python3 对拉勾数据进行可视化分析
上回说到我们如何如何把拉勾的数据抓取下来的,既然获取了数据,就别放着不动,把它拿出来分析一下,看看这些数据里面都包含了什么信息。(本次博客源码地址:https://github.com/MaxLyu/Lagou_Analyze)
一、前期准备
由于上次抓的数据里面包含有 ID 这样的信息,我们需要将它去掉,并且查看描述性统计,确认是否存在异常值或者缺失值。
read_file = "analyst.csv"
# 读取文件获得数据
data = pd.read_csv(read_file, encoding="gbk")
# 去除数据中无关的列
data = data[:].drop(['ID'], axis=1)
# 描述性统计
data.describe()
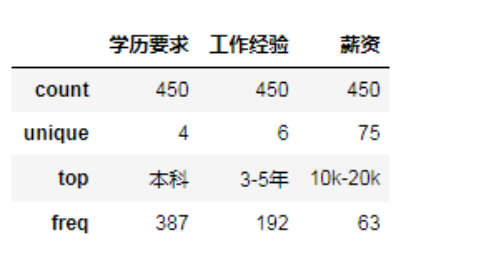
结果中的 unique 表示的是在该属性列下面存在的不同值个数,以学历要求为例子,它包含【本科、大专、硕士、不限】这4个不同的值,top 则表示数量最多的值为【本科】,freq 表示出现的频率为 387。由于薪资的 unique 比较多,我们查看一下存在什么值。
print(data['学历要求'].unique())
print(data['工作经验'].unique())
print(data['薪资'].unique())

二、预处理
从上述两张图可以看到,学历要求和工作经验的值比较少且没有缺失值与异常值,可以直接进行分析;但薪资的分布比较多,总计有75种,为了更好地进行分析,我们要对薪资做一个预处理。根据其分布情况,可以将它分成【5k 以下、5k-10k、10k-20k、20k-30k、30k-40k、40k 以上】,为了更加方便我们分析,取每个薪资范围的中位数,并划分到我们指定的范围内。
# 对薪资进行预处理
def pre_salary(data):
salarys = data['薪资'].values
salary_dic = {}
for salary in salarys:
# 根据'-'进行分割并去掉'k',分别将两端的值转换成整数
min_sa = int(salary.split('-')[0][:-1])
max_sa = int(salary.split('-')[1][:-1])
# 求中位数
median_sa = (min_sa + max_sa) / 2
# 判断其值并划分到指定范围
if median_sa < 5:
salary_dic[u'5k以下'] = salary_dic.get(u'5k以下', 0) + 1
elif median_sa >= 5 and median_sa < 10:
salary_dic[u'5k-10k'] = salary_dic.get(u'5k-10k', 0) + 1
elif median_sa >= 10 and median_sa < 20:
salary_dic[u'10k-20k'] = salary_dic.get(u'10k-20k', 0) + 1
elif median_sa >= 20 and median_sa < 30:
salary_dic[u'20k-30k'] = salary_dic.get(u'20k-30k', 0) + 1
elif median_sa >= 30 and median_sa < 40:
salary_dic[u'30k-40k'] = salary_dic.get(u'30k-40k', 0) + 1
else:
salary_dic[u'40以上'] = salary_dic.get(u'40以上', 0) + 1
print(salary_dic)
return salary_dic
对【薪资】进行预处理之后,还要对【任职要求】的文本进行预处理。因为要做成词云图,需要对文本进行分割并去除掉一些出现频率较多但没有意义的词,我们称之为停用词,所以我们用 jieba 库进行处理。jieba 是一个python实现的分词库,对中文有着很强大的分词能力。
import jieba
def cut_text(text):
stopwords =['熟悉','技术','职位','相关','工作','开发','使用','能力',
'优先','描述','任职','经验','经验者','具有','具备','以上','善于',
'一种','以及','一定','进行','能够','我们']
for stopword in stopwords:
jieba.del_word(stopword) words = jieba.lcut(text)
content = " ".join(words)
return content
预处理完成之后,就可以进行可视化分析了。
三、可视化分析
我们先绘制环状图和柱状图,然后将数据传进去就行了,环状图的代码如下:
def draw_pie(dic):
labels = []
count = [] for key, value in dic.items():
labels.append(key)
count.append(value) fig, ax = plt.subplots(figsize=(8, 6), subplot_kw=dict(aspect="equal")) # 绘制饼状图,wedgeprops 表示每个扇形的宽度
wedges, texts = ax.pie(count, wedgeprops=dict(width=0.5), startangle=0)
# 文本框设置
bbox_props = dict(boxstyle="square,pad=0.9", fc="w", ec="k", lw=0)
