048 SparkSQL自定义UDAF函数
一:程序
1.需求
实现一个求平均值的UDAF。
这里保留Double格式化,在完成求平均值后与系统的AVG进行对比,观察正确性。
2.SparkSQLUDFDemo程序
package com.scala.it import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} import scala.math.BigDecimal.RoundingMode object SparkSQLUDFDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("udf")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // ==================================
// 写一个Double数据格式化的自定义函数(给定保留多少位小数部分)
sqlContext.udf.register(
"doubleValueFormat", // 自定义函数名称
(value: Double, scale: Int) => {
// 自定义函数处理的代码块
BigDecimal.valueOf(value).setScale(scale, RoundingMode.HALF_DOWN).doubleValue()
}) // 自定义UDAF
sqlContext.udf.register("selfAvg", AvgUDAF) sqlContext.sql(
"""
|SELECT
| deptno,
| doubleValueFormat(AVG(sal), 2) AS avg_sal,
| doubleValueFormat(selfAvg(sal), 2) AS self_avg_sal
|FROM hadoop09.emp
|GROUP BY deptno
""".stripMargin).show() }
}
3.AvgUDAF程序
package com.scala.it import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._ object AvgUDAF extends UserDefinedAggregateFunction{
override def inputSchema: StructType = {
// 给定UDAF的输出参数类型
StructType(
StructField("sal", DoubleType) :: Nil
)
} override def bufferSchema: StructType = {
// 在计算过程中会涉及到的缓存数据类型
StructType(
StructField("total_sal", DoubleType) ::
StructField("count_sal", LongType) :: Nil
)
} override def dataType: DataType = {
// 给定该UDAF返回的数据类型
DoubleType
} override def deterministic: Boolean = {
// 主要用于是否支持近似查找,如果为false:表示支持多次查询允许结果不一样,为true表示结果必须一样
true
} override def initialize(buffer: MutableAggregationBuffer): Unit = {
// 初始化 ===> 初始化缓存数据
buffer.update(0, 0.0) // 初始化total_sal
buffer.update(1, 0L) // 初始化count_sal
} override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
// 根据输入的数据input,更新缓存buffer的内容
// 获取输入的sal数据
val inputSal = input.getDouble(0) // 获取缓存中的数据
val totalSal = buffer.getDouble(0)
val countSal = buffer.getLong(1) // 更新缓存数据
buffer.update(0, totalSal + inputSal)
buffer.update(1, countSal + 1L)
} override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
// 当两个分区的数据需要进行合并的时候,该方法会被调用
// 功能:将buffer2中的数据合并到buffer1中
// 获取缓存区数据
val buf1Total = buffer1.getDouble(0)
val buf1Count = buffer1.getLong(1) val buf2Total = buffer2.getDouble(0)
val buf2Count = buffer2.getLong(1) // 更新缓存区
buffer1.update(0, buf1Total + buf2Total)
buffer1.update(1, buf1Count + buf2Count)
} override def evaluate(buffer: Row): Any = {
// 求返回值
buffer.getDouble(0) / buffer.getLong(1)
}
}
4.效果

二:知识点
1.udf注册

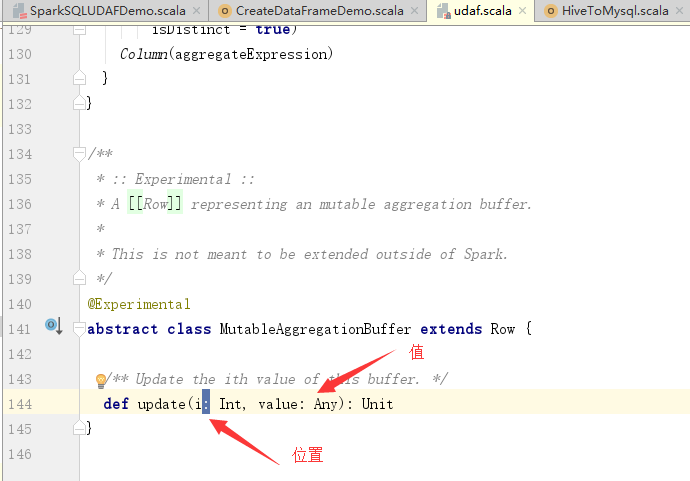
2.解释上面的update
重要的是两个参数的意思,不然程序有些看不懂。
所以,程序的意思是,第一位存储总数,第二位存储个数。
3.还要解释一个StructType的生成
在以前的程序中,是使用Array来生成的。如:

