神经网络:多层网络与C++实现
相关源码可参考最新的实现:https://github.com/ronnyyoung/EasyML ,中的neural_network模块,后持续更新,包括加入CNN的结构。
一、引言
在前一篇关于神经网络的文章中,给出了神经网络中单个神经元的结构和作用原理,并且用梯度下降的方法推导了单个SIMGOID单元的权值更新法则。在文章的最后给了一个例子,我们以一个4维的单位向量作为特征,映射到一维的[0,1]的空间中,我们采用了一个感知器单元,实验结果发现经过15000次(实际应该在5000次左右已经收敛了)的训练后,对于给出的特征向量,感知器单元总是能够得到很接近我们预期的结果了。然而在实际应用过程中,单个神经元不能拟合太复杂的映射关系,我们需要构建更复杂的网络来逼近那些更复杂的目标函数,本文的最后,我们会用多层网络处理前一篇文章中的例子,经过300-500次的训练,就可以很好的收敛。
本篇文章为神经网络这个主题的第二篇文章,主要介绍多层网络的结构及用反向传播算法对权值进行更新,最后我们会一步一步用C++对整个结构进行实现。
二、多层网络结构
多层网络,顾名思义就是由多个层结构组成的网络系统,它的每一层都是由若干个神经元结点构成,该层的任意一个结点都与上一层的每一个结点相联,由它们来提供输入,经过计算产生该结点的输出并作为下一层结点的输入。
值得注意的是任何多层的网络结构必须有一输入层、一个输出层。下面的图结构是更形象的表示:
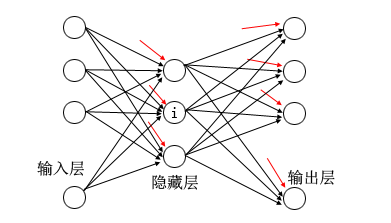
我们从图像中来再次说明多层网络的结构:上图是一个3层的网络结构,它由一个输入层、一个输出层和一个隐藏层构成,当然隐藏层的层数可以更多。图像隐藏层的结点$i$与输入层的每一个结点相连,也就是说它接收了一组向量$input=[x_1,x_2,x_3,\cdots,x_n]$作为输入,同时与它相连的n条线代表了n个输入的权值。特别要注意的是图像隐藏层结点与输出结点还有一个红色的连线,它们代表了偏置,即$w_0$。
那么结合上篇文章的内容,我们知道图像的i结点,它将输入与对应的权值进行线性加权求和,然后经过$sigmoid函数$计算,把得到的结果作为该个结点的输出。
$$net_i=w_0+x_1w_1+x_2w_2+x_3w_3+x_nw_n=\sum_{i=0}^{N=n}x_iw_i.(其中x_0=1)$$
$$o_i=\frac{1}{1+e^{-net_i}}$$
整个多层网络就是由一组输入开始,然后按每条连结线的权重,进行一直的向前计算。这里我们进一步对上面这个网络结构进行量化,以便后面实现:首先它是一个三层的网络结构,第一层是输入层,它本身没有接收输入,也没有连线进来;第二层有3个结点,并且有3*(4+1)根连结线,注意每个结点有一个偏置线;最后一层是输出层,它有4个结点,并且有4*(3+1)根连结线。所以说整个网络结构为$[layer1,layer2,layer3]$,而每一层都是这样的结构:$layer=[nodes,weights]$。
三、反向传播算法
我们已经在上篇文章中讨论了单个结点用梯度下降的方法,可以去更新权值向量。而对于多层网络结构,我们也可以用类似的方法也推导整个网络的权值更新法则,我们把这种方法叫作反向传播算法,因为它是从输出层开始向前逐层更新权值的。
那么我们先从输出层考虑,还是先考虑整个输出误差是多少?不同与单个感知器单元(一个输出),多层网络结构具有多个输出,那么它的误差计算公式可以用LSM法则表示如下:
$$E(w)=\frac{1}{2}\sum_{d \in D}\sum_{k \in outputs}(t_{kd}-o_{kd})^2$$
其中,$outputs$是网络输出单元的集合,$D$还是代表所有训练样本空间,$t_{kd}$和$o_{kd}$是与训练样例$d$和第$k$个输出单元相关的预期值与输出值。
我们的目标是搜索一个巨大的假设空间,这个假设空间由网络结构中所有可能的权值构成。如果用几何的定义来思考,那么这个巨大的搜索空间构成了一个误差曲面,我们需要找到这个曲面上的最小值点。显然,梯度下降是我们的一个方法,我们通过计算曲面任何点的梯度方向,然后沿着反方向去改变权值,就会使误差变小。
回忆我们一篇文章讲到的随机梯度下降法则,我们将它应用在多层网络的反向传播算法中。我们每次只处理一个样本实例,然后更新各个权值,通过大量的样本实例逐渐的调整权值。那么对于每一次的训练样例$d$来说,它的输出误差为:
$$E_d(w)=\frac{1}{2}\sum_{k \in outputs}(t_{kd}-o_{kd})^2$$
对于输出层的结点上的连线权值,很明显它们可以直接影响到最终的误差,而隐藏层结点上的连结线权值只能间接的影响最后的结果,所以我们分两种情况来推导反向传播算法。
情况1:对于输出单元的权值训练法则:
我们知道每个结点前的所有连结线只能通过影响net(net的定义在上面的公式中)的结果来影响误差E,所以有:
$$\frac{\partial E_d}{\partial w_i}=\frac{\partial E_d}{\partial net}\frac{\partial net}{\partial w_i}=\frac{\partial E_d}{\partial net}x_i$$
