Linux上的文件查找工具之locate与find
前言
Linux上提供了两款工具用于查找文件,一款是locate,另一款是find。
locate的特点是根据已生成的数据库查找,速度较快,但是查找的是快照数据,不准确。
因此在日常使用中,为了准确性,使用find的情况比较常见。并且find可自定义查找条件,十分灵活。
locate
Linux上有一个RPM包,名为mlocate,它是locate/updatedb的一种实现。
mlocate前面的m代表的意思是merging,它表示updatedb会重复使用已存在的数据库,从而避免读取整个文件系统,这样就加快了updatedb的速度。
mlocate包中主要有2个命令,一个是locate,另一个是updatedb。
updatedb用于检索Linux的文件系统并生成/更新数据库文件,该数据库记录了系统上每个文件的位置。
它会结合crontab每日更新,相关的文件是:/etc/cron.daily/mlocate。
locate根据用户所输入的关键词(pattern)读取updatedb所维护的数据库,并将结果输出在STDOUT上。
locate [OPTION]... PATTERN...
如果没有使用--regex正则选项的话,那么PATTERN可以包含globbing字符。
如果PATTERN没有包含globbing字符的话,那么locate默认会在PATTERN前后加上“*”,即“*PATTERN*”。
看一个简单的示例。该命令的输出很多,我做了剔除操作。
[root@C7 ~]# locate passwd
/etc/passwd
/etc/passwd-
/etc/security/opasswd
/usr/share/doc/passwd-0.79/AUTHORS
/usr/share/doc/passwd-0.79/COPYING
可以看到,locate的查找机制,并不是精确查找passwd这个文件名,而是通过前文所说的“*PATTERN*”机制实现了模糊查找。
并且locate所查找的是整个路径,而不仅仅是文件名。
如果希望locate只根据基名(basename)来查找的话,则使用-b选项。
[root@C7 ~]# locate passwd | wc -l [root@C7 ~]# locate -b passwd | wc -l
pattern可以有多个。多个pattern之间是或关系,只要满足某一个,就将其显示出来。
# locate PATTERN1 PATTERN2 PATTERN3
[root@C7 ~]# locate passwd | wc -l [root@C7 ~]# locate passwd vim | wc -l [root@C7 ~]# locate passwd vim shadow | wc -l
如果希望查找的文件路径满足所有的pattern,则使用-A选项。
[root@C7 ~]# locate -A passwd vim shadow | wc -l
-c选项可用于统计相关pattern的条目数。
[root@C7 ~]# locate passwd | wc -l [root@C7 ~]# locate -c passwd
关于locate,了解到这里即可。
find
推荐阅读骏马金龙的两篇博文,难度比较大,适合深入了解。
本文则比较适合日常使用以及新手入门。
find是一款文件实时查找工具。它的语法如下。
find [-H] [-L] [-P] [-D debugopts] [-Olevel] [path...] [expression]
语法比较复杂,我们来简化一下。
-H、-L和-P:用于决定find是如何对待字符链接文件。默认find采取-P选项,不追踪字符链接文件。
-D debugoptions:这个是find的调试模式,当我们执行find后的命令输出,与我们所期望的不同时,使用该选项。
-Olevel:启用查询优化(query optimization)。
上述三种选项,新手都可以忽略,保持其默认即可。简化后的结果为。
find [-H] [-L] [-P] [-D debugopts] [-Olevel] [path...] [expression]
path:表示find查找文件的搜索目录。find只会在给出的目录下查找。可以有多个。
expression:表达式,这个是重点,下文详述。
表达式(expression)
[options...] [tests...] [actions...]
find查找文件的机制,主要是根据表达式的评估值来决定的。表达式会自左而右进行评估求值。只有当最终评估值为true的时候,才会输出文件完整路径(默认action)。
表达式由三部分构成:选项(option)、测试(test)和动作(action)。
选项(option)
所有的选项,总是会返回true。
选项所影响范围是全局的,而不仅仅是找到的某些特定文件。
-daystart:只影响这些测试(-amin、-atime、-cmin、-ctime、-mmin和-mtime),在测量时间的时候,从今天的起始开始计算,而不是24小时之前。
-maxdepth levels:最大深度。0表示只查找目录自身,1表示最多至一级子目录,以此类推。
[root@C7 ~]# find /etc/ -maxdepth
/etc/
[root@C7 ~]# find /etc/ -maxdepth
/etc/
/etc/fstab
...
