Pandas基础使用
Pandas是基于NumPy的一种工具,该工具是为了解决数据分析任务而创建的。
1、导入pandas
import pandas as pd
2、pandas数据类型:
1)Series:一维数据类型,其中每个元素都有一个标签
2)DataFrame:二维数据类型,它可以存储各种不同类型的数据,每个元素都有自己的标签
3、Series对象的创建
s = pd.Series([-1.234,2.354,1.256,-5.235])

可以看到如果我们没有指定行索引,pandas将会默认给它创建0,1,2,...等作为行索引
当然我们也可以给它指定行索引index,如下:

注意上面两个例子中打印出来的的type,下面我们将其中一个数字改为字符串,这时候,它就不再是单纯的数字了,它的dtype就变成了object

也就是说,我们可以指定dtype输出,如下,指定dtype为int,输出值就全部去掉小数部分,只打印出了整数部分的值:

除了上面的以list创建Series外,还可以通过字典方式,常量值等来创建Series


4、Series对象的访问
s.values:获取所有的值列表
s.index:获取所有的行索引列表
s['a'] :访问索引为'a'的元素
s[0] : 访问第1个元素
s[['a', 'b']]:访问索引为a和b的两个元素
s[:2]:访问前两个元素
5、DataFrame对象的生成
pd.DataFrame(data, index, column)
data数据类型:列表嵌套的列表,列表组成的字典,Series组成的字典,字典组成的字典等
index:行索引列表
column:列索引列表
行索引和列索引都可以为为空,pandas会自动以0,1,2,...等为它创建索引
1)以列表嵌套列表的方式生成DataFrame,外层列表长度表示行数,内层列表最大长度表示列数

