Python并发复习2 - 多线程模块threading
一、多线程的调用
threading 模块建立在thread 模块之上。thread模块以低级、原始的方式来处理和控制线程,而threading 模块通过对thread进行二次封装,
提供了更方便的api来处理线程。
多线程的调用有两种方式,函数式和继承式。
import threading
import time def sayhi(num): #定义每个线程要运行的函数 print("running on number:%s" %num) time.sleep() if __name__ == '__main__': t1 = threading.Thread(target=sayhi,args=(,)) #生成一个线程实例
t2 = threading.Thread(target=sayhi,args=(,)) #生成另一个线程实例 t1.start() #启动线程
t2.start() #启动另一个线程
import threading
import time class MyThread(threading.Thread):
def __init__(self,num):
super().__init__
self.num = num def run(self):#定义每个线程要运行的函数 print("running on number:%s" %self.num) time.sleep() if __name__ == '__main__': t1 = MyThread()
t2 = MyThread()
t1.start()
t2.start()
二、 阻塞线程和守护线程
join():
在子线程完成运行之前,这个子线程的父线程将一直被阻塞。
setDaemon(True):
将线程声明为守护线程,必须在start() 方法调用之前设置, 如果不设置为守护线程程序会被无限挂起。这个方法基本和join是相反的。
当我们 在程序运行中,执行一个主线程,如果主线程又创建一个子线程,主线程和子线程 就分兵两路,分别运行,那么当主线程完成
想退出时,会检验子线程是否完成。如 果子线程未完成,则主线程会等待子线程完成后再退出。但是有时候我们需要的是 只要主线程
完成了,不管子线程是否完成,都要和主线程一起退出,
#!/usr/bin/env python
# encoding: utf- """
@version: python37
@author: Geoffrey
@file: 多线程复习.py
@time: -- 上午9:
""" import threading
from time import ctime,sleep def func(name, i):
print (f"开始第{i}个线程 --- {name} {ctime()}")
sleep()
print(f"停止 第{i}个线程 {ctime}") threads = [] t0 = threading.Thread(target=func,args=('Julia',))
t1 = threading.Thread(target=func,args=('Python',))
t2 = threading.Thread(target=func,args=('C++',))
t3 = threading.Thread(target=func,args=('Java',)) threads.append(t0)
threads.append(t1)
threads.append(t2)
threads.append(t3) if __name__ == '__main__': for i,t in enumerate(threads):
