Python爬虫---爬取腾讯动漫全站漫画
操作环境
- 编译器:pycharm社区版
- python 版本:anaconda python3.7.4
- 浏览器选择:Google浏览器
- 需要用到的第三方模块:requests , lxml , selenium , time , bs4,os
网页分析
明确目标
首先我们打开腾讯动漫首页,分析要抓取的目标漫画。
找到腾讯动漫的漫画目录页,简单看了一下目录,发现全站的漫画数量超过了三千部(感觉就是爬下来也会把内存撑爆)
于是我觉得爬取首页的推荐漫画会是一个比较好的选择(爬取全站漫画只需要稍稍改一下网址构造就可以做到了)
提取漫画地址
选定了对象之后,就应该想办法来搞到漫画的地址了
右击检查元素,粗略看一遍网页的源代码,这时我发现里面有很多连续的

随便打开一个《li》标签,点击里面包裹的链接地址会跳转到一个新的网页,这个网页正是我想要找的漫画地址,可以见得我的猜测是正确的,等到实际操作的时候再用表达式提取信息就非常容易了
提取漫画章节地址
进入漫画的目录页,发现一页最多可以展示20章的漫画目录,要想更换显示还需要点击章节名上面的选项卡来显示其他章节的地址
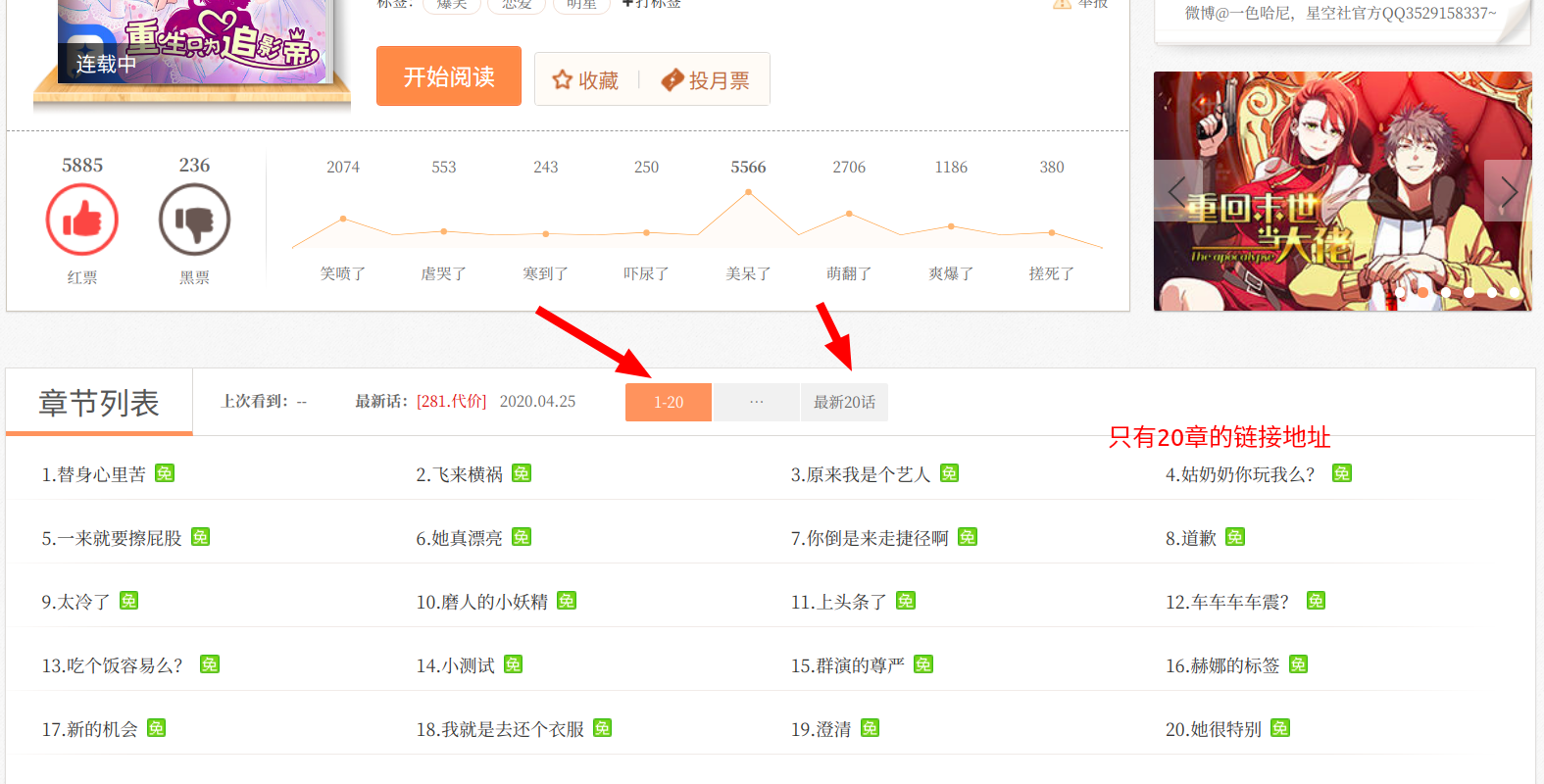
接下来就需要我们来检查网页元素想办法来获取章节地址了,同样右击检查元素
在看到了源代码后,我发现了一个非常惊喜的事情,这个源码里面包含这所有的章节链接,而不是通过动态加载来展示的,这就省去了我们提取其他章节链接的功夫,只需要花心思提取漫画图片就可以了
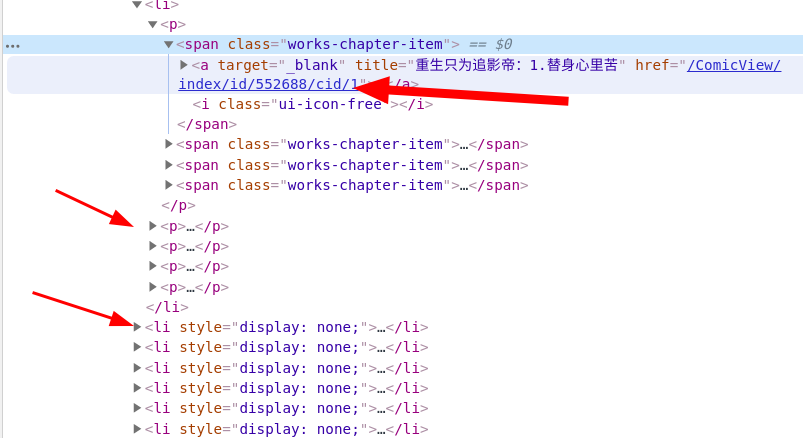
这里每个《p》标签下包含了五个《a》标签,每个《li》标签下包含了四个《p》标签,而每个漫画的链接就存在每个《a》标签中,可以轻松通过语法来提取到每页的链接信息
提取漫画图片
怎么将漫画的图片地址提取出来并保存到本地,这是这个代码的难点和核心
先是打开漫画,这个漫画页应该是被加上了某些措施,所以它没办法使用右键查看网页源代码,但是使用快捷键[ctrl + shift +i]是可以看到的
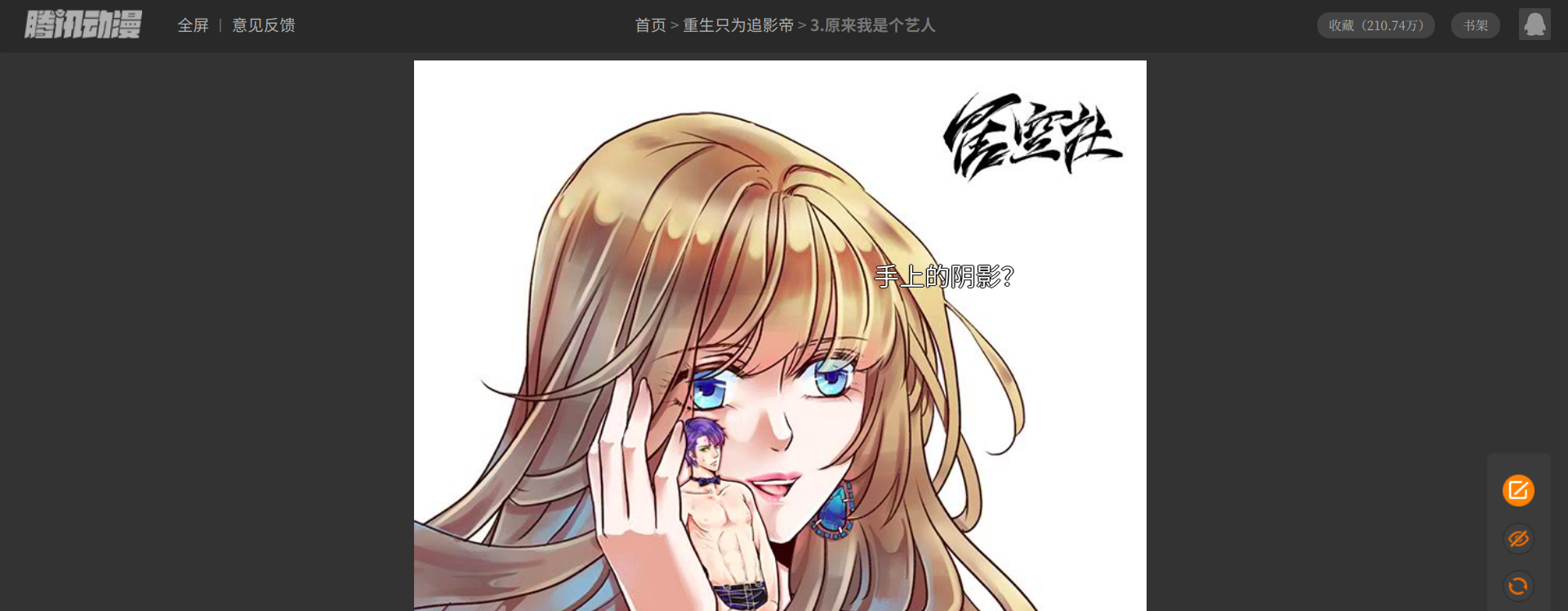
按下[ctrl + shift + i],检查元素

通过第一次检查,可以发现网页的元素中只有前几张图片的地址信息,后面的信息都为后缀.gif的文件表示,这些gif文件就是图片的加载动画
接着向下滑动到底部,等待图片全部显示出来再次检查元素
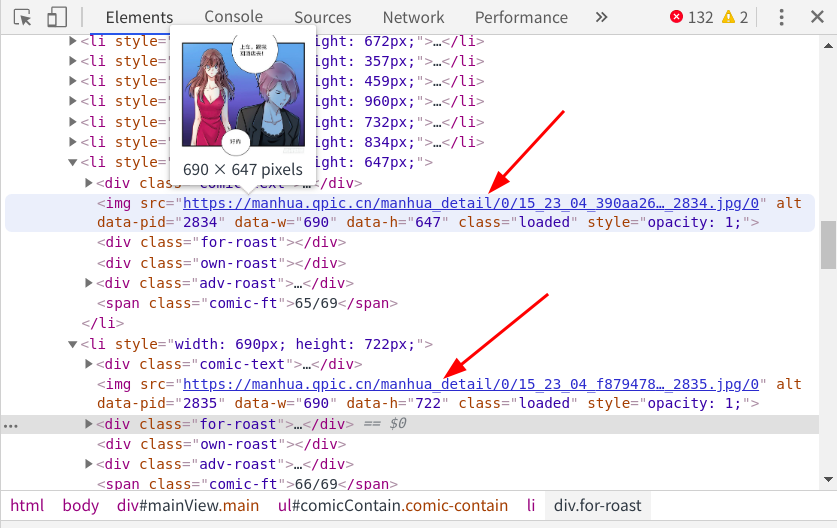