所以我们只用推导出$\frac{\partial E_d}{\partial net}$即可。
$$\frac{\partial E_d}{\partial net}=\frac{\partial E_d}{\partial o}\frac{\partial o}{\partial net}=-(t-o)o(1-o)$$
将上面的两个公式合并,我们就得到了更新权值的法则,如下:
$$w_i \gets w_i+\Delta w \\\Delta w=-\eta \frac{\partial E_d}{\partial w_i}x_i=\eta (t-o)o(1-o)x_i$$
我们把其中的$(t-o)o(1-o)$看成与该个结点相关的误差项,并用符号$\delta$表示。
情况2:隐藏单元的权值训练法则
隐藏层中的任意结点上的连结线权值都是通过影响以它的输出作为输入的下一层(downstream)的结点而最终影响误差的,所以隐藏层的推导如下:
$$\frac{\partial E_d}{\partial net_i}=\sum_{k \in ds(i)}\frac{\partial E_d}{\partial net_k}\frac{\partial net_k}{net_i}
= \sum_{k \in ds(i)}-\delta_k \frac{\partial net_k}{net_i}=-o_i(1-o_i)\sum_{k \in ds(i)}\delta_k w_{ki}$$
所以隐藏层单元权值更新法则为:
$$w_i \gets w_i+\Delta w_i \\\Delta w_i=-\eta \delta_i x_i \\\delta_i=o(1-o)\sum_{k \in ds(i)}\delta_kw_{ki}$$
OK,上面内容就是反向传播算法,上面公式中有些中间推导步骤省略了,无非是一些链式法则求导的内容。不过就算没弄清楚整个推导过程也没有关系,只要按下面的算法来更新你的所有权值即可。
1,对于训练样例training_examples中的每个$<\vec{x},\vec{t}>$,把输入沿网络传播,计算出网络中每个单元$u$的输出$o_u$;
2,对于网络中的每个输出单元$k$,计算它的误差项$\delta_k$
$$\delta_k \gets o_k(1-o_k)(t_k-o_k)$$
3,对于网络中的每个隐藏的单元$h$,计算它的误差项$\delta_h$
$$\delta_h \gets o_h(1-o_h)\sum_{k \in outputs}w_{kh}\delta_k$$
4,更新每个网络权值$w_{ji}$
$$w_{ji} \gets w_{ji}+\Delta w_{ji},其中,\Delta w_{ji}=\eta \delta_j x_{ji}$$
四、深入讨论
收敛性与局部最小值
正如前面所说的反向传播算法实现了一种对可能的网络权值空间的梯度下降搜索,它不断迭代从而减小训练样例目标值与网络输出之间的误差。但因为多层网络,误差曲面可能含有多个不同的局部极小值,我们的梯度下降可以收敛在这些极小值中。因此,对于多层网络,反向传播算法仅能保证收敛到误差E的某个局部极小值,不一定收敛到全局最小误差。
尽管缺乏对收敛到全局最小误差的保证,反向传播算法在实践中仍是非常有效的函数逼近算法。对很多实际中的应用,人们发现局部最小值的问题没有想像的那么严重。因为局部极小值往往是对于某个权值而言,些时其他权值未必也是极小值。事实上网络的权越多,误差曲面维数越多,也就越可能为梯度下降提供更多的“逃逸路线”让梯度下降离开相对该单个权值的局部极小值。
另外一个观点是,我们开始给权值初始化的值都非常小,接近于0,在这样小权值的情况下,sigoid函数可以近似的看为线性的,所以在权值变化的初期是不存在局部极小值问题的,而到了后期整个网络到了高度非线性的时候,可能这里的极小值点已经很接近全局最小值了。
多层网络的处理能力
很多人都会在这里发出疑问,什么类型的函数可以使用多层网络来表示呢?或者说什么样的分类问题可以用多层网络来表示呢?答案是:任意函数。任意函数可以被一个有三层单元的网络以任意精度逼近(Cybenko 1988)。但是值得注意的是,我们使用的梯度下降算法并没有搜索整个权值空间,所以我们很可能会漏掉那个最合适的权值集合。
归纳偏置
什么是归纳偏置?举个例子,假如我们有两个样本$x_1=[1,0,0,0]$和$x_2=[0.8,0,0,0]$并且我们认为它们属于同一类别,即如果把它们作为神经网络的输入,我们希望它们得到同样的输出。训练样本中只有这两个实例,但是如果我们需要得到$x_3=[0.9,0,0,0]$的输出时,它的结果会和$x_1$,$x_2$的输出一样。神经网络的这种能力,我们称它为归纳偏置的能力,实际网络是在数据点之间平滑插值。
过度拟合
因为我们收集到的样本中有些样本可能由于我们分类错误等原因,造成了一个错误的样本用例,实际上神经网络对这种带有噪点的样本的适应性很强。但是在上面我们介绍的原理中,我们并没有规定权值迭代更新的终止条件,往往我们是设置了一个迭代次数来控制,也就有可能造成,在训练的后期那些权值是过度拟合那些噪点样本。这个问题没有统一的解决方案,现在比较常用的方法就是通过交叉验证,即在训练的同时,用一组校验校本进行测试,找出分类率回降的一个点,从而终于训练过程。
