2019-2020-1 20199326《Linux内核原理与分析》第九周作业
进程的切换和系统的一般执行过程
中断
中断在本质上都是软件或者硬件发生了某种情形而通知处理器的行为,处理器进而停止正在运行的指令流(当前进程),对这些通知做出相应反应,即转去执行预定义的中断处理程序(内核代码)。
中断分为硬中断和软中断。
硬中断就是CPU的两根引脚(可屏蔽中断和不可屏蔽中断),CPU在执行每条指令后会检测这两根引脚的电平,如果是高电平,说明有中断请求,CPU就会中断当前程序的执行去处理中断。
软中断包括除零错误,系统调用、调试断点等在CPU执行指令过程中发生的各种特殊情况统称为异常。异常一般分为3种,故障,退出,陷阱。区别是故障可以恢复到当前指令,退出是不可恢复的严重故障,陷阱是程序主动产生的异常,例如int 0x80。
进程调度的时机
linux内核通过schedule函数实现进程调度,schedule函数在运行队列中找到一个进程,把CPU分配给它。调用schedule函数一次就是调度一次。调用schedule函数的时候就是进程调度的时机。
调用schedule函数有两种方法:
- 进程主动调用schedule()
- 松散调用
进程调度时机如下:
- 用户进程通过特定的系统调用主动让出CPU
- 中断处理程序在内核返回用户态时进行调度
- 内核线程主动调用schedule函数让出CPU
- 中断处理程序主动调用schedule函数让出CPU,涵盖第一和第二种情况
Linux内核中没有操作系统中定义的线程概念,从内核角度看,不管是进程还是内核线程都对应一个task_struct数据结构,本质上都是进程,linux系统在用户态实现的线程库pthread是通过在内核中多个进程共享一个地址空间实现的。
一般来说,cpu在任何时刻都处于以下3种情况之一:
- 运行于用户空间,执行用户进程上下文
- 运行于内核空间,处于进程(一般是内核线程)上下文
- 运行于内核空间,处于中断上下文。
内核线程以进程上下文的形式运行在内核空间中,本质上还是进程,但是它还有调用内核代码的权限,比如主动调用schedule函数让出cpu等
调度策略与算法
调度策略要考虑这个算法的整体目标,是追求资源利用率最高还是追求响应最及时,或是其他的一些目标,然后找到对应的方法或机制作为对策,这就是调度策略。
调度算法就是从就绪队列中选取一个进程,考虑如何实现调度策略并满足设定的目标
进程的分类1:
I/O消耗型进程
处理器消耗型进程
进程的分类2:
交互式进程
批处理进程
实时进程
调度策略:
#define SCHED_NORMAL 0 //普通进程 使用CFS调度管理程序
#define SCHED_FIFO 1//实时进程 优先级高于第一个
#define SCHED_RR 2 //实时进程 优先级高于第一个
#define SCHED_BATCH 3//保留,未实现
#define SCHED——IDLE 5//idle进程
内核中根据进程的优先级来区分普通进程与实时进程,Linux内核进程优先级为0-139,数值越高,优先级越低,0位最高优先级,实时进程的优先级取值为0-99,而普通进程只有nice值,范围为100-139,子进程会继承父进程的优先级
CFS调度算法:
CFS即为完全公平调度算法,其基本原理是基于权重的动态优先级调度算法。每个进程使用CPU的顺序由进程已使用的CPU虚拟时间(vruntime)决定,已使用的虚拟时间越少,进程排序越靠前,进程在此被调度执行的概率也就越高。
进程上下文切换
为了控制进程的执行,内核必须有能力挂起正在CPU中运行的进程,并恢复执行以前挂起的某个进程,这种行为被称为进程切换、任务切换或进程上下文切换。
进程上下文包含了进程执行需要的所有信息
- 用户地址空间
- 控制信息
- 硬件上下文
- CR3寄存器
- ESP寄存器
- EIP寄存器及其他寄存器
linux操作系统内核为用户提供的服务:
- 通过系统调用的形式为进程提供各种服务
- 通过异常处理程序与中断服务程序为硬件的正常工作提供各种服务
- 通过内核线程为系统提供动态的维护服务和中断服务中可延时处理的任务
linux系统的一般执行过程##
情景:正在运行的用户态进程X切换到用户态进程Y的过程
- 正在运行的用户态进程X
