(转)php读取文件使用redis的pipeline导入大批量数据
第一次写博客,哈哈,纯属用来记录一下自己工作中遇到的问题及解决办法。
昨天因为工作的需求,需要做一个后台上传TXT文件,读取其中的内容,然后导入redis库中。要求速度快,并且支持至少10W以上的数据,而内容也就一个字段存类似openid和QQ。我一开始做的时候就老套路,遍历、hset,然后就发现非常的慢,一千条数据就花了30-32秒,当时就觉得不行,于是就请教了一个大佬,然后就得知了方法
我生成了20W的数据用来做测试,文件大小6M多。
话不多说,直接贴代码了
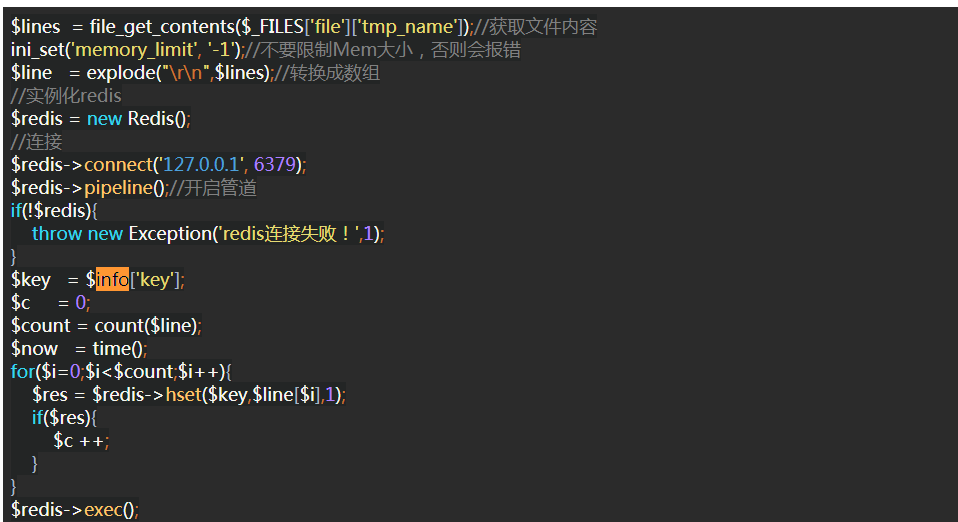
$lines = file_get_contents($_FILES['file']['tmp_name']);//获取文件内容
ini_set('memory_limit', '-1');//不要限制Mem大小,否则会报错
$line = explode("\r\n",$lines);//转换成数组
//实例化redis
$redis = new Redis();
//连接
$redis->connect('127.0.0.1', 6379);
$redis->pipeline();//开启管道
if(!$redis){
throw new Exception('redis连接失败!',1);
}
$key = $info['key'];
$c = 0;
$count = count($line);
$now = time();
for($i=0;$i<$count;$i++){
$res = $redis->hset($key,$line[$i],1);
if($res){
$c ++;
}
}
$redis->exec();
使用结果:

哈哈,即使就直接用time()方法获取的,是计秒的,没有毫秒那种效果,不过也可以看出来确实是非常的快,20W的数据不到两秒就存进去了
其实整个代码都非常简单,能让redis快速导入的就是一个点“pipeline”,开启了这个就可以了。哈哈以前没有用过,所以就小小的记录一下。
---------------------
作者:逝去日子如风
来源:CSDN
原文:https://blog.csdn.net/hzj1064189928/article/details/80499657
版权声明:本文为博主原创文章,转载请附上博文链接!
(转)php读取文件使用redis的pipeline导入大批量数据的更多相关文章
- php读取文件使用redis的pipeline(管道)导入大批量数据
需求:需要做一个后台上传TXT文件,读取其中的内容,然后导入redis库中.要求速度快,并且支持至少10W以上的数据,而内容也就一个字段存类似openid和QQ 传统做法:我一开始做的时候就老套路,遍 ...