五、ANN的实现
我们首先来定义几个类,用它们来分别表示神经网络结构中一些基本组件:整个网络(NeuralNetwork)、单层网络(NNlayer)、神经元结点(NNneural)、连接线(NNconnection)。
首先整个网络包含了一些参数,如层数、每层的结点数、迭代次数、每次实例的输出等,同时一个网络结构应该有的功能:设置参数、初始化网络、网络向前传播、反向传播、样本输入、训练等。
class NNlayer;
class NNneural;
class NNconnection; class NeuralNetwork
{
private:
unsigned nLayer; // 网络层数
vector<unsigned> nodes; // 每层的结点数
vector<double> actualOutput; // 每次迭代的输出结果
double etaLearningRate; // 权值学习率
unsigned iterNum; // 迭代次数
public:
vector<NNlayer*> m_layers; // 整个网络层
void create(unsigned num_layers,unsigned * ar_nodes); // 创建网络
void initializeNetwork(); // 初始化网络,包括设置权值等
void forwardCalculate(vector<double>& invect,vector<double>& outvect); // 向前计算
void backPropagate(vector<double>& tVect,vector<double>& oVect); //反向传播 void train(vector<vector<double>>& inputVect,vector<vector<double>>& outputVect); //训练
void classifer(vector<double>& inVect,vector<double>& outVect); // 分类
};
然后设计单层网络结构,我们需要一个指针成员来说明层与层之间的连接关系,同时每层网络是由大量的神经元结点构成,同时我们将权值向量作为了每一层的成员,为什么没有将权值与每个结点上的连接线捆在一起呢?那是因为到后面介绍到卷积神经网络的时候,你会发现很多结点可以共有一个权值。
class NNlayer
{
public:
NNlayer(){ preLayer = NULL; }
NNlayer *preLayer;
vector<NNneural> m_neurals;
vector<double> m_weights;
void addNeurals(unsigned num, unsigned preNumNeurals);
void backPropagate(vector<double>& dErrWrtDxn, vector<double>& dErrWrtDxnm, double eta);
};
然后就是每个结点类和结点上的连接线,每个结点包含了一个输出和若干个连接线。这里连接线里保存是两个索引值,它表明条连接线的权重在整个权重向量中的索引与它连接的前面一层结点的索引。
class NNneural
{
public:
double output;
vector<NNconnection> m_connection; };
class NNconnection
{
public:
unsigned weightIdx;
unsigned neuralIdx;
};
上面是基本的数据结构,而我们整个算法的核心就在于向前计算与反向传播来更新阈值,也就是函数forwardCalculate()和backPropagate()。
向前传播函数其实比较简单,注意第一层是输入层,它不接受来自其他层的输入,我们只需将它所有结点的输出设置为训练样本的特征即可。而反向传播函数,将最后一层与隐藏层区分开来,因为它们更新权值的法则不同,并且这个工作由每一层的backPropagate()函数来完成。
下面是整个代码中比较重要的几个函数,需要完整代码的可以联系我。
void NeuralNetwork::initializeNetwork()
{
// 初始化网络,主要是创建各层和各层的结点,并给权重向量赋初值
for (vector<NNlayer*>::size_type i = ; i != nLayer; i++)
{
NNlayer* ptrLayer = new NNlayer;
if (i == )
{
ptrLayer->addNeurals(nodes[i],);
}
else
{
ptrLayer->preLayer = m_layers[i - ];
ptrLayer->addNeurals(nodes[i],nodes[i-]);
unsigned num_weights = nodes[i] * (nodes[i-]+); // 有一个是bias
for (vector<double>::size_type k = ; k != num_weights; k++)
{
// 初始化权重在0~0.05
ptrLayer->m_weights.push_back(0.05*rand()/RAND_MAX);
