ELM:ELM基于近红外光谱的汽油测试集辛烷值含量预测结果对比—Jason niu
%ELM:ELM基于近红外光谱的汽油测试集辛烷值含量预测结果对比—Jason niu
load spectra_data.mat
temp = randperm(size(NIR,1)); P_train = NIR(temp(1:50),:)';
T_train = octane(temp(1:50),:)'; P_test = NIR(temp(51:end),:)';
T_test = octane(temp(51:end),:)';
N = size(P_test,2); [Pn_train,inputps] = mapminmax(P_train);
Pn_test = mapminmax('apply',P_test,inputps); [Tn_train,outputps] = mapminmax(T_train);
Tn_test = mapminmax('apply',T_test,outputps); [IW,B,LW,TF,TYPE] = elmtrain(Pn_train,Tn_train,30,'sig',0); tn_sim = elmpredict(Pn_test,IW,B,LW,TF,TYPE); T_sim = mapminmax('reverse',tn_sim,outputps); result = [T_test' T_sim']; E = mse(T_sim - T_test); N = length(T_test);
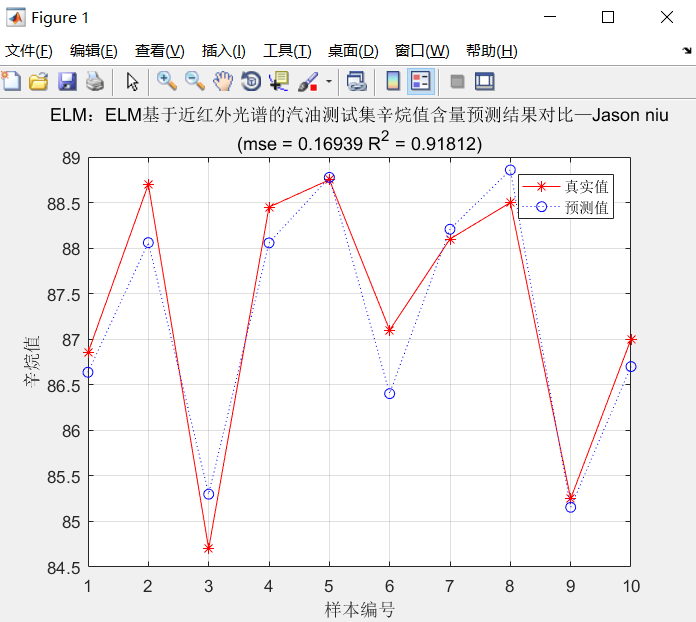
R2=(N*sum(T_sim.*T_test)-sum(T_sim)*sum(T_test))^2/((N*sum((T_sim).^2)-(sum(T_sim))^2)*(N*sum((T_test).^2)-(sum(T_test))^2)); figure(1)
plot(1:N,T_test,'r-*',1:N,T_sim,'b:o')
grid on
legend('真实值','预测值')
xlabel('样本编号')
ylabel('辛烷值')
string = {'ELM:ELM基于近红外光谱的汽油测试集辛烷值含量预测结果对比—Jason niu';['(mse = ' num2str(E) ' R^2 = ' num2str(R2) ')']};
title(string)
ELM:ELM基于近红外光谱的汽油测试集辛烷值含量预测结果对比—Jason niu的更多相关文章
- RBF:RBF基于近红外光谱的汽油辛烷值含量预测结果对比—Jason niu
load spectra_data.mat temp = randperm(size(NIR,1)); P_train = NIR(temp(1:50),:)'; T_train = octane(t ...
- PLS:利用PLS(两个主成分的贡献率就可达100%)提高测试集辛烷值含量预测准确度并《测试集辛烷值含量预测结果对比》—Jason niu
load spectra; temp = randperm(size(NIR, 1)); P_train = NIR(temp(1:50),:); T_train = octane(temp(1:50 ...
- PCA:利用PCA(四个主成分的贡献率就才达100%)降维提高测试集辛烷值含量预测准确度并《测试集辛烷值含量预测结果对比》—Jason niu
load spectra; temp = randperm(size(NIR, 1)); P_train = NIR(temp(1:50),:); T_train = octane(temp(1:50 ...
