Mysql中的分库分表
mysql中的分库分表
分库:减少并发问题
分表:降低了分布式事务
分表
1、垂直分表
把其中的不常用的基础信息提取出来,放到一个表中通过id进行关联。降低表的大小来控制性能,但是这种方式没有解决高数据量带来的性能损耗。
优点
1、拆分后业务清楚,达到专库专用。
2、可以实现热数据和冷数据的分离,将不经常变化的数据和变动较大的数据分散到不同的
库/表里面。
3、便于维护。
缺点
1、不能解决数据量大带来的性能损耗,读写的压力依旧很大。
2、不同的业务不能夸库关联,只能通过业务关联。
2、水平分表
以某个字段按照一定的规则将一个表数据分到多个表中
优点
1、单表的数据量减少了,提高性能。
2、提高了系统的稳定性和负载能力。
3、切分出来的表结构相同,程序改动的少。
缺点
1、拆分规则较难抽象。
2、数据分片在扩容是需要迁移
3、维护量增大
4、依然存在跨库无法join等问题,同时涉及分布式事物,数据一致性问题。
分库策略
hash取模 通过一个表中的字段进行散列
range 范围区分 (比如:时间,地区....)
list 预定义 (步长区分
分库分表需要解决的问题
1、事物问题
解决事物问题有两种可行的规方案分布式事物和通过应用程序与数据库共同控制实现
1、使用分布式事物
优点:交给数据库管理,简单有效
缺点:性能代价高,特别是shard越来越多时
2、应用程序和数据库共同控制
原理:将一个跨多个数据库的分布式事物分拆成多个仅处于单个数据上面的小事物,并通过
应用程序来总控各个小事物。
优点:性能上有优势。
缺点:需要应用程序在事物控制上做灵活的设计。
2、跨节点JOIN问题
只要进行切分,跨节点JOIN是不可避免的。解决这一问题的普遍做法两次查询实现。在第一次查询的结果集中找出关联数据的ID,根据这些ID发起第二次请求得到关联的数据。
3、跨界店的count.order by,group by聚合函数的问题
这是一类问题,因为他们都需要基于全部数据集进行计算。解决方案:与跨界店IOIN问题类似,分别在各个节点得到结果后再用用程序端进行合并。和JOIN不同的是每个节点的查询可以并行执行,因此很多时候它的速度比单一大表快很多。结果集很大,对应用程序的内存消耗是一个问题。
4、数据迁移,容量规划,扩容等问题
来自淘宝综合业务平台团队,它利用对2的倍数取余具有向前兼容的特性(如对4取余得1的数对2取余也是1)来分配数据,避免了行级别数据的迁移,但是依然需要进行表级别的迁移,同时对于扩容规模和分别数量都有限制。总体上,这些方案都不是十分的理想,多多少少存在一些缺点,同时反映了Sharding扩容的难度。
5、事物
优点
1、基于两阶段提交,最大限度保证跨库数据库操作的“原子性”,是分布式系统下最严谨的事物实现方式。
2、实现简单,工作量小。由于多数应用服务器以及一些独立的分布式事物协调器做出了大量的封装工作,使得项目引入分布式事物的难度和工作量基本上可以忽略不计。
缺点
系统伸缩的死敌。基于两阶段提交的分布式事物在提交事物时需要进行多个节点之间的协调,最大限度的退后了事物的时间点,客观上延迟了事物的执行时间,会导致事物访问共享资源时发生冲突和死锁的概率增高,随着数据库节点的增加,这种趋势会越来越严重,从而成为系统在数据层面上水平伸缩的“枷锁”。
事物补偿(幂等值)
对那些对性能要求很高,但对一致性要求并不高的系统。往往并不苟求系统的实时一致性,只要在一个允许的时间周期内达到最终一致性即可,这使得事物补偿机制成为一种方案。事物补偿机制最初被提出是在“长事物”的处理中,单对于分布式系统确保一致性很有很好的参考意义。笼统的讲,与事物在执行过程中发生错误立即回滚的方式不同,事物补偿性是一种事后检查并补救的措施,它只期望在一个容许的时间周期内得到最终一致的结果就可以了。事物补偿是实现与系统业务紧密相关,并没有一种标准的处理方案。一些常见的实现方式:对数据进行对账检查,基于日志进行对比,定期同标准数据来源进行同步。。。