- python 读取文件第一列 空格隔开的数据
file=open('6230hand.log','r') result=list() for c in file.readlines(): c_array=c.split(" " ...
- Excel——读取文件后——组装成待插入数据库数据——实体映射模式
package com.it.excel.excelLearn; import java.io.IOException; import java.util.HashMap; import java.u ...
- Redis 管道pipeline
Redis是一个cs模式的tcp server,使用和http类似的请求响应协议. 一个client可以通过一个socket连接发起多个请求命令. 每个请求命令发出后client通常会阻塞并等待red ...
- 【redis】pipeline - 管道模型
redis-pipeline 2020-02-10: 因为我把github相关的wiki删了,所以导致破图...待解决.(讲真github-wiki跟project是2个url,真的不好用) 因为用的 ...
- Redis 单节点百万级别数据 读取 性能测试.
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 这里先进行造数据,向redis中写入五百万条数据,具体方式有如下三种: 方法一:(Lua 脚本) vim ...
- 大数据学习day34---spark14------1 redis的事务(pipeline)测试 ,2. 利用redis的pipeline实现数据统计的exactlyonce ,3 SparkStreaming中数据写入Hbase实现ExactlyOnce, 4.Spark StandAlone的执行模式,5 spark on yarn
1 redis的事务(pipeline)测试 Redis本身对数据进行操作,单条命令是原子性的,但事务不保证原子性,且没有回滚.事务中任何命令执行失败,其余的命令仍会被执行,将Redis的多个操作放到 ...
- Java 创建文件夹和文件,字符串写入文件,读取文件
两个函数如下: TextToFile(..)函数:将字符串写入给定文本文件: createDir(..)函数:创建一个文件夹,有判别是否存在的功能. public void TextToFile(fi ...
- C#读取文件为byte[]
C#读取文件为byte[] 转载请注明出处 http://www.cnblogs.com/Huerye/ /// <summary> /// 读取程序生成byte /// </sum ...
随机推荐
- Go 知识点
必须在源文件中非注释的第一行指明这个文件属于哪个包,如:package main. package main表示一个可独立执行的程序,每个 Go 应用程序都包含一个名为 main 的包. main 函 ...
- Linux中安装nodejs及插件
Linux中安装nodejs及插件 1.去官网下载安装包 英文网址:https://nodejs.org/en/download/ 中文网址:http://nodejs.cn/download/ 通过 ...
- 动态调用WebService的代理类
using System; using System.Collections; using System.ComponentModel; using System.Data; using System ...
- RN 获取组件的宽度和高度
https://www.cnblogs.com/zhiyingzhou/p/7471212.html https://blog.csdn.net/calvin_zhou/article/details ...
- Asynchronous programming in javascript
Javascript是单线程的,因此异步编程对其尤为重要. ES 6以前: * 回调函数* 事件监听(事件发布/订阅)* Promise对象 ES 6: * Generator函数(协程corouti ...
- linux使用shell脚本停止java进程
使用shell脚本停止java进程,过程就是先查出对应的java进程pid,然后kill掉 - | 其中xxx是对应进程的关键词(即从查出的所有java进程中分辨出目标进程)
- python 代理的使用
这里分享一个测试ip的网址 http://ip.filefab.com/index.php scrapy 随机请求头和代理ip的使用原理 import random # 添加一个中间键 cla ...
- 7.9 skippart.c 程序
7.9 skippart.c 程序 #include <stdio.h> int main(void) { const float MIN = 0.0f; const float MAX ...
- Nginx访问控制
1.访问控制 涉及模块:ngx_http_access_module 模块概述:允许限制某些 IP 地址的客户端访问. 对应指令: allow 语法: allow address | CIDR | u ...
- TNS-12541: TNS: 无监听程序 解决方案
转自 感谢 https://www.cnblogs.com/yx007/p/6732012.html 问题描述 在用PL/SQL Developer连接Oracle 11g时报错“ORA-12 ...