MySQL表连接原理
以下文章均来自掘金小测:
https://juejin.im/book/5bffcbc9f265da614b11b731/section/5c061b0cf265da612577e0f4
表连接本质:把各个连接表中的记录都取出来依次匹配的组合加入结果集并返回给用户.
举例:
mysql> CREATE TABLE t1 (m1 int, n1 char(1));
Query OK, 0 rows affected (0.02 sec) mysql> CREATE TABLE t2 (m2 int, n2 char(1));
Query OK, 0 rows affected (0.02 sec) mysql> INSERT INTO t1 VALUES(1, 'a'), (2, 'b'), (3, 'c');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0 mysql> INSERT INTO t2 VALUES(2, 'b'), (3, 'c'), (4, 'd');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0 (admin@g1-db-test-v07:5001)[jinhailan]>select * from t1;
+------+------+
| m1 | n1 |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
+------+------+
3 rows in set (0.00 sec) (admin@g1-db-test-v07:5001)[jinhailan]>select * from t2;
+------+------+
| m2 | n2 |
+------+------+
| 2 | b |
| 3 | c |
| 4 | d |
+------+------+
3 rows in set (0.00 sec)
t1和t2连接过程:
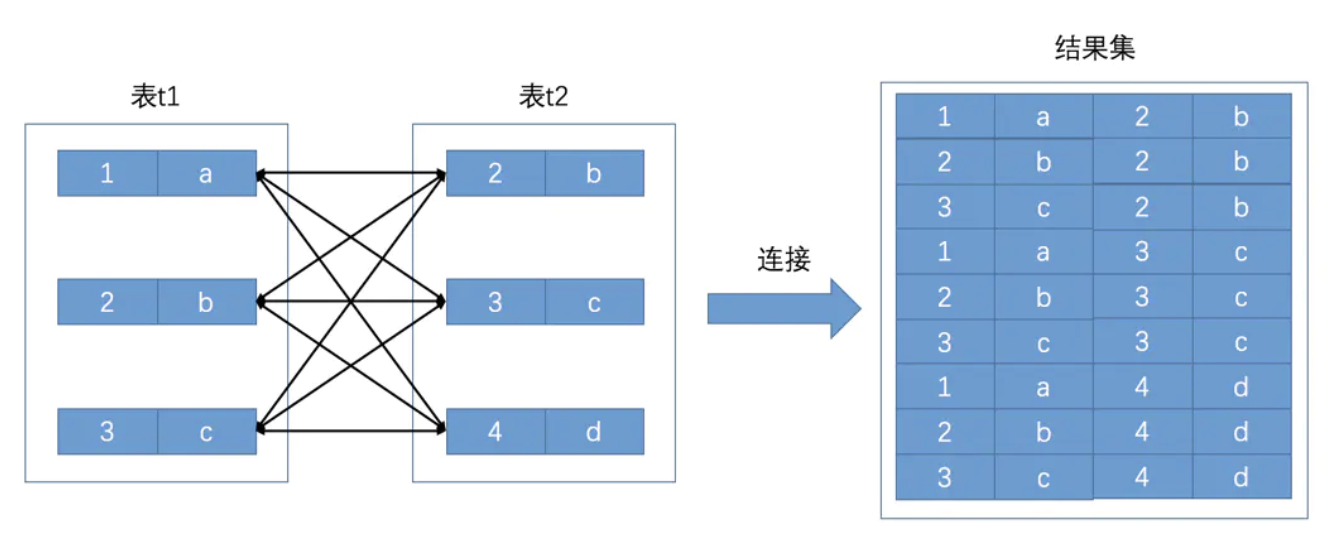
连接查询的结果集中包含一个表中的每一条记录与另一个表中的每一条记录相互匹配的组合,像这样的结果集就可以称之为笛卡尔积
t1和t2表连接查询如下:
(admin@g1-db-test-v07:5001)[jinhailan]>select * from t1,t2;
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 1 | a | 2 | b |
| 2 | b | 2 | b |
| 3 | c | 2 | b |
| 1 | a | 3 | c |
| 2 | b | 3 | c |
| 3 | c | 3 | c |
| 1 | a | 4 | d |
| 2 | b | 4 | d |
| 3 | c | 4 | d |
+------+------+------+------+
9 rows in set (0.00 sec)
表连接过程
没有限制的表连接产生笛卡尔积,结果集是非常巨大的,所以在连接的时候过滤掉特定记录组合是有必要的.