2)以列表组成的字典,列表长度需要相同,将会默认以字典的key作为列索引

3)Series组成的字典生成DataFrame

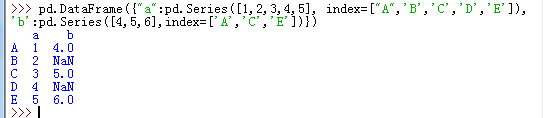
以字典形式生成的DataFrame对象,会以key的并集作为列索引,index的并集作为行索引,不存在的赋值为NaN
6、DataFrame对象的读取
df.index:获取行索引列表
df.values:获取值列表
df.columns:获取列索引列表
df.a/ df['a']:获取列索引为first的元素
df[0:1]:获取第一行元素
df[:3]:获取前三行元素
df.loc[:, :]:访问所有行,所有列元素
df.loc[:, ['a', 'b']]:访问所有行,列为a和b的元素
df.loc[['a'], ['b']]:访问行为a,列为b的元素
df.iloc[:,:]:访问所有行,所有列元素
df.iloc[0:2, :2]:访问前两行,前两列元素
df.iloc[[0,2], 0:2]:访问第1行,第3行及前两列元素
df.ix[:,:]:访问所有行,所有列元素
df.ix[:2, ['a','b']]:访问前两行,列索引为a和b的元素
df.ix[df.a>1, :2]:访问所有列索引为a的元素中,大于1的元素的行和前两列的元素
7、下面我们以股票交易数据为例来分析:
我这里有一个csv格式的近两年来的股票数据( table.csv )
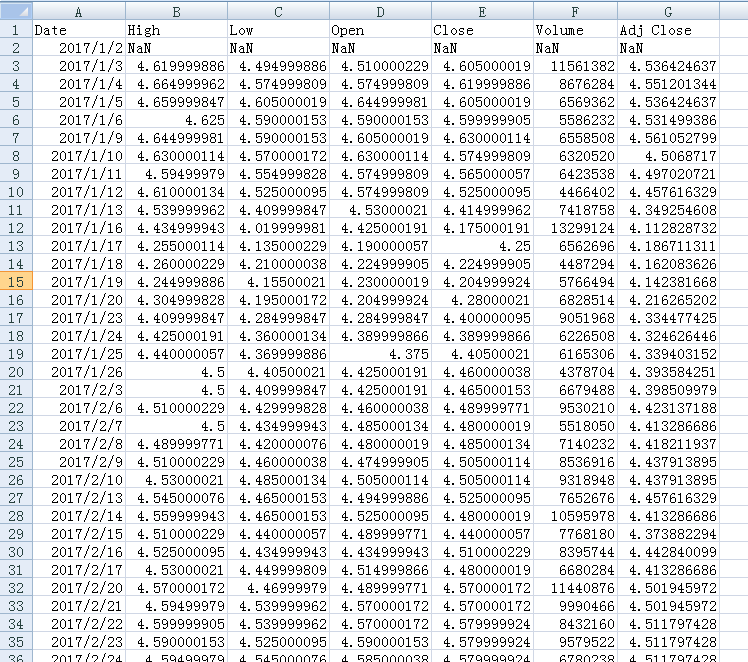
1)读取csv文件
df = pd.read_csv("C:\\Users\\admin\\Desktop\\table.csv",parse_dates=True, header=0,index_col=0,encoding="gb2312")
2)数据内容查看方法:
df.head(n):查看前n行数据
df.tail(n):查看后n行数据
df.columns:查看所有的索引列列表
df.index:查看所有的行索引列表
df.values:查看所有的值列表
df.shape:查看行数和列数
df.describe():查看基本信息,如总条数,最小值,最大值,平均数等
df.info():可以查看有几条非空数据
df.isnull():查看所有数据是否为空
df[df.isnull().T.any()]:查看含有空元素的行
df.fillna(method='bfill', axis=0, inplace=True):用下一行的数据替换掉NaN(用上一行method='ffill', 指定值替换用value=指定值)
3、特殊值处理方法
df.round(n):四舍五入,保留n位小数
df.astype(type):按照指定的格式转换数值
df.Volume.astype(int):将volume列的数值转换为int类型
applymap:可以搭配lambda使用,做数据格式转换
df.applymap(lambda x: '%0.2f' % x):保留两位小数
df.ix[:, ['Volume']].apply(lambda x: '%0.0f' % x):保留0位小数
df[df.values==0]:查找值为0的数据
df.loc[df.loc[:, high]==0, 'High'] = df.High.median():将High列为0的数值替换为High列的中间值
Pandas基础使用的更多相关文章
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- Pandas基础学习与Spark Python初探
摘要:pandas是一个强大的Python数据分析工具包,pandas的两个主要数据结构Series(一维)和DataFrame(二维)处理了金融,统计,社会中的绝大多数典型用例科学,以及许多工程领域 ...
- numpy&pandas基础
numpy基础 import numpy as np 定义array In [156]: np.ones(3) Out[156]: array([1., 1., 1.]) In [157]: np.o ...
- Pandas 基础(1) - 初识及安装 yupyter
Hello, 大家好, 昨天说了我会再更新一个关于 Pandas 基础知识的教程, 这里就是啦......Pandas 被广泛应用于数据分析领域, 是一个很好的分析工具, 也是我们后面学习 machi ...
- 基于 Python 和 Pandas 的数据分析(2) --- Pandas 基础
在这个用 Python 和 Pandas 实现数据分析的教程中, 我们将明确一些 Pandas 基础知识. 加载到 Pandas Dataframe 的数据形式可以很多, 但是通常需要能形成行和列的数 ...
- python学习笔记(四):pandas基础
pandas 基础 serise import pandas as pd from pandas import Series, DataFrame obj = Series([4, -7, 5, 3] ...
- 数据分析02 /pandas基础
数据分析02 /pandas基础 目录 数据分析02 /pandas基础 1. pandas简介 2. Series 3. DataFrame 4. 总结: 1. pandas简介 numpy能够帮助 ...
随机推荐
- 产品经理说| AIOps 让告警变得更智能 (下)
AIOps 人工智能和IT运营支撑 Ops 之间的故事,愈演愈烈,已经成为当今运维圈的热门话题,我打算从2篇文档分享我们在 AIOps 上一些探索和实践.(上篇)主要介绍了为什么事件(告警)处理需要 ...
- Oracle EBS compile PLD PLL files.
PLL->PLX:frmcmp_batch module_type=library userid=apps/apps module=$1.pll output_file=$1.plx compi ...
- mysql 数据库安装
一.Mysql的安装 1. 安装mysql-server服务端 版本5.7.19-0ubuntu0.16.04.1 目前可以下载的版本: 5.5 5.6 5.7 8.0 测试版 输入:(我这里不需要客 ...
- oracle外部表
关于外部表的描述 正确描述 the create table as select statement can be used to upload data into a normal table in ...
- C# -- 使用递归列出文件夹目录及目录下的文件
使用递归列出文件夹目录及目录的下文件 1.使用递归列出文件夹目录及目录下文件,并将文件目录结构在TreeView控件中显示出来. 新建一个WinForm应用程序,放置一个TreeView控件: 代码实 ...
- sklearn使用——最小二乘法
参考网页:http://sklearn.apachecn.org/cn/0.19.0/ 其中提供了中文版的文件说明,较为清晰. from sklearn.linear_model import Lin ...
- LeetCode算法题-Range Sum Query Immutable(Java实现)
这是悦乐书的第204次更新,第214篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第70题(顺位题号是303).给定整数数组nums,找到索引i和j(i≤j)之间的元素之 ...
- tomcat session 共享
1. nginx+tomcat7+memcached 安装JDK7sudo apt-get install java7-jdk 安装tomcat7Tomcat7下载地址http://mirror.bj ...
- [福大软工] Z班 第12次成绩排行榜
注:本次成绩排行榜是针对结对项目二的点评分数 作业要求 http://www.cnblogs.com/easteast/p/7604534.html 评分细则 (1)有贴生成得最"好&quo ...
- socket 如何判断远端服务器的连接状态?连接断开,需重连
fluent-logger-java is a Java library, to record events via Fluentd, from Java application. https://g ...