t.setDaemon(bool(i))# 将线程声明为守护线程,必须在start() 方法调用之前设置,如果不设置为守护线程程序会被无限挂起。
t.start()
# t.join() # 设置为阻塞线程 print (" --------- 主线程执行完成 %s" %ctime())
不设置守护线程,默认是非守护线程。

如果t1,t2,t3设置设置为守护线程,执行结果为在主线程执行完毕后,他们是否执行完成不能保证,随着主进程结束而结束。
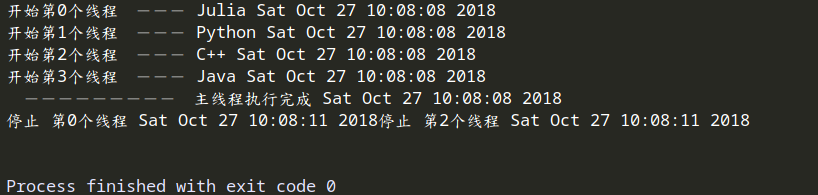
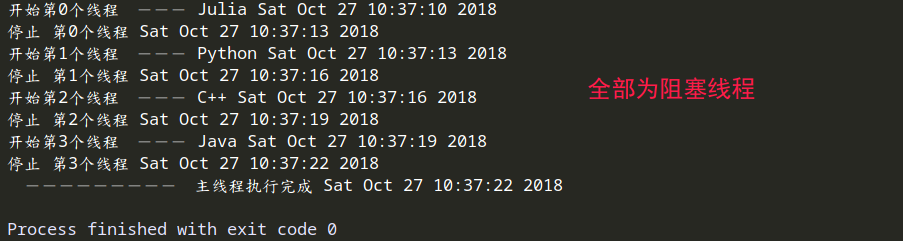
如果设置全部为阻塞线程,结果为轮流执行,相当于单线程。
三、互斥锁,GIL
1、Cpython的GIL解释器锁的工作机制
在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势。需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。Python同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。CPython是Python的一种,GIL不是Python语言的缺陷。所以明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL。
1.2 GIL的介绍
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。可以肯定的一点是:保护不同的数据的安全,就应该加不同的锁。要想了解GIL,首先确定一点:每次执行python程序,都会产生一个独立的进程。例如python test1.py,python test2.py,python test3.py会产生3个不同的python进程。
1.3 GIL原理
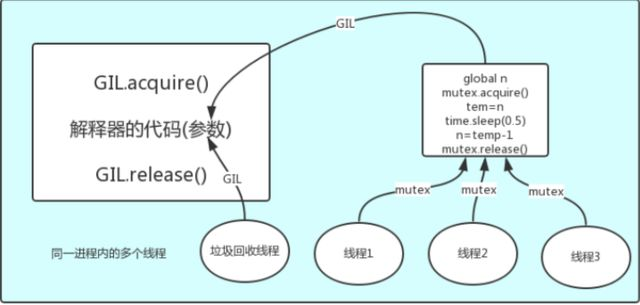
第一点:
所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的(test.py的所有代码以及Cpython解释器的所有代码)例如:test.py定义一个函数work(代码内容如下图),在进程内所有线程都能访问到work的代码,于是我们可以开启三个线程然后target都指向该代码,能访问到意味着就是可以执行。
第二点:
所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程要想运行自己的任务,首先需要解决的是能够访问到解释器的代码。
总结:
解释器的代码是所有线程共享的,所以垃圾回收线程也可能访问到解释器的代码而去执行,这就导致了一个问题:对于同一个数据100,可能线程1执行x=100的同时,而垃圾回收执行的是回收100的操作,解决这种问题没有什么高明的方法,就是加锁处理,即GIL,保证python解释器同一时间只能执行一个任务的代码。
1.4 GIL和Lock
锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据。保护不同的数据就应该加不同的锁。所以,解释就是GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock。如下图:
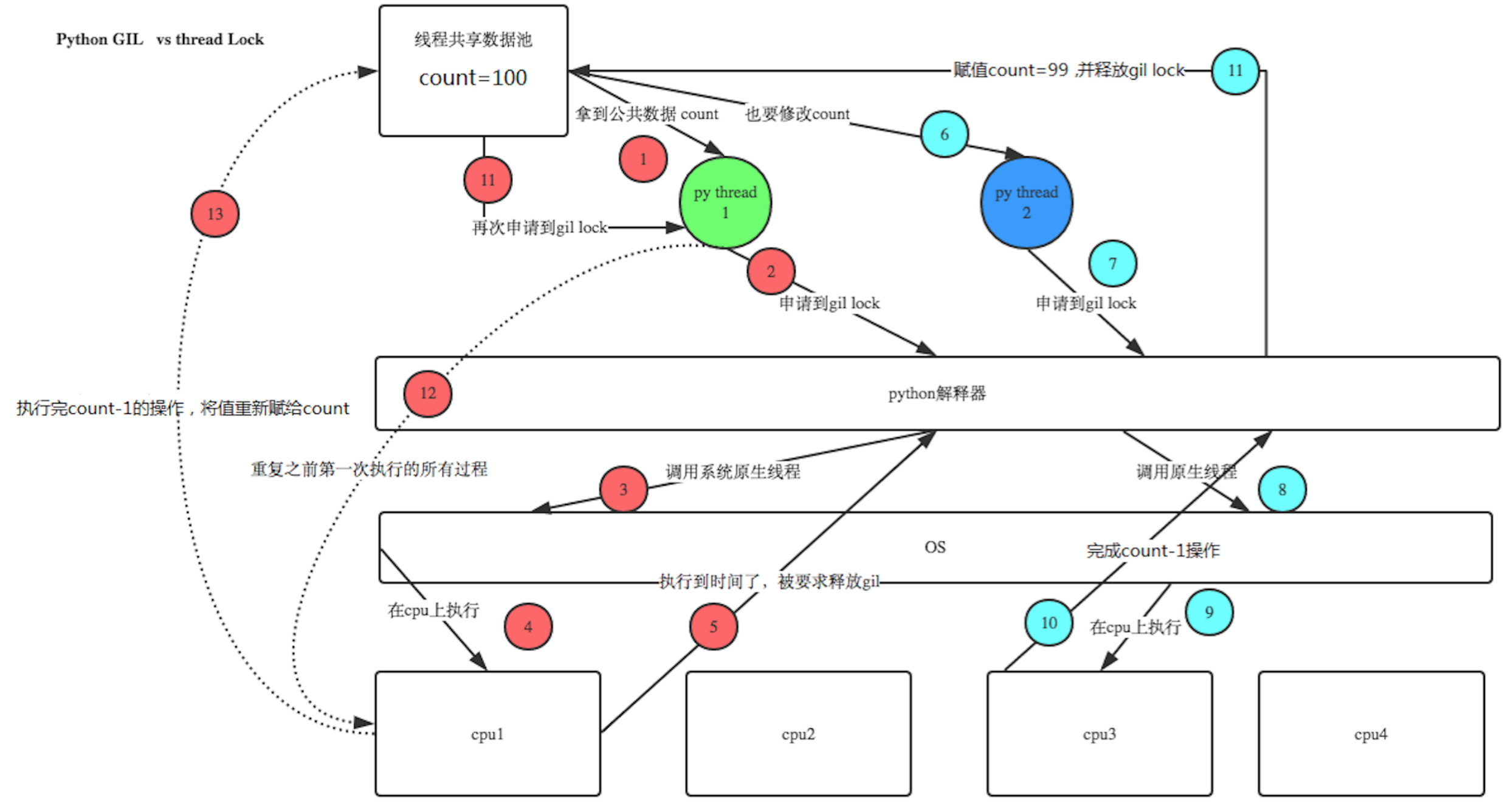
1、100个线程去抢GIL锁,即抢执行权限
