【Hadoop离线基础总结】数据仓库和hive的基本概念
数据仓库和Hive的基本概念
数据仓库
概述
数据仓库英文全称为 Data Warehouse,一般简称为DW。主要目的是构建面向分析的集成化数据环境,主要职责是对仓库中的数据进行分析,支持我们做决策。主要特征
面向主题(Subject-Oriented):数据分析有一定的范围,需要选取一定的主题进行分析。
集成性(Integrated):集成各个其他方面关联的数据,比如分析订单购买人的情况,就涉及到用户信息的数据。
非易失性(Non-Volatile):数据分析主要是分析过去已经发生的数据,都是既成的事实,不会再改变
时变性(Time-varient):随着时间的推移发展,数据的形态也在发生变化,数据分析的手段也要相应的改变数据仓库与数据库的区别

数据仓库分层架构
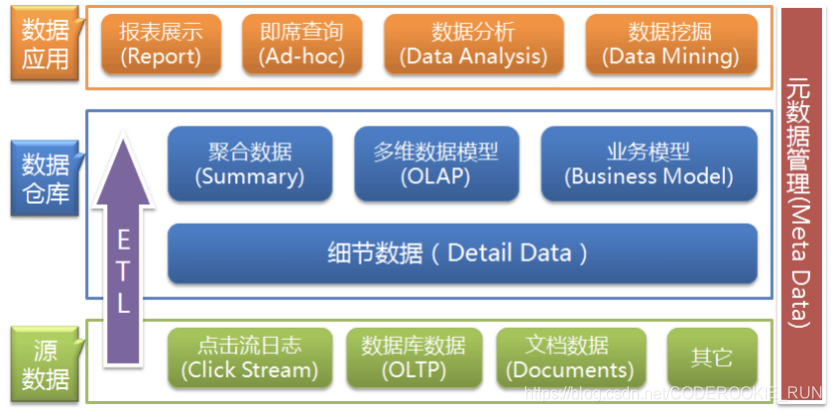
数据仓库架构可分为三层:源数据、数据仓库、数据应用
源数据层(ODS):是产生数据的地方。此层数据直接沿用外围系统数据结构和数据,不对外开放,为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备。
数据仓库层(DW):也称为细节层,主要集中存储数据,面向主题进行分析。DW层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗(去除了杂质)后的数据。
数据应用层(DA/APP):前端应用直接读取的数据源;根据报表、专题分析需求而计算生成的数据,主要用于展示分析之后的数据结果。
ETL(抽取Extract, 转化Transfer, 装载Load):数据仓库从各数据源获取数据及在数据仓库内的数据转换和流动都可以认为是ETL的过程。ETL是数据仓库的流水线,也可以认为是数据仓库的血液,它维系着数据仓库中数据的新陈代谢,而数据仓库日常的管理和维护工作的大部分精力就是保持ETL的正常和稳定。