- 发生中断(包括异常、系统调用等),硬件完成以下动作
- save cs:eip/ss:esp/eflags:当前CPU上下文压入用户态进程X的内核堆栈
- load cs:eip and ss:esp 加载当前进程内核堆栈相关信息,跳转到中断处理程序,即中断执行路径的起点。
- SAVE_ALL 保存现场,此时完成了中断上下文切换,即从进程X的用户态到进程X的内核态
- 中断处理过程中或中断返回前调用了schedule函数,其中的switch_to做了关键的进程上下文切换
- $1f后开始运行用户态进程Y
- restore_all 恢复现场
- iret-pop cs:eip/ss:esp/eflags从Y进程的内核堆栈中弹出2中硬件完成的压栈内容
- 继续运行用户态进程Y
Linux操作系统的整体构架##
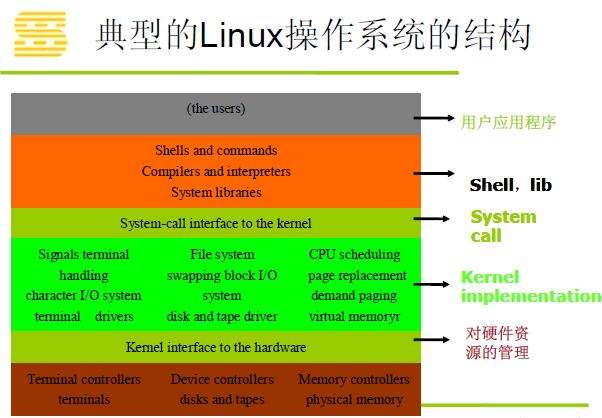
实验:进程调度相关源代码跟踪和分析##
概述:本次实验是使用gdb跟踪分析schedule函数,总共设置了4个断点,schedule,context_switch,switch_to,pick_next_task.
大致逻辑是,要发生进程调度时,首先会调用schedule函数,而schedule函数里有一个pick_next_task函数,字面意思是选择下一个进程,该函数负责根据调度策略和调度算法选择下一个进程,而context_switch函数也属于schedule函数,该函数用于实现进程切换,switch_to则属于context_switch函数,进行进程关键上下文切换。调试截图如下。
schedule

pick_next_task

context_switch

markdown_highlight();
var allowComments = true, cb_blogId = 543336, cb_blogApp = 'funmary', cb_blogUserGuid = '11b250a3-b7b2-4a70-c8c6-08d73591183a';
var cb_entryId = 11841995, cb_entryCreatedDate = '2019-11-12 18:13', cb_postType = 1;
loadViewCount(cb_entryId);
loadSideColumnAd();
var commentManager = new blogCommentManager();
commentManager.renderComments(0);
var googletag = googletag || {};
googletag.cmd = googletag.cmd || [];
googletag.cmd.push(function () {
googletag.defineSlot("/1090369/C1", [300, 250], "div-gpt-ad-1546353474406-0").addService(googletag.pubads());
googletag.defineSlot("/1090369/C2", [468, 60], "div-gpt-ad-1539008685004-0").addService(googletag.pubads());
googletag.pubads().enableSingleRequest();
googletag.enableServices();
});
fixPostBody();
deliverBigBanner();
setTimeout(function() { incrementViewCount(cb_entryId); }, 50); deliverAdT2();
deliverAdC1();
deliverAdC2();
loadNewsAndKb();
loadBlogSignature();
LoadPostCategoriesTags(cb_blogId, cb_entryId); LoadPostInfoBlock(cb_blogId, cb_entryId, cb_blogApp, cb_blogUserGuid);
GetPrevNextPost(cb_entryId, cb_blogId, cb_entryCreatedDate, cb_postType);