# 线与箭头设置
kw = dict(xycoords='data', textcoords='data', arrowprops=dict(arrowstyle="-"),
bbox=bbox_props, zorder=0, va="center") for i, p in enumerate(wedges):
ang = (p.theta2 - p.theta1)/2. + p.theta1
y = np.sin(np.deg2rad(ang))
x = np.cos(np.deg2rad(ang))
# 设置文本框在扇形的哪一侧
horizontalalignment = {-1: "right", 1: "left"}[int(np.sign(x))]
# 用于设置箭头的弯曲程度
connectionstyle = "angle,angleA=0,angleB={}".format(ang)
kw["arrowprops"].update({"connectionstyle": connectionstyle})
# annotate()用于对已绘制的图形做标注,text是注释文本,含 'xy' 的参数跟坐标点有关
text = labels[i] + ": " + str('%.2f' %((count[i])/sum(count)*100)) + "%"
ax.annotate(text, size=13, xy=(x, y), xytext=(1.35*np.sign(x), 1.4*y),
horizontalalignment=horizontalalignment, **kw)
plt.show()
柱状图的代码如下:
def draw_workYear(data):
workyears = list(data[u'工作经验'].values)
wy_dic = {}
labels = []
count = []
# 得到工作经验对应的数目并保存到count中
for workyear in workyears:
wy_dic[workyear] = wy_dic.get(workyear, 0) + 1
print(wy_dic)
# wy_series = pd.Series(wy_dic)
# 分别得到 count 的 key 和 value
for key, value in wy_dic.items():
labels.append(key)
count.append(value)
# 生成 keys 个数的数组
x = np.arange(len(labels)) + 1
# 将 values 转换成数组
y = np.array(count) fig, axes = plt.subplots(figsize=(10, 8))
axes.bar(x, y, color="#1195d0")
plt.xticks(x, labels, size=13, rotation=0)
plt.xlabel(u'工作经验', fontsize=15)
plt.ylabel(u'数量', fontsize=15) # 根据坐标将数字标在图中,ha、va 为对齐方式
for a, b in zip(x, y):
plt.text(a, b+1, '%.0f' % b, ha='center', va='bottom', fontsize=12)
plt.show()
我们再把学历要求和薪资的数据稍微处理一下变成字典形式,传进绘制好的环状图函数就行了。另外,我们还要对【任职要求】的文本进行可视化。
from wordcloud import WordCloud
# 绘制词云图
def draw_wordcloud(content): wc = WordCloud(
font_path = 'c:\\Windows\Fonts\msyh.ttf',
background_color = 'white',
max_font_size=150, # 字体最大值
min_font_size=24, # 字体最小值
random_state=800, # 随机数
collocations=False, # 避免重复单词
width=1600,height=1200,margin=35, # 图像宽高,字间距
)
wc.generate(content) plt.figure(dpi=160) # 放大或缩小
plt.imshow(wc, interpolation='catrom',vmax=1000)
plt.axis("off") # 隐藏坐标
四、成果与总结
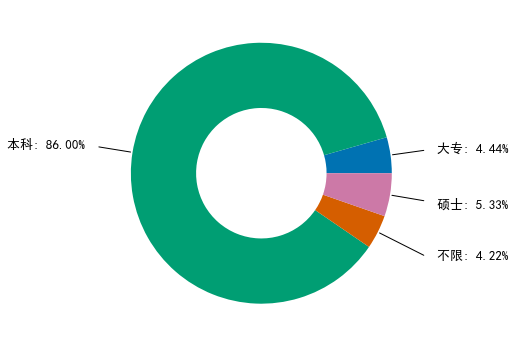
python数据分析师的学历大部分要求是本科,占了86%。

从柱状图可以看出,python数据分析师的工作经验绝大部分要求1-5年。
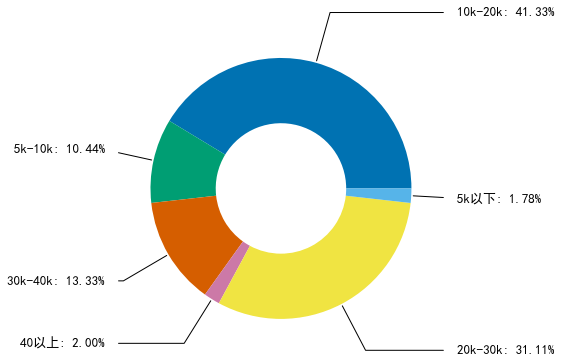
由此可以得出python数据分析的工资为10k-30k的比较多,工资高的估计要求会比较高,所以我们看一下职位要求。

从词云图可看出,数据分析肯定要对数据比较敏感,并且对统计学、excel、python、数据挖掘、hadoop等也有一定的要求。不仅如此,还要求具有一定的抗压能力、解决问题的能力、良好的表达能力、思维能力等。
python3 对拉勾数据进行可视化分析的更多相关文章
- OneAPM大讲堂 | 监控数据的可视化分析神器 Grafana 的告警实践
文章系国内领先的 ITOM 管理平台供应商 OneAPM 编译呈现. 概览 Grafana 是一个开源的监控数据分析和可视化套件.最常用于对基础设施和应用数据分析的时间序列数据进行可视化分析,也可以用 ...
