[python爬虫]简单爬虫功能
在我们日常上网浏览网页的时候,经常会看到某个网站中一些好看的图片,它们可能存在在很多页面当中,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材。
我们最常规的做法就是通过鼠标右键,选择另存为。但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过截图工具截取下来,但这样就降低图片的清晰度。就算可以弄下来,但是我们需要几千个页面当中的图片,如果一个一个下载,你的手将残。好吧~!其实你很厉害的,右键查看页面源代码。
我们可以通过python 来实现这样一个简单的爬虫功能,把我们想要的代码爬取到本地。下面就看看如何使用python来实现这样一个功能。
一、获取整个页面数据
def get_content(url):
"""
获取网页源码
"""
html = urllib.urlopen(url)
content = html.read()
html.close()
return content
二、抓取图片文件名
抓取文件名时,由于特殊符号会影响显示,所以将“ * ”,“ / ”等符号删
def get_name(name,file):
"""
抓取图片文件名
"""
self.picName = name.decode('utf-8')
if "*" in self.picName:
self.picName = self.picName.replace("*","")
elif "/" in self.picName:
self.picName = self.picName.replace("/","")
print self.picName def get_file(info):
"""
获取img文件
"""
soup = BeautifulSoup(info,"html.parser")
# 找到所有免费下载的模块
all_files = soup.find_all('a',title="免费下载")
# 找到所有的hi标题
titles = soup.find_all('h1')
# 截取需要的标题
for title in titles:
name = str(title)[4:-5] # 获取文件名
for file in all_files:
get_name(name,file)
三、下载图片
下载后缀名是"gif"或者"jpg"的图片,并存放在E:\\googleDownLoad\\\cssmuban目录下
def pic_category(str_images):
"""
下载图片
"""
soup = BeautifulSoup(info,"html.parser")
all_image = soup.find_all('div',class_="large-Imgs")
images = str_images
pat = re.compile(images)
image_code = re.findall(pat,str(all_image))
for i in image_code:
if str(i)[-3:] == 'gif':
image = urllib.urlretrieve('http://www.cssmoban.com'+str(i), 'E:\\googleDownLoad\\\cssmuban\\'+str(self.picName).decode('utf-8')+'.gif')
else:
image = urllib.urlretrieve('http://www.cssmoban.com'+str(i), 'E:\\googleDownLoad\\\cssmuban\\'+str(self.picName).decode('utf-8')+'.jpg') def pic_download(info):
"""
下载图片
"""
pic_category(r'src="(.+?\.gif)"')
pic_category(r'src="(.+?\.jpg)"')
四、遍历所有url,下载每个页面的所需要的图片和文件名
self.num = 1
# 下载文件
for i in range(6000):
url = 'http://www.cssmoban.com/cssthemes/'+ str(self.num) +'.shtml'
info = get_content(url)
get_file(info)
pic_download(info)
self.num = self.num + 1
运行结果如下:
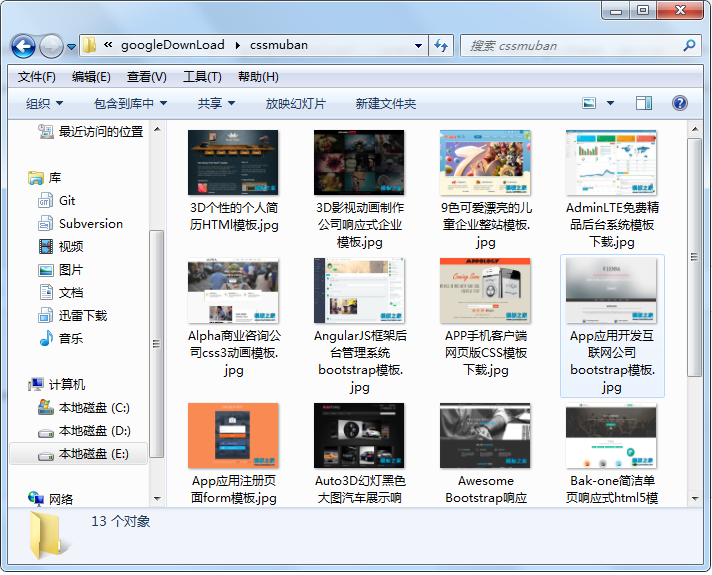

本站文章为宝宝巴士 SD.Team原创,转载务必在明显处注明:(作者官方网站:宝宝巴士)
转载自【宝宝巴士SuperDo团队】 原文链接: http://www.cnblogs.com/superdo/p/4927574.html
[python爬虫]简单爬虫功能的更多相关文章
- Python开发简单爬虫 - 慕课网
课程链接:Python开发简单爬虫 环境搭建: Eclipse+PyDev配置搭建Python开发环境 Python入门基础教程 用Eclipse编写Python程序 课程目录 第1章 课程介绍 ...