连接查询中,过滤条件可以分为两种:
1.涉及单表的条件:
也一直称为搜索条件,比如t1.m1 > 1是只针对t1表的过滤条件,t2.n2 < 'd'是只针对t2表的过滤条件。
2.涉及两表的条件
比如t1.m1 = t2.m2、t1.n1 > t2.n2等,这些条件中涉及到了两个表.
看以下例子
SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd';
在这个查询中我们指明了这三个过滤条件:
t1.m1 > 1t1.m1 = t2.m2t2.n2 < 'd'
整个过程如下:

1.首先确定第一个需要查询的表,这个表称之为驱动表。怎样在单表中执行查询语句我们在前一章都唠叨过了,只需要选取代价最小的那种访问方法去执行单表查询语句就好了(就是说从const、ref、ref_or_null、range、index、all这些执行方法中选取代价最小的去执行查询)。此处假设使用t1作为驱动表,那么就需要到t1表中找满足t1.m1 > 1的记录,因为表中的数据太少,我们也没在表上建立二级索引,所以此处查询t1表的访问方法就设定为all吧,也就是采用全表扫描的方式执行单表查询。
2.
针对上一步骤中从驱动表产生的结果集中的每一条记录,分别需要到t2表中查找匹配的记录,所谓匹配的记录,指的是符合过滤条件的记录。因为是根据t1表中的记录去找t2表中的记录,所以t2表也可以被称之为被驱动表。上一步骤从驱动表中得到了2条记录,所以需要查询2次t2表。此时涉及两个表的列的过滤条件t1.m1 = t2.m2就派上用场了:
当
t1.m1 = 2时,过滤条件t1.m1 = t2.m2就相当于t2.m2 = 2,所以此时t2表相当于有了t2.m2 = 2、t2.n2 < 'd'这两个过滤条件,然后到t2表中执行单表查询。当
t1.m1 = 3时,过滤条件t1.m1 = t2.m2就相当于t2.m2 = 3,所以此时t2表相当于有了t2.m2 = 3、t2.n2 < 'd'这两个过滤条件,然后到t2表中执行单表查询。
最后结果:
(admin@g1-db-test-v07:5001)[jinhailan]>SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd';
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 2 | b | 2 | b |
| 3 | c | 3 | c |
+------+------+------+------+
2 rows in set (0.00 sec)
从上边两个步骤可以看出来,我们上边唠叨的这个两表连接查询共需要查询1次t1表,2次t2表。当然这是在特定的过滤条件下的结果,如果我们把t1.m1 > 1这个条件去掉,那么从t1表中查出的记录就有3条,就需要查询3次t2表了。也就是说在两表连接查询中,驱动表只需要访问一次,被驱动表可能被访问多次。
内连接和外连接
例子
(admin@g1-db-test-v07:5001)[jinhailan]>CREATE TABLE student (
-> number INT NOT NULL AUTO_INCREMENT COMMENT '学号',
-> name VARCHAR(5) COMMENT '姓名',
-> major VARCHAR(30) COMMENT '专业',
-> PRIMARY KEY (number)
-> ) Engine=InnoDB CHARSET=utf8 COMMENT '学生信息表'; CREATE TABLE score (
number INT COMMENT '学号',Query OK, 0 rows affected (0.15 sec) (admin@g1-db-test-v07:5001)[jinhailan]>
(admin@g1-db-test-v07:5001)[jinhailan]>CREATE TABLE score (
-> number INT COMMENT '学号',
-> subject VARCHAR(30) COMMENT '科目',
-> score TINYINT COMMENT '成绩',
-> PRIMARY KEY (number, subject)
-> ) Engine=InnoDB CHARSET=utf8 COMMENT '学生成绩表';
Query OK, 0 rows affected (0.11 sec) (admin@g1-db-test-v07:5001)[jinhailan]>insert into student values(20180101,'杜子腾','软件学院');
Query OK, 1 row affected (0.05 sec) (admin@g1-db-test-v07:5001)[jinhailan]>insert into student values(20180102,'范统','计算机科学与工程');
Query OK, 1 row affected (0.03 sec) (admin@g1-db-test-v07:5001)[jinhailan]>insert into student values(20180103,'史珍香','计算机科学与工程');
Query OK, 1 row affected (0.05 sec) (admin@g1-db-test-v07:5001)[jinhailan]>insert into score values(20180101,'母猪的产后护理',78);