loadOptUnderPost();
GetHistoryToday(cb_blogId, cb_blogApp, cb_entryCreatedDate);
中断在本质上都是软件或者硬件发生了某种情形而通知处理器的行为,处理器进而停止正在运行的指令流(当前进程),对这些通知做出相应反应,即转去执行预定义的中断处理程序(内核代码)。
中断分为硬中断和软中断。
硬中断就是CPU的两根引脚(可屏蔽中断和不可屏蔽中断),CPU在执行每条指令后会检测这两根引脚的电平,如果是高电平,说明有中断请求,CPU就会中断当前程序的执行去处理中断。
软中断包括除零错误,系统调用、调试断点等在CPU执行指令过程中发生的各种特殊情况统称为异常。异常一般分为3种,故障,退出,陷阱。区别是故障可以恢复到当前指令,退出是不可恢复的严重故障,陷阱是程序主动产生的异常,例如int 0x80。
进程调度的时机
linux内核通过schedule函数实现进程调度,schedule函数在运行队列中找到一个进程,把CPU分配给它。调用schedule函数一次就是调度一次。调用schedule函数的时候就是进程调度的时机。
调用schedule函数有两种方法:
- 进程主动调用schedule()
- 松散调用
进程调度时机如下:
- 用户进程通过特定的系统调用主动让出CPU
- 中断处理程序在内核返回用户态时进行调度
- 内核线程主动调用schedule函数让出CPU
- 中断处理程序主动调用schedule函数让出CPU,涵盖第一和第二种情况
Linux内核中没有操作系统中定义的线程概念,从内核角度看,不管是进程还是内核线程都对应一个task_struct数据结构,本质上都是进程,linux系统在用户态实现的线程库pthread是通过在内核中多个进程共享一个地址空间实现的。
一般来说,cpu在任何时刻都处于以下3种情况之一:
- 运行于用户空间,执行用户进程上下文
- 运行于内核空间,处于进程(一般是内核线程)上下文
- 运行于内核空间,处于中断上下文。
内核线程以进程上下文的形式运行在内核空间中,本质上还是进程,但是它还有调用内核代码的权限,比如主动调用schedule函数让出cpu等
调度策略与算法
调度策略要考虑这个算法的整体目标,是追求资源利用率最高还是追求响应最及时,或是其他的一些目标,然后找到对应的方法或机制作为对策,这就是调度策略。
调度算法就是从就绪队列中选取一个进程,考虑如何实现调度策略并满足设定的目标
进程的分类1:
I/O消耗型进程
处理器消耗型进程
进程的分类2:
交互式进程
批处理进程
实时进程
调度策略:
#define SCHED_NORMAL 0 //普通进程 使用CFS调度管理程序
#define SCHED_FIFO 1//实时进程 优先级高于第一个
#define SCHED_RR 2 //实时进程 优先级高于第一个
#define SCHED_BATCH 3//保留,未实现
#define SCHED——IDLE 5//idle进程
内核中根据进程的优先级来区分普通进程与实时进程,Linux内核进程优先级为0-139,数值越高,优先级越低,0位最高优先级,实时进程的优先级取值为0-99,而普通进程只有nice值,范围为100-139,子进程会继承父进程的优先级
CFS调度算法:
CFS即为完全公平调度算法,其基本原理是基于权重的动态优先级调度算法。每个进程使用CPU的顺序由进程已使用的CPU虚拟时间(vruntime)决定,已使用的虚拟时间越少,进程排序越靠前,进程在此被调度执行的概率也就越高。
进程上下文切换
为了控制进程的执行,内核必须有能力挂起正在CPU中运行的进程,并恢复执行以前挂起的某个进程,这种行为被称为进程切换、任务切换或进程上下文切换。
进程上下文包含了进程执行需要的所有信息
- 用户地址空间
- 控制信息
- 硬件上下文
- CR3寄存器
- ESP寄存器
- EIP寄存器及其他寄存器
linux操作系统内核为用户提供的服务:
- 通过系统调用的形式为进程提供各种服务
- 通过异常处理程序与中断服务程序为硬件的正常工作提供各种服务
- 通过内核线程为系统提供动态的维护服务和中断服务中可延时处理的任务
linux系统的一般执行过程##
