Notes on Distributed System -- Distributed Hash Table Based On Chord
1 Design document
1.1 System overview
We implemented a Book Finder System using a distributed hash table (DHT) based on the Chord protocol. Using this system, the client can set and get the book’s information (title and genre for simplicity) using the DHT. The whole system is composed of 1 supernode, 1 client (or more clients), and several compute nodes.
The client will deal with Set and Get request. It will get a node address from the supernode first. Then it sends the request to the node via Thrift.
The supernode could listen to requests from the client, and record the information of nodes. When a node wants to join the DHT, it contacts the SuperNode using Thrift. The SuperNode will then return one of the nodes information. The client will contact the SuperNode, and SuperNode will return node information randomly chosen.
The nodes will store the book information and keep the DHT table. Each node will maintain a predecessor pointer, a successor pointer, and a FingerTable for fast searching in chord ring. The FingerTable will be updated when a new node is added into the system. Also, the data will be stored on different node based on the hash value of BookTitle. When client do a get/set operation, the operation will be forwarded to appropriate node based on searching result in FingerTable.
pa2要求实现一个分布式key-value hash table,存储图书名和对应的类别供用户查询(就set、get两种操作)。DHT基于Chord协议。Chord的原理可以参考https://program-think.blogspot.com/2017/09/Introduction-DHT-Kademlia-Chord.html,这里也介绍一下:
DHT是去中心化的,节点数量也是会动态变化的(但作业里不考虑这个)。在一致性哈希中,我们把哈希值唯一确定,之后映射到一个圆环中。 那么,当分布式出现崩溃或新增节点的情况时,只会影响圆环中的一部分。
在Chord协议中,所有的node(每台node有一个unique node ID)和数据(<key=hash(DAT), val=DAT>)都用m位的哈希函数映射到圆环上(圆环表示chord空间。设M位的哈希函数,那么环上的取值范围就是0 ~ (2^m)-1)。每个数据都存储到它顺时针方向的第一个node上。每个node都有指针指向上一个/下一个的ip地址(类似双向循环链表)。如图所示:
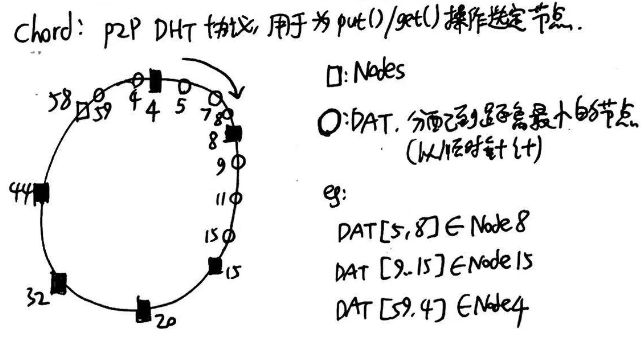
按照目前这个思路,设client连接到了某个node,想set或get一条数据,就直接顺着这个环遍历node就可以了。但是一个一个遍历太慢啦。有什么方法可以跳过一些肯定找不到所需数据的node呢?
FingerTable就是这样一个路由算法,可以实现在log(N)的时间内找到目标节点。“Finger Table”是一个列表,最多包含 m 项(m 就是散列值的比特数),每一项都是节点 ID。假设当前节点的 ID 是 n,那么表中第 i 项的值是:successor( (n + 2^i) mod 2^m ) 。在查找的时候,当收到请求(key)时,就到“Finger Table”中找到【最大的且不超过 key】的那一项,然后把 key 转发给这一项对应的节点。如下图就是m=7时的一个DHT(范围0-127),以及Node #80的Finger Table:
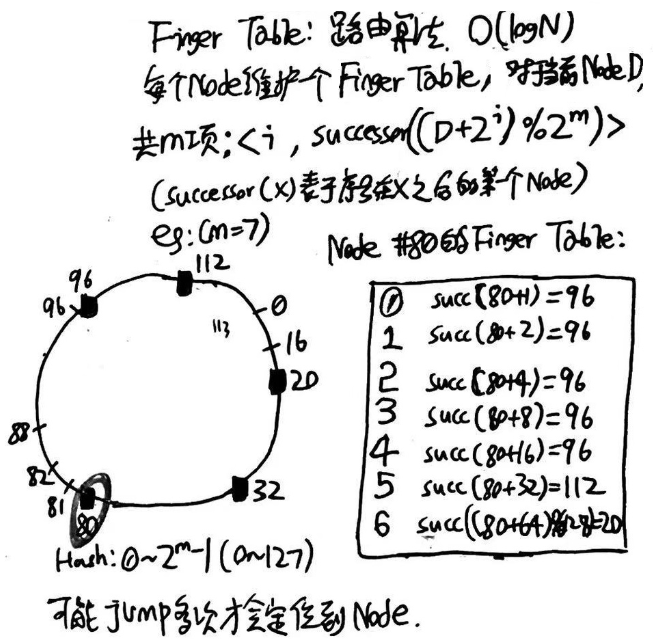
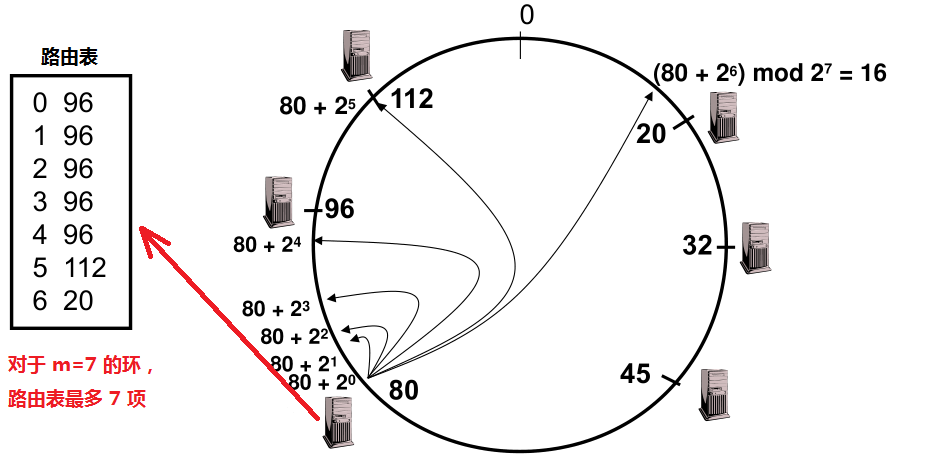
下面来看看具体实现叭
整个系统由若干client,一个supernode,若干个node组成。You will need to implement multi-threaded server for a node as there can be multiple clients in the system at the same time.
- SuperNode负责存储所有node的信息和generate node ID,在创建DHT时所有node都要联系SuperNode来获得node ID等信息。
- 每个node维护自己的FingerTable,存储自己负责的数据,并且有successor, predecessor两个指针。node还负责与client进行交互。若client要找的数据不在本地,node会查FingerTable表,并把请求forward到对应的node。
- client进行操作时,首先联系SuperNode,由SuperNode返回一个node。然后client连接这个node进行后续的操作。
1.2 Assumptions
We made these assumptions in this system:
- Each Node can either run on same or different machine on its own port.
- More than 2 Thrift Interface files are needed (for SuperNode and Nodes).
- The Nodes will act as client of SuperNode for joining phase for forming DHT and will act as a server for handling requests from the client.
- SuperNode should not maintain any state about the DHT (only the list of nodes)
- The genre will be updated if a client sets a different genre for a book title.
- The system does not need to be persistent in this project.
- The number of nodes for DHT can be set when the SuperNode starts as a parameter. (This will let the SuperNode know the DHT is ready)
- No node failures or nodes leaving the DHT after they've joined.
1.3 Component design
1.3.1 Common part
In the common part, we defined a Thrift struct Address, which is used to describe a node (IP, port, NodeID).
1.3.2 Client
The client accepts a task from users.
client启动时rpc到SuperNode,获得一个node,之后用户的set / get操作都rpc到这个node上进行。
To initiate it, input “java -cp ".:/usr/local/Thrift/*" Client <serverIP> <serverPort>”, for example, “java -cp ".:/usr/local/Thrift/*" Client csel-kh1250-01 9090”.
To set a book with the genre, input Set “Book_title” “Genre” (“” are required), for example, Set “Harry Potter” “Magic”. The server will return the trace and the node who stores this book.
To reset a book with a genre, just input Set “Book_title” “Genre” (“” are required) again, for example, Set “Harry Potter” “Magic and Children”.
To set books and genres with a file. Input Set “filename”, for example, Set “../shakespeares.txt”.