Query OK, 1 row affected (0.01 sec) (admin@g1-db-test-v07:5001)[jinhailan]>insert into score values(20180101,'萨达姆的战争准备',88);
Query OK, 1 row affected (0.05 sec) (admin@g1-db-test-v07:5001)[jinhailan]>insert into score values(20180102,'萨达姆的战争准备',100);
Query OK, 1 row affected (0.01 sec) (admin@g1-db-test-v07:5001)[jinhailan]>insert into score values(20180102,'母猪的产后护理',98);
Query OK, 1 row affected (0.07 sec) (admin@g1-db-test-v07:5001)[jinhailan]> SELECT * FROM student;
+----------+-----------+--------------------------+
| number | name | major |
+----------+-----------+--------------------------+
| 20180101 | 杜子腾 | 软件学院 |
| 20180102 | 范统 | 计算机科学与工程 |
| 20180103 | 史珍香 | 计算机科学与工程 |
+----------+-----------+--------------------------+
3 rows in set (0.00 sec) (admin@g1-db-test-v07:5001)[jinhailan]>SELECT * FROM score;
+----------+--------------------------+-------+
| number | subject | score |
+----------+--------------------------+-------+
| 20180101 | 母猪的产后护理 | 78 |
| 20180101 | 萨达姆的战争准备 | 88 |
| 20180102 | 母猪的产后护理 | 98 |
| 20180102 | 萨达姆的战争准备 | 100 |
+----------+--------------------------+-------+
4 rows in set (0.00 sec)
想查每个学生的成绩,根据学号做关联
(admin@g1-db-test-v07:5001)[jinhailan]>SELECT * FROM student, score WHERE student.number = score.number;
+----------+-----------+--------------------------+----------+--------------------------+-------+
| number | name | major | number | subject | score |
+----------+-----------+--------------------------+----------+--------------------------+-------+
| 20180101 | 杜子腾 | 软件学院 | 20180101 | 母猪的产后护理 | 78 |
| 20180101 | 杜子腾 | 软件学院 | 20180101 | 萨达姆的战争准备 | 88 |
| 20180102 | 范统 | 计算机科学与工程 | 20180102 | 母猪的产后护理 | 98 |
| 20180102 | 范统 | 计算机科学与工程 | 20180102 | 萨达姆的战争准备 | 100 |
+----------+-----------+--------------------------+----------+--------------------------+-------+
4 rows in set (0.05 sec) (admin@g1-db-test-v07:5001)[jinhailan]>SELECT s1.number, s1.name, s2.subject, s2.score FROM student AS s1, score AS s2 WHERE s1.number = s2.number; #缩减一下显示的列
+----------+-----------+--------------------------+-------+
| number | name | subject | score |
+----------+-----------+--------------------------+-------+
| 20180101 | 杜子腾 | 母猪的产后护理 | 78 |
| 20180101 | 杜子腾 | 萨达姆的战争准备 | 88 |
| 20180102 | 范统 | 母猪的产后护理 | 98 |
| 20180102 | 范统 | 萨达姆的战争准备 | 100 |
+----------+-----------+--------------------------+-------+
4 rows in set (0.00 sec)
史珍香同学,也就是学号为20180103的同学因为某些原因没有参加考试,如果想把没有成绩的同学信息也显示,就出现了两个概念.