2、肯定有一个线程先抢到GIL(暂且称为线程1),然后开始执行,一旦执行就会拿到lock.acquire()
3、极有可能线程1还未运行完毕,就有另外一个线程2抢到GIL,然后开始运行,但线程2发现互斥锁lock还未被线程1释放,于是阻塞,被迫交出执行权限,即释放GIL
4、直到线程1重新抢到GIL,开始从上次暂停的位置继续执行,直到正常释放互斥锁lock,然后其他的线程再重复2 3 4的过程
四 、线程死锁和递归锁
如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁,因为系统判断这部分资源都正在使用,所有这两个线程在无外力作用下将一直等待下去。
import threading,time class myThread(threading.Thread):
def doA(self):
lockA.acquire()
print(self.name,"获得锁A",time.ctime())
time.sleep()
lockB.acquire()
print(self.name,"获得锁B",time.ctime())
lockB.release()
print(self.name,'释放锁B')
lockA.release()
print(self.name,'释放锁A') def doB(self):
lockB.acquire()
print(self.name,"获得锁B",time.ctime())
time.sleep()
lockA.acquire()
print(self.name,"获得锁A",time.ctime())
lockA.release()
print(self.name,'释放锁A')
lockB.release()
print(self.name,'释放锁B') def run(self):
self.doA()
self.doB()
if __name__=="__main__": lockA=threading.Lock()
lockB=threading.Lock()
threads=[] for i in range():
threads.append(myThread())
for t in threads:
t.start()
for t in threads:
t.join()
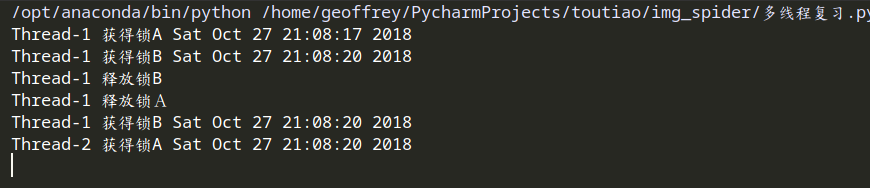
解决办法:使用递归锁RLOCK。RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次acquire。直到一个线程所有的acquire都被release,其他的线程才能获得资源。
五、生产者消费者模型
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
这就像,在餐厅,厨师做好菜,不需要直接和客户交流,而是交给前台,而客户去饭菜也不需要不找厨师,直接去前台领取即可,这也是一个解耦的过程。
使用队列:
#!/usr/bin/env python
# encoding: utf- """
@version: python37
@author: Geoffrey
@file: 生产者消费者模型.py
@time: -- 下午7:
""" import time,random
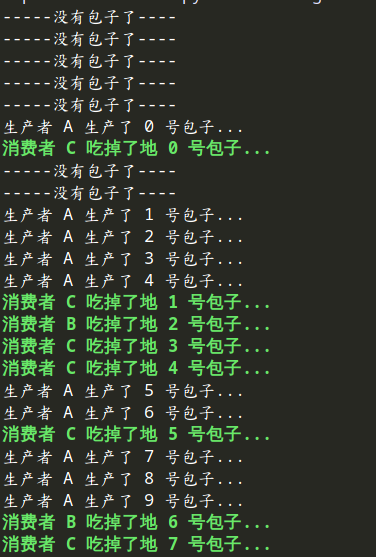
import queue,threading def Producer(name):
count =
while count <:
# print("生产中........")
time.sleep(random.randrange())