对数据仓库分层的原因:用空间换时间。通过数据分层管理可以简化数据清洗的过程,也就是把原来一步的工作分到了多个步骤去完成,每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性,当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。数据仓库元数据管理
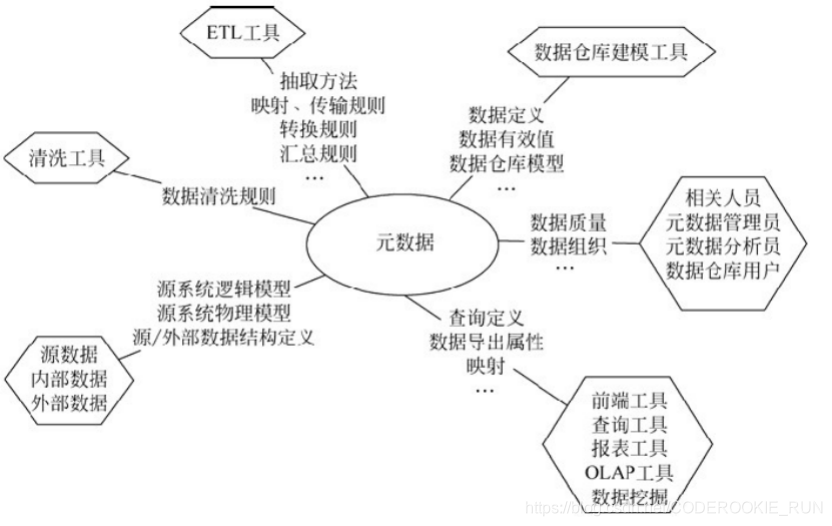
元数据(Meta Date):主要记录数据仓库中模型的定义、各层级间的映射关系、监控数据仓库的数据状态及ETL的任务运行状态。简单来讲,元数据记录了ETL一整套流程。如果要更为 详细地说,元数据定义了源数据系统到数据仓库的映射、数据转换的规则、数据仓库的逻辑结构、数据更新的规则、数据导入历史记录以及装载周期等相关内容。数据抽取和转换的专家以及数据仓库管理员正是通过元数据高效地构建数据仓库。
Hive的基本概念
概述
Hive是基于Hadoop的一个数据仓库处理工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。本质是将sql语句转换成MapReduce的任务进行执行,所以一定程度上可以说hive是MapReduce的一个客户端。结构化、半结构化、非结构化数据
结构化数据:体现为数据字段固定,数据类型固定(数据库的表就是一种最典型的结构化数据)
半结构化数据:XML,JSON,数据类型一定,但是数据的字段个数不定
非结构化数据:完全没有任何规律,字段类型不定、字段个数不定、数据类型不定,比如说音频、视频选择用Hive的原因
直接使用Hadoop的弊端:人员学习成本高、项目周期要求短、MapReduce实现复杂查询逻辑开发难度大
用Hive的好处:操作接口采用类sql语法,提供快速开发的能力。 避免了去写MapReduce,减少开发人员的学习成本。 功能扩展很方便Hive架构
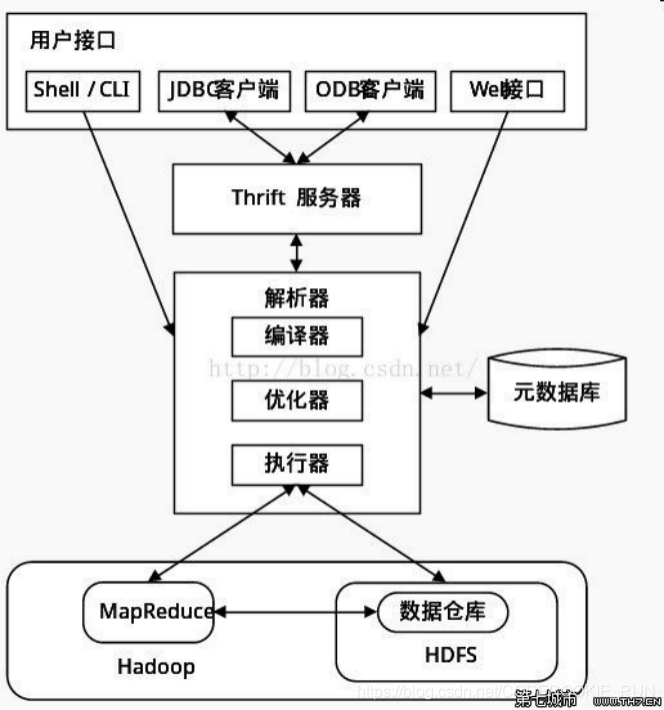
用户接口:就是提供写sql语句的地方。包括CLI、JDBC/ODBC、WebGUI。其中,CLI (command line interface) 为shell命令行;JDBC/ODBC是Hive的JAVA实现,与传统数据库JDBC类似;WebGUI是通过浏览器访问Hive。