}
}
m_layers.push_back(ptrLayer);
}
}
initializeNetwork
void NNlayer::addNeurals(unsigned num, unsigned preNumNeural)
{
for (vector<NNneural>::size_type i = ; i != num; i++)
{
NNneural sneural;
sneural.output = ;
for (vector<NNconnection>::size_type k = ; k != preNumNeural+; k++)
{
NNconnection sconnection;
sconnection.weightIdx = i*(preNumNeural + ) + k; // 设置权重索引
sconnection.neuralIdx = k; // 设置前层结点索引
sneural.m_connection.push_back(sconnection);
}
m_neurals.push_back(sneural);
}
}
addNeurals
void NeuralNetwork::forwardCalculate(vector<double>& invect, vector<double>& outvect)
{
actualOutput.clear();
vector<NNlayer*>::iterator layerIt = m_layers.begin();
while (layerIt != m_layers.end())
{
if (layerIt == m_layers.begin())
{
// 第一层
for (vector<NNneural>::size_type k = ; k != (*layerIt)->m_neurals.size(); k++)
{
(*layerIt)->m_neurals[k].output = invect[k];
}
}
else
{
vector<NNneural>::iterator neuralIt = (*layerIt)->m_neurals.begin();
int neuralIdx = ;
while (neuralIt != (*layerIt)->m_neurals.end())
{
vector<NNconnection>::size_type num_connection = (*neuralIt).m_connection.size();
double dsum = (*layerIt)->m_weights[num_connection*(neuralIdx + ) - ]; // 先将偏置加上
for (vector<NNconnection>::size_type i = ; i != num_connection - ; i++)
{
// sum=sum of xi*wi
unsigned wgtIndex = (*neuralIt).m_connection[i].weightIdx;
unsigned neuIndex = (*neuralIt).m_connection[i].neuralIdx;
dsum += ((*layerIt)->preLayer->m_neurals[neuIndex].output*(*layerIt)->m_weights[wgtIndex]);
}
neuralIt->output = SIGMOID(dsum);
neuralIdx++;
neuralIt++;
}
}
++layerIt;
}
// 将最后一层的结果传递给输出
NNlayer* lastLayer = m_layers[m_layers.size() - ];
vector<NNneural>::iterator neuralIt = lastLayer->m_neurals.begin();
while (neuralIt != lastLayer->m_neurals.end())
{
outvect.push_back(neuralIt->output);
++neuralIt;
}
}
forwardCalculate
void NeuralNetwork::backPropagate(vector<double>& tVect, vector<double>& oVect)
{
// lit是最后一层的迭代器
vector<NNlayer*>::iterator lit = m_layers.end() - ;
// dErrWrtDxLast是最后一层所有结点的误差
vector<double> dErrWrtDxLast((*lit)->m_neurals.size());
// 所有层的误差
vector<vector<double>> diffVect(nLayer);
for (vector<NNneural>::size_type i = ; i != (*lit)->m_neurals.size();i++)
{
dErrWrtDxLast[i] = oVect[i] - tVect[i];
}
diffVect[nLayer - ] = dErrWrtDxLast;
// 先将其他层的误差都设为0