To get books’ genres, input Get “Book_title”, for example, Get “Harry Potter”. If the book exists, the server will return trace with the node who stores this book, and its genre. If the book does not exist, the server will return an error message.
To quit the program, type in Quit.
1.3.3 Supernode
To initiate the supernode, input java -cp ".:/usr/local/Thrift/*" SuperNode Port NodeNumber, for example, “java -cp ".:/usr/local/Thrift/*" SuperNode 9090 5”.
Also, we support user-defined chord length. The command-line will be java -cp ".:/usr/local/Thrift/*" SuperNode Port NodeNumber ChordLen. Then the range of chord ring will be 0-(2^ChordLen). ChordLen will be 7 if it is not defined explicitly.
SuperNode上维护了以下数据结构:
- (CopyOnWriteArrayList相当于一个并发性能更好的vector https://www.cnblogs.com/myseries/p/10877420.html。Vector是增删改查方法都加了synchronized,保证同步,但是每个方法执行的时候都要去获得锁,性能就会大大下降。而CopyOnWriteArrayList 只是在增删改上加锁,但是读不加锁,在读方面的性能就好于Vector,CopyOnWriteArrayList支持读多写少的并发情况。)
- CopyOnWriteArrayList CurrentNodes:存储所有的node列表
- CopyOnWriteArrayList PossibleKeys:存储所有可用的node ID
- ConcurrentHashMap NodeKeys:存储所有的node和对应的ID
The supernode implements the following methods:
1. Join(IP, Port): When a node wants to join the DHT, the SuperNode will then return one of nodes information to implement updatedht process. If the SuperNode is busy in join process of another node, it will return a “NACK” to the requesting node and let the node wait. Node加入时会rpc调用SuperNode的Join()。Join()会返回之前加入过的node中最新的那个,新node就加入到这个node的后面(如果新node是第一个进来的,返回"Empty")。
2. PostJoin(IP, Port): After the node is done to join the DHT, it should notify the SuperNode about it. The supernode will then add the node information to the nodelist and allow other nodes to join the DHT. (node在Join()之后会进行一些操作来加入chord,加入完成后rpc调用SuperNode的PostJoin()。SuperNode会记下这个节点的ip地址、id等信息,然后返回true结束加入过程。)
另外,当一个node执行了Join()后,SuperNode上会加锁,其他node试图Join()时就只能忙等(不停收到"NACK")。PostJoin()之后才会解锁。这样保证同时只有一个节点在加入。
3. GetNode(): The client will contact the SuperNode and it will return node information randomly chosen. The client may contact SuperNode only once when the client is running or every time when the client sends a request for testing purpose. Client通过rpc调用SuperNode的GetNode()来获取一个node
4. GetPossibleKey(), after the node call join, it can call the GetPossibleKey() to get the key that can be assigned to it. node在Join()之后,调用该rpc函数来获取自己的node ID
5. GetHashPara(), the node can get the parameter of hash function from it.
1.3.4 Node
To initiate the node, input “java -cp ".:/usr/local/Thrift/*" Node <serverIP> <serverPort> <nodePort>”, for example, “java -cp ".:/usr/local/Thrift/*" Node csel-kh1250-01 9090 9092”.
To make the supernode ready for client, it should get NodeNumber Nodes (For example, 5 postjoin calls).
