分布式事务专题笔记(一) 基础概念 与 CAP 理论
个人博客网:https://wushaopei.github.io/ (你想要这里多有)
一、基础概念
1、什么是事务
2、本地事务
3、分布式事务


begin transaction;
//1.本地数据库操作:张三减少金额
//2.本地数据库操作:李四增加金额
commit transation;
begin transaction;
//1.本地数据库操作:张三减少金额
//2.远程调用:让李四增加金额
commit transation;
4、分布式事务产生的场景
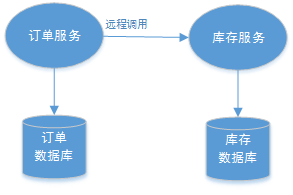
4.3 、多服务访问同一个数据库实例 比如:订单微服务和库存微服务即使访问同一个数据库也会产生分布式事务,原因就是跨JVM进程,两个微服务持有了不同的数据库链接进行数据库操作,此时产生分布式事务。

二、 分布式事务基础理论
1、CAP理论
1.1 理解CAP
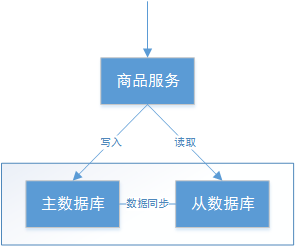
- 商品服务请求主数据库写入商品信息(添加商品、修改商品、删除商品)
- 主数据库向商品服务响应写入成功。
- 商品服务请求从数据库读取商品信息。
一致性是指写操作后的读操作可以读取到最新的数据状态,当数据分布在多个节点上,从任意结点读取到的数据都
- 商品服务写入主数据库成功,则向从数据库查询新数据也成功。
- 商品服务写入主数据库失败,则向从数据库查询新数据也失败。
- 写入主数据库后要将数据同步到从数据库。
- 写入主数据库后,在向从数据库同步期间要将从数据库锁定,待同步完成后再释放锁,以免在新数据写入成功 后,向从数据库查询到旧的数据。
- 由于存在数据同步的过程,写操作的响应会有一定的延迟。
- 为了保证数据一致性会对资源暂时锁定,待数据同步完成释放锁定资源。
- 如果请求数据同步失败的结点则会返回错误信息,一定不会返回旧数据。
可用性是指任何事务操作都可以得到响应结果,且不会出现响应超时或响应错误。
- 从数据库接收到数据查询的请求则立即能够响应数据查询结果。
- 从数据库不允许出现响应超时或响应错误。
- 写入主数据库后要将数据同步到从数据库。
- 由于要保证从数据库的可用性,不可将从数据库中的资源进行锁定。
- 即时数据还没有同步过来,从数据库也要返回要查询的数据,哪怕是旧数据,如果连旧数据也没有则可以按照 约定返回一个默认信息,但不能返回错误或响应超时。
- 所有请求都有响应,且不会出现响应超时或响应错误。
通常分布式系统的各各结点部署在不同的子网,这就是网络分区,不可避免的会出现由于网络问题而导致结点之间通信失败,此时仍可对外提供服务,这叫分区容忍性。
- 主数据库向从数据库同步数据失败不影响读写操作。
- 其一个结点挂掉不影响另一个结点对外提供服务。
- 尽量使用异步取代同步操作,例如使用异步方式将数据从主数据库同步到从数据库,这样结点之间能有效的实现松耦合。
- 添加从数据库结点,其中一个从结点挂掉其它从结点提供服务。
- 分区容忍性分是分布式系统具备的基本能力。
2、CAP组合方式
在所有分布式事务场景中不会同时具备CAP三个特性,因为在具备了P的前提下C和A是不能共存的。
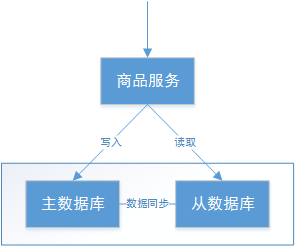
所以在生产中对分布式事务处理时要根据需求来确定满足CAP的哪两个方面。
放弃一致性,追求分区容忍性和可用性。这是很多分布式系统设计时的选择。
放弃可用性,追求一致性和分区容错性,我们的zookeeper其实就是追求的强一致,又比如跨行转账,一次转账请求要等待双方银行系统都完成整个事务才算完成。
放弃分区容忍性,即不进行分区,不考虑由于网络不通或结点挂掉的问题,则可以实现一致性和可用性。那么系统将不是一个标准的分布式系统,我们最常用的关系型数据库就满足了CA。
2、BASE 理论
CAP理论告诉我们一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容忍性(Partition tolerance)这三项中的两项,其中AP在实际应用中较多,AP即舍弃一致性,保证可用性和分区容忍性,但是在实际生产中很多场景都要实现一致性,比如前边我们举的例子主数据库向从数据库同步数据,即使不要一致性,但是最终也要将数据同步成功来保证数据一致,这种一致性和CAP中的一致性不同,CAP中的一致性要求在任何时间查询每个结点数据都必须一致,它强调的是强一致性,但是最终一致性是允许可以在一段时间内每个结点的数据不一致,但是经过一段时间每个结点的数据必须一致,它强调的是最终数据的一致性。
2.2 Base 理论介绍
BASE 是 Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent (最终一致性)三个短语的缩写。BASE理论是对CAP中AP的一个扩展,通过牺牲强一致性来获得可用性,当出现故障允许部分不可用但要保证核心功能可用,允许数据在一段时间内是不一致的,但最终达到一致状态。满足BASE理论的事务,我们称之为“柔性事务”。
- 基本可用:分布式系统在出现故障时,允许损失部分可用功能,保证核心功能可用。如,电商网站交易付款出现问题了,商品依然可以正常浏览。
- 软状态:由于不要求强一致性,所以BASE允许系统中存在中间状态(也叫软状态),这个状态不影响系统可用性,如订单的"支付中"、“数据同步中”等状态,待数据最终一致后状态改为“成功”状态。
- 最终一致:最终一致是指经过一段时间后,所有节点数据都将会达到一致。如订单的"支付中"状态,最终会变为“支付成功”或者"支付失败",使订单状态与实际交易结果达成一致,但需要一定时间的延迟、等待。
分布式事务专题笔记(一) 基础概念 与 CAP 理论的更多相关文章
- 分布式事务专题笔记(三)分布式事务解决方案之TCC(三阶段提交)
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 1.什么是TCC事务 TCC是Try.Confifirm.Cancel三个词语的缩写,TCC要求每个分支 ...