内连接和外连接
内连接:
对于内连接的两个表,驱动表中的记录在被驱动表中找不到匹配的记录,该记录不会加入到最后的结果集,我们上边提到的连接都是所谓的内连接。
外连接:
对于外连接的两个表,驱动表中的记录即使在被驱动表中没有匹配的记录,也仍然需要加入到结果集。
根据选择的驱动表的不同,外连接还能分为:
左外连接
选取左侧的表为驱动表。
右外连接
选取右侧的表为驱动表。
即使对于外连接来说,有时候我们也并不想把驱动表的全部记录都加入到最后的结果集。这就犯难了,有时候匹配失败要加入结果集,有时候又不要加入结果集,这咋办,有点儿愁啊。。。噫,把过滤条件分为两种不就解决了这个问题了么,所以放在不同地方的过滤条件是有不同语义的
WHERE子句中的过滤条件WHERE子句中的过滤条件就是我们平时见的那种,不论是内连接还是外连接,凡是不符合WHERE子句中的过滤条件的记录都不会被加入最后的结果集。ON子句中的过滤条件对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配
ON子句中的过滤条件的记录,那么该记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用NULL值填充。需要注意的是,这个
ON子句是专门为外连接驱动表中的记录在被驱动表找不到匹配记录时应不应该把该记录加入结果集这个场景下提出的,所以如果把ON子句放到内连接中,MySQL会把它和WHERE子句一样对待,也就是说:内连接中的WHERE子句和ON子句是等价的。
一般情况下,我们都把只涉及单表的过滤条件放到WHERE子句中,把涉及两表的过滤条件都放到ON子句中,我们也一般把放到ON子句中的过滤条件也称之为连接条件。
小贴士: 左外连接和右外连接简称左连接和右连接,所以下边提到的左外连接和右外连接中的`外`字都用括号扩起来,以表示这个字儿可有可无。
左(外)连接的语法
SELECT * FROM t1 LEFT [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件];
其中中括号里的OUTER单词是可以省略的。对于LEFT JOIN类型的连接来说,我们把放在左边的表称之为外表或者驱动表,右边的表称之为内表或者被驱动表。所以上述例子中t1就是外表或者驱动表,t2就是内表或者被驱动表。需要注意的是,对于左(外)连接和右(外)连接来说,必须使用ON子句来指出连接条件。
(admin@g1-db-test-v07:5001)[jinhailan]>SELECT s1.number, s1.name, s2.subject, s2.score FROM student AS s1 LEFT JOIN score AS s2 ON s1.number = s2.number;
+----------+-----------+--------------------------+-------+
| number | name | subject | score |
+----------+-----------+--------------------------+-------+
| 20180101 | 杜子腾 | 母猪的产后护理 | 78 |
| 20180101 | 杜子腾 | 萨达姆的战争准备 | 88 |
| 20180102 | 范统 | 母猪的产后护理 | 98 |
| 20180102 | 范统 | 萨达姆的战争准备 | 100 |
| 20180103 | 史珍香 | NULL | NULL |
+----------+-----------+--------------------------+-------+
右(外)连接的语法
SELECT * FROM t1 RIGHT [OUTER] JOIN t2 ON 连接条件 [WHERE 普通过滤条件];
只不过驱动表是右边的表,被驱动表是左边的表,具体就不唠叨了。
内连接的语法
内连接和外连接的根本区别就是在驱动表中的记录不符合ON子句中的连接条件时不会把该记录加入到最后的结果集,我们最开始唠叨的那些连接查询的类型都是内连接。不过之前仅仅提到了一种最简单的内连接语法,就是直接把需要连接的多个表都放到FROM子句后边。其实针对内连接,MySQL提供了好多不同的语法,我们以t1和t2表为例瞅瞅:
SELECT * FROM t1 [INNER | CROSS] JOIN t2 [ON 连接条件] [WHERE 普通过滤条件];
也就是说在MySQL中,下边这几种内连接的写法都是等价的:
SELECT * FROM t1 JOIN t2; SELECT * FROM t1 INNER JOIN t2; SELECT * FROM t1 CROSS JOIN t2;
上边的这些写法和直接把需要连接的表名放到FROM语句之后,用逗号,分隔开的写法是等价的
SELECT * FROM t1, t2;
现在我们虽然介绍了很多种内连接的书写方式,不过熟悉一种就好了,这里我们推荐INNER JOIN的形式书写内连接(因为INNER JOIN语义很明确嘛,可以和LEFT JOIN和RIGHT JOIN很轻松的区分开)。这里需要注意的是,由于在内连接中ON子句和WHERE子句是等价的,所以内连接中不要求强制写明ON子句。
连接的本质就是把各个连接表中的记录都取出来依次匹配的组合加入结果集并返回给用户。不论哪个表作为驱动表,两表连接产生的笛卡尔积肯定是一样的。而对于内连接来说,由于凡是不符合ON子句或WHERE子句中的条件的记录都会被过滤掉,其实也就相当于从两表连接的笛卡尔积中把不符合过滤条件的记录给踢出去,所以对于内连接来说,驱动表和被驱动表是可以互换的,并不会影响最后的查询结果。但是对于外连接来说,由于驱动表中的记录即使在被驱动表中找不到符合ON子句条件的记录时也要将其加入到结果集,所以此时驱动表和被驱动表的关系就很重要了,也就是说左外连接和右外连接的驱动表和被驱动表不能轻易互换。
(admin@g1-db-test-v07:5001)[jinhailan]>select * from t1;
+------+------+
| m1 | n1 |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
+------+------+
3 rows in set (0.00 sec) (admin@g1-db-test-v07:5001)[jinhailan]>select * from t2;
+------+------+
| m2 | n2 |
+------+------+
| 2 | b |
| 3 | c |
| 4 | d |
+------+------+
3 rows in set (0.00 sec) (admin@g1-db-test-v07:5001)[jinhailan]>SELECT * FROM t1 LEFT JOIN t2 ON t1.m1 = t2.m2;
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 2 | b | 2 | b |
| 3 | c | 3 | c |
| 1 | a | NULL | NULL |
+------+------+------+------+
3 rows in set (0.00 sec) (admin@g1-db-test-v07:5001)[jinhailan]>SELECT * FROM t1 RIGHT JOIN t2 ON t1.m1 = t2.m2;
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 2 | b | 2 | b |
| 3 | c | 3 | c |
| NULL | NULL | 4 | d |
+------+------+------+------+
3 rows in set (0.00 sec)
(admin@g1-db-test-v07:5001)[jinhailan]>SELECT * FROM t1 INNER JOIN t2 ON t1.m1 = t2.m2;
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 2 | b | 2 | b |