/etc/cupshelpers
/etc/pinforc
-mindepth levels:最小深度。1表示从1级子文件开始处理(即不处理目录自身),以此类推。
测试(test)
测试,其实就是查找的条件,可以根据文件名、路径名、大小、类型、所有权和权限等条件来查找。
创建示例文件层级结构。
[root@C7 ~]# tree -F /tmp/test_find/
/tmp/test_find/
├── .log
├── .log
├── .log
├── .log
├── .log
├── a.txt
├── b.txt
├── c.txt
├── dir1/
│ └── test.sh
├── dir2/
│ └── test.xlsx
├── dir3/
│ └── work.doc
├── empty_dir/
└── zwl.log directories, files
根据名称查找
-name "PATTERN":根据文件名来查找文件,pattern支持globbing字符。
[root@C7 ~]# find /tmp/test_find/ -name "*.log"
/tmp/test_find/.log
/tmp/test_find/.log
/tmp/test_find/.log
/tmp/test_find/.log
/tmp/test_find/.log
/tmp/test_find/zwl.log
注意,find的查找,是根据文件名的精确查找,而不是locate的模糊查找。例如:
[root@C7 ~]# find /tmp/test_find/ -name "zwl"
这个实例,是无法找出“zwl.log”文件的。
-iname "PATTERN":类似-name,区别在于该选项是忽略字母大小写。
[root@C7 ~]# touch /tmp/test_find/{alongdidi,ALongDiDi,ALONGDIDI}.log
[root@C7 ~]# find /tmp/test_find/ -name "alongdidi.log"
/tmp/test_find/alongdidi.log
[root@C7 ~]# find /tmp/test_find/ -iname "alongdidi.log"
/tmp/test_find/alongdidi.log
/tmp/test_find/ALongDiDi.log
/tmp/test_find/ALONGDIDI.log
-name和-iname都是基于文件的名称(基名,basename)来查找,而不是像locate那样可以基于整个路径名。想实现的话,可以通过-path。
-path "PATTERN"
[root@C7 ~]# find /tmp/test_find/ -path "*test*/dir*/test*"
/tmp/test_find/dir1/test.sh
/tmp/test_find/dir2/test.xlsx
匹配整个路径的时候,还可以基于正则表达式。
-regex "PATTERN":基于正则匹配完整路径。
-iregex "PATTERN":等同于-regex,但是忽略字母大小写。
-regextype type:默认支持Emacs正则,想调整正则类型的话,通过该选项。
一般我们基于名称匹配的时候,常用的是基于文件的名称,而不会基于整个路径名称!
根据文件所有权查找
-user NAME:根据文件的所有者查找,可以是username,也可以是UID。
-group NAME:根据文件的所有组查找,可以是groupname,也可以是GID。
“/tmp/test_find/”目录下的所有文件的所有者和所有组都是root,我们有意修改几个。
[root@C7 ~]# chown zwl:zwl /tmp/test_find/{alongdidi,ALongDiDi,ALONGDIDI}.log
[root@C7 ~]# find /tmp/test_find/ -user zwl -group zwl -ls
-rw-r--r-- zwl zwl Mar : /tmp/test_find/alongdidi.log
-rw-r--r-- zwl zwl Mar : /tmp/test_find/ALongDiDi.log
-rw-r--r-- zwl zwl Mar : /tmp/test_find/ALONGDIDI.log
[root@C7 ~]# find /tmp/test_find/ -user -group -ls
-rw-r--r-- zwl zwl Mar : /tmp/test_find/alongdidi.log
-rw-r--r-- zwl zwl Mar : /tmp/test_find/ALongDiDi.log
-rw-r--r-- zwl zwl Mar : /tmp/test_find/ALONGDIDI.log
命令结尾的“-ls”是动作的一种,输出类似于“ls -l”。
一般都是通过用户/组的名称来查找,如果用户/组被删除了,那么就只能通过UID/GID了。