现在所有的漫画图片全部显示出来,下方并无.gif 的文件,由此可知,腾讯动漫是以js异步加载来显示图片的,要想获取页面的全部图片,就必须要滑动滚动条,将全部的图片加载完成再进行提取,这里我选择selenium模块和chromedriver来帮助我完成这些操作。下面开始进行代码的编写。
编写代码
导入需要的模块
import requests
from lxml import etree
from selenium import webdriver #selenium模拟操作
from time import sleep
from bs4 import BeautifulSoup
from selenium.webdriver.chrome.options import Options #谷歌无头浏览器
import os
获取漫画地址
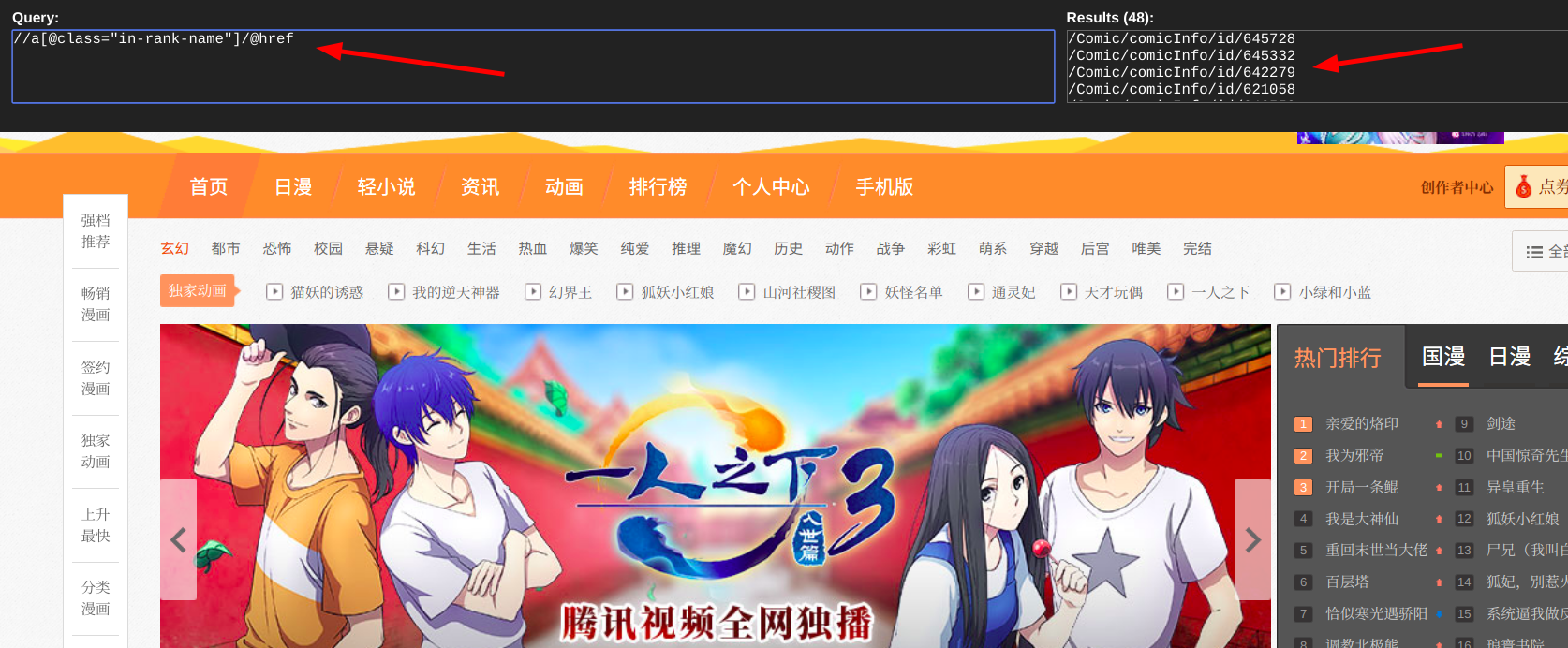
这里我使用的是xpath提取漫画地址信息,在谷歌浏览器中使用xpath helper插件辅助编写xpath表达式
#打开腾讯动漫首页
url = 'https://ac.qq.com/'
#给网页发送请求
data = requests.get(url).text
#将网页信息转换成xpath可识别的类型
html = etree.HTML(data)
#提取到每个漫画的目录页地址
comic_list = html.xpath('//a[@class="in-rank-name"]/@href')
print(comic_list)
print一下输出的comic_list,提取成功

提取漫画的内容页
内容页的提取也很简单,就像上面的分析一样,使用简单的xpath语法即可提取

然后我们再将漫画的名字提取出来,方便为保存的文件夹命名
#遍历提取到的信息
for comic in comic_list:
#拼接成为漫画目录页的网址
comic_url = url + str(comic)
#从漫画目录页提取信息
url_data = requests.get(comic_url).text
#准备用xpath语法提取信息
data_comic = etree.HTML(url_data)
#提取漫画名--text()为提取文本内容
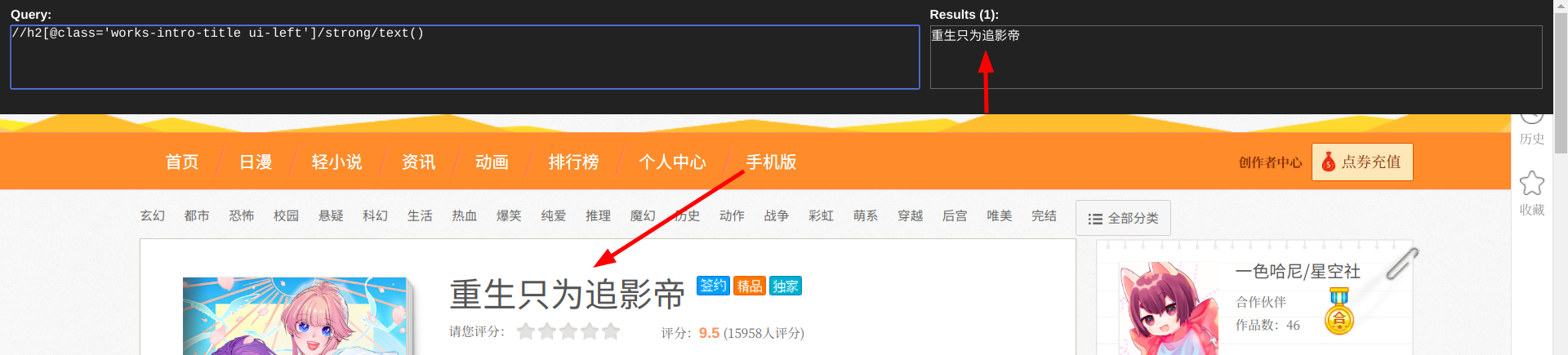
name_comic = data_comic.xpath("//h2[@class='works-intro-title ui-left']/strong/text()")
#提取该漫画每一页的地址
item_list = data_comic.xpath("//span[@class='works-chapter-item']/a/@href")