Node上维护了以下数据结构:
- Address Successor:指向该node的后继node
- Address Predecessor:指向该node的前驱node
- ConcurrentHashMap Dict:本地的Hash Table
- FingerItem[] FingerTable:本地的FingerTable
其中FingerItem类包括如下信息:
public class FingerItem{ //For FingerTable[i],
Address Node; // Node = Successor(FingerTable[i].start)
long ivx; long ivy; // [ivx, ivy) = [FingerTable[i].start, FingerTable[i+1].start)
long start; // start = (NodeInfo.ID+(long)(Math.pow(2,i-1))) % (long)(Math.pow(2,ChordLen)))
public FingerItem(Address _Node, long _ivx, long _ivy, long _start) {
Node=_Node;
ivx=_ivx;
ivy=_ivy;
start=_start;
}
public static long FingerCalc(long _n, int _k, int _m) {
if (_k == _m + 1)
return (_n);
else
return ((_n + (long) (Math.pow(2, _k - 1))) % (long) (Math.pow(2, _m)));
}
public void PrintItem(int i){
System.out.println("FingerItem"+i+" "+Node+" "+ivx+"_"+ivy+" : "+start);
}
}
The Node will contain an interface for the client and other nodes. Following calls to the Node are implemented:
1. Set(Book_title, Genre, chain): When a client wants to set a book title and a genre, it contacts the Node using Thrift. The node will check whether it needs to store information locally or not. If it is not the node for the book title, it will forward the request to other nodes recursively. The chain is used for tracing involved nodes. 首先对key进行hash。如果该key存在本地,则直接set本地。否则调用FindSuccessor(hash_of_key)找到负责该hash值的node(也就是该点的successor,顺时针方向第一个),并rpc调用该node上的Set()
2. Get(Book_title, chain): When a client wants to know a genre with a book title, it contacts the Node using Thrift. The Node will check whether it is the node for the book title. If not, it will forward the request to other nodes recursively. The chain is used for tracing involved nodes. 首先对key进行hash。如果该key存在本地,则直接get本地。否则调用FindSuccessor(hash_of_key)找到负责该hash值的node(也就是该点的successor,顺时针方向第一个),并rpc调用该node上的Get()
3. UpdateDHT(Address NN, int IDX, List<Long> chain): On the new node, The IDX item in FingerTable will be updated to node NN. Then the new node will contact the involved nodes in the finger table to let them update DHT. When the node finishes calling to all nodes, it will let the SuperNode know that it is done to join by calling PostJoin().
4. HashKey(String key, int MODbit): calculate the hash value of key string.
5. FindSuccessor(ID): Find successor of an arbitrary point ID in chord ring. 调用FindPredecessor(ID)找到ID在chord环上的Predecessor,然后rpc调用该Predecessor上的GetSuccessor(),这样也就找到了ID点的successor。
6. FindPredecessor(MID): Find predecessor of an arbitrary point ID in chord ring. 找到MID在chord环上的Predecessor。若当前node不负责MID所在的这一区域(不满足node.ID < MID < node.Successor.ID),则需要FindClosetPrecedingFinger(MID)找到MID的前驱,然后在这个node上再找。
7. FindClosetPrecedingFinger(MID): Find the closet predecessor of an arbitrary point #MID on chord ring, by finding in Finger Table 找到在当前node的FingerTable中,距离MID最近的Predecessor(node.ID < FingerTable[i].ID < MID)。如下图:
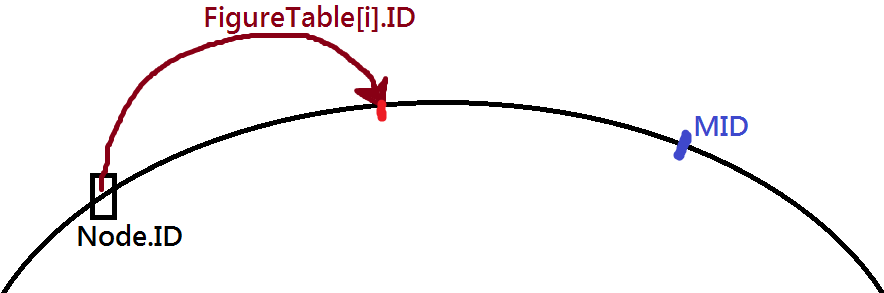
8. InSet(long _x, long _i, long _y, int ll, int rr): Check whether _i is in the (_x, _y) set in chord ring clockwise order. 检查在Chord环上是否满足tx<ti<ty
9. InitNode(): Initialize all the variables in the new node. Find its predecessor and successor, and call UpdateDHT(). 调用SuperNode的Join()通知当前node的加入,等SuperNode通知可以加入后,SuperNode会返回一个node的信息,表示当前node加到这个node的后面。然后加入当前node:初始化Predecessor、successor等信息(类似双向循环链表中加入节点),初始化自己的FingerTable(根据自身的前驱的FingerTable信息),然后rpc调用前驱节点的UpdateDHT()来更新它们的FingerTable。最后调用PostJoin()通知SuperNode自己加入完成了。
10. GetSuccessor(), GetPredecessor(): 返回当前节点的Successor/Predecessor.
11. SetSuccessor(), SetPredecessor(): 设置当前节点的Successor/Predecessor.
2 User document
2.1 How to compile
We have written a make script to compile the whole project.