[root@C7 ~]# chown haimianbb:haimianbb /tmp/test_find/{a,b,c}.txt
[root@C7 ~]# find /tmp/test_find/ -user haimianbb -group haimianbb -ls
-rw-r--r-- haimianbb haimianbb Mar : /tmp/test_find/a.txt
-rw-r--r-- haimianbb haimianbb Mar : /tmp/test_find/b.txt
-rw-r--r-- haimianbb haimianbb Mar : /tmp/test_find/c.txt
[root@C7 ~]# userdel -r haimianbb
[root@C7 ~]# find /tmp/test_find/ -user haimianbb -group haimianbb -ls
find: ‘haimianbb’ is not the name of a known user
[root@C7 ~]# find /tmp/test_find/ -user -group -ls
-rw-r--r-- Mar : /tmp/test_find/a.txt
-rw-r--r-- Mar : /tmp/test_find/b.txt
-rw-r--r-- Mar : /tmp/test_find/c.txt
或者通过-nouser和-nogroup也可以查找得到。
-nouser:查找没有所有者的文件。
-nogroup:查找没有所有组的文件。
[root@C7 ~]# find /tmp/test_find/ -nouser -nogroup -ls
-rw-r--r-- Mar : /tmp/test_find/a.txt
-rw-r--r-- Mar : /tmp/test_find/b.txt
-rw-r--r-- Mar : /tmp/test_find/c.txt
根据文件的类型查找
-type TYPE:
f:普通文件;
d:目录文件;
l:字符链接文件;
b:块设备文件;
c:字符设备文件;
p:管道文件;
s:套接字文件。
[root@C7 ~]# find /tmp/test_find/ -type f -name "*.txt"
/tmp/test_find/a.txt
/tmp/test_find/b.txt
/tmp/test_find/c.txt
[root@C7 ~]# find /tmp/test_find/ -type d
/tmp/test_find/
/tmp/test_find/dir1
/tmp/test_find/dir2
/tmp/test_find/dir3
/tmp/test_find/empty_dir
根据文件的大小查找
-size [+|-]#UNIT:“#”表示具体的数值大小,是一个正整数。
可以带上正负符号,也可以不带,其含义各不相同。正号表示大于,负号表示小于。
UNIT表示size的单位。单位:k=1024B(注意,这里是小写字母的k),M=1024KB,G=1024GB。
首先我们先使用dd命令创造一些指定大小的测试文件。
# dd if=/tmp/messages of=/tmp/test_find/size1.txt bs=1K count=
# dd if=/tmp/messages of=/tmp/test_find/size2.txt bs=1K count=
# dd if=/tmp/messages of=/tmp/test_find/size3.txt bs=1K count=
[root@C7 ~]# ls -lh /tmp/test_find/size*.txt
-rw-r--r-- root root 10K Mar : /tmp/test_find/size1.txt
-rw-r--r-- root root 20K Mar : /tmp/test_find/size2.txt
-rw-r--r-- root root 30K Mar : /tmp/test_find/size3.txt
简单测试。
[root@C7 ~]# find /tmp/test_find/ -size 20k -name "size*.txt" -ls
-rw-r--r-- root root Mar : /tmp/test_find/size2.txt
[root@C7 ~]# find /tmp/test_find/ -size +20k -name "size*.txt" -ls
-rw-r--r-- root root Mar : /tmp/test_find/size3.txt
[root@C7 ~]# find /tmp/test_find/ -size -20k -name "size*.txt" -ls
-rw-r--r-- root root Mar : /tmp/test_find/size1.txt
但是,如果一个文件的大小是19.xKB或者20.xKB呢?