print(name_comic)
print(item_list)
print打印的信息:

提取章节名
刚刚我们输出的是漫画页的地址字段,但是通过这些字段并不能请求到信息,还需在前面加上域名才可以构成一个完整的网址
提取章节名是为了在漫画名的文件夹下再为每个章节创建一个文件夹保存漫画图片
for item in item_list:
#拼接每一章节的地址
item_url = url + str(item)
#print(item_url)
#请求每一章节的信息
page_mes = requests.get(item_url).text
#准备使用xpath提取内容
page_ming = etree.HTML(page_mes)
#提取章节名
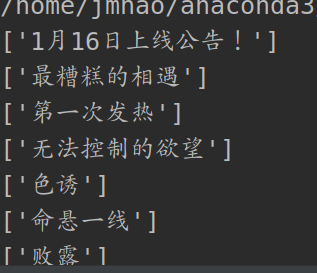
page_name = page_ming.xpath('//span[@class="title-comicHeading"]/text()')
print(page_name)
打印章节名:
获取漫画源网页代码
这个部分的代码是这个代码的核心部分,也是花费时间最久的部分
首先我们知道通过正常的方式没有办法请求到所有的图片地址信息,若是使用抓包方法会变得非常难分析,所以我采用的是模拟浏览器滑动的方法来获得图片的地址信息
为了方便看到结果,先将webdriver设置为有界面模式,等到实现想要的功能之后,再将它隐藏起来
#webdriver位置
path = r'/home/jmhao/chromedriver'
#浏览器参数设置
browser = webdriver.Chrome(executable_path=path)
#开始请求第一个章节的网址
browser.get(item_url)
#设置延时,为后续做缓冲
sleep(2)
#尝试执行下列代码
try:
#设置自动下滑滚动条操作
for i in range(1, 100):
#滑动距离设置
js = 'var q=document.getElementById("mainView").scrollTop = ' + str(i * 1000)
#执行滑动选项
browser.execute_script(js)
#延时,使图片充分加载
sleep(2)
sleep(2)
#将打开的界面截图保存,证明无界面浏览器确实打开了网页
browser.get_screenshot_as_file(str(page_name) + ".png")
#获取当前页面源码
data = browser.page_source
#在当前文件夹下创建html文件,并将网页源码写入
