,我们把它也堆积起来,这里的池化输出是 28×28×32。为了匹配所有维度,因为如果输入的高度和宽度为 28×28,则输出的相应维度也是28×28。我们需要对最大池化使用 padding,它是一种特殊的池化形式,然后再进行池化,padding 不变,步幅为 1。
这个操作非常有意思,但我们要继续学习后面的内容,一会再实现这个池化过程。

有了这样的 Inception 模块,你就可以输入某个量,因为它累加了所有数字,这里的最终输出为 32+32+128+64=256。 Inception 模块的输入为 28×28×129,输出为 28×28×256。这就是 Inception 网络的核心内容,提出者包括 Christian Szegedy、刘伟、贾阳青、Pierre Sermanet、Scott Reed、 Dragomir Anguelov、 Dumitru Erhan、 Vincent Vanhoucke 和 Andrew Rabinovich。基本思想是 Inception 网络不需要人为决定使用哪个过滤器或者是否需要池化,而是由网络自行确定这些参数,你可以给网络添加这些参数的所有可能值,然后把这些输出连接起来,让网络自己学习它需要什么样的参数,采用哪些过滤器组合。Inception的这种结构不仅增加了网络的宽度,还增减了网络对尺度的适应性。
下面我们来考虑一下Inception这种结构的计算成本,我们以5×5 过滤器为例 :

这是一个 28×28×192 的输入块,执行一个 5×5 卷积,它有 32 个过滤器,输出为 28×28×32。我们来计算这个 28×28×32 输出的计算成本,它有 32 个过滤器,因为输出有 32 个通道,每个过滤器大小为 5×5×192,输出大小为 28×28×32,所以你要计算 28×28×32 个数字。对于输出中的每个数字来说,你都需要执行 5×5×192 次乘法运算,所以乘法运算的总次数为每个输出值所需要执行的乘法运算次数(5×5×192)乘以输出值个数(28×28×32),把这些数相乘结果等于 1.2 亿。即使在现在,用计算机执行 1.2 亿次乘法运算,成本也是相当高的。
为了降低计算成本,Inception v1模型在原有的Inception模型基础上作了一下改进,Inception v1模型在3x3,5x5最大池化层前面分别加入了1x1的卷积核,起到了降低特征图厚度的作用(其中1x1卷积主要用来降维压缩通道数),下面我们会介绍 1×1 卷积的应用。

输入为 28×28×192,输出为 28×28×32。其结果是这样的,对于输入层,使用 1×1 卷积把输入值从 192 个通道减少到 16 个通道。然后对这个较小层运行5×5 卷积,得到最终输出。请注意,输入和输出的维度依然相同,输入是 28×28×192,输出是 28×28×32,和上一页的相同。但我们要做的就是把左边这个大的输入层压缩成这个较小的的中间层,它只有 16 个通道,而不是 192 个。

有时候这被称为瓶颈层,瓶颈通常是某个对象最小的部分,假如你有这样一个玻璃瓶,这是瓶塞位置,瓶颈就是这个瓶子最小的部分。
同理,瓶颈层也是网络中最小的部分,我们先缩小网络表示,然后再扩大它。
接下来我们看看这个计算成本,应用 1×1 卷积,过滤器个数为 16,每个过滤器大小为1×1×192,这两个维度相匹配(输入通道数与过滤器通道数), 28×28×16 这个层的计算成本是,输出 28×28×192 中每个元素都做 192 次乘法,用 1×1×192 来表示,相乘结果约等于 240万。