- Python做简单爬虫(urllib.request怎么抓取https以及伪装浏览器访问的方法)
一:抓取简单的页面: 用Python来做爬虫抓取网站这个功能很强大,今天试着抓取了一下百度的首页,很成功,来看一下步骤吧 首先需要准备工具: 1.python:自己比较喜欢用新的东西,所以用的是Pyt ...
- python实现简单爬虫抓取图片
最近在学习python,正如大家所知,python在网络爬虫方面有着广泛的应用,下面是一个利用python程序抓取网络图片的简单程序,可以批量下载一个网站更新的图片,其中使用了代理IP的技术. imp ...
- Python开发简单爬虫(一)
一 .简单爬虫架构: 爬虫调度端:启动爬虫,停止爬虫,监视爬虫运行情况 URL管理器:对将要爬取的和已经爬取过的URL进行管理:可取出带爬取的URL,将其传送给“网页下载器” 网页下载器:将URL指定 ...
- Python开发简单爬虫
简单爬虫框架: 爬虫调度器 -> URL管理器 -> 网页下载器(urllib2) -> 网页解析器(BeautifulSoup) -> 价值数据 Demo1: # codin ...
- 教你如何入手用python实现简单爬虫微信公众号并下载视频
主要功能 如何简单爬虫微信公众号 获取信息:标题.摘要.封面.文章地址 自动批量下载公众号内的视频 一.获取公众号信息:标题.摘要.封面.文章URL 操作步骤: 1.先自己申请一个公众号 2.登录自己 ...
- python多线程简单爬虫
爬虫本质就是将网站或者接口的数据经过筛选后按需求保存 这里实现一个简单爬虫仅供参考 import requests import bs4 import threading import queue i ...
- python实现简单爬虫功能
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片鼠标右键的 ...
- 使用python实现简单爬虫
简单的爬虫架构 调度器 URL管理器 管理待抓取的URL集合和已抓取的URL,防止重复抓取,防止死循环 功能列表 1:判断新添加URL是否在容器中 2:向管理器添加新URL 3:判断容器是否为空 4: ...
随机推荐
- 数据结构--栈(附上STL栈)
定义: 栈是一种只能在某一端插入和删除数据的特殊线性表.他按照先进先出的原则存储数据,先进的数据被压入栈底,最后进入的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后被压入栈的,最先弹出).因此栈 ...
- Android原生多语言切换方案,兼容Android10
前言 一个应用若需要国际化,至少需要支持中文和英语这两种语言,而同时随着谷歌的系统的更新,安卓系统可以设置当前语言的首选语言.因此,本文立足于此,多语言的切换方案为:App固定的文字内容,跟随系统,中 ...
- Java笔记(day23-day26)
IO流1,复制一个文本文件. 1,明确体系: 源:InputStream ,Reader 目的:OutputStream ,Writer 2,明确数据: ...
- P2774 方格取数问题 网络流
题目: P2774 方格取数问题 题目背景 none! 题目描述 在一个有 m*n 个方格的棋盘中,每个方格中有一个正整数.现要从方格中取数,使任意 2 个数所在方格没有公共边,且取出的数的总和最大. ...
- Spring Cloud学习 之 Spring Cloud Hystrix(使用详解)
文章目录 创建请求命令: 定义服务降级: 异常处理: 异常传播: 异常获取: 命令名称,分组以及线程池划分: 创建请求命令: Hystrix命令就是我们之前说的HystrixCommand,它用来 ...
- MySQL 入门(3):事务隔离
摘要 在这一篇内容中,我将从事务是什么开始,聊一聊事务的必要性. 然后,介绍一下在InnoDB中,四种不同级别的事务隔离,能解决什么问题,以及会带来什么问题. 最后,我会介绍一下InnoDB解决高并发 ...
- echarts 中 symbol 自定义图片
首先我使用的技术框架的VUE,当然该方法在其他框架也是适用的,这点大家注意一下~ 在官方文档里面,修改标记的图形(symbol)的方法有三种: 一:ECharts 提供的标记类型有 'circle', ...
- [codeforces-543B]bfs求最短路
题意:给一个边长为1的无向图,求删去最多的边使得从a到b距离<=f,从c到d距离<=g,a,b,c,d,f,g都是给定的,求最多删去的边数. 思路:反过来思考,用最少的边构造两条从a到b, ...
- CentOS7 Installing Python3
最近开始学习python. python火了这么久,我终于还是跪舔它了,我是一个跟风的人,学过C.C#.JAVA.PHP,无一例外的浅尝即止,不知道我这双已经近视的眼,确认过的眼神还对不对,希望pyt ...
- HDU 2006 (水)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2006 题目大意:给你几个数,求奇数的乘积和 解题思路: 很水,不需要数组的,一个变量 x 就行 代码: ...