stanfordcorenlp安装教程&问题汇总(importerror-no-module-named-psutil、OSError: stanford-chinese-corenlp-yyyy-MM-dd-models.jar not exists.)&简单使用教程
stanfordcorenlp安装教程&简单使用教程
编译环境:python 3.6 、win10 64位、jdk1.8及以上
1、stanfordcorenlp安装依赖环境
- 下载安装JDK 1.8及以上版本。安装教程:https://blog.csdn.net/qq_40426415/article/details/80994622
jdk下载地址:https://www.oracle.com/java/technologies/javase-jdk8-downloads.html
- 下载Stanford CoreNLP文件。下载地址:https://stanfordnlp.github.io/CoreNLP/
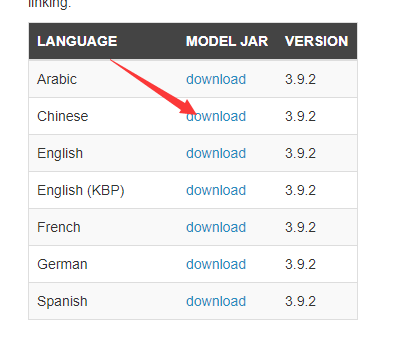
- 处理中文文本,需要下载中文模型数据。下载地址:http://nlp.stanford.edu/software/stanford-chinese-corenlp-2018-10-05-models.jar
刚刚上传了百度云文件,需要的也可以通过百度云下载:链接:https://pan.baidu.com/s/12nYVdnuZlzcxRBOuRs7NMQ 提取码:o8it
2、安装过程
- 首先安装好JDK1.8及以上版本,安装好,并配置好环境;
- 其次,通过pip命令下载stanforecorenlp。本文安装的stanfordcorenlp版本为3.9.1,如果如果需要安装其它版本,可以用pip install stanforecorenlp==3.7.1,指定安装的版本。
pip install stanforecorenlp -i http://pypi.mirrors.ustc.edu.cn/simple/ --trusted-host pypi.mirrors.ustc.edu.cn
- 再次,下载StanfordCoreNlp文件,下载好后解压,解压位置可以根据你自己的喜好选择,如D:\stanford_nlp;
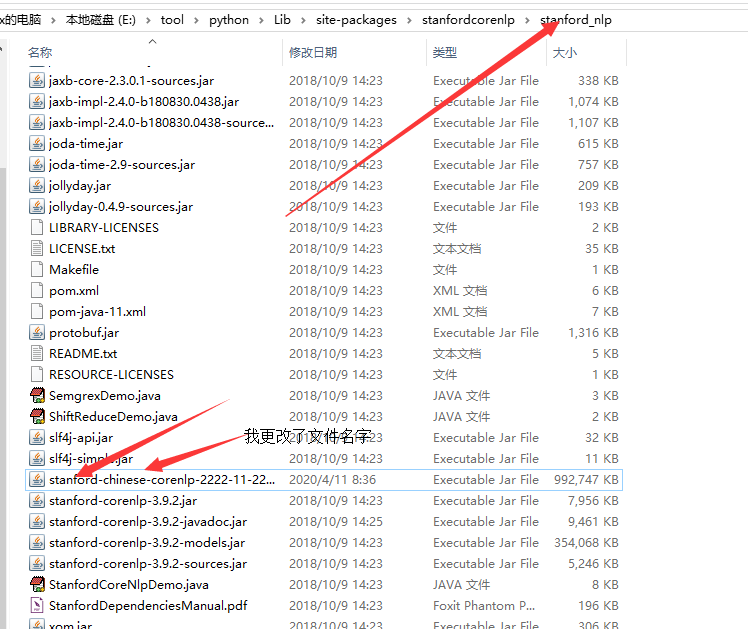
- 接着,下载中文模型,并将下载好的文件放到StanfordCoreNlp解压后的根目录文件夹中,如下图:
- 最后,在python中导入stanford corenlp,导入成功,即可成功使用。
3、问题汇总
(1)安装jdk 1.8版本以上是个比较大的难题,文中提供的安装教程写的很好,可以照着他的安装教程一步步安装,大概率不会出错。
(2)成功安装Stanford coreNlp,但是import stanfore corenlp失败,出现:importerror-no-module-named-psutil,
解决方法:重新安装psutil,选择不同的版本,如pip install psutil==4.0.0 ,然后再导入stanford corenlp。
(3)中文包已经放到StanfordCoreNlp解压的目录下,但是运行程序还是无法识别出中文模型,出现:OSError: stanford-chinese-corenlp-yyyy-MM-dd-models.jar not exists.