复制size2.txt,创建出2个文件,并且在size4.txt上删除5行,在size5.txt上复制粘贴5行。
使得19KB<size4.txt<20KB;20KB<size5.txt<21KB。
-rw-r--r-- root root Mar : /tmp/test_find/size4.txt
-rw-r--r-- root root Mar : /tmp/test_find/size5.txt
再次查找。
[root@C7 ~]# find /tmp/test_find/ -size 20k -name "size*.txt" -ls
-rw-r--r-- root root Mar : /tmp/test_find/size2.txt
-rw-r--r-- root root Mar : /tmp/test_find/size4.txt
[root@C7 ~]# find /tmp/test_find/ -size -20k -name "size*.txt" -ls
-rw-r--r-- root root Mar : /tmp/test_find/size1.txt
[root@C7 ~]# find /tmp/test_find/ -size +20k -name "size*.txt" -ls
-rw-r--r-- root root Mar : /tmp/test_find/size3.txt
-rw-r--r-- root root Mar : /tmp/test_find/size5.txt
结论:
-size -n ≤ (n-)
(n-) < -size n ≤ n
-size +n > n
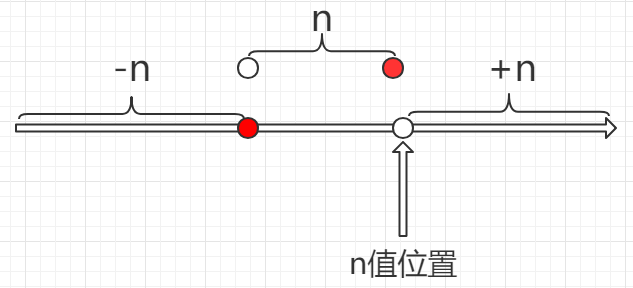
根据时间戳查找
-atime n:文件在n天前访问过。在计算的时候,n天应该换算成(n*24)小时。计算的结果,是可以出现小数的,但是小数会被丢弃,从而取整。
因此无论是1.1天还是1.9天,都是会被认为是1天。假设现在的时间是“3月15日16:00:00”,那么从“3月13日16:01:00”到“3月14日16:00:00”,都理解为1天。
n也支持正负号。
-1天:从“3月14日16:01:00”到“3月15日16:00:00”。
+1天:“3月13日16:00:00”之前。
-atime [+|-]n
-mtime [+|-]n
-ctime [+|-]n
time的单位是24小时,此外还有min,单位是分钟,机制是类似的。
-amin [+|-]n
-mmin [+|-]n
-cmin [+|-]n
find根据时间查找,应该至少是基于分钟的,至于是否基于秒,我不确定,也不太知道如何去测试。除非对时间的精度有较高的要求,否则就不深究了。
根据文件权限查找
-perm [/|-] mode
-perm mode:精确权限匹配,即文件的所有者、所有组和其他人的权限都必须刚好符合mode。权限不能比mode多,也不能比mode少。
[root@C7 ~]# find /tmp/test_find/ -name "*.log" -ls
-rwxrwxrwx root root Mar : /tmp/test_find/.log
-rwxr-xr-x root root Mar : /tmp/test_find/.log
-rw-rw-rw- root root Mar : /tmp/test_find/.log
-rw-r--r-- root root Mar : /tmp/test_find/.log
-rw-r--r-- root root Mar : /tmp/test_find/.log
-rw-r--r-- root root Mar : /tmp/test_find/zwl.log
-rw-r--r-- zwl zwl Mar : /tmp/test_find/alongdidi.log
-rw-r--r-- zwl zwl Mar : /tmp/test_find/ALongDiDi.log
-rw-r--r-- zwl zwl Mar : /tmp/test_find/ALONGDIDI.log
[root@C7 ~]# find /tmp/test_find/ -name "*.log" -perm -ls
-rwxrwxrwx root root Mar : /tmp/test_find/.log
[root@C7 ~]# find /tmp/test_find/ -name "*.log" -perm -ls
-rwxr-xr-x root root Mar : /tmp/test_find/.log
[root@C7 ~]# find /tmp/test_find/ -name "*.log" -perm -ls
-rw-rw-rw- root root Mar : /tmp/test_find/.log
-perm g=w:表示文件的权限必须得是0020,除了组有写权限,其他的权限位都为0。
-perm -mode:给出的权限位之间的关系是逻辑与关系。例如:
[root@C7 ~]# find /tmp/test_find/ -name "*.log" -perm - -ls
-rwxrwxrwx root root Mar : /tmp/test_find/.log
-rw-rw-rw- root root Mar : /tmp/test_find/.log
查找至少所有者具有读写权限并且(逻辑与)所有组具有写权限并且其他人具有写权限的log文件。不考虑其他额外的权限。意思是如果在此基础之上,还有执行权限,那么也会被找到。
-perm /mode:给出的权限位之间的关系是逻辑或关系。例如:
find . -perm /
查找那些可以被写入的文件(无论是被所有者还是所有组还是其他人)。
find . -perm /
查找可以被执行的文件。
find . -perm /
find . -perm /u+w,g+w