6、ID问题
一旦数据被切分到多个物理节点上,我么将不再依赖数据库自身的主键生成机制。一方面,每个分区数据库生成的ID无法保证在全局上是唯一的;另一方面,应用程序在插入数据之前需要获取ID,以便SQL路由。
UUID
使用UUID作为主键是最简单的方案,但是缺点也是非常明显的。由于UUID非常的长,除占用大量的存储空间,最主要的问题在索引上,在建立索引和基于索引进行查询时存在性能
问题。
结合数据库维护一个Sequence表此方案简单,在数据库中建立一个Sequence表
CREATE TABLE `SEQUENCE` (
`table_name` varchar(18) NOT NULL,
`nextid` bigint(20) NOT NULL,
PRIMARY KEY (`table_name`)
) ENGINE=InnoDB
每当需要为某个表新纪录生成ID是就从Sequence表中取出对应表的nextid,并将nextid的值加1更新到数据库中一以备下次使用。此方法简单,但是缺点明显,由于所有插入任何都需要访问该表,该表很容易成为系统的性能瓶颈,同时也存在单点的问题,一旦还数据库失效,整个应用程序将无法工作。有人提出用Master-Slave进行主从同步,但是也只能解决单点问题,并不能解决读写1:1的访问压力问题。Twitter的分布式自增ID算法Snowflake在分布式系统中吗,需要生成全局的UID的场合还是蛮多的,twitter的snowfake解决了这种需要,实现也是很简单的,除去配置信息,核心代码就是毫秒级时间41位 机器ID 10位毫秒内序列12位。
* 10---0000000000 0000000000 0000000000 0000000000 0 --- 00000 ---00000 --
-000000000000
在上面的字符串中,第一位为未使用(实际上也可作为long的符号位),接下来的41位为毫秒级时间,然后5位datacenter标识位,5位机器ID(并不算标识符,实际是为线程标识),然后12位该毫秒内的当前毫秒内的计数,加起来刚好64位,为一个Long型。这样的好处是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和机器ID作区分),并且效率较高,经测试,snowflake每秒能够产生26万ID左右,完全满足需要。
7、跨分片的排序分页
一般来说,分页的时候需要按照指定的字段进行排序。当排序字段就是分片字段的时候,我们通过分片规则可以较为容易的定位到指定的分片,而当排序字段非分片字段的时候,情况就复杂了。为了结果的准确性,我们需要在不通的分片节点将数据进行排序并返回,将不通分片返回的结果集进行汇总和再次排序。最后返回给用户。
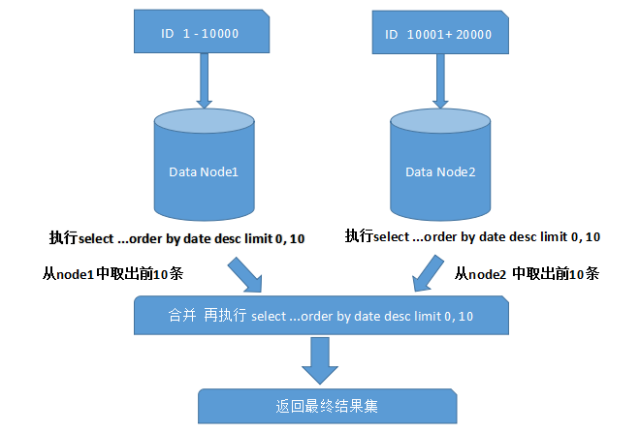
上面描述的是最简单的一种情况(去第一页的数据),看起来对性能的影响不大。但是,如果取出第10页数据,情况就复杂很多了。

为什么不取10条,而是把前10页的数据全部取出来了呢?其实也不难理解,因为个节点的数据可能是随机的,为了排序的准确性,必须把所有分片节点前的前N也数据都拍好序后做合并,最终进行整体的排序。很显然这样的操作是很消耗性能的,用户越往后翻,性能就会越差。
那么如何解决呢?
