HashMap ConcurrentHashMap解读
前言:
常见的关于HahsMap与ConcurrentHashMap的问题:
数据结构、线程安全、扩容、jdk1.7 HashMap死循环、jdk1.8 HashMap红黑树、容量必须是2的冥次
HashMap
数据结构:数组,单向链表
线程安全:不安全,HashTable线程安全,但是全用了 synchronized ,性能低
一、jdk1.7中
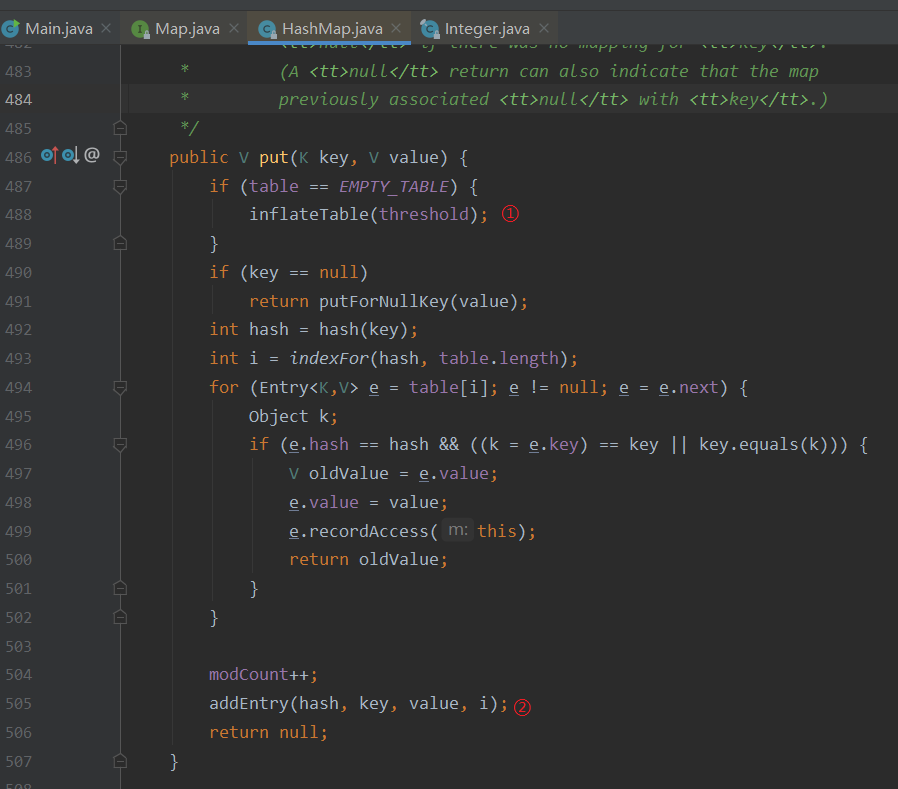
①:对HashMap初始化进行初始化;
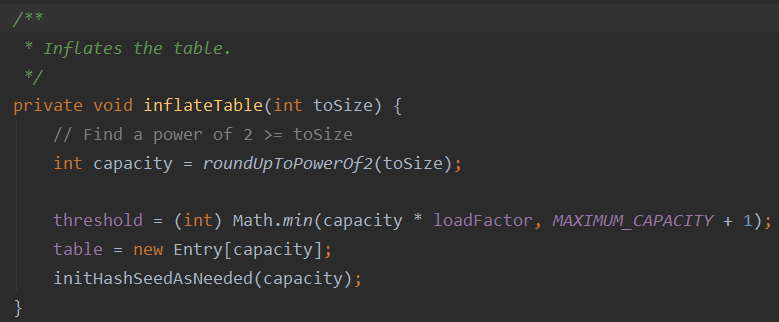
初始化HashMap的 threshold 字段,通过因子算出,默认为0.75,算出来是16 * 0.75为12;
初始化hash种子信息;
保证了HashMap的容量是2的冥次。为什么HashMap的容量必须是2的冥次,因为可以增加有效长度,减少hash碰撞,关于hash碰撞:https://blog.csdn.net/qq_35583089/article/details/80048285
②:添加Entry对象,赋值
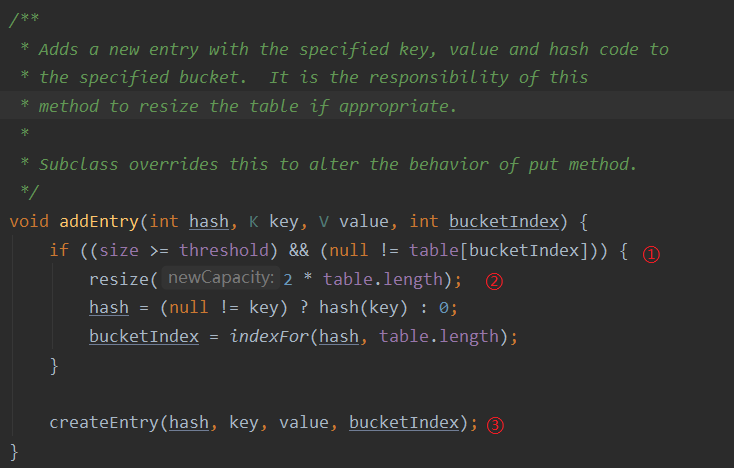
①:判断当前容量是否到达阈值,例如12
②:扩容
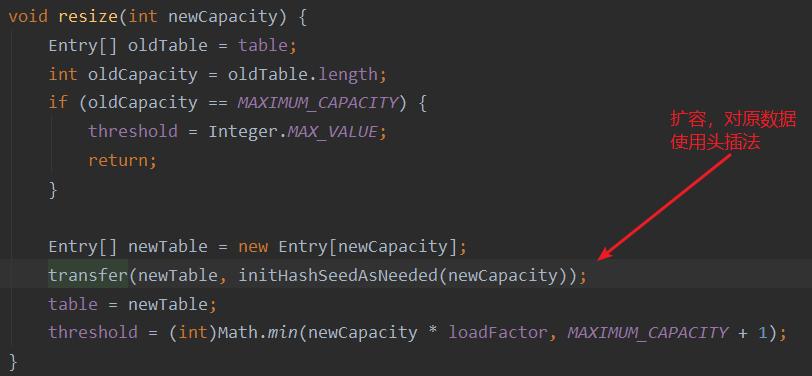
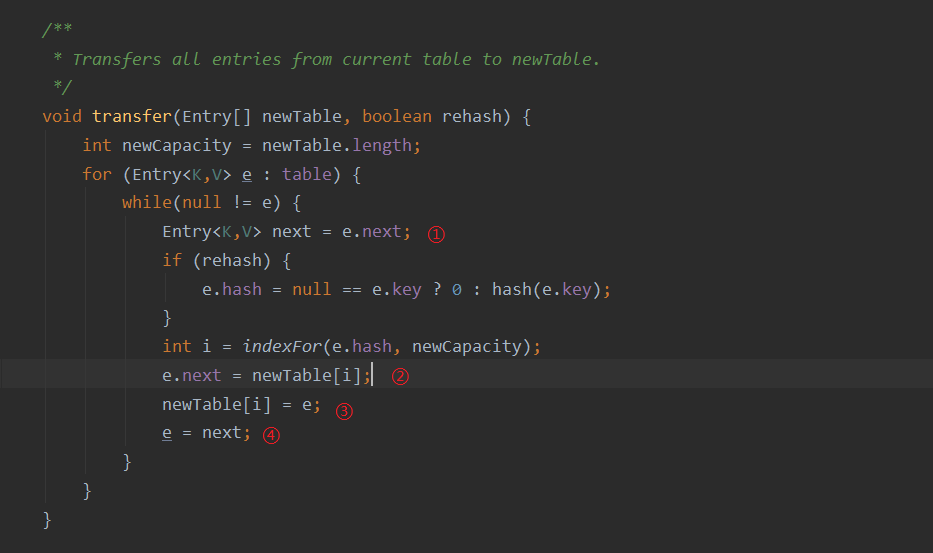
头插法:原先的头会成为新链表的尾部,原先的尾部会成为新链表的头
这里的代码就是为什么不建议并发时使用HashMap的原因,e.next形成死循环,导致CPU 100%卡死,并且线程不安全
二、jdk1.8中
jdk1.8中,当容量超过2的8次方(64)时,使用红黑树替代链表
ConcurrentHashMap
数据结构(jdk1.7):Segment数组,Segment下又有HashEntry,HashEntry为数组+链表
数据结构(jdk1.8):但是在jdk1.8中,起始的数据结构是数组+链表的。但是当单个链表长度
ConcurrentHashMap是一个线程安全的Map类,其通过多个Segment来保存数据,操作不同Segment之间是可以并发的,而操作统计个Segment进行数据的插入时,会进行 ReentrantLock 上锁操作
一、jdk1.7
先看看put方法
public V put(K key, V value) {
ConcurrentHashMap.Segment<K,V> s;
if (value == null)
throw new NullPointerException();
//通过key的hash值算出segment的下标
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (ConcurrentHashMap.Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
//这里会判断对应下标的segment是否存在,不存在会进行初始化
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
下面是Segment.put方法
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//尝试获得锁,并开始同步
ConcurrentHashMap.HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
ConcurrentHashMap.HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
ConcurrentHashMap.HashEntry<K,V> first = entryAt(tab, index);
for (ConcurrentHashMap.HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
//和HashMap一样,链表使用头插法,后插入的元素永远在数组的最前面
if (node != null)
node.setNext(first);
else
node = new ConcurrentHashMap.HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
//超过Segment阈值时,对HashEntry进行扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
二、jdk1.8
java1.7采用volatile去获取已存在的Segment。java1.8采用的CAS算法,而没用使用Segment进行数据存储
HashMap ConcurrentHashMap解读的更多相关文章
- HashTable & HashMap & ConcurrentHashMap 原理与区别
一.三者的区别 HashTable HashMap ConcurrentHashMap 底层数据结构 数组+链表 数组+链表 数组+链表 key可为空 否 是 否 value可为空 否 是 否 ...