解析器:解析sql语句,转换成MepReduce的任务提交并准备执行,是重中之重。
元数据存储:通常是存储在关系数据库如mysql/derby中(Derby不好用,元数据一般都保存在mysql或者oracle中等)。Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。Hive与Hadoop的关系

一句话来说明:Hive是MapReduce的一个客户端Hive和传统数据库的对比
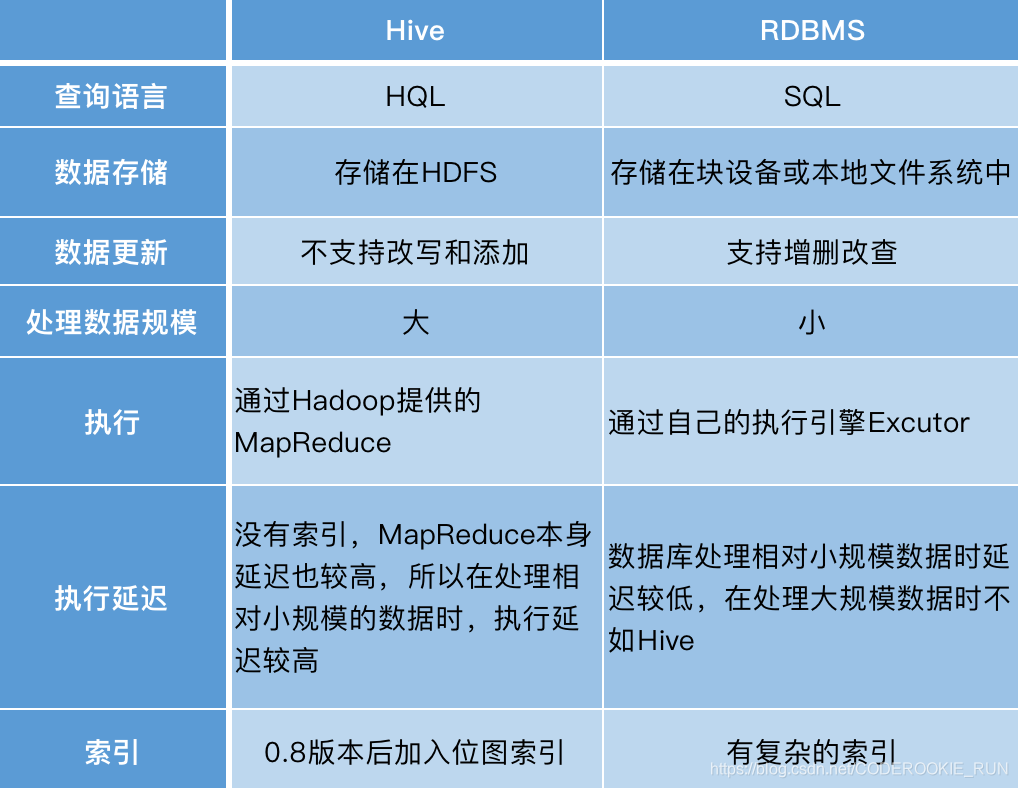
Hive的数据存储
Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,ORC,RCFILE等),只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
【Hadoop离线基础总结】数据仓库和hive的基本概念的更多相关文章
- 【Hadoop离线基础总结】Hive调优手段
Hive调优手段 最常用的调优手段 Fetch抓取 MapJoin 分区裁剪 列裁剪 控制map个数以及reduce个数 JVM重用 数据压缩 Fetch的抓取 出现原因 Hive中对某些情况的查询不 ...
- 【Hadoop离线基础总结】流量日志分析网站整体架构模块开发
目录 数据仓库设计 维度建模概述 维度建模的三种模式 本项目中数据仓库的设计 ETL开发 创建ODS层数据表 导入ODS层数据 生成ODS层明细宽表 统计分析开发 流量分析 受访分析 访客visit分 ...
- 【Hadoop离线基础总结】oozie的安装部署与使用
目录 简单介绍 概述 架构 安装部署 1.修改core-site.xml 2.上传oozie的安装包并解压 3.解压hadooplibs到与oozie平行的目录 4.创建libext目录,并拷贝依赖包 ...
- 【Hadoop离线基础总结】Hue的简单介绍和安装部署
目录 Hue的简单介绍 概述 核心功能 安装部署 下载Hue的压缩包并上传到linux解压 编译安装启动 启动Hue进程 hue与其他框架的集成 Hue与Hadoop集成 Hue与Hive集成 Hue ...