fh = open("dongman.html", "w", encoding="utf-8")
#写入操作
fh.write(data)
#关掉浏览器
fh.close()
# 若上述代码执行报错(大概率是由于付费漫画),则执行此部分代码
except Exception as err:
#跳过错误代码
pass
运行之后会自动打开漫画的内容页,并拖动右侧的滑动条(模拟了手动操作,缓慢拖动是为了让图片充分加载),其中的sleep方法和网速有一定的关系,网速好的可以适当减少延时的时间,网速差可适当延长
在写拖动滑动条的代码时,我尝试了非常多种拖动写法,也模拟了按下方向键的操作,可是只有这一种方法使用成功了。我认为失败的原因可能是刚打开界面的时候会有一个导航条挡住滑块,导致无法定位到滑块的坐标(因为我用其他网页测试的时候都是可以拖动的)

使用的try是为了防止有一些章节会弹出付费窗口,导致程序报错,使后续无法运行,即遇到会报错的情况就跳过此段代码,执行except中的选项
这段程序运行完之后有一个dongman.html文件保存在当前文件夹下,里面就包含了所有图片的url,接下来只要读取这个文件的内容就可以提取到所有的漫画地址了
下载漫画图片
当我们保存完网页的源代码之后,接下来的操作就变得简单了 我们要做的就是提取文件内容,将图片下载到本地
#用beautifulsoup打开本地文件
html_new = BeautifulSoup(open('dongman.html', encoding='utf-8'), features='html.parser')
#提取html文件中的主体部分
soup = html_new.find(id="mainView")
#设置变量i,方便为保存的图片命名
i = 0
#提取出主体部分中的img标签(因为图片地址保存在img标签中)
for items in soup.find_all("img"):
#提取图片地址信息
item = items.get("src")
#请求图片地址
comic_pic = requests.get(item).content
#print(comic_pic)
#尝试提取图片,若发生错误则跳过
try:
#打开文件夹,将图片存入
with open('comic/' + str(name_comic) + '/' + str(page_name) + '/' + str(i + 1) + '.jpg', 'wb') as f:
#print('正在下载第 ', (i + 1), ' 张图片中')
print('正在下载' , str(name_comic) , '-' , str(page_name) , '- 第' , (i+1) , '张图片')