解决方法:有点无赖,将中文模型的名字修改,如上图我做的修改,很随别的改了一个时间。你也可以根据我上面的格式更改中文模型名称。注意只能更改时间,其它不改变。

4、stanfordcorenlp的简单使用
# -*- coding:utf-8 -*-
#导入StandfordCoreNLP模块
from stanfordcorenlp import StanfordCoreNLP
#导入中文语言包,lang='zh'
nlp = StanfordCoreNLP(r'E:\tool\python\Lib\site-packages\stanfordcorenlp\stanford_nlp', lang='zh')
sentence = '江西财经大学在南昌,是一所有着很强的综合能力的大学,大明王在这里读书,学习大数据会计,正在做自然语言处理作业'
word = nlp.word_tokenize(sentence)
print('\t '.join(word))
print(nlp.pos_tag(sentence))
print(nlp.ner(sentence))
print(nlp.parse(sentence))
print(nlp.dependency_parse(sentence))
运行结果:
"E:\学习笔记\Python学习\python 代码\07\venv\Scripts\python.exe" "E:/学习笔记/NLP学习/NLP code/stanfordcorenlp_test/test.py"
江西 财经 大学 在 南昌 , 是 一 所 有 着 很 强 的 综合 能力 的 大学 , 大明 王 在 这里 读书 , 学习 大 数据 会计 , 正在 做 自然 语言 处理 作业
[('江西', 'NR'), ('财经', 'NN'), ('大学', 'NN'), ('在', 'P'), ('南昌', 'NR'), (',', 'PU'), ('是', 'VC'), ('一', 'CD'), ('所', 'M'), ('有', 'VE'), ('着', 'AS'), ('很', 'AD'), ('强', 'VA'), ('的', 'DEC'), ('综合', 'NN'), ('能力', 'NN'), ('的', 'DEG'), ('大学', 'NN'), (',', 'PU'), ('大明', 'JJ'), ('王', 'NN'), ('在', 'P'), ('这里', 'PN'), ('读书', 'VV'), (',', 'PU'), ('学习', 'VV'), ('大', 'JJ'), ('数据', 'NN'), ('会计', 'NN'), (',', 'PU'), ('正在', 'AD'), ('做', 'VV'), ('自然', 'NN'), ('语言', 'NN'), ('处理', 'NN'), ('作业', 'NN')]
[('江西', 'STATE_OR_PROVINCE'), ('财经', 'O'), ('大学', 'O'), ('在', 'O'), ('南昌', 'CITY'), (',', 'O'), ('是', 'O'), ('一', 'NUMBER'), ('所', 'O'), ('有', 'O'), ('着', 'O'), ('很', 'O'), ('强', 'O'), ('的', 'O'), ('综合', 'O'), ('能力', 'O'), ('的', 'O'), ('大学', 'O'), (',', 'O'), ('大明', 'PERSON'), ('王', 'PERSON'), ('在', 'O'), ('这里', 'O'), ('读书', 'O'), (',', 'O'), ('学习', 'O'), ('大', 'O'), ('数据', 'O'), ('会计', 'TITLE'), (',', 'O'), ('正在', 'O'), ('做', 'O'), ('自然', 'O'), ('语言', 'O'), ('处理', 'O'), ('作业', 'O')]
(ROOT
(IP
(NP (NR 江西) (NN 财经) (NN 大学))
(VP
(VP
(VP
(PP (P 在)
(NP (NR 南昌)))
(PU ,)
(VP (VC 是)
(NP
(QP (CD 一)
(CLP (M 所)))
(CP
(IP
(VP (VE 有) (AS 着)
(NP
(CP
(IP
(VP
(ADVP (AD 很))
(VP (VA 强))))
(DEC 的))
(NP (NN 综合) (NN 能力)))))
(DEG 的))
(NP (NN 大学)))))
(PU ,)
(IP
(NP
(ADJP (JJ 大明))
(NP (NN 王)))
(VP
(VP
(PP (P 在)
(NP (PN 这里)))
(VP (VV 读书)))
(PU ,)
(VP (VV 学习)
(NP
(NP
(ADJP (JJ 大))
(NP (NN 数据)))
(NP (NN 会计)))))))
(PU ,)
(VP
(ADVP (AD 正在))
(VP (VV 做)
(NP (NN 自然) (NN 语言) (NN 处理) (NN 作业)))))))
[('ROOT', 0, 18), ('compound:nn', 3, 1), ('compound:nn', 3, 2), ('nsubj', 18, 3), ('case', 5, 4), ('nmod:prep', 18, 5), ('punct', 18, 6), ('cop', 18, 7), ('nummod', 18, 8), ('mark:clf', 8, 9), ('dep', 18, 10), ('aux:asp', 10, 11), ('advmod', 13, 12), ('amod', 16, 13), ('mark', 13, 14), ('compound:nn', 16, 15), ('dobj', 10, 16), ('mark', 10, 17), ('punct', 18, 19), ('amod', 21, 20), ('nsubj', 24, 21), ('case', 23, 22), ('nmod:prep', 24, 23), ('conj', 18, 24), ('punct', 24, 25), ('conj', 24, 26), ('amod', 28, 27), ('compound:nn', 29, 28), ('dobj', 26, 29), ('punct', 24, 30), ('advmod', 32, 31), ('conj', 24, 32), ('compound:nn', 35, 33), ('compound:nn', 35, 34), ('compound:nn', 36, 35), ('dobj', 32, 36)] Process finished with exit code 0
stanfordcorenlp安装教程&问题汇总(importerror-no-module-named-psutil、OSError: stanford-chinese-corenlp-yyyy-MM-dd-models.jar not exists.)&简单使用教程的更多相关文章
- Python安装模块出错(ImportError: No module named setuptools)解决方法
原地址:http://www.cnblogs.com/BeginMan/archive/2013/05/28/3104928.html 在window平台下安装第三方模块时,出现这样的错误:
- pytorch1.0 安装执行后报错ImportError: No module named future.utils
File "/usr/local/lib/python2.7/dist-packages/caffe2/python/utils.py", line 10, in <modu ...
