Storm集群部署
一. 说明
Storm是一个分布式实时计算系统,Storm对于实时计算的意义就相当于Hadoop对于批量计算的意义。对于实时性较高的系统Storm是不错的选择。Hadoop提供了map, reduce原语,使批处理程序变得非常地简单和优美。同样,storm也为实时计算提供了一些简单优美的原语。
涉及的术语说明:
Nimbus:Storm集群的主控节点,负责在Storm集群内分发代码,分配任务给工作机器,并且负责监控集群运行状态。其进程名为nimbus。
Supervisor:Supervisor负责监听从Nimbus分配给它执行的任务,据此启动或停止执行任务的工作进程。其进程名为supervisor。
core:Storm的UI服务进程。
安装部署前的准备工作:
1. 配置各主机IP,将各主机IP配置为静态IP(保证各主机可以正常通信,为避免过多的网络传输,建议在同一网段)。
2. 修改各主机名,Storm集群中的所有主机都需要修改。
3. 配置各主机映射,修改hosts文件,加入各主机IP和主机名的映射。
4. 开放相应端口,后面文档中配置的端口都需要开放(或者关闭防火墙)。
5. Python2.7及以上版本。
6. 保证Zookeeper集群服务正常运行。如果在CentOS上安装过Hadoop或者Zookeeper的话,1-5项基本没问题。关于Zookeeper参考:http://www.cnblogs.com/wxisme/p/5178211.html。
7. 这里使用的JDK、Storm版本分别为1.8和0.9.5。
二. 安装配置Storm集群
1. 到Storm官网下载对应的安装包并上传到集群节点。
2. 解压安装包
tar -xvzf apache-storm-0.9..tar.gz
3. 修改storm.yaml配置文件
vim conf/storm.yaml
Storm集群使用的Zookeeper集群地址,根据实际情况进行修改。
storm.zookeeper.servers:
- "node1"
- "node2"
- "node3"
Zookeeper的端口不是默认端口时需要配置参数:
storm.zookeeper.port: "修改的端口"
Nimbus和Supervisor进程用于存储少量状态,如jars、confs等的本地磁盘目录,需要提前创建该目录(根据实际情况创建)并给以足够的访问权限。
storm.local.dir: "/usr/storm/data"
Storm集群Nimbus机器地址,各个Supervisor工作节点需要知道哪个机器是Nimbus,以便下载Topologies的jars、confs等文件。根据实际情况进行修改。
nimbus.host: "node3"
对于每个Supervisor工作节点,需要配置该工作节点可以运行的worker数量。每个worker占用一个单独的端口用于接收消息,该配置选项即用于定义哪些端口是可被worker使用的。默认情况下,每个节点上可运行4个workers,分别在6700、6701、6702和6703端口。根据实际情况进行修改。