cd pa2/src
./make.sh
2.2 How to run the project
. Run supernode
cd pa2/src/
java -cp ".:/usr/local/Thrift/*" SuperNode Port NodeNumber
<Port>: The port of super
<NodePort>: The port of node
<NodeNumber>: Number of nodes
Eg. java -cp ".:/usr/local/Thrift/*" SuperNode
. Run compute node
Start compute node on different machines.
cd pa2/src/
java -cp ".:/usr/local/Thrift/*" Node <serverIP> <serverPort> <nodePort>
<ServerIP>: The ip address of server
<ServerPort>: The port of server
<NodePort>: The port of node
Eg: java -cp ".:/usr/local/Thrift/*" Node csel-kh1250-
. Run client
cd pa2/src/
java -cp ".:/usr/local/Thrift/*" Client <serverIP> <serverPort>
<ServerIP>: The ip address of supernode
<ServerPort>: The port of supernode
E.g. java -cp ".:/usr/local/Thrift/*" Client csel-kh1250-
Set "Harry Potter" "magic"
Get “Harry Potter”
Get “Harry”
Set “Harry Potter” “child”
Set “../shakespeares.txt”
2.3 What will happen after running
The results and log(node searching trace) will be output on the screen. You will be asked to input the next command.
3 Testing Document
3.1 Testing Environment
Machines:
We use 7 machines to perform the test, including 1 supernode machine (csel-kh1250-01), 5 computeNode machines (csel-kh4250-03, csel-kh4250-01, csel-kh4250-22, csel-kh4250-25, csel-kh4250-34), 1 client machine (csel-kh1250-03).
Test Set:
We use a test set (../shakespeares.txt) including 42 items, totally 1.1 kB. The data uses a shared directory via NSF.
Logging:
Trace Logging is output on the window.
Testing Settings:
We test positive test case – where the book title is present in the DHT and negative test case – where the book title is not present in the DHT. And also other tests.
3.2 Join and PostJoin
The successfully joined node will print its ID, successor, predecessor, and FingerTable as follows:
NODE INFO: Successfully joined SuperNode. My ID is , and ChordLen=
Returned JointRes==csel-kh4250-.cselabs.umn.edu :
My Successor is Address(ip:csel-kh4250-.cselabs.umn.edu, port:, ID:) . My Predecessor is Address(ip:csel-kh4250-.cselabs.umn.edu, port:, ID:)
__________________________________________________
| Print Finger Table |
__________________________________________________
|| || Address(ip:csel-kh4250-.cselabs.umn.edu, port:, ID:) || ||
|| || Address(ip:csel-kh4250-.cselabs.umn.edu, port:, ID:) || ||
|| || Address(ip:csel-kh4250-.cselabs.umn.edu, port:, ID:) || ||
|| || Address(ip:csel-kh4250-.cselabs.umn.edu, port:, ID:) || ||
|| || Address(ip:csel-kh4250-.cselabs.umn.edu, port:, ID:) || ||
|| || Address(ip:csel-kh4250-.cselabs.umn.edu, port:, ID:) || ||
|| || Address(ip:csel-kh4250-.cselabs.umn.edu, port:, ID:) || ||
__________________________________________________
When another new node is added and the Finger Table of this node is updated, it will print its updated Finger Table again.
Supernode output:
Postjoin csel-kh4250-.cselabs.umn.edu:
Postjoin csel-kh4250-.cselabs.umn.edu:
Postjoin csel-kh4250-.cselabs.umn.edu:
Postjoin csel-kh4250-.cselabs.umn.edu:
Postjoin csel-kh4250-.cselabs.umn.edu:
Stability Test: Join multiple nodes at the same time:
Node output:
NODE INFO: Try joining SuperNode…
NODE INFO: Try joining SuperNode…
NODE INFO: Try joining SuperNode…
NODE INFO: Try joining SuperNode…
In this case, only one node will join first, while other nodes will wait for the change for joining.
3.2 Set Book and Genre
1) With Book and Genre as input
Set "Harry Potter" "magic"
[Harry Potter is set on machine with hash value= ]Trace(, , , )
Succeed to set: Harry Potter magic
When doing Set/Get task, the client command line will return its result, and all the nodes involved (including the node directly communicate with client, the nodes passed when forwarding, and the node physically saving this record). All the visited nodes will be successively printed in Trace() field.