#写入操作
f.write(comic_pic)
#更改图片名,防止新下载的图片覆盖原图片
i += 1
#若上述代码执行报错,则执行此部分代码
except Exception as err:
#跳过错误代码
pass
下载结果
到了这里代码就写完了,来看一下运行结果:
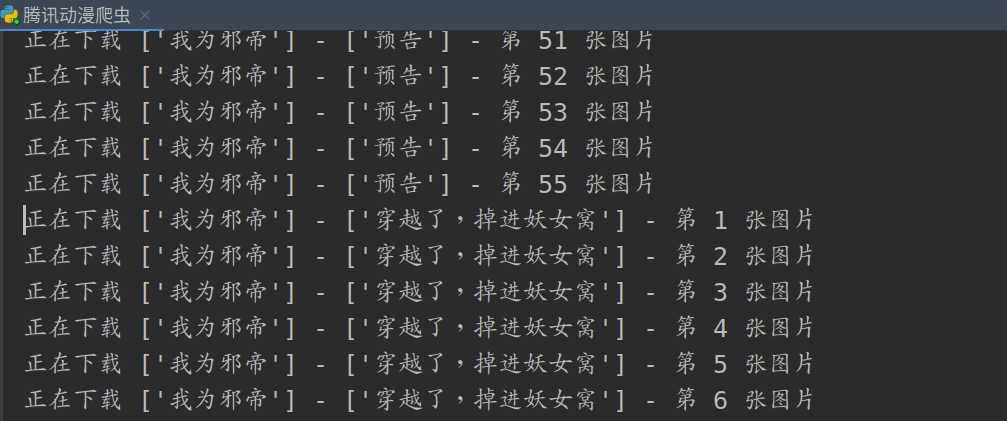
打开文件夹看到:

完整代码
import requests
from lxml import etree
from selenium import webdriver
from time import sleep
from bs4 import BeautifulSoup
from selenium.webdriver.chrome.options import Options
import os
#打开腾讯动漫首页
url = 'https://ac.qq.com/'
#给网页发送请求
data = requests.get(url).text
#将网页信息转换成xpath可识别的类型
html = etree.HTML(data)
#提取到每个漫画的目录页地址
comic_list = html.xpath('//a[@class="in-rank-name"]/@href')
#print(comic_list)
#遍历提取到的信息
for comic in comic_list:
#拼接成为漫画目录页的网址
comic_url = url + str(comic)
#从漫画目录页提取信息
url_data = requests.get(comic_url).text
#准备用xpath语法提取信息
data_comic = etree.HTML(url_data)
#提取漫画名--text()为提取文本内容
name_comic = data_comic.xpath("//h2[@class='works-intro-title ui-left']/strong/text()")
#提取该漫画每一页的地址
item_list = data_comic.xpath("//span[@class='works-chapter-item']/a/@href")
# print(name_comic)
# print(item_list)
#以漫画名字为文件夹名创建文件夹
os.makedirs('comic/' + str(name_comic))
#将一本漫画的每一章地址遍历
for item in item_list:
#拼接每一章节的地址
item_url = url + str(item)