| 3 | c | 3 | c |
+------+------+------+------+
2 rows in set (0.00 sec)
连接的原理
嵌套循环连接(Nested-Loop Join)
对于两表连接来说,驱动表只会被访问一遍,但被驱动表却要被访问到好多遍,具体访问几遍取决于对驱动表执行单表查询后的结果集中的记录条数。对于内连接来说,选取哪个表为驱动表都没关系,而外连接的驱动表是固定的,也就是说左(外)连接的驱动表就是左边的那个表,右(外)连接的驱动表就是右边的那个表。我们上边已经大致介绍过t1表和t2表执行内连接查询的大致过程,我们温习一下
步骤1:选取驱动表,使用与驱动表相关的过滤条件,选取代价最低的单表访问方法来执行对驱动表的单表查询。
步骤2:对上一步骤中查询驱动表得到的结果集中每一条记录,都分别到被驱动表中查找匹配的记录。

如果有3个表进行连接的话,那么步骤2中得到的结果集就像是新的驱动表,然后第三个表就成为了被驱动表,重复上边过程,也就是步骤2中得到的结果集中的每一条记录都需要到t3表中找一找有没有匹配的记录,用伪代码表示一下这个过程就是这样:
for each row in t1 { #此处表示遍历满足对t1单表查询结果集中的每一条记录
for each row in t2 { #此处表示对于某条t1表的记录来说,遍历满足对t2单表查询结果集中的每一条记录
for each row in t3 { #此处表示对于某条t1和t2表的记录组合来说,对t3表进行单表查询
if row satisfies join conditions, send to client
}
}
}
这个过程就像是一个嵌套的循环,所以这种驱动表只访问一次,但被驱动表却可能被多次访问,访问次数取决于对驱动表执行单表查询后的结果集中的记录条数的连接执行方式称之为嵌套循环连接(Nested-Loop Join),这是最简单,也是最笨拙的一种连接查询算法。
使用索引加快连接速度
我们知道在嵌套循环连接的步骤2中可能需要访问多次被驱动表,如果访问被驱动表的方式都是全表扫描的话,妈呀,那得要扫描好多次呀~~~ 但是别忘了,查询t2表其实就相当于一次单表扫描,我们可以利用索引来加快查询速度哦。回顾一下最开始介绍的t1表和t2表进行内连接的例子:
SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd';
我们使用的其实是嵌套循环连接算法执行的连接查询,再把上边那个查询执行过程表拉下来给大家看一下:

查询驱动表t1后的结果集中有两条记录,嵌套循环连接算法需要对被驱动表查询2次:
当
t1.m1 = 2时,去查询一遍t2表,对t2表的查询语句相当于:SELECT * FROM t2 WHERE t2.m2 = 2 AND t2.n2 < 'd';
当
t1.m1 = 3时,再去查询一遍t2表,此时对t2表的查询语句相当于:SELECT * FROM t2 WHERE t2.m2 = 3 AND t2.n2 < 'd';
可以看到,原来的t1.m1 = t2.m2这个涉及两个表的过滤条件在针对t2表做查询时关于t1表的条件就已经确定了,所以我们只需要单单优化对t2表的查询了,上述两个对t2表的查询语句中利用到的列是m2和n2列,我们可以:
在
m2列上建立索引,因为对m2列的条件是等值查找,比如t2.m2 = 2、t2.m2 = 3等,所以可能使用到ref的访问方法,假设使用ref的访问方法去执行对t2表的查询的话,需要回表之后再判断t2.n2 < d这个条件是否成立。这里有一个比较特殊的情况,就是假设
m2列是t2表的主键或者唯一二级索引列,那么使用t2.m2 = 常数值这样的条件从t2表中查找记录的过程的代价就是常数级别的。我们知道在单表中使用主键值或者唯一二级索引列的值进行等值查找的方式称之为const,而设计MySQL的大叔把在连接查询中对被驱动表使用主键值或者唯一二级索引列的值进行等值查找的查询执行方式称之为:eq_ref。在
n2列上建立索引,涉及到的条件是t2.n2 < 'd',可能用到range的访问方法,假设使用range的访问方法对t2表的查询的话,需要回表之后再判断在m2列上的条件是否成立。