情景:正在运行的用户态进程X切换到用户态进程Y的过程
- 正在运行的用户态进程X
- 发生中断(包括异常、系统调用等),硬件完成以下动作
- save cs:eip/ss:esp/eflags:当前CPU上下文压入用户态进程X的内核堆栈
- load cs:eip and ss:esp 加载当前进程内核堆栈相关信息,跳转到中断处理程序,即中断执行路径的起点。
- SAVE_ALL 保存现场,此时完成了中断上下文切换,即从进程X的用户态到进程X的内核态
- 中断处理过程中或中断返回前调用了schedule函数,其中的switch_to做了关键的进程上下文切换
- $1f后开始运行用户态进程Y
- restore_all 恢复现场
- iret-pop cs:eip/ss:esp/eflags从Y进程的内核堆栈中弹出2中硬件完成的压栈内容
- 继续运行用户态进程Y
Linux操作系统的整体构架##
实验:进程调度相关源代码跟踪和分析##
概述:本次实验是使用gdb跟踪分析schedule函数,总共设置了4个断点,schedule,context_switch,switch_to,pick_next_task.
大致逻辑是,要发生进程调度时,首先会调用schedule函数,而schedule函数里有一个pick_next_task函数,字面意思是选择下一个进程,该函数负责根据调度策略和调度算法选择下一个进程,而context_switch函数也属于schedule函数,该函数用于实现进程切换,switch_to则属于context_switch函数,进行进程关键上下文切换。调试截图如下。
schedule
pick_next_task
context_switch
linux内核通过schedule函数实现进程调度,schedule函数在运行队列中找到一个进程,把CPU分配给它。调用schedule函数一次就是调度一次。调用schedule函数的时候就是进程调度的时机。
调用schedule函数有两种方法:
- 进程主动调用schedule()
- 松散调用
进程调度时机如下:
- 用户进程通过特定的系统调用主动让出CPU
- 中断处理程序在内核返回用户态时进行调度
- 内核线程主动调用schedule函数让出CPU
- 中断处理程序主动调用schedule函数让出CPU,涵盖第一和第二种情况
Linux内核中没有操作系统中定义的线程概念,从内核角度看,不管是进程还是内核线程都对应一个task_struct数据结构,本质上都是进程,linux系统在用户态实现的线程库pthread是通过在内核中多个进程共享一个地址空间实现的。
一般来说,cpu在任何时刻都处于以下3种情况之一:
- 运行于用户空间,执行用户进程上下文
- 运行于内核空间,处于进程(一般是内核线程)上下文
- 运行于内核空间,处于中断上下文。
内核线程以进程上下文的形式运行在内核空间中,本质上还是进程,但是它还有调用内核代码的权限,比如主动调用schedule函数让出cpu等
调度策略与算法
调度策略要考虑这个算法的整体目标,是追求资源利用率最高还是追求响应最及时,或是其他的一些目标,然后找到对应的方法或机制作为对策,这就是调度策略。
调度算法就是从就绪队列中选取一个进程,考虑如何实现调度策略并满足设定的目标
进程的分类1:
I/O消耗型进程
处理器消耗型进程
进程的分类2:
交互式进程
批处理进程
实时进程
调度策略:
#define SCHED_NORMAL 0 //普通进程 使用CFS调度管理程序
#define SCHED_FIFO 1//实时进程 优先级高于第一个
#define SCHED_RR 2 //实时进程 优先级高于第一个
#define SCHED_BATCH 3//保留,未实现
#define SCHED——IDLE 5//idle进程
内核中根据进程的优先级来区分普通进程与实时进程,Linux内核进程优先级为0-139,数值越高,优先级越低,0位最高优先级,实时进程的优先级取值为0-99,而普通进程只有nice值,范围为100-139,子进程会继承父进程的优先级
CFS调度算法:
CFS即为完全公平调度算法,其基本原理是基于权重的动态优先级调度算法。每个进程使用CPU的顺序由进程已使用的CPU虚拟时间(vruntime)决定,已使用的虚拟时间越少,进程排序越靠前,进程在此被调度执行的概率也就越高。