#print(item_url)
#请求每一章节的信息
page_mes = requests.get(item_url).text
#准备使用xpath提取内容
page_ming = etree.HTML(page_mes)
#提取章节名
page_name = page_ming.xpath('//span[@class="title-comicHeading"]/text()')
#print(page_name)
#再以章节名命名一个文件夹
os.makedirs('comic/' + str(name_comic) + '/' + str(page_name))
#以下为代码的主体部分
#设置谷歌无界面浏览器
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
#webdriver位置
path = r'/home/jmhao/chromedriver'
#浏览器参数设置
browser = webdriver.Chrome(executable_path=path, options=chrome_options)
#开始请求第一个章节的网址
browser.get(item_url)
#设置延时,为后续做缓冲
sleep(2)
#browser.get_screenshot_as_file(str(page_name) + ".png")
#尝试执行下列代码
try:
#设置自动下滑滚动条操作
for i in range(1, 100):
#滑动距离设置
js = 'var q=document.getElementById("mainView").scrollTop = ' + str(i * 1000)
#执行滑动选项
browser.execute_script(js)
#延时,使图片充分加载
sleep(2)
sleep(2)
#将打开的界面截图保存,证明无界面浏览器确实打开了网页
browser.get_screenshot_as_file(str(page_name) + ".png")
#获取当前页面源码
data = browser.page_source
#在当前文件夹下创建html文件,并将网页源码写入
fh = open("dongman.html", "w", encoding="utf-8")
#写入操作
fh.write(data)
#关掉无界面浏览器
fh.close()
#下面的操作为打开保存的html文件,提取其中的图片信息,并保存到文件夹中
#用beautifulsoup打开本地文件