- python 安装 reportlab 报错 “ImportError: No module named reportlab.lib”
reportlab是什么? 是一个处理PDF和画图的python开源库. 初次安装: pip install reportlab 重新安装: pip install --upgrade --force ...
- 安装 chardet ,出现ImportError: No module named setuptools
原因:在linux的机子上没有setuptools 可能此机子上的python版本过低 http://www.cnblogs.com/kkgreen/archive/2012/08/02/262042 ...
- ubuntu ImportError: No module named setuptools 一句命令解决方案
https://blog.csdn.net/Super_jm_/article/details/81947563 使用pip安装文件时候提示 ImportError: No module named ...
- 关于win系统下Anaconda与TensorFlow的安装相关事宜以及错误:ImportError: No module named 'tensorflow'的解决
1.安装TensorFlow之前应该先安装Anaconda,不需要安装python,否则会出问题,我安装的版本是Anaconda3-4.2.0-Windows-x86_64,在这个链接上可以找到--h ...
- linux上安装完torch后仍报错:ImportError: No module named torch
linux上安装完torch后仍报错: Traceback (most recent call last): File , in <module> import torch ImportE ...
- 【python】已安装模块提示ImportError: No module named
今天遇到了一个问题,运行代码时出现错误 Traceback (most recent call last): File , in <module> import zmq ImportErr ...
- python安装提示ImportError: No module named web
今天在开发一个项目时出现错误,重新安装了一下python和yum,然后面板就无法启动了,提示需要安装web依赖,但是具体是哪个web源呢,pip install web不行 Traceback (mo ...
- caffe安装编译问题-ImportError: No module named skimage.io
问题描述 >>> import caffe Traceback (most recent call last): File , in <module> File , in ...
随机推荐
- Python处理HTTP返回包遇到问题总结TypeError、keyError、SyntaxError、AttributeError
处理HTTP返回包包括对关键参数的校验,参数完整性检验,获取返回包参数的方法,返回包数据去重方法 在执行时遇到不少问题,部分问题记录如下: 1.报错信息:“TypeError: list indice ...
- Rescue BFS+优先队列 杭电1242
思路 : 优先队列 每次都取最小的时间,遇到了终点直接就输出 #include<iostream> #include<queue> #include<cstring> ...
- Python生成一维码
参考页面 https://pypi.org/project/python-barcode/ 利用python-barcode的库 一.安装python-barcode库 #安装前提条件库 pip in ...
- 6. webRTC
webrtc网上封装的很多,demo很多都是一个页面里实现的,今天实现了个完整的 , A 发视频给 B. 1.) A 方 <!DOCTYPE html> <html id=" ...
- 使用 PyHamcrest 执行健壮的单元测试
在 测试金字塔 的底部是单元测试.单元测试每次只测试一个代码单元,通常是一个函数或方法. 通常,设计单个单元测试是为了测试通过一个函数或特定分支的特定执行流程,这使得将失败的单元测试和导致失败的 bu ...
- jquery动态live绑定toggle事件
$(".btn").live("click",function(){ $(this).toggle( function () { //事件 1 console. ...
- 是时候学习python了
“ 学习Pyhton,如何学以致用 -- 知识往问题靠,问题往知识靠” 01 为什么学Python 一直有听说Python神奇,总是想学,虽然不知道为啥.奈何每天写bug,修bug忙得不亦乐乎,总是不 ...
- 总结php删除html标签和标签内的内容的方法
来源:https://www.cnblogs.com/shaoguan/p/7336984.html 经常扒别人网站文章的坑们:我是指那种批量式采集的压根不看内容的:少不了都会用到删除html标签的函 ...
- PHP面向对象之重写与重载
/*** ====笔记部分==== 重写/覆盖 override 指:子类重写了父类的同名方法 重载: overload 重载是指:存在多个同名方法,但参数类型/个数不同. 传不同的参数,调用不同的方 ...
- PHP Ajax 跨域问题解决方案
本文通过设置Access-Control-Allow-Origin来实现跨域. 例如:客户端的域名是client.0751.tv,而请求的域名是server.0751.tv. 如果直接使用ajax访问 ...