那第二个卷积层呢? 240 万只是第一个卷积层的计算成本,第二个卷积层的计算成本又是多少呢?这是它的输出, 28×28×32,对每个输出值应用一个 5×5×16 维度的过滤器,计算结果为 1000 万。所以所需要乘法运算的总次数是这两层的计算成本之和,也就是 1240 万,与上一张幻灯片中的值做比较,计算成本从 1.2 亿下降到了原来的十分之一,即 1240 万。所需要的加法运算与乘法运算的次数近似相等,所以我只统计了乘法运算的次数。
总结一下,如果你在构建神经网络层的时候,不想决定池化层是使用 1×1, 3×3 还是 5×5的过滤器,那么 Inception 模块就是最好的选择。我们可以应用各种类型的过滤器,只需要把输出连接起来。之后我们讲到计算成本问题,我们学习了如何通过使用 1×1 卷积来构建瓶颈层,从而大大降低计算成本。
你可能会问,仅仅大幅缩小表示层规模会不会影响神经网络的性能?事实证明,只要合理构建瓶颈层,你既可以显著缩小表示层规模,又不会降低网络性能,从而节省了计算。这就是 Inception 模块的主要思想,我们在这总结一下。后面我们将演示一个完整的 Inception 网络。
三 Inception网络
我们已经讲解了Inception 网络基础模块。在这里,我们将学习如何将这些模块组合起来,构筑你自己的 Inception 网络。

Inception 模块会将之前层的激活或者输出作为它的输入,作为前提,这是一个28×28×192 的输入,和我们之前视频中的一样。我们详细分析过的例子是,先通过一个 1×1的层,再通过一个 5×5 的层, 1×1 的层可能有 16 个通道,而 5×5 的层输出为 28×28×32,共32 个通道。