进程上下文切换
为了控制进程的执行,内核必须有能力挂起正在CPU中运行的进程,并恢复执行以前挂起的某个进程,这种行为被称为进程切换、任务切换或进程上下文切换。
进程上下文包含了进程执行需要的所有信息
- 用户地址空间
- 控制信息
- 硬件上下文
- CR3寄存器
- ESP寄存器
- EIP寄存器及其他寄存器
linux操作系统内核为用户提供的服务:
- 通过系统调用的形式为进程提供各种服务
- 通过异常处理程序与中断服务程序为硬件的正常工作提供各种服务
- 通过内核线程为系统提供动态的维护服务和中断服务中可延时处理的任务
linux系统的一般执行过程##
情景:正在运行的用户态进程X切换到用户态进程Y的过程
- 正在运行的用户态进程X
- 发生中断(包括异常、系统调用等),硬件完成以下动作
- save cs:eip/ss:esp/eflags:当前CPU上下文压入用户态进程X的内核堆栈
- load cs:eip and ss:esp 加载当前进程内核堆栈相关信息,跳转到中断处理程序,即中断执行路径的起点。
- SAVE_ALL 保存现场,此时完成了中断上下文切换,即从进程X的用户态到进程X的内核态
- 中断处理过程中或中断返回前调用了schedule函数,其中的switch_to做了关键的进程上下文切换
- $1f后开始运行用户态进程Y
- restore_all 恢复现场
- iret-pop cs:eip/ss:esp/eflags从Y进程的内核堆栈中弹出2中硬件完成的压栈内容
- 继续运行用户态进程Y
Linux操作系统的整体构架##
实验:进程调度相关源代码跟踪和分析##
概述:本次实验是使用gdb跟踪分析schedule函数,总共设置了4个断点,schedule,context_switch,switch_to,pick_next_task.
大致逻辑是,要发生进程调度时,首先会调用schedule函数,而schedule函数里有一个pick_next_task函数,字面意思是选择下一个进程,该函数负责根据调度策略和调度算法选择下一个进程,而context_switch函数也属于schedule函数,该函数用于实现进程切换,switch_to则属于context_switch函数,进行进程关键上下文切换。调试截图如下。
schedule
pick_next_task
context_switch
为了控制进程的执行,内核必须有能力挂起正在CPU中运行的进程,并恢复执行以前挂起的某个进程,这种行为被称为进程切换、任务切换或进程上下文切换。
进程上下文包含了进程执行需要的所有信息
- 用户地址空间
- 控制信息
- 硬件上下文
- CR3寄存器
- ESP寄存器
- EIP寄存器及其他寄存器
linux操作系统内核为用户提供的服务:
- 通过系统调用的形式为进程提供各种服务
- 通过异常处理程序与中断服务程序为硬件的正常工作提供各种服务
- 通过内核线程为系统提供动态的维护服务和中断服务中可延时处理的任务
linux系统的一般执行过程##
情景:正在运行的用户态进程X切换到用户态进程Y的过程
- 正在运行的用户态进程X
- 发生中断(包括异常、系统调用等),硬件完成以下动作
- save cs:eip/ss:esp/eflags:当前CPU上下文压入用户态进程X的内核堆栈
- load cs:eip and ss:esp 加载当前进程内核堆栈相关信息,跳转到中断处理程序,即中断执行路径的起点。
- SAVE_ALL 保存现场,此时完成了中断上下文切换,即从进程X的用户态到进程X的内核态
- 中断处理过程中或中断返回前调用了schedule函数,其中的switch_to做了关键的进程上下文切换
- $1f后开始运行用户态进程Y
- restore_all 恢复现场
- iret-pop cs:eip/ss:esp/eflags从Y进程的内核堆栈中弹出2中硬件完成的压栈内容
- 继续运行用户态进程Y
Linux操作系统的整体构架##
实验:进程调度相关源代码跟踪和分析##
概述:本次实验是使用gdb跟踪分析schedule函数,总共设置了4个断点,schedule,context_switch,switch_to,pick_next_task.