2) With Filename
Set "../shakespeares.txt"
[All's Well That Ends Well is set on machine 50 with hash value= 35]Trace(75, 25, 50, )
Succeed to set: All's Well That Ends Well Comedies
[As You Like It is set on machine with hash value= ]Trace(, , , )
Succeed to set: As You Like It Comedies
[The Comedy of Errors is set on machine with hash value= ]Trace(, , , )
Succeed to set: The Comedy of Errors Comedies
[Love's Labor's Lost is set on machine with hash value= ]Trace(, , , )
Succeed to set: Love's Labor's Lost Comedies
[Measure for Measure is set on machine with hash value= ]Trace(, , , )
Succeed to set: Measure for Measure Comedies
[The Merchant of Venice is set on machine with hash value= ]Trace(, , , )
Succeed to set: The Merchant of Venice Comedies
…...
3) Reset book and genre
Set "Harry Potter" "magic and
children"
[Harry Potter is set on machine with hash value= ]Trace(, , , )
Succeed to set: Harry Potter magic and children
In this sample, the key is “Harry Potter” and the value is “magic and children”. It is set on machine 0 because the hash value of its key is 120. When setting this key, it visited node 75, 100, 0 successively.
3.3 Get
1) Positive: File exists
Get "Harry Potter"
Succeed to get: Harry Potter.
[Harry Potter:magic and children is get on machine with hash value= ]Trace(, , , )
In this sample, “Harry Potter:magic and children” means the key is “Harry Potter” and the value is “magic and children”. It is found on machine 0 because the hash value of its key is 120. When getting this key, it visited node 75, 100, 0 successively.
2) Negative: key does not exist
Get "Filename in Dream"
ERROR[Filename in Dream is NOT FOUND on machine with hash value= ]Trace(, , )
Failed to find: Filename in Dream
In this sample, the key “Filename in Dream” should be on machine 100 because the hash value of its key is 89. When trying to get this key, it visited node 75, 100 successively. But the key does not exist.
3.4 Printing Trace Log
After each Set() and Get() operation, the system will print all nodes it passed when executing, in the trace() field.

Note: According to the algorithm in the reference paper, the find_processor() function will always pass the predecessor of the end point in the path, and then check whether the next point should end this finding process.
3.5 Invalid Command
When typing invalid command, the system will show error message.
WrongCommand "Book"
Wrong Command: please input again
Input Command: Set Book_title Genre|Set Filename|Get Book_title|Quit
下面是写作业过程中的一点笔记:
task: 基于Chord实现一个Hash Table
我负责写Node,队友写SuperNode和Client。总体参考paper[Stoica et al., 2001]上的伪代码
FindSuccessor(key):对chord环上的任意一个key,返回他的successor
FindPredecessor(key):对chord环上的任意一个key,返回他的Predecessor
n.Closet_Preceding_Finger(key):对chord环上的任意一个key,在node n的Finger table中查找它的最近的Predecessor
注意几个坑点:
1. 在UpdateDHT时,因为这个函数是被递归调用的,所以有可能会出现若干个node形成infinite loop的情况。解决方法就是在updateDHT函数入口设置一个List来记录visited过的节点,如果下次遇到重复的就退出。
2. 在FindSuccesor / FindPredecessor里,假设这个书名就该在自己node上 那findsuccessor里就不需要rpc,直接访问自己的的successor就行了。这个需要特别判断一下,不然自己rpc自己是会崩的
3. 在UpdateDHT的伪代码中,if(s属于[n, finger[i].node)) 这里在测试中发现有问题。我们改成了if(finger[i].start属于[finger[i].node, s])解决了问题。它表示对于finger[i]这一项,新节点s比该项的当前值finger[i].node靠后,且是该节点能触到的位置finger[i].start的successor,所以要更新。 (所以顶会论文也会出错么?
FingerTable的实现:
public class FingerItem{ //For FingerTable[i],
Address Node; // Node = Successor(FingerTable[i].start)
long ivx; long ivy; // [ivx, ivy) = [FingerTable[i].start, FingerTable[i+1].start)
long start; // start = (NodeInfo.ID+(long)(Math.pow(2,i-1))) % (long)(Math.pow(2,ChordLen)))
public FingerItem(Address _Node, long _ivx, long _ivy, long _start) {
Node=_Node;
ivx=_ivx;
ivy=_ivy;
start=_start;
}
public static long FingerCalc(long _n, int _k, int _m) {
if (_k == _m + 1)
return (_n);
else
return ((_n + (long) (Math.pow(2, _k - 1))) % (long) (Math.pow(2, _m)));
}
public void PrintItem(int i){
System.out.println("FingerItem"+i+" "+Node+" "+ivx+"_"+ivy+" : "+start);
}
}
FingerItem[ChordLen] FingerTable;
Notes on Distributed System -- Distributed Hash Table Based On Chord的更多相关文章
- Spell checker using hash table
Problem description Given a text file, show the spell errors from it. (https://www.andrew.cmu.edu/c ...