- NN:实现BP神经网络的回归拟合,基于近红外光谱的汽油辛烷值含量预测结果对比—Jason niu
load spectra_data.mat plot(NIR') title('Near infrared spectrum curve—Jason niu') temp = randperm(siz ...
- ELM:ELM实现鸢尾花种类测试集预测识别正确率(better)结果对比—Jason niu
load iris_data.mat P_train = []; T_train = []; P_test = []; T_test = []; for i = 1:3 temp_input = fe ...
- GRNN/PNN:基于GRNN、PNN两神经网络实现并比较鸢尾花种类识别正确率、各个模型运行时间对比—Jason niu
load iris_data.mat P_train = []; T_train = []; P_test = []; T_test = []; for i = 1:3 temp_input = fe ...
- Azure上搭建ActiveMQ集群-基于ZooKeeper配置ActiveMQ高可用性集群
ActiveMQ从5.9.0版本开始,集群实现方式取消了传统的Master-Slave方式,增加了基于ZooKeeper+LevelDB的实现方式. 本文主要介绍了在Windows环境下配置基于Zoo ...
- 机器学习基础:(Python)训练集测试集分割与交叉验证
在上一篇关于Python中的线性回归的文章之后,我想再写一篇关于训练测试分割和交叉验证的文章.在数据科学和数据分析领域中,这两个概念经常被用作防止或最小化过度拟合的工具.我会解释当使用统计模型时,通常 ...
- 基于开源软件构建高性能集群NAS系统,包括负载均衡(刘爱贵)
大数据时代的到来已经不可阻挡,面对数据的爆炸式增长,尤其是半结构化数据和非结构化数据,NoSQL存储系统和分布式文件系统成为了技术浪潮,得到了长足的发展.非结构化数据目前呈现更加快速的增长趋势,IDC ...
随机推荐
- nginx(一)之默认配置文件
首先是nginx.conf vim /etc/nginx/nginx.conf user nginx; // 设置nginx服务的系统使用用户 worker_processes 1; // 工作进程数 ...
- Git- 命令及使用
关于Git相关介绍这里就不介绍了,可转<Git- 简介>或者查看官网信息.这篇整理一下git相关的命令. 1) 远程仓库相关命令 克隆下载仓库:$ git clone git://gi ...
- laravel 获取当前月,当前星期,当天起始时间方法
获取当前月起始时间: 1. $time=time(); $start=date('Y-m-01',$time);//获取指定月份的第一天 $end=date('Y-m-t',$time); //获取指 ...
- Mesh无线网络的定义与WiFi的区别
Mesh无线网络的定义与WiFi的区别 无线Mesh网络(无线网状网络)也称为「多跳(multi-hop)」网络,它是一种与传统无线网络完全不同的新型无线网络技术.无线网状网是一种基于多跳路由,对等网 ...
- Nginx详解九:Nginx基础篇之Nginx的访问控制
基于IP的访问控制:http_access_module 不允许指定网段的用户访问:配置语法:deny address | CIDR | unix: | all;默认状态:-配置方法:http.ser ...
- Python中pass的用法、作用
pass主要作用就是占位,让代码整体完整.如果定义一个函数里面为空或一个判断写好了之后还没想好满足条件需要执行执行什么逻辑,又想留着后面使用,但是函数和判断里面为空,那么就会报错,当你还没想清楚函数内 ...
- jQuery 常用的方法
<!DOCTYPE html><html lang="en"><head> <meta charset="utf-8" ...
- Android 第一波
1. Devik进程,Linux进程,线程的区别 说一说对 SP 频繁操作有什么后果? SP 能存储多少数据? SP 的底层其实是由xml文件来实现的,操作 SP 的过程其实就是xml的序列化和反序列 ...
- 三.hadoop mapreduce之WordCount例子
目录: 目录见文章1 这个案列完成对单词的计数,重写map,与reduce方法,完成对mapreduce的理解. Mapreduce初析 Mapreduce是一个计算框架,既然是做计算的框架,那么表现 ...
- kickstart-E
A题 简答模拟题 #include <iostream> #include<stdio.h> #include <set> #include <algorit ...