html_new = BeautifulSoup(open('dongman.html', encoding='utf-8'), features='html.parser')
#提取html文件中的主体部分
soup = html_new.find(id="mainView")
#设置变量i,方便为保存的图片命名
i = 0
#提取出主体部分中的img标签(因为图片地址保存在img标签中)
for items in soup.find_all("img"):
#提取图片地址信息
item = items.get("src")
#请求图片地址
comic_pic = requests.get(item).content
#print(comic_pic)
#尝试提取图片,若发生错误则跳过
try:
#打开文件夹,将图片存入
with open('comic/' + str(name_comic) + '/' + str(page_name) + '/' + str(i + 1) + '.jpg', 'wb') as f:
#print('正在下载第 ', (i + 1), ' 张图片中')
print('正在下载' , str(name_comic) , '-' , str(page_name) , '- 第' , (i+1) , '张图片')
#写入操作
f.write(comic_pic)
#更改图片名,防止新下载的图片覆盖原图片
i += 1
#若上述代码执行报错,则执行此部分代码
except Exception as err:
#跳过错误代码
pass
# 若上述代码执行报错(大概率是由于付费漫画),则执行此部分代码
except Exception as err:
#跳过错误代码
pass
github:https://github.com/jjjjmhao/Sprider/commit/16d15a34d722f3c50060f9f3015c9ff577deb05a
Python爬虫---爬取腾讯动漫全站漫画的更多相关文章
- python爬虫爬取腾讯招聘信息 (静态爬虫)
环境: windows7,python3.4 代码:(亲测可正常执行) import requests from bs4 import BeautifulSoup from math import c ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
随机推荐
- iOS 缩小 ipa 大小
一.爱奇艺 爱奇艺移动应用优化之路:如何让崩溃率小于千分之二 iOS8 对于 App 的 text 段有 60MB 的限制: 超过 200MB 的 App 需要连接 WIFI 下载(之前是 150MB ...