supervisor.slots.ports:
-
-
-
DRPC提供了集群中处理功能的访问接口,storm集群drpc地址,根据实际情况进行修改。关于DRCP参考:http://www.dataguru.cn/article-5572-1.html
drpc.servers:
- "node3"
默认情况下,Storm启动worker进程时,JVM的最大内存是768M。由于在使用过程中,Bolt中加载大量数据,768M内存无法满足要求,会导致内存溢出。根据实际情况进行修改。
worker.childopts: "-Xmx1024m"
注意:上面的各项配置之间最好不要留有空行或者其他的空白字符。
三. 启动Storm集群
1. 在主控节点启动Nimbus服务
bin/storm nimbus >> /dev/null &
查看nimbus服务是否启动:
jps
2.在各个节点启动Supervisor服务
bin/storm supervisor >> /dev/null &
3.启动drpc服务
bin/storm drpc >> /dev/null &
4.在主控节点启动Storm UI服务
bin/storm ui >> /dev/null &
查看UI服务是否启动:
jps
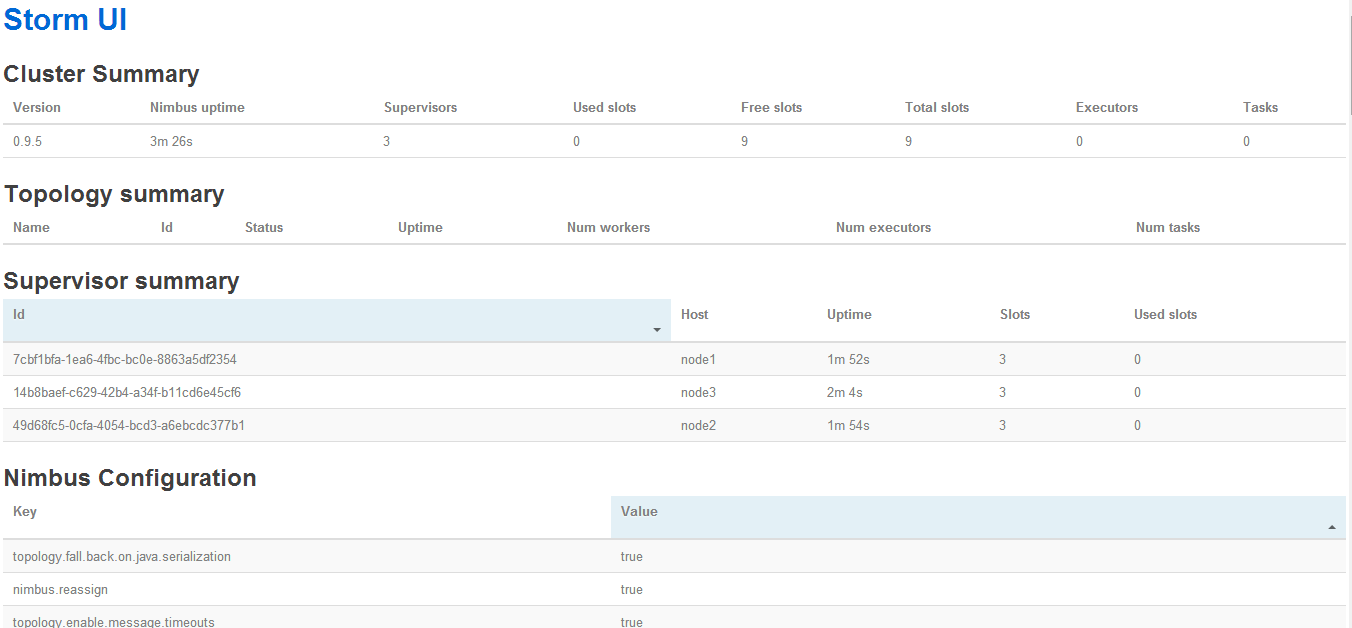
访问Storm UI
http://nimbus:8080/
四. 向Storm集群提交服务
执行以下命令,启动Storm Topology:
bin/storm jar test.jar com.test.MyTopology arg1 arg2
其中,test.jar是包含Topology实现代码的jar包,com.test.MyTopology的main方法是Topology的入口,arg1和arg2为com.test.MyTopology执行时需要传入的参数。
停止Storm Topology:
bin/storm kill {toponame}
其中,{toponame}为Topology提交到Storm集群时指定的Topology任务名称。
简单的Storm集群就部署好了,可以开始愉快的Storm之旅了!
Storm集群部署的更多相关文章
- Storm 系列(三)Storm 集群部署和配置
Storm 系列(二)Storm 集群部署和配置 本章中主要介绍了 Storm 的部署过程以及相关的配置信息.通过本章内容,帮助读者从零开始搭建一个 Storm 集群. 一.Storm 的依赖组件 1 ...
- Storm集群部署及单词技术
1. 集群部署的基本流程 集群部署的流程:下载安装包.解压安装包.修改配置文件.分发安装包.启动集群 注意: 所有的集群上都需要配置hosts vi /etc/hosts 192.168.239.1 ...