q.put(count)
print(f'生产者 {name} 生产了 {count} 号包子...')
count += def Consumer(name):
count =
while count <:
time.sleep(random.randrange())
if not q.empty():
data = q.get()
print(f'\033[32;1m消费者 {name} 吃掉了地 {data} 号包子...\033[0m' )
else:
print("-----没有包子了----")
count += if __name__ == '__main__':
q = queue.Queue() p1 = threading.Thread(target=Producer, args=('A',))
c1 = threading.Thread(target=Consumer, args=('B',))
c2 = threading.Thread(target=Consumer, args=('C',))
c3 = threading.Thread(target=Consumer, args=('D',))
p1.start()
c1.start()
c2.start()
c3.start()
不使用队列:
#!/usr/bin/env python
# encoding: utf- """
@version: python37
@author: Geoffrey
@file: 生产者消费者_condition.py
@time: -- 下午8:
""" import threading
import time # 商品
product = None
# 条件变量
con = threading.Condition() # 生产者方法
def produce():
global product
product = if con.acquire():
while True:
if product < :
product +=
print (f'生产出商品{product}') else:
# 通知消费者,商品已经生产
con.notify()
# 等待通知
con.wait()
time.sleep(0.5) # 消费者方法
def consume():
global product
product = if con.acquire():
while True:
if product > :
print (f'消费了第{product}商品')
product -=
else:
# 通知生产者,商品已经没了
con.notify() # 等待通知
con.wait()
time.sleep(0.5) t1 = threading.Thread(target=produce)
t2 = threading.Thread(target=consume) t1.start()
t2.start()

Python并发复习2 - 多线程模块threading的更多相关文章
- Python并发复习1 - 多线程
一.基本概念 程序: 指令集,静态, 进程: 当程序运行时,会创建进程,是操作系统资源分配的基本单位 线程: 进程的基本执行单元,每个进程至少包含一个线程,是任务调度和执行的基本单位 > 进程和 ...
- Python并发复习4- concurrent.futures模块(线程池和进程池)
Python标准库为我们提供了threading(多线程模块)和multiprocessing(多进程模块).从Python3.2开始,标准库为我们提供了concurrent.futures模块,它提 ...