1、如果是前台提供分页。则限定用户只能看前面n页,这个限定在业务上也是合情合理的,一般看后面的分页的意义不大(如果一定要看,可以要求用户缩小范围重新查询)
2、如果是后台批处理任务要求分批获取数据,则可以加大page size,比如每次获取5000条记录,有效减少分页(当然离线访问一般走备库,避免冲击主库)
3、可以借助大数据平台
8、分库策略
分库维度确定后,如何把记录分到各个库中呢
1、根据数值范围,比如ID为1-9999到第一个库,10000-20000的到第二个库
2、根据数值取模,比如ID mod n,余数为0的记录到第一个库中,为1的记录到第二个库中。
9、分库数量
分库数量首先和单库处理的记录数有关,一般来说MySQL单库超过5000万条记录,Oracle超过1亿条记录,DB压力就很大(当然还跟数据表中记录有关系)在满足上述前提下,如果分库的数量少了,达不到分散存储和减轻DB性能压力的目的;果分库的数量多,好处是每个库的记录少,单库访问性能好,但对于跨多个库的访问,应用如程序需要访问多个库,如果并发模式,要消耗宝贵的线程资源;如果串行模式,执行时间会急剧增加。分库的数量影响硬件的投入,一般每个分库泡在单独的物理机上面,多一个意味着多一台设备。一般建议分4-8个库。
10、路由透明
分库从某种意义上,意味着DB schema改变了,必然影响应用,但这种改变和业务无关,所以要尽量保证分库对应用代码透明,分库逻辑尽量在数据访问层处理。当然完全做到这一点很困难,具体哪些应该由DAL负责,哪些由应用负责,这里有一些建议:对于单库访问,比如查询条件指定用户Id,则该SQL只需访问特定库。此时应该由DAL层自动路由到特定库,当库二次分裂时,也只要修改mod 因子,应用代码不受影响。
对于简单的多库查询,DAL负责汇总各个数据库返回的记录,此时仍对上层应用透明。
Mysql中的分库分表的更多相关文章
- MySQL纯透明的分库分表技术还没有
MySQL纯透明的分库分表技术还没有 种树人./oneproxy --proxy-address=:3307 --admin-username=admin --admin-password=D033 ...
- Mycat安装并实现mysql读写分离,分库分表
Mycat安装并实现mysql读写分离,分库分表 一.安装Mycat 1.1 创建文件夹 1.2 下载 二.mycat具体配置 2.1 server.xml 2.2 schema.xml 2.3 se ...
- Docker安装Mycat并实现mysql读写分离,分库分表
Docker安装Mycat并实现mysql读写分离,分库分表 一.拉取mycat镜像 二.准备挂载的配置文件 2.1 创建文件夹并添加配置文件 2.1.1 server.xml 2.1.2 serve ...
- MYSQL性能优化--分库分表
1.分库分表 1>纵向分表 将本来可以在同一个表的内容,人为划分为多个表.(所谓的本来,是指按照关系型数据库的第三范式要求,是应该在同一个表的.) 分表理由:根据数据的活跃度进行分离,(因为不同 ...
- mysql、oracle分库分表方案之sharding-jdbc使用(非demo示例)
选择开源核心组件的一个非常重要的考虑通常是社区活跃性,一旦项目团队无法进行自己后续维护和扩展的情况下更是如此. 至于为什么选择sharding-jdbc而不是Mycat,可以参考知乎讨论帖子https ...