假设m2和n2列上都存在索引的话,那么就需要从这两个里边儿挑一个代价更低的去执行对t2表的查询。当然,建立了索引不一定使用索引,只有在二级索引 + 回表的代价比全表扫描的代价更低时才会使用索引。
另外,有时候连接查询的查询列表和过滤条件中可能只涉及被驱动表的部分列,而这些列都是某个索引的一部分,这种情况下即使不能使用eq_ref、ref、ref_or_null或者range这些访问方法执行对被驱动表的查询的话,也可以使用索引扫描,也就是index的访问方法来查询被驱动表。所以我们建议在真实工作中最好不要使用*作为查询列表,最好把真实用到的列作为查询列表。
基于块的嵌套循环连接(Block Nested-Loop Join)
扫描一个表的过程其实是先把这个表从磁盘上加载到内存中,然后从内存中比较匹配条件是否满足。现实生活中的表可不像t1、t2这种只有3条记录,成千上万条记录都是少的,几百万、几千万甚至几亿条记录的表到处都是。内存里可能并不能完全存放的下表中所有的记录,所以在扫描表前边记录的时候后边的记录可能还在磁盘上,等扫描到后边记录的时候可能内存不足,所以需要把前边的记录从内存中释放掉。我们前边又说过,采用嵌套循环连接算法的两表连接过程中,被驱动表可是要被访问好多次的,如果这个被驱动表中的数据特别多而且不能使用索引进行访问,那就相当于要从磁盘上读好几次这个表,这个I/O代价就非常大了,所以我们得想办法:尽量减少访问被驱动表的次数。
当被驱动表中的数据非常多时,每次访问被驱动表,被驱动表的记录会被加载到内存中,在内存中的每一条记录只会和驱动表结果集的一条记录做匹配,之后就会被从内存中清除掉。然后再从驱动表结果集中拿出另一条记录,再一次把被驱动表的记录加载到内存中一遍,周而复始,驱动表结果集中有多少条记录,就得把被驱动表从磁盘上加载到内存中多少次。所以我们可不可以在把被驱动表的记录加载到内存的时候,一次性和多条驱动表中的记录做匹配,这样就可以大大减少重复从磁盘上加载被驱动表的代价了。所以设计MySQL的大叔提出了一个join buffer的概念,join buffer就是执行连接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个join buffer中,然后开始扫描被驱动表,每一条被驱动表的记录一次性和join buffer中的多条驱动表记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的I/O代价。使用join buffer的过程如下图所示:
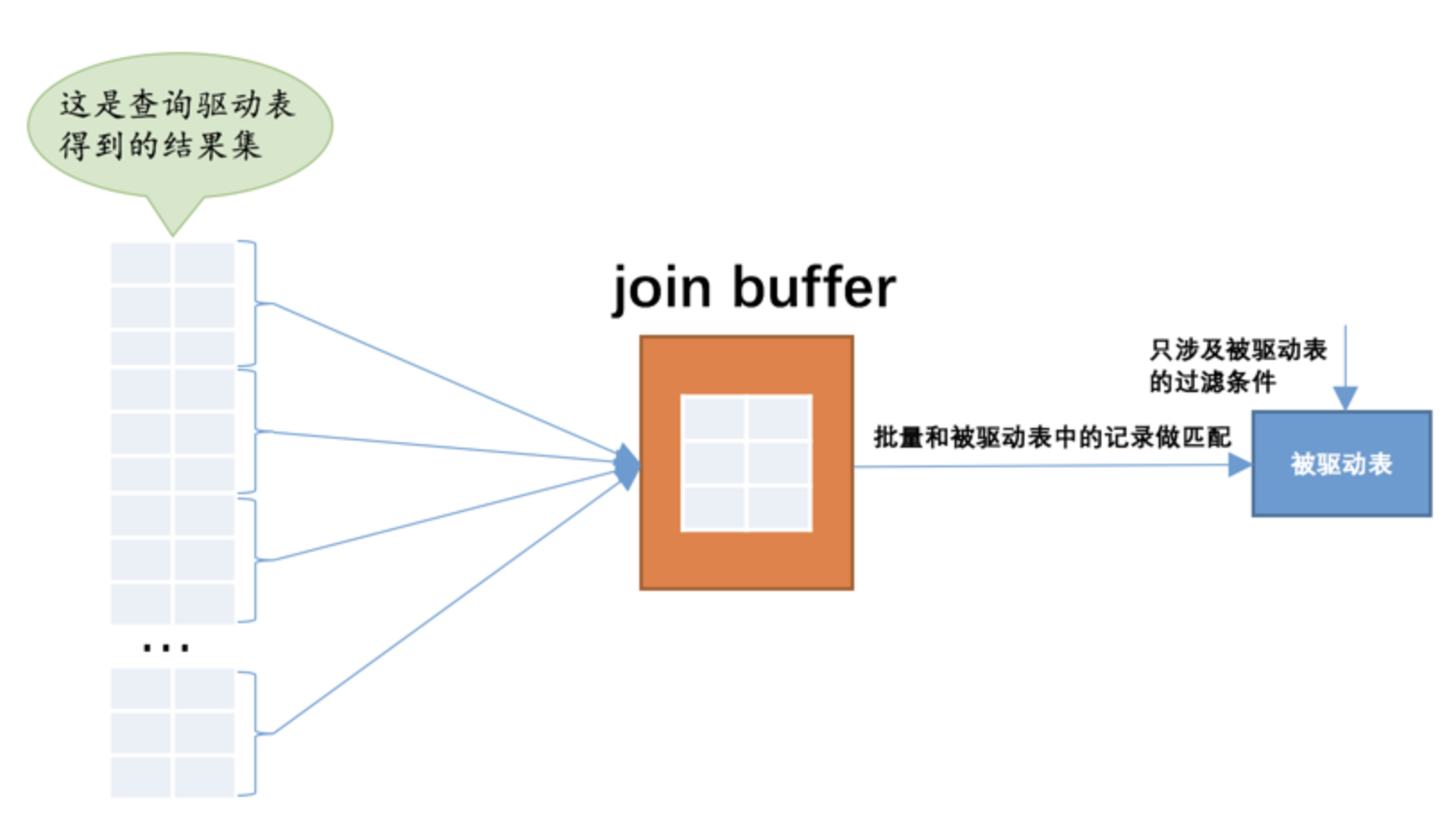
最好的情况是join buffer足够大,能容纳驱动表结果集中的所有记录,这样只需要访问一次被驱动表就可以完成连接操作了。设计MySQL的大叔把这种加入了join buffer的嵌套循环连接算法称之为基于块的嵌套连接(Block Nested-Loop Join)算法。
这个join buffer的大小是可以通过启动参数或者系统变量join_buffer_size进行配置,默认大小为262144字节(也就是256KB),最小可以设置为128字节。当然,对于优化被驱动表的查询来说,最好是为被驱动表加上效率高的索引,如果实在不能使用索引,并且自己的机器的内存也比较大可以尝试调大join_buffer_size的值来对连接查询进行优化。
另外需要注意的是,驱动表的记录并不是所有列都会被放到join buffer中,只有查询列表中的列和过滤条件中的列才会被放到join buffer中,所以再次提醒我们,最好不要把*作为查询列表,只需要把我们关心的列放到查询列表就好了,这样还可以在join buffer中放置更多的记录呢哈。
MySQL表连接原理的更多相关文章
- Mysql单表访问方法,索引合并,多表连接原理,基于规则的优化,子查询优化
参考书籍<mysql是怎样运行的> 非常推荐这本书,通俗易懂,但是没有讲mysql主从等内容 书中还讲解了本文没有提到的子查询优化内容, 本文只总结了常见的子查询是如何优化的 系列文章目录 ...