for (unsigned i = ; i < nLayer - ; i++)
{
diffVect[i].resize(m_layers[i]->m_neurals.size(),0.0);
} vector<NNlayer*>::size_type i = m_layers.size()-;
for (lit; lit>m_layers.begin(); lit--)
{
(*lit)->backPropagate(diffVect[i],diffVect[i-],etaLearningRate);
--i;
}
diffVect.clear();
}
void NNlayer::backPropagate(vector<double>& dErrWrtDxn,vector<double>& dErrWrtDxnm,double eta)
{
double output;
vector<double> dErrWrtDyn(dErrWrtDxn.size());
for (vector<NNneural>::size_type i = ; i != m_neurals.size(); i++)
{
output = m_neurals[i].output;
dErrWrtDyn[i] = DSIGMOID(output)*dErrWrtDxn[i];
}
unsigned ii();
vector<NNneural>::iterator nit = m_neurals.begin();
vector<double> dErrWrtDwn(m_weights.size(),);
while(nit != m_neurals.end())
{
for (vector<NNconnection>::size_type k = ; k != (*nit).m_connection.size(); k++)
{
if (k == (*nit).m_connection.size() - )
output = ;
else
output = preLayer->m_neurals[(*nit).m_connection[k].neuralIdx].output;
dErrWrtDwn[(*nit).m_connection[k].weightIdx] += output*dErrWrtDyn[ii];
} ++nit;
++ii;
}
unsigned j();
nit = m_neurals.begin();
while (nit != m_neurals.end())
{
for (vector<NNconnection>::size_type k = ; k != (*nit).m_connection.size()-; k++)
{
dErrWrtDxnm[(*nit).m_connection[k].neuralIdx] += dErrWrtDyn[j] * m_weights[(*nit).m_connection[k].weightIdx];
}
++j;
++nit;
}
for (vector<double>::size_type i = ; i != m_weights.size(); i++)
{
m_weights[i] -= eta*dErrWrtDwn[i];
}
}
backPropagate
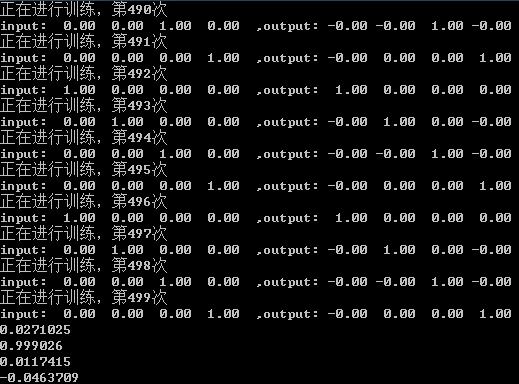
这里我们想起上篇文章中的一个例子,这里我们用多层的网络来再次去拟合那个目标函数,我们用了3层的网络结构,隐藏层设置了20层,而这里我们没有将结果设置为1维,而是用一个4维向量组成也就是与输入向量一致。下面是经过500迭代后产生的结果,并组我们最后以一组[0.01,0.99,0.001,-0.05]这样的输入来测试,我们预期的结果是[0,1,0,0],而程序得到的结果是[0.027,0.999,0.011,-0.046]。
六、结束语
到这里,神经网络的基本结构和最常见的训练法则已经介绍完了,但是神经网络的发展已经有几十年的历史了,期间出现了各种的变种,让神经网络发展为了不同的种类,但它的基本思路都是不变的,正如下一篇文章即将介绍的卷积神经网络。
本文原理部分主要参考Tom M.Mitchell的《机器学习》,而实现部分主要参考了CodeProject中的Neural Network for recognition of handwriting digits这篇文章。感谢你的阅读。
神经网络:多层网络与C++实现的更多相关文章
- 利用神经网络进行网络流量识别——特征提取的方法是(1)直接原始报文提取前24字节,24个报文组成596像素图像CNN识别;或者直接去掉header后payload的前1024字节(2)传输报文的大小分布特征;也有加入时序结合LSTM后的CNN综合模型
国外的文献汇总: <Network Traffic Classification via Neural Networks>使用的是全连接网络,传统机器学习特征工程的技术.top10特征如下 ...
- 简单的RNN和BP多层网络之间的区别
先来个简单的多层网络 RNN的原理和出现的原因,解决什么场景的什么问题 关于RNN出现的原因,RNN详细的原理,已经有很多博文讲解的非常棒了. 如下: http://ai.51cto.com/art/ ...