- mysql为什么要分库分表?
1 基本思想之什么是分库分表?从字面上简单理解,就是把原本存储于一个库的数据分块存储到多个库上,把原本存储于一个表的数据分块存储到多个表上. 2 基本思想之为什么要分库分表? 单表操作数据量有最优值, ...
- mycat+ mysql集群 分库分表
mycat介绍Mycat数据库分库分表中间件国内最活跃的.性能最好的开源数据库中间件!Mycat关键特性关键特性支持SQL92标准支持MySQL.Oracle.DB2.SQL Server.Postg ...
- 分布式中的分库分表之后,ID 主键如何处理?
面试题 分库分表之后,id 主键如何处理?(唯一性,排序等) 面试官心理分析 其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 开始累加,那肯定 ...
- 实现对MySQL数据库进行分库/分表备份(shell脚本)
工作中,往往数据库备份是件非常重要的事情,毕竟数据就是金钱,就是生命!废话不多,下面介绍一下:如何实现对MySQL数据库进行分库备份(shell脚本) Mysq数据库dump备份/还原语法: mysq ...
随机推荐
- python基础--深浅拷贝copy
拷贝是音译的词,其实他是从copy这个英文单词音译过来的,那什么是copy? copy其实就是复制一份,也就是所谓的抄一份.深浅copy其实就是完全复制一份,和部分复制一份的意思. 1.赋值运算 l1 ...
- javaweb_HTML
第一章:网页的构成 1.1概念:b/s与c/s 1.1.1 现在的软件开发的整体架构主要分为B/S架构与C/S架构: b/s:浏览器/服务器 c/s:客户端/服务器 客户端:需要安装在系统里,才可使用 ...
- Python Django撸个WebSSH操作Kubernetes Pod(下)- 终端窗口自适应Resize
追求完美不服输的我,一直在与各种问题斗争的路上痛并快乐着 上一篇文章Django实现WebSSH操作Kubernetes Pod最后留了个问题没有解决,那就是terminal内容窗口的大小没有办法调整 ...
- Jupyter的安装和基本使用
1. 安装Jupyter pip install jupyter 2. Jupyter的初次使用 # 进入虚拟环境 workon ai # 输入命令 jupyter notebook 本地notebo ...
- MySQL datetime类型详解
研发反馈问题,数据库中datetime数据类型存储的值末尾会因四舍五入出现不一致数据,影响查询结果,比如:程序中自动获取带毫秒精度的日期'2019-03-05 01:53:55.63',存入数据库后变 ...
- javascript正则表达式入门先了解这些
前言 此内容由学习<JavaScript正则表达式迷你书(1.1版)>整理而来(于2020年3月30日看完).此外还参考了MDN上关于Regex和String的相关内容,还有ECMAScr ...
- HDU-1051 一个DP问题
Problem Description There is a pile of n wooden sticks. The length and weight of each stick are know ...
- 阿里云ECS(Ubuntu)单节点Kubernetes部署
参考资料: kubernetes官网英文版 kubernetes官网中文版 前言 这篇文章是比较久之前写的了,无聊翻了下博客发现好几篇博文排版莫名其妙的变了... 于是修改并完善了下.当初刚玩k8s的 ...
- 从零开始发布一个ArcGIS Server地图服务
@ 目录 一.软件环境搭建 1.数据库安装 1.1.Oracle(可选) 1.1.1.安装Oracle服务端 1.1.2.安装Oracle客户端 1.2.PostgreSQL(可选) 1.2.1.安装 ...
- Consul+upsync+Nginx 动态负载均衡
1,动态负载均衡 传统的负载均衡,如果修改了nginx.conf 的配置,必须需要重启nginx 服务,效率不高.动态负载均衡,就是可配置化,动态化的去配置负载均衡. 2,实现方案 1. Consul ...