- 2.Storm集群部署及单词统计案例
1.集群部署的基本流程 2.集群部署的基础环境准备 3.Storm集群部署 4.Storm集群的进程及日志熟悉 5.Storm集群的常用操作命令 6.Storm源码下载及目录熟悉 7.Storm 单词 ...
- storm集群部署和配置过程详解
先整体介绍一下搭建storm集群的步骤: 设置zookeeper集群 安装依赖到所有nimbus和worker节点 下载并解压storm发布版本到所有nimbus和worker节点 配置storm ...
- Storm1.0.3集群部署
Storm集群部署 所有集群部署的基本流程都差不多:下载安装包并上传.解压安装包并配置环境变量.修改配置文件.分发安装包.启动集群.查看集群是否部署成功. 1.所有的集群上都要配置hosts vi ...
- 02_Storm集群部署
1. 部署前的硬件及软件检查 硬件要求 1)storm集群部署包括zookeeper部署,而zookeeper集群最小为3台机器2)storm的计算过程都在内存中完成,因此内存要尽量大3)storm少 ...
- Storm集群安装部署步骤【详细版】
作者: 大圆那些事 | 文章可以转载,请以超链接形式标明文章原始出处和作者信息 网址: http://www.cnblogs.com/panfeng412/archive/2012/11/30/how ...
- Storm入门教程 第三章Storm集群安装部署步骤、storm开发环境
一. Storm集群组件 Storm集群中包含两类节点:主控节点(Master Node)和工作节点(Work Node).其分别对应的角色如下: 主控节点(Master Node)上运行一个被称为N ...
- Storm集群安装部署步骤
本文以Twitter Storm官方Wiki为基础,详细描述如何快速搭建一个Storm集群,其中,项目实践中遇到的问题及经验总结,在相应章节以"注意事项"的形式给出. 1. Sto ...
随机推荐
- android 平台搭建
直接到官网下载 http://developer.android.com/sdk/index.html?utm_source=weibolife
- 用thinkphp写的一个例子:抓取网站的内容并且保存到本地
我需要写这么一个例子,到电子课本网下载一本电子书. 电子课本网的电子书,是把书的每一页当成一个图片,然后一本书就是有很多张图片,我需要批量的进行下载图片操作. 下面是代码部分: public func ...
- 解决部份机型toast不显示问题
问题:部份机型不显示toast 解决方案: 1.自己在设置里面去允许通知,但是显然客户会说别的app都可以,so 2.自定义解决.查看toast的源码发现其附着在window上 源码下载地址:http ...
- Android开发(三十一)——重复引用包错误Conversion to Dalvik format failed
错误:Conversion to Dalvik format failed: Unable to execute dex: Multiple dex files define Landroid/sup ...
- Android学习笔记----Activity的生命周期图示
转载,一目了然.
- 在线制作h5——上帝的礼物
在线制作h5 网址:http://www.godgiftgame.com 网站名称:上帝的礼物 推荐指数:5颗星 功能概要 可以设置背景.元素图片.元素文字.元素图形.声音.加载.链接.分享,生成h5 ...
- 小数量宽带用户的福音,Panabit 云计费easyradius 接口隆重发布,PA宽带计费系统
PA接口在早前就发布了,但是一直迟迟没有发布官方说明文档,由于最近问的客户较多,特写了这篇文档 由于PA使用标准radius认证协议,所以用户需要在本地搭建一个计费,由于大部分用户的数量只有几百个,不 ...
- ASP.NET 4.0 forms authentication issues with IE11
As I mentioned earlier, solutions that rely on User-Agent sniffing may break, when a new browser or ...
- xml和xsd架构文档相关知识
1.使用架构(XSD)验证XML文件 2.使用自动生成工具: 工具目录:C:\Program Files (x86)\Microsoft SDKs\Windows\v8.0A\bin\NETFX 4. ...
- C primer plus 练习题 第七章
1. #include <stdio.h> #define SPACE ' ' #define NEWLINE '\n' int main() { int spaces,newlines, ...