find . -perm /u=w,g=w
查找可以被用户或者组写入的文件。
操作符(operator)
操作符可用于组合表达式,用来决定表达式的处理优先级。这里按照优先级从高到低说明一下。
\( expr \):优先级最高。
! expr:取反。
expr1 expr2:省略-a或者-and,逻辑与。
expr1 -o expr2:等同-or,逻辑或。
expr1, expr2:列表;2个表达式都会被评估,expr1的评估值被忽略,列表的评估值取决于expr2。
表达式我们在书写的时候,一般只会有一个option和action,或者没有。操作符一般用于组合测试。
# find /tmp/test_find/ -name "*.log" -perm - -ls
# find /tmp/test_find/ -name "*.txt" -o -perm /
德摩尔定律
非(p且q)=(非p)或(非q)
非(p或q)=(非p)且(非q)
动作(action)
动作决定了对于查找到的文件要执行的操作。省略的话,默认是-print。
[root@C7 ~]# find /tmp/test_find/ -name "alongdidi.log"
/tmp/test_find/alongdidi.log
-ls:打印类似“ls -l”的详细信息。
-fls /PATH/TO/FILE:类似于-ls,区别在于多一步重定向输出至文件。等同于“-ls > /PATH/TO/FILE”
-delete:将找到的文件删除,不会有任何提示。无法用于删除非空目录。
find: cannot delete ‘/tmp/test_find/dir1’: Directory not empty
-ok COMMAND {} \;:对查找到的每个文件执行COMMAND指定的命令,每次执行COMMAND需要用户确认。
{},即表示所查找到的文件。
[root@C7 ~]# find /tmp/test_find/ -type f -name "1.log" -ok stat {} \;
< stat ... /tmp/test_find/.log > ? y
File: ‘/tmp/test_find/.log’
Size: Blocks: IO Block: regular empty file
Device: fd00h/64768d Inode: Links:
Access: (/-rwxrwxrwx) Uid: ( / root) Gid: ( / root)
Access: -- ::56.737451749 +
Modify: -- ::56.737451749 +
Change: -- ::53.413515181 +
Birth: -
-exec COMMAND {} \;:对查找到的每个文件执行COMMAND指定的命令,每次执行COMMAND不不不需要用户确认!!!
在使用-ok或者-exec的时候,find先查找符合条件的文件,再将这些文件一次性全部交给后面的COMMAND处理,如果文件量比较大,则会报错。
error: too many arguments
此时可以使用exargs命令解决。
find ... | xargs COMMAND
练习
1、查找/var目录下属主为root,且属组为mail的所有文件或目录。
~]# find /var -user root -group mail -ls
2、查找/usr目录下不属于root、bin或者hadoop的所有文件或目录,请使用两种方法。
~]# find /usr ! -user root ! -user bin ! -user hadoop -ls
~]# find /usr ! \( -user root -o -user bin -o -user hadoop \) -ls
3、查找/etc目录下最近一周内其内容修改过,且属主不是root用户也不是hadoop用户的文件或目录。
~]# find /etc -mtime - ! -user root ! -user hadoop -ls
~]# find /etc -mtime - !\( -user root -o -user hadoop \) -ls
4、查找当前系统上没有属主或属组,且最近一周内曾被访问过的文件或目录。
~]# find / \( -nouser -o -nogroup \) -atime - -ls
5、查找/etc目录下大于1M且类型为普通文件的所有文件。
~]# find /etc -size +1M -type f -exec ls -lh {} \;
6、查找/etc目录下所有用户都没有写权限的文件。
~]# find /etc ! -perm / -type f -ls
7、查找/etc目录下至少有一类用户没有执行权限的文件。
~]# find /etc ! -perm - -type f -ls
8、查找/etc/init.d目录下,所有用户都有执行权限,且其他用户有写权限的所有文件。
~]# find /etc/init.d -perm - -perm - -type f -ls
~]# find /etc/init.d -perm - -type f -ls
Linux上的文件查找工具之locate与find的更多相关文章
- Linux操作系统的文件查找工具locate和find命令常用参数介绍
Linux操作系统的文件查找工具locate和find命令常用参数介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.非实时查找(数据库查找)locate工具 locate命 ...
- Linux文件查找工具之find “大宝剑”--转载
原文地址:http://xinzong.blog.51cto.com/10018904/1749465 一.文件查找工具常用软件 locate: locate命令其实是find -name的另一种写法 ...