- 深入理解HashMap+ConcurrentHashMap的扩容策略
前言 理解HashMap和ConcurrentHashMap的重点在于: (1)理解HashMap的数据结构的设计和实现思路 (2)在(1)的基础上,理解ConcurrentHashMap的并发安全的 ...
- Jdk8 Hashmap ConcurrentHashMap
JDK1.8 Hashmap JDK1.8 ConcurrentHashMap 不采用segment而采用 synchronized (f) f = table[i]; 减小锁的力度 设计了MOVE ...
- java多线程之hashmap concurrenthashmap的状态同步
最近在高并发的系统中发现,concurrenthashmap除了大家熟知的避免循环期间发生ConcurrentModificationException异常外,还有重要的一点是Retrievals r ...
- HashMap完全解读
一.什么是HashMap 基于哈希表的 Map 接口的实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.(除了非同步和允许使用 null 之外,HashMap 类与 Has ...
- HashMap? ConcurrentHashMap? 相信看完这篇没人能难住你!
前言 Map 这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据. 本篇主要想讨论 ConcurrentHashMap 这样一个并发容器,在正式开始之前我觉得有必要谈谈 ...
- ConcurrentHashMap 解读
初始化: 问题:如何当且仅只有一个线程初始化table private final Node<K,V>[] initTable() { Node<K,V>[] tab; int ...
- Java7/8 HashMap ConcurrentHashMap
网上关于 HashMap 和 ConcurrentHashMap 的文章确实不少,不过缺斤少两的文章比较多,所以才想自己也写一篇,把细节说清楚说透,尤其像 Java8 中的 ConcurrentHas ...
- HashMap? ConcurrentHashMap?
前言 Map 这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据. 本篇主要想讨论 ConcurrentHashMap 这样一个并发容器,在正式开始之前我觉得有必要谈谈 ...
随机推荐
- python学习 —— 获取系统运行情况信息并在Linux下设置定时运行python脚本
代码: # -*- coding:utf-8 -*- from psutil import * def cpu_usage_rate(): for i, j in zip(range(1, cpu_c ...
- AF(操作者框架)系列(1)-LabVIEW中的模块化应用概述
一.引子 在前面对LabVIEW介绍的文章中,关于框架开发的内容涉及很少.为了讲解操作者框架(Actor Framework)的优缺点,也只是拿出来QDSM(Queue-Driven State Ma ...
- Python - 模块中的"if __name__ == '__main__':"
1.1 如果导入的模块除了定义函数之外还中有可以执行代码,那么Python解释器在导入这个模块时就会执行这些代码. module1.py: def foo(): print('module 1') f ...
- Python 爬取 热词并进行分类数据分析-[热词关系图+报告生成]
日期:2020.02.05 博客期:144 星期三 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- git 修改分支 删除分支 新增分支
一.修改分支名 1.本地分支重命名 git branch -m oldName newName 2.将重命名后的分支推送到远程 git push origin newName 3.重新更新所有分支 g ...
- Spring源码试读--BeanFactory模拟实现
动机 现在Springboot越来越便捷,如果简单的Spring应用,已无需再配置xml文件,基本可以实现全注解,即使是SpringCloud的那套东西,也都可以通过yaml配置完成.最近一年一直在用 ...
- tomcat启动报错failed to start component
严重: A child container failed during start java.util.concurrent.ExecutionException: org.apache.catali ...
- Spark教程——(10)Spark SQL读取Phoenix数据本地执行计算
添加配置文件 phoenixConnectMode.scala : package statistics.benefits import org.apache.hadoop.conf.Configur ...
- 树莓派4B踩坑指南 - (4)输入法和字体
输入法和字体 fcitx 安装谷歌输入法和sunpinyin,哪个不用可以装完卸载: sudo apt-get install fcitx fcitx-googlepinyin fcitx-modul ...
- python人脸对比
import sys import ssl from urllib import request,parse # client_id 为官网获取的AK, client_secret 为官网获 ...