- 【个人笔记】《知了堂》mysql表连接
为什么使用表连接 什么是表连接? 如果数据来自多个表,那么可以采用链接查询的方式来实现.因此表连接就是多个表连接合在一起实现查询效果 表连接的原理 表连接采用的是笛卡尔乘积,称之为横向连接. 笛卡尔乘 ...
- SQL Server三种表连接原理
在SQL Server数据库中,查询优化器在处理表连接时,通常会使用一下三种连接方式: 嵌套循环连接(Nested Loop Join) 合并连接 (Merge Join) Hash连接 (Hash ...
- Mysql表连接查询
原文地址: https://www.cnblogs.com/qiuqiuqiu/p/6442791.html 1.内联接(典型的联接运算,使用像 = 或 <> 之类的比较运算符).包括相等 ...
- mysql 表连接
1.子查询是指在另一个查询语句中的SELECT子句. 例句: SELECT * FROM t1 WHERE column1 = (SELECT column1 FROM t2); 其中,SELECT ...
- MySQL表连接
有3种: JOIN 按照功能大致分为如下三类: CROSS JOIN (交叉连接) INNER JOIN (内连接或等值连接). OUTER JOIN (外连接) 交叉连接CROSS JOIN 交叉连 ...
- mysql 内连接原理
- 【SqlServer系列】表连接
1 概述 1.1 已发布[SqlServer系列]文章 [SqlServer系列]MYSQL安装教程 [SqlServer系列]数据库三大范式 [SqlServer系列]表单查询 1.2 本篇 ...
- MySQL中基本的多表连接查询教程
一.多表连接类型1. 笛卡尔积(交叉连接) 在MySQL中可以为CROSS JOIN或者省略CROSS即JOIN,或者使用',' 如: SELECT * FROM table1 CROSS JOIN ...
随机推荐
- PHP连数据库生成数据字典
<?php /** * 生成mysql数据字典 */ header("Content-type:text/html;charset=utf-8"); // 配置数据库 $da ...
- swagger获取
参考 https://www.jianshu.com/p/840320d431a1 https://www.cnblogs.com/luoluocaihong/p/7106276.html
- 免杀PHP一句话一枚
免杀PHP一句话shell,利用随机异或免杀D盾,免杀安全狗护卫神等 <?php class VONE { function HALB() { $rlf = 'B' ^ "\x23&q ...
- 记一次 springboot 参数解析 bug调试 HandlerMethodArgumentResolver
情况描述 前端输入框输入中文的横线 -- ,到后台接收时变成了 &madsh;$mdash 正常应该显示成这样: bug调试思路记录 最开始完全没有向调试源码方面想,试了不少方法,都没解决,没 ...
- JS: 子项可以来回交换的两个下拉列表
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> ...
- tornado结合前端进行文件上传
在表单中我们获取用户提交的数据,使用的是get_argument,复选框使用的是get_arguments,但是文件的不一样,文件的使用request.files. form文件上传 html代码: ...
- 吴裕雄--天生自然java开发常用类库学习笔记:观察者设计模式
import java.util.* ; class House extends Observable{ // 表示房子可以被观察 private float price ;// 价钱 public ...
- 吴裕雄--天生自然java开发常用类库学习笔记:属性类Properties
import java.util.Properties; public class PropertiesDemo01{ public static void main(String args[]){ ...
- Java中的数学方法
直接用代码 public class TestNumber { public static void main(String[] args) { float f1 = 5.4f; float f2 = ...
- Idea 打开多profile注意事项
Maven项目经常会有多个profile,可以方便在编译时指定profile. 如果有多个profile,idea 在打开工程后默认配置可能会有些问题. 例如: 最近在编译一个项目:https://g ...