为了在这个 3×3 的卷积层中节省运算量,你也可以做相同的操作,这样的话 3×3 的层将会输出 28×28×128。

或许你还想将其直接通过一个 1×1 的卷积层,这时就不必在后面再跟一个 1×1 的层了,这样的话过程就只有一步,假设这个层的输出是 28×28×64。

最后是池化层。,这里我们要做些有趣的事情,为了能在最后将这些输出都连接起来,我们会使用 same类型的 padding 来池化,使得输出的高和宽依然是 28×28,这样才能将它与其他输出连接起来。但注意,如果你进行了最大池化,即便用了 same padding, 3×3 的过滤器, stride 为 1,其输出将会是 28×28×192,其通道数或者说深度与这里的输入(通道数)相同。所以看起来它会有很多通道,我们实际要做的就是再加上一个 1×1 的卷积层,去进行我们在 1×1 卷积层的视频里所介绍的操作,将通道的数量缩小,缩小到 28×28×32。也就是使用 32 个维度为1×1×192 的过滤器,所以输出的维度其通道数缩小为 32。 这样就避免了最后输出时,池化层占据所有的通道。
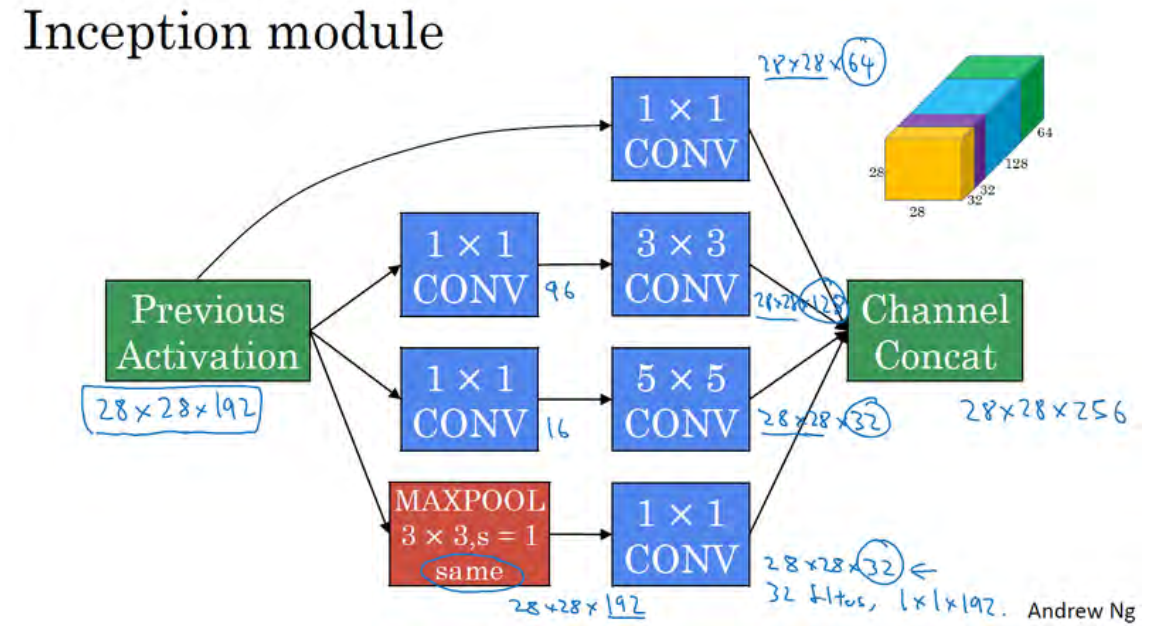
最后,将这些方块全都连接起来。在这过程中,把得到的各个层的通道都加起来,最后得到一个 28×28×256 的输出。这就是一个 Inception 模块,而 Inception 网络所做的就是将这些模块都组合到一起。
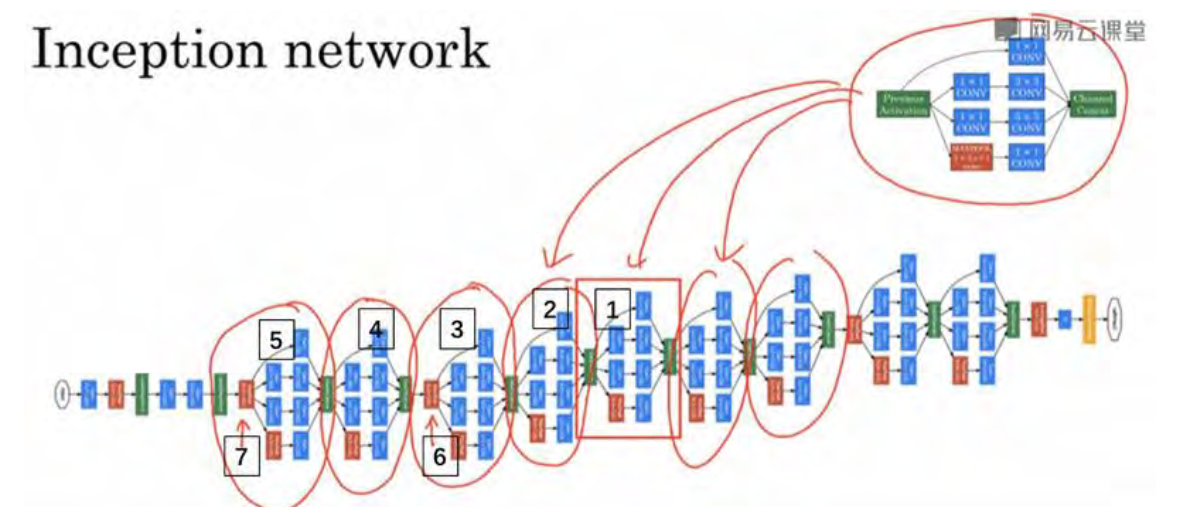
这是一张取自 Szegety et al 的论文中关于 Inception 网络的图片,你会发现图中有许多重复的模块,可能整张图看上去很复杂,但如果你只截取其中一个环节(编号 1),就会发现这就是我们讲解的 Inception 模块。
我们深入看看里边的一些细节, 你会发现 Inception 网络只是由很多inception模块在不同的位置重复组成的网络,所以如果你理解了Inception 模块,你就也能理解 Inception 网络。
下图是一个比较清晰的结构图:

事实上,如果你读过论文的原文,你就会发现,这里其实还有一些分支,我现在把它们加上去。对上图做如下说明:
- 网络最后采用了average pooling来代替全连接层,想法来自NIN,事实证明可以将TOP1 accuracy提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便以后大家finetune;
- 上图用到了辅助分类器,除了最后一层的输出,其中间节点的分类效果也很好。因此在Inception Net中,还使用到了辅助分类节点(auxiliary classifiers),即将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中。这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个Inception Net的训练很有裨益。
- 为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。文章中说这两个辅助的分类器的loss应该加一个衰减系数,但看caffe中的model也没有加任何衰减。此外,实际测试的时候,这两个额外的softmax会被去掉。
网络各层的详细参数如下图所示:
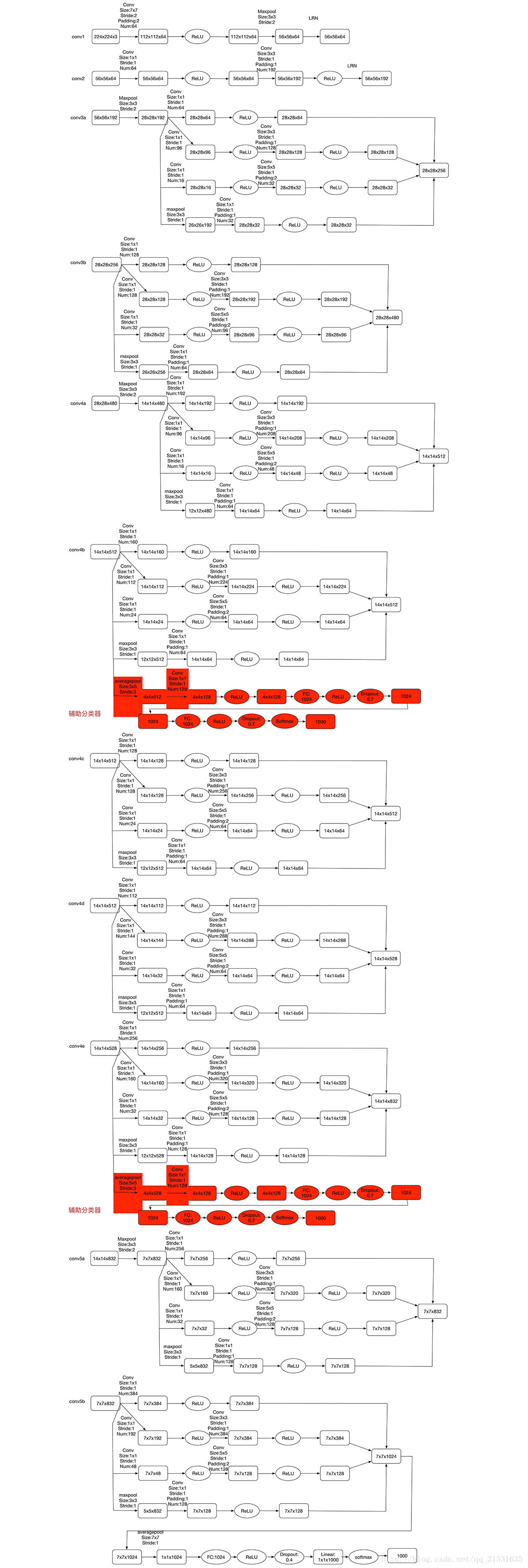
还有这个特别的 Inception 网络是由 Google公司的作者所研发的,它被叫做 GoogleLeNet,这个名字是为了向 LeNet 网络致敬。
参考文章
[1]Going deeper with convolutions
[2]系统学习深度学习(十九)--GoogLeNetV1,V2,V3
[3]Rethinking the Inception Architecture for Computer Vision
第十四节,卷积神经网络之经典网络Inception(四)的更多相关文章
- 第十三节,卷积神经网络之经典网络LeNet-5、AlexNet、VGG-16、ResNet(三)(后面附有一些网络英文翻译文章链接)
一 实例探索 上一节我们介绍了卷积神经网络的基本构建,比如卷积层.池化层以及全连接层这些组件.事实上,过去几年计算机视觉研究中的大量研究都集中在如何把这些基本构件组合起来,形成有效的卷积神经网络.最直 ...
- 深度学习——卷积神经网络 的经典网络(LeNet-5、AlexNet、ZFNet、VGG-16、GoogLeNet、ResNet)
一.CNN卷积神经网络的经典网络综述 下面图片参照博客:http://blog.csdn.net/cyh_24/article/details/51440344 二.LeNet-5网络 输入尺寸:32 ...
- 深度学习方法(十):卷积神经网络结构变化——Maxout Networks,Network In Network,Global Average Pooling
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 最近接下来几篇博文会回到神经网络结构 ...
- 深度学习方法(五):卷积神经网络CNN经典模型整理Lenet,Alexnet,Googlenet,VGG,Deep Residual Learning
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 关于卷积神经网络CNN,网络和文献中 ...
- 第十六节,卷积神经网络之AlexNet网络实现(六)
上一节内容已经详细介绍了AlexNet的网络结构.这节主要通过Tensorflow来实现AlexNet. 这里做测试我们使用的是CIFAR-10数据集介绍数据集,关于该数据集的具体信息可以通过以下链接 ...
- 第十五节,卷积神经网络之AlexNet网络详解(五)