- 深度学习原理与框架-递归神经网络-RNN网络基本框架(代码?) 1.rnn.LSTMCell(生成单层LSTM) 2.rnn.DropoutWrapper(对rnn进行dropout操作) 3.tf.contrib.rnn.MultiRNNCell(堆叠多层LSTM) 4.mlstm_cell.zero_state(state初始化) 5.mlstm_cell(进行LSTM求解)
问题:LSTM的输出值output和state是否是一样的 1. rnn.LSTMCell(num_hidden, reuse=tf.get_variable_scope().reuse) # 构建 ...
- 用python实现数字图片识别神经网络--启动网络的自我训练流程,展示网络数字图片识别效果
上一节,我们完成了网络训练代码的实现,还有一些问题需要做进一步的确认.网络的最终目标是,输入一张手写数字图片后,网络输出该图片对应的数字.由于网络需要从0到9一共十个数字中挑选出一个,于是我们的网络最 ...
- My blog in AI ---神经网络,网络架构
上一篇博文中,我们介绍了神经网络中的神经元,那么该如何组织起来这些神经元,才能发挥出最好的效果去解决现实中的问题呢? 这是一个复杂的问题,在工程中,神经网络的架构也是训练的也是一种超参数,本节先在理论 ...
- 反馈神经网络Hopfield网络
一.前言 经过一段时间的积累,对于神经网络,已经基本掌握了感知器.BP算法及其改进.AdaLine等最为简单和基础的前馈型神经网络知识,下面开启的是基于反馈型的神经网络Hopfiled神经网络.前馈型 ...
- Task4.用PyTorch实现多层网络
1.引入模块,读取数据 2.构建计算图(构建网络模型) 3.损失函数与优化器 4.开始训练模型 5.对训练的模型预测结果进行评估 import torch.nn.functional as F im ...
- 多层神经网络BP算法 原理及推导
首先什么是人工神经网络?简单来说就是将单个感知器作为一个神经网络节点,然后用此类节点组成一个层次网络结构,我们称此网络即为人工神经网络(本人自己的理解).当网络的层次大于等于3层(输入层+隐藏层(大于 ...
- 【MLP】多层感知机网络
BPN(Back Propagation Net) 反向传播神经网络是对非线性可微分函数进行权值训练的多层网络,是前向神经网络的一种. BP网络主要用于: 1)函数逼近与预测分析:用输入矢量和相应的输 ...
随机推荐
- Visual Studio Online Integrations-Productivity
原文:http://www.visualstudio.com/zh-cn/explore/vso-integrations-di ...
- input file美化
<style> a{display:inline-block; width:100px; height:40px; position:relative; overflow:hidden;} ...
- Android内核开发:系统启动速度优化-Android OS启动优化(转)
Android系统的启动优化主要分为三大部分: (1) Bootloader优化 (2) Linux Kernel的剪裁与优化 (3) Android OS部分的剪裁与优化 本文重点关注Android ...
- R语言的前世今生(转)
最近因病休养在家,另外也算是正式的离开Snack Studio.终于有了大把可以自由支配的时间.可以自主的安排.最近闲暇的时间总算是恶补了不少前段时间行业没有时间关注的新事物.看着行业里引领潮流的东西 ...
- 转<<C#集合Dictionary中按值的降序排列
转载地址:http://blog.sina.com.cn/s/blog_5c5bc9070100pped.html C#集合Dictionary中按值的降序排列 static void Main(st ...
- 360双击ctrl搜索可能会与firefox快捷键冲突
最近使用火狐浏览器时有好几次要在网页上的对话框输入文字时出现问题,按下字母键直接跳出了firefox菜单选项,用鼠标重新定位到输入位置再打还是不行,照样会弹出菜单提示,如下图,这可能是有什么快捷键冲突 ...
- zstu.4014.水手分椰子(数学推导)
深入浅出学算法015-水手分椰子 Time Limit: 5 Sec Memory Limit: 64 MB Submit: 1827 Solved: 524 Description n个水手来到 ...
- [Effective JavaScript 笔记]第59条:避免过度的强制转换
js是弱类型语言.许多标准的操作符和代码库会把输入参数强制转换为期望的类型而不是抛出错误.如果未提供额外的逻辑,使用内置操作符的程序会继承这样的强制转换行为. functin square(x){ r ...
- php友好格式化时间
php格式化时间显示 function toTime($time) {//$time必须为时间戳 $rtime = date("Y-m-d H:i",$time); $htime ...
- poj 1664
http://poj.org/problem?id=1664 题目是中文的,一个递归的题目 把每一次的苹果分为两类 Ⅰ:所以盘子都放一个,然后其他的在随便放: Ⅱ:有一个盘子没有放苹果: 这样下去的话 ...