在上面的程序中,不是这种方式,使用集合的方式。

048 SparkSQL自定义UDAF函数的更多相关文章
- hive自定义udaf函数
自定义udaf函数的代码框架 //首先继承一个类AbstractGenericUDAFResolver,然后实现里面的getevaluate方法 public GenericUDAFEvaluator ...
- sparksql 自定义用户函数(UDF)
自定义用户函数有两种方式,区别:是否使用强类型,参考demo:https://github.com/asker124143222/spark-demo 1.不使用强类型,继承UserDefinedAg ...
- 047 SparkSQL自定义UDF函数
一:程序部分 1.需求 Double数据类型格式化,可以给定小数点位数 2.程序 package com.scala.it import org.apache.spark.{SparkConf, Sp ...
- 关于CDH5.2+ 添加hive自定义UDAF函数的方法
- Spark(十三)【SparkSQL自定义UDF/UDAF函数】
目录 一.UDF(一进一出) 二.UDAF(多近一出) spark2.X 实现方式 案例 ①继承UserDefinedAggregateFunction,实现其中的方法 ②创建函数对象,注册函数,在s ...
- 【Spark篇】---SparkSql之UDF函数和UDAF函数
一.前述 SparkSql中自定义函数包括UDF和UDAF UDF:一进一出 UDAF:多进一出 (联想Sum函数) 二.UDF函数 UDF:用户自定义函数,user defined functio ...
- Spark基于自定义聚合函数实现【列转行、行转列】
一.分析 Spark提供了非常丰富的算子,可以实现大部分的逻辑处理,例如,要实现行转列,可以用hiveContext中支持的concat_ws(',', collect_set('字段'))实现.但是 ...
- 自定义Hive函数
7. 函数 7.1 系统内置函数 查看系统自带的函数:show functions; 显示自带的函数的用法:desc function upper(函数名); 详细显示自带的函数的用法:desc fu ...
- 入门大数据---SparkSQL常用聚合函数
一.简单聚合 1.1 数据准备 // 需要导入 spark sql 内置的函数包 import org.apache.spark.sql.functions._ val spark = SparkSe ...
随机推荐
- mvc 母版页保持不刷新
//比如这是左边菜单栏 <ul class="treeview-menu" id="left_menu"> <li><a href ...
- cocos2dx-lua 延迟调用函数和定时器
下面是cocos官方的方法. function performWithDelay(node, callback, delay) local delay = cc.DelayTime:create(de ...
- JS 操作数组对象
我们在操作数组时,加入数组中是以对象的形式存在,例如: 那么我们会涉及到去重复,去掉为0的数组中的对象,js代码如下: function getItemList(gid, totalMoney, ad ...
- 分析Vue框架源码心得
1.在封装一个公用组件,比如button按钮,我们多个地方使用,不同类型的button调用不同的方法,我们就可以这样用 代码片段: <lin-button v-for="(item,i ...
- 【进阶2-2期】JavaScript深入之从作用域链理解闭包(转)
这是我在公众号(高级前端进阶)看到的文章,现在做笔记 https://github.com/yygmind/blog/issues/18 红宝书(p178)上对于闭包的定义:闭包是指有权访问另外一 ...
- python 列表,字典,元组,字符串,常用函数
飞机票 一.列表方法 1.ls.extend(object) 向列表ls中插入object中的每个元素,object可以是字符串,元组和列表(字符串“abc”中包含3个元组),相当于ls和object ...
- LeetCode(67):二进制求和
Easy! 题目描述: 给定两个二进制字符串,返回它们的和(用二进制表示). 输入为非空字符串且只包含数字 1 和 0. 示例 1: 输入: a = "11", b = " ...
- 网络编程—udp
一.ip地址 1. 什么是地址 地址就是用来标记地点的 2. ip地址的作用 ip地址:用来在网络中标记一台电脑,比如192.168.1.1:在本地局域网上是唯一的. 3. ip地址的分类 每一个IP ...
- RESTful架构解读
什么是REST REST与技术无关,代表的是一种软件架构风格.REST全称是Representational State Tranfer, 表征性状态转移. REST从资源的角度类审视整个网络,它将分 ...
- easyUI-layout布局
https://www.cnblogs.com/kexb/p/3685913.html <!DOCTYPE html><html><head> <meta c ...