- 分布式事务专题笔记(二)分布式事务解决方案之 2PC(两阶段提交)
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 前面已经了解了分布式事务的基础理论,以理论为基础,针对不同的分布式场景业界常见的解决方案有2PC.TCC ...
- spring分布式事务学习笔记
最近项目中使用了分布式事务,本文及接下来两篇文章总结一下在项目中学到的知识. 分布式事务对性能有一定的影响,所以不是最佳的解决方案,能通过设计避免最好尽量避免. 分布式事务(Distributed t ...
- Elasticserach学习笔记-01基础概念
本文系本人根据官方文档的翻译,能力有限.水平一般,如果对想学习Elasticsearch的朋友有帮助,将是本人的莫大荣幸. 原文出处:https://www.elastic.co/guide/en/e ...
- spring分布式事务学习笔记(1)
此文已由作者夏昀授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 分布式事务对性能有一定的影响,所以不是最佳的解决方案,能通过设计避免最好尽量避免. 分布式事务(Distrib ...
- 【miscellaneous】 GStreamer应用开发手册学习笔记之基础概念介绍
第3章. 基础概念介绍 本章将介绍GStreamer的基本概念. 理解这些概念对于你后续的学习非常重要,因为后续深入的讲解我们都假定你已经完全理解了这些概念. 3.1. 元件(Elements) 元件 ...
- Docker:学习笔记(1)——基础概念
Docker:学习笔记(1)——基础概念 Docker是什么 软件开发后,我们需要在测试电脑.客户电脑.服务器安装运行,用户计算机的环境各不相同,所以需要进行各自的环境配置,耗时耗力.为了解决这个问题 ...
- [Computational Advertising] 计算广告学笔记之基础概念
因为工作需要,最近一直在关注计算广告学的内容.作为一个新手,学习计算广告学还是建议先看一下刘鹏老师在师徒网的教程<计算广告学>. 有关刘鹏老师的个人介绍:刘鹏现任360商业产品首席架构师, ...
- OpenFlow Switch学习笔记(一)——基础概念
OpenFlow Switch v1.4.0规范是在2013年10月14号发布,规范涵盖了OpenFlow Switch各个组件的功能定义.Controller与Switch之间的通信协议Open F ...
随机推荐
- leetCode刷题 | 两数相加
给出两个 非空 的链表用来表示两个非负的整数.其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字. 如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和 ...
- 201771030125-王英雪 实验一 软件工程准备一<构建之法与博客首秀>
项目 内容 班级博客 点我呀! 作业要求 看这里! 课程学习目标 提出三个问题并以写博客的形式记录下来 参考文献 现代软件工程讲义 三个问题 问题一:软件工程究竟是什么? 在现代软件工程讲义一书中给出 ...
- matlab读取csv文件并显示
传统的方式可以通过读取文件,然后处理字符串的方式对csv文件进行解析,在matlab中可以通过csvread函数读取csv文件,然后通过plot对数据进行显示,也可以对里面的函数进行分析: csv文件 ...
- ubuntu上lib-ace库安装编译
描述下本人电脑情况: 虚拟机版本:VMware-workstation-full-v7.1.4: ACE版本:ACE6.0.0 虚拟机[Linux](http://lib.csdn.net/base/ ...
- Spring方法注入的使用与实现原理
一.前言 这几天为了更详细地了解Spring,我开始阅读Spring的官方文档.说实话,之前很少阅读官方文档,就算是读,也是读别人翻译好的.但是最近由于准备春招,需要了解很多知识点的细节,网上几乎 ...
- Selenium + Python + Chrome 自动化测试 环境搭建
一.下载Python 相关的教程很多,此处不详细记录了,下面是官网下载地址: https://www.python.org/downloads/ 我使用的python版本为 Python 3.6.1 ...
- about VennsBlog.
此博客主要将用于记录自己学习路上的一些点滴及心得 同时,也希望各位提出指正 相互交流,共同进步 感谢相遇
- 简单的Java实现Netty进行通信
使用Java搭建一个简单的Netty通信例子 看过dubbo源码的同学应该都清楚,使用dubbo协议的底层通信是使用的netty进行交互,而最近看了dubbo的Netty部分后,自己写了个简单的Net ...
- android LoaderManger加载数据Tip
要查看LoaderManager的具体介绍请看博客: LoaderManager介绍 使用时发现不管怎么调用getLoaderManager().restartLoader(LOADER_TYPE_Q ...
- 「雕爷学编程」Arduino动手做(21)——激光开关模块
37款传感器与模块的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止37种的.鉴于本人手头积累了一些传感器和模块,依照实践出真知(一定要动手做)的理念,以学习和交流为目的,这里 ...