- 用Python爬取《王者荣耀》英雄皮肤数据并可视化分析,用图说话
大家好,我是辰哥~ 今天辰哥带大家分析一波当前热门手游<王者荣耀>英雄皮肤,比如皮肤上线时间.皮肤类型(勇者:史诗:传说等).价格. 1.获取数据 数据来源于<王者荣耀官方网站> ...
- 毕设之Python爬取天气数据及可视化分析
写在前面的一些P话:(https://jq.qq.com/?_wv=1027&k=RFkfeU8j) 天气预报我们每天都会关注,我们可以根据未来的天气增减衣物.安排出行,每天的气温.风速风向. ...
- 大数据Web可视化分析系统开发
下载地址 https://tomcat.apache.org/download-70.cgi 打开我们的idea 这些的话都可以按照自己的需求来修改 在这里新建包 新建一个java类 package ...
- 汽车数据的可视化分析(R)
数据下载:http://www.fueleconomy.gov/feg/epadata/vehicles.csv.zip 将数据导入R中, 1.首先将工作路径设定到本地保存了vehicles.csv的 ...
- 通过 Azure IoT 中心实现互联网设备数据的可视化分析
本课程主要介绍了如何 在Azure 平台上借助 Azure IoT 中心, Azure 流分析,Web 应用, Azure 数据库等服务快速构建收集处理并可视化来自设备的数据流的应用, 包括项目背景介 ...
- 新闻实时分析系统 大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计 2.下载Tomcat并创建Web工程并配置相关服务 下载tomcat,解压并启动tomcat服务. 1)新建web app项目 创建好之后的效果 2)对tomcat进 ...
- 新闻网大数据实时分析可视化系统项目——21、大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计 2.下载Tomcat并创建Web工程并配置相关服务 下载tomcat,解压并启动tomcat服务. 1)新建web app项目 创建好之后的效果 2)对tomcat进 ...
- 爬虫综合大作业——网易云音乐爬虫 & 数据可视化分析
作业要求来自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075 爬虫综合大作业 选择一个热点或者你感兴趣的主题. 选择爬取的对象 ...
随机推荐
- easyui属性赋值
了解easyui tree组件的童鞋估计都知道tree的node有他自己单独的属性(id,text,iconCls,checked,state,attribute,target).而原先这个几个属性想 ...
- dhcp服务简单配置
dhcp服务搭建 注意事项: > 配置虚拟机虚拟网络编辑器,取消"使用本地DHCP服务将IP地址分配给虚拟机" > 虚拟机网络连接设置为"仅主机模式" ...
- Python爬虫的学习经历
在准备学习人工智能之前呢,我看了一下大体的学习纲领.发现排在前面的是PYTHON的基础知识和爬虫相关的知识,再者就是相关的数学算法与金融分析.不过想来也是,如果想进行大量的数据运算与分析,宏大的基础数 ...
- 学习笔记----php环境配置
Php开发环境自定义搭建 (万事开头难) 第一步:Apache安装(httpd-2.4.37-win64-VC15.zip) 下载已编译apache安装包:Apachelounge官方下载地址:htt ...
- Python 递归 Resursion()
条件: ①递归有最小值或有确定值 ②fun(x) = ax * bfun(x-1) 类似规则 eg. n! : ①1! = 1 ②n! = n* (n-1)! def factorial (n): ...
- SQL Server 存储过程的运用
概述 最近因为业务的需求写了一段时间存储过程,发现之前写的存储过程存在一些不严谨的地方,特别是TRY...CATCH中嵌套事务的写法:虽然之前写的并没有错,但是还是埋藏着很大的隐患在里面.希望这篇文章 ...
- Senparc.Weixin SDK 微信公众号 .NET 开发教程 索引
Senparc.WeixinSDK从一开始就坚持开源的状态,这个过程中得到了许多朋友的认可和支持. 目前SDK已经达到比较稳定的版本,这个过程中我觉得有必要整理一些思路和经验,和大家一起分享.也欢迎大 ...
- 大叔学ML第三:多项式回归
目录 基本形式 小试牛刀 再试牛刀 调用类库 基本形式 上文中,大叔说道了线性回归,线性回归是个非常直观又简单的模型,但是很多时候,数据的分布并不是线性的,如: 如果我们想用高次多项式拟合上面的数据应 ...
- 【洛谷4172】 [WC2006]水管局长(LCT)
传送门 洛谷 BZOJ Solution 如果不需要动态的话,那就是一个裸的最小生成树上的最大边权对吧. 现在动态了的话,把这个过程反着来,就是加边对吧. 现在问题变成了怎么动态维护加边的最小生成树, ...
- map put值 使用匿名函数
List<Map<String, Object>> list = setRoleMenuRlMapper.selectMapByParams(params); // Map m ...