原文 ImageNet Classification with Deep ConvolutionalNeural Networks 下载地址:http://papers.nips.cc/paper/4 ...
- DeepLearning.ai学习笔记(四)卷积神经网络 -- week2深度卷积神经网络 实例探究
一.为什么要进行实例探究? 通过他人的实例可以更好的理解如何构建卷积神经网络,本周课程主要会介绍如下网络 LeNet-5 AlexNet VGG ResNet (有152层) Inception 二. ...
- DeepLearning.ai学习笔记(四)卷积神经网络 -- week4 特殊应用:人力脸识别和神经风格转换
一.什么是人脸识别 老实说这一节中的人脸识别技术的演示的确很牛bi,但是演技好尴尬,233333 啥是人脸识别就不用介绍了,下面笔记会介绍如何实现人脸识别. 二.One-shot(一次)学习 假设我们 ...
- DeepLearning.ai学习笔记(四)卷积神经网络 -- week1 卷积神经网络基础知识介绍
一.计算机视觉 如图示,之前课程中介绍的都是64* 64 3的图像,而一旦图像质量增加,例如变成1000 1000 * 3的时候那么此时的神经网络的计算量会巨大,显然这不现实.所以需要引入其他的方法来 ...
随机推荐
- Python魔法方法(magic method)细解几个常用魔法方法(上)
这里只分析几个可能会常用到的魔法方法,像__new__这种不常用的,用来做元类初始化的或者是__init__这种初始化使用的 每个人都会用的就不介绍了. 其实每个魔法方法都是在对内建方法的重写,和做像 ...
- 如何在网页中用echarts图表插件做出静态呈现效果
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- bash中的pasue
#!/bin/bash echo 按任意键继续 read -n
- fiddler学习笔记2 字段说明;移动设备、解密证书
# : 抓取顺序从1开始递增 result: http 请求状态 protocol: 请求使用的协议如:http https ftp Host: 请求地址 ...
- Java多线程之synchronized线程锁
package org.study2.javabase.ThreadsDemo.sync; /** * @Auther:GongXingRui * @Date:2018/9/18 * @Descrip ...
- Spring 使用介绍(八)—— 零配置(一)
一.概述 所谓零配置,并不是说一点配置都没有了,而是配置很少而已.通过约定来减少需要配置的数量,提高开发效率. 零配置实现主要有以下两种方式: 惯例优先原则:也称为约定大于配置(convention ...
- [Codeforces235D]Graph Game——概率与期望+基环树+容斥
题目链接: Codeforces235D 题目大意:给出一棵基环树,并给出如下点分治过程,求点数总遍历次数的期望. 点分治过程: 1.遍历当前联通块内所有点 2.随机选择联通块内一个点删除掉 3.对新 ...
- Luogu4726 【模板】多项式指数函数(NTT+多项式求逆)
https://www.cnblogs.com/HocRiser/p/8207295.html 安利! #include<iostream> #include<cstdio> ...
- 数据库 -- pymysql
pythen3连接mysql pymsql介绍 PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2中则使用mysqldb. Django中也可以使用P ...
- 洛谷P1092 虫食算(算竞进阶习题)
模拟+dfs 这个题就三行,搜索的话我们从右向左,从上到下.. 如果是在1,2行我们就直接枚举0-n所有数,但是到了第三行,最直接的就是填上这一列上前两行的数的和modN,在此基础上判断该填的数有没有 ...