- 【Hadoop离线基础总结】impala简单介绍及安装部署
目录 impala的简单介绍 概述 优点 缺点 impala和Hive的关系 impala如何和CDH一起工作 impala的架构及查询计划 impala/hive/spark 对比 impala的安 ...
- 【Hadoop离线基础总结】Sqoop常用命令及参数
目录 常用命令 常用公用参数 公用参数:数据库连接 公用参数:import 公用参数:export 公用参数:hive 常用命令&参数 从关系表导入--import 导出到关系表--expor ...
- 【Hadoop离线基础总结】Hive的基本操作
Hive的基本操作 创建数据库与创建数据库表 创建数据库的相关操作 创建数据库:CREATE TABLE IF NOT EXISTS myhive hive创建表成功后的存放位置由hive-site. ...
- 【Hadoop离线基础总结】Hive的安装部署以及使用方式
Hive的安装部署以及使用方式 安装部署 Derby版hive直接使用 cd /export/softwares 将上传的hive软件包解压:tar -zxvf hive-1.1.0-cdh5.14. ...
- 【Hadoop离线基础总结】Sqoop数据迁移
目录 Sqoop介绍 概述 版本 Sqoop安装及使用 Sqoop安装 Sqoop数据导入 导入关系表到Hive已有表中 导入关系表到Hive(自动创建Hive表) 将关系表子集导入到HDFS中 sq ...
随机推荐
- GeoGebra案例(傅里叶级数的方波)
傅里叶级数介绍:请移步参见这位马大佬的博文 https://www.matongxue.com/madocs/619.html 马大佬中的gif图在我看来是非常直观且有趣的,奈何本人本领实在有限,学习 ...
- 用Python画的,5 种非传统的可视化技术,超炫酷的动态图
数据可以帮助我们描述这个世界.阐释自己的想法和展示自己的成果,但如果只有单调乏味的文本和数字,我们却往往能难抓住观众的眼球.而很多时候,一张漂亮的可视化图表就足以胜过千言万语.本文将介绍 5 种基于 ...
- Spring Cloud 系列之 Gateway 服务网关(三)
本篇文章为系列文章,未读第一集的同学请猛戳这里: Spring Cloud 系列之 Gateway 服务网关(一) Spring Cloud 系列之 Gateway 服务网关(二) 本篇文章讲解 Ga ...
- Linux常见提权
常见的linux提权 内核漏洞提权 查看发行版 cat /etc/issue cat /etc/*-release 查看内核版本 uname -a 查看已经安装的程序 dpkg -l rpm -qa ...
- pytorch 中LSTM模型获取最后一层的输出结果,单向或双向
单向LSTM import torch.nn as nn import torch seq_len = 20 batch_size = 64 embedding_dim = 100 num_embed ...
- 曹工杂谈--只用一个命令,centos系统里装了啥软件,啥时候装的,全都清清楚楚
前言 一直以来,对linux的掌握就是半桶水的状态,经常yum装个东西,结果依赖一堆东西:然后再用源码装个东西,只知道make.make install,背后干了啥也不清楚了,卸载也不方便. 这几天工 ...
- C/C++,被誉为“最经典的编程语言”,不仅是因为编程入门需要学?
计算机诞生初期,用机器语言或汇编语言编写程序; 第一种高级语言FORTRAN诞生于1954年; BASIC语言(1964)是由FORTRAN语言的简化而成的是为初学者设计的小型高级语言; C语言是19 ...
- Vue-cli4脚手架搭建
一:要安装Node.js:安装路径要默认安装(node-v12.16.2-x64.msi-长支持 二:要安装cnpm 1)说明:npm(node package manager)是nodejs的包管理 ...
- 在IBM Cloud中运行Fabric
文章目录 打包智能合约 创建IBM Cloud services 创建fabric网络 创建org和相应的节点 创建order org和相应节点 创建和加入channel 导入智能合约 上篇文章我们讲 ...
- 使用Node.js的http-serve搭建本地服务器
为什么要使用它? 首先,类似于vue-cli创建的项目,都能够实现浏览器中自动刷新,实时查看项目效果.其中的原理在于,webpack这样的工具启动了一个本地服务器,将本机当作一台服务器,这样在浏览器中 ...