- DHT(Distributed Hash Table) Translator
DHT(Distributed Hash Table) Translator What is DHT? DHT is the real core of how GlusterFS aggregates ...
- DHT(Distributed Hash Table,分布式哈希表)
DHT(Distributed Hash Table,分布式哈希表)类似Tracker的根据种子特征码返回种子信息的网络. DHT全称叫分布式哈希表(Distributed Hash Table),是 ...
- 分布式系统(Distributed System)资料
这个资料关于分布式系统资料,作者写的太好了.拿过来以备用 网址:https://github.com/ty4z2008/Qix/blob/master/ds.md 希望转载的朋友,你可以不用联系我.但 ...
- 译《Time, Clocks, and the Ordering of Events in a Distributed System》
Motivation <Time, Clocks, and the Ordering of Events in a Distributed System>大概是在分布式领域被引用的最多的一 ...
- Aysnc-callback with future in distributed system
Aysnc-callback with future in distributed system
- Note: Time clocks and the ordering of events in a distributed system
http://research.microsoft.com/en-us/um/people/lamport/pubs/time-clocks.pdf 分布式系统的时钟同步是一个非常困难的问题,this ...
- Hash table: why size should be prime?
Question: Possible Duplicate:Why should hash functions use a prime number modulus? Why is it necessa ...
- 散列表(hash table)——算法导论(13)
1. 引言 许多应用都需要动态集合结构,它至少需要支持Insert,search和delete字典操作.散列表(hash table)是实现字典操作的一种有效的数据结构. 2. 直接寻址表 在介绍散列 ...
随机推荐
- Apple watch ,小米微信通知
Applewatch怎么显示微信通知?iWatch显示微信消息通知设置方法.大家都知道Applewatch上收到微信消息,iWatch是不会显示通知的,需要用户自行设置才行.下面小编来教大家如何设置A ...
- Collections与Collection
Collection是集合体系的最顶层,包含了集合体系的共性 Collections是一个工具类,方法都是用用Collection Collections方法: //static int binary ...
- C# 自制报表组件 EzReportBuild 2.0
组件无闪烁.画面流畅,效率一般,支持SQL和ACCESS两种.可以完成报表设计.预览.打印等功能,提供接口函数,可以将设计.预览等嵌入到自定的winform中调用,使用简单.每份报表可设置多页,每页可 ...
- 基于Eureka的服务治理
代码地址如下:http://www.demodashi.com/demo/11927.html 一.服务的注册与发现 关系调用说明: 服务生产者启动时,向服务注册中心注册自己提供的服务 服务消费者启动 ...
- java中LIst转换成Json
List转换成json串 public String getNameListByID(Long Id) { List<Name> nameLists= nameService.select ...
- vue 配置了全局的http拦截器,单独某个组件不需要这个拦截器,如何设置
之前写过关于全局配置http拦截器的随笔,现在有个需求,在微信支付时,生成二维码,页面显示一个遮罩层,二维码页面需要每两秒请求一次接口,若返回结果为已支付,则进行页面跳转,但因为全局http中load ...
- The declared package does not match the expected package Java
今天使用vscode 编写java代码做测试时候,发现这个问题,大概总结一下. 目录结构 bao -> Point.java test.java package bao; public clas ...
- 分析abex-crackme#1
1.分析环境2.运行程序,了解大致的运行过程3.运行Ollydbg调试程序3.1.分析结果简述4.破解4.1.方法一4.2.方法二5.运行结果6.与书中不同之处 1.分析环境 操作系统:Win10 1 ...
- Unity3D UI适配
直接贴图
- Isight 命令行运行任务
说明书参考:https://abaqus-docs.mit.edu/2017/English/DSSIMULIA_Established.htm 不一定对版本.但是大部分还可以. 不对的可以在命令里敲 ...