- Python并发复习3 - 多进程模块 multiprocessing
python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进程.Python提供了非常好用的多进程包multiprocessing,只需要定 ...
- Python并发编程04 /多线程、生产消费者模型、线程进程对比、线程的方法、线程join、守护线程、线程互斥锁
Python并发编程04 /多线程.生产消费者模型.线程进程对比.线程的方法.线程join.守护线程.线程互斥锁 目录 Python并发编程04 /多线程.生产消费者模型.线程进程对比.线程的方法.线 ...
- python并发编程之多线程1
一多线程的概念介绍 threading模块介绍 threading模块和multiprocessing模块在使用层面,有很大的相似性. 二.开启多线程的两种方式 1.创建线程的开销比创建进程的开销小, ...
- 30 python 并发编程之多线程
一 threading模块介绍 multiprocess模块的完全模仿了threading模块的接口,二者在使用层面,有很大的相似性,因而不再详细介绍 官网链接:https://docs.python ...
- 基于Python的多线程模块Threading小结
步入正题前,先准备下基本知识,线程与进程的概念. 相信作为一个测试人员,如果从理论概念上来说其两者的概念或者区别,估计只会一脸蒙蔽,这里就举个例子来说明下其中的相关概念. 平安夜刚过,你是吃到了苹果还 ...
- python并发编程之多线程基础知识点
1.线程理论知识 概念:指的是一条流水线的工作过程的总称,是一个抽象的概念,是CPU基本执行单位. 进程和线程之间的区别: 1. 进程仅仅是一个资源单位,其中包含程序运行所需的资源,而线程就相当于车间 ...
- Python并发编程之多线程使用
目录 一 开启线程的两种方式 二 在一个进程下开启多个线程与在一个进程下开启多个子进程的区别 三 练习 四 线程相关的其他方法 五 守护线程 六 Python GIL(Global Interpret ...
随机推荐
- Confluence 6 用户目录图例 - 可读写连接 LDAP
上面的图:Confluence 连接到一个 LDAP 目录. https://www.cwiki.us/display/CONFLUENCEWIKI/Diagrams+of+Possible+Conf ...
- deepin、Ubuntu安装Nginx
deepin安装nginx 切换至root用户 su 密码: 基础库的安装 安装gcc g++的依赖库 sudo apt-get install build-essential && ...
- Java的动手动脑(七)
日期:2018.11.18 博客期:025 星期日 Part 1:使用 Files.walkFileTree()来找出指定文件夹下大小大于1KB的文件 package temp; import jav ...
- python面试30-40题
1.简述python引用计数机制 python垃圾回收主要以引用计数为主,标记-清除和分代清除为辅的机制,其中标记-清除和分代回收主要是为了处理循环引用的难题. 引用计数算法 当有1个变量保存了对 ...
- java Swing组件和事件处理(二)
1.BoxLayout类可以创建一个布局对象,成为盒式布局,BoxLayout在javax.Swing border 包中,java.swing 包提供一个Box类,该类也是一个类,创建的容器称作一 ...
- Python中的xxx == xx是否等价于xxx is xxx
先上代码: >>> a = 1 >>> b = 1 >>> a is b True >>> a == b True what? ...
- Python列表、元组、字典和集合的区别
数据结构 是否可变 是否重复 是否有序 定义符号 列表(list) 可变 可重复 有序 [] 元组(tuple) 不可变 可重复 有序 () 字典(dictionary) 可变 可重复 无序 {key ...
- ecilpse运行Servlet程序是找不到路径的原因
当工作空间路径有空格时,空格会被转成%20,将导致路径无法识别,于是就找不到路径了.
- 最短路径问题---Dijkstra算法详解
侵删https://blog.csdn.net/qq_35644234/article/details/60870719 前言 Nobody can go back and start a new b ...
- Java链表和递归
删除链表的指定元素: public class ListNode { public int val; public ListNode next; public ListNode(int x){ val ...