- Linux 上的数据可视化工具
Linux 上的数据可视化工具 5 种开放源码图形化工具简介 Linux® 上用来实现数据的图形可视化的应用程序有很多,从简单的 2-D 绘图到 3-D 制图,再到科学图形编程和图形模拟.幸运的是,这 ...
- 在Linux上安装Elasticsearch Head工具.md
在Linux上安装Elasticsearch Head工具 1.修改elasticsearch的参数 编辑elasticsearch的配置文件elasticsearch.yml $ vim /data ...
- Duplicate Manager Pro for Mac(重复文件查找工具)破解版安装
1.软件简介 Duplicate Manager Pro 是 macOS 系统上一款重复文件查找工具,可以帮你在 Mac 电脑上查找出磁盘上面的重复文件,然后让你对这些重复文件进行判断并删除,使 ...
- xsos:一个在Linux上阅读SOSReport的工具
xsos:一个在Linux上阅读SOSReport的工具 时间 2019-05-23 14:36:29 51CTO 原文 http://os.51cto.com/art/201905/596889 ...
- 文件处理工具 gif合成工具 文件后缀批量添加工具 文件夹搜索工具 重复文件查找工具 网页图片解析下载工具等
以下都是一些简单的免费分享的工具,技术支持群:592132877,提供定制化服务开发. Gif动图合成工具 主要功能是扫描指定的文件夹里的所有zip文件,然后提取Zip文件中的图片,并合成一张gif图 ...
- Linux上读取文件
Linux上读取文件的方法: #!/bin/bash # This is a script for test exec CONFIG_FILE=$ #该脚本传一个文件名为参数 FILE_NO= ech ...
- linux上hosts文件如何配置
linux上hosts文件如何配置 一.什么是host Hosts是一个没有扩展名的系统文件,其基本作用就是将一些常用的网址域名与其对应的IP地址建立一个关联“数据库”,当用户在浏览器中输入一个需要登 ...
随机推荐
- Confluence 6 配置服务器基础地址
服务器基础地址(Server Base URL)是用户访问 Confluence 的 URL 地址.这个基础的 URL 地址必须与你在浏览器中访问 Confluence 中的地址. Confluenc ...
- 进入页面,根据后台传过来的flag 判断列表隐藏与否
需求描述:页面中有两个列表,一个已添加,一个可以添加,进入页面的时候,如果已添加中有数据则显示,没有数据就隐藏,emmmm,这种需求,我该怎么吐槽嗷嗷嗷 解决思路:让已添加的列表的div默认隐藏,前台 ...
- 【sqli-labs】Less11~Less16
学习sqli-labs的笔记,前面的笔记内容比较详细.后面的只记录关键点了. Less11: POST注入, 有回显,有错误提示 从11题起是POST注入,发现有两个输入框.用firefox的F12查 ...
- 【python】控制台输出颜色
来源:http://www.cnblogs.com/yinjia/p/5559702.html 在开发项目过程中,为了方便调试代码,经常会向stdout中输出一些日志,默认的这些日志就直接显示在了终端 ...
- Python使用正则表达式分割字符串
re.split(pattern, string, [maxsplit], [flags]) pattern:表示模式字符串,由要匹配的正则表达式转换而来. string:表示要匹配的字符串. max ...
- C++ 关于ShowWindow()的疑问
IDE: Code::Blocks 16.01 操作系统:Windows 7 x64 最初的代码,目的是为了隐藏窗口出现在任务栏上的图标. #include <windows.h> usi ...
- Nginx + tomcat服务器 负载均衡
Nginx 反向代理初印象 Nginx (“engine x”) 是一个高性能的HTTP和反向代理 服务器,也是一个IMAP/POP3/SMTP服务器.其特点是占有内存少,并发能力强,事实上nginx ...
- CentOS安装jdk的三种方法
方法一:手动解压JDK的压缩包,然后设置环境变量 方法二:用yum安装JDK,(全称为 Yellow dog Updater, Modified)是一个在Fedora和RedHat以及CentOS中的 ...
- 步步為營-97-MyMVC3
說明: 解決另外一個不合理之處:通過控制器完成處理 1:在mvc文件夾下面添加一個工廠類文件DefaultControllerFactory 1.2進一步升級為抽象工廠 2 下一步如何規範Contro ...
- 为什么dbms_metadata.get_ddl显示不全?
http://bi.dataguru.cn/thread-335433-1-1.html