- +load 和 +initialize
APP 启动到执行 main 函数之前,程序就执行了很多代码. 执行顺序: 将程序依赖的动态链接库加载到内存 加载可执行文件中的所有符号,代码 runtime 解析被编译的符号代码 遍历所有的 cla ...
- 基于.NetCore3.1搭建项目系列 —— 使用Swagger导出文档 (番外篇)
前言 回顾之前的两篇Swagger做Api接口文档,我们大体上学会了如何在net core3.1的项目基础上,搭建一套自动生产API接口说明文档的框架. 本来在Swagger的基础上,前后端开发人员在 ...
- cut-trailing-bytes:二进制尾部去0小工具
背景 之前的文章 二进制文件处理之尾部补0和尾部去0 中介绍了一种使用 sed 去除二进制文件尾部的 NULL(十六进制0x00)字节的方法. 最近发现这种方法有局限性,无法处理较大的文件.因为 se ...
- Python常用模块之模块的使用
一 模块介绍 1.什么是模块? #常见的场景:一个模块就是一个包含了一组功能的python文件,比如spam.py,模块名为spam,可以通过import spam使用. #在python中,模块 ...
- 解决Python pip安装第三方包慢的问题
解决Python pip安装第三方包慢的问题 主要是修改源,国内的源有几个 阿里云 http://mirrors.aliyun.com/pypi/simple/ 中国科技大学 https://pypi ...
- L - Subway(最短路spfa)
L - Subway(最短路spfa) You have just moved from a quiet Waterloo neighbourhood to a big, noisy city. In ...
- Spring Boot 完整讲解
SpringBoot学习笔记 文章写得比较详细,所以很长(105336 字数),可以参考目录 文章目录 SpringBoot学习笔记 @[toc] 一. Spring Boot 入门 预:必须掌握的技 ...
- 小白快速使用fetch与后端交互
本人专心后端,但在完成页面碰到了交互,选择了fetch来完成, 总结了一下简单的使用fetch的方法. fetch是纯原生JS与后端交互的方法,请注意,Fetch规格不同于jQuery.ajax(), ...
- 用命令在本地创建github仓库
问题 每次创建github仓库,都要到github官网,有点麻烦,想在本地直接创建github仓库,写好项目后直接push. 操作系统:linux 步骤 1, 首先在github申请一个私人api t ...