大致逻辑是,要发生进程调度时,首先会调用schedule函数,而schedule函数里有一个pick_next_task函数,字面意思是选择下一个进程,该函数负责根据调度策略和调度算法选择下一个进程,而context_switch函数也属于schedule函数,该函数用于实现进程切换,switch_to则属于context_switch函数,进行进程关键上下文切换。调试截图如下。
schedule
pick_next_task
context_switch
情景:正在运行的用户态进程X切换到用户态进程Y的过程
- 正在运行的用户态进程X
- 发生中断(包括异常、系统调用等),硬件完成以下动作
- save cs:eip/ss:esp/eflags:当前CPU上下文压入用户态进程X的内核堆栈
- load cs:eip and ss:esp 加载当前进程内核堆栈相关信息,跳转到中断处理程序,即中断执行路径的起点。
- SAVE_ALL 保存现场,此时完成了中断上下文切换,即从进程X的用户态到进程X的内核态
- 中断处理过程中或中断返回前调用了schedule函数,其中的switch_to做了关键的进程上下文切换
- $1f后开始运行用户态进程Y
- restore_all 恢复现场
- iret-pop cs:eip/ss:esp/eflags从Y进程的内核堆栈中弹出2中硬件完成的压栈内容
- 继续运行用户态进程Y
Linux操作系统的整体构架##
实验:进程调度相关源代码跟踪和分析##
概述:本次实验是使用gdb跟踪分析schedule函数,总共设置了4个断点,schedule,context_switch,switch_to,pick_next_task.
大致逻辑是,要发生进程调度时,首先会调用schedule函数,而schedule函数里有一个pick_next_task函数,字面意思是选择下一个进程,该函数负责根据调度策略和调度算法选择下一个进程,而context_switch函数也属于schedule函数,该函数用于实现进程切换,switch_to则属于context_switch函数,进行进程关键上下文切换。调试截图如下。
schedule
pick_next_task
context_switch
实验:进程调度相关源代码跟踪和分析##
概述:本次实验是使用gdb跟踪分析schedule函数,总共设置了4个断点,schedule,context_switch,switch_to,pick_next_task.
大致逻辑是,要发生进程调度时,首先会调用schedule函数,而schedule函数里有一个pick_next_task函数,字面意思是选择下一个进程,该函数负责根据调度策略和调度算法选择下一个进程,而context_switch函数也属于schedule函数,该函数用于实现进程切换,switch_to则属于context_switch函数,进行进程关键上下文切换。调试截图如下。
schedule
pick_next_task
context_switch
概述:本次实验是使用gdb跟踪分析schedule函数,总共设置了4个断点,schedule,context_switch,switch_to,pick_next_task.
大致逻辑是,要发生进程调度时,首先会调用schedule函数,而schedule函数里有一个pick_next_task函数,字面意思是选择下一个进程,该函数负责根据调度策略和调度算法选择下一个进程,而context_switch函数也属于schedule函数,该函数用于实现进程切换,switch_to则属于context_switch函数,进行进程关键上下文切换。调试截图如下。
schedule
pick_next_task
context_switch
markdown_highlight();
var allowComments = true, cb_blogId = 543336, cb_blogApp = 'funmary', cb_blogUserGuid = '11b250a3-b7b2-4a70-c8c6-08d73591183a';
var cb_entryId = 11841995, cb_entryCreatedDate = '2019-11-12 18:13', cb_postType = 1;
loadViewCount(cb_entryId);
loadSideColumnAd();
var commentManager = new blogCommentManager();
commentManager.renderComments(0);
var googletag = googletag || {};
googletag.cmd = googletag.cmd || [];
googletag.cmd.push(function () {
googletag.defineSlot("/1090369/C1", [300, 250], "div-gpt-ad-1546353474406-0").addService(googletag.pubads());
googletag.defineSlot("/1090369/C2", [468, 60], "div-gpt-ad-1539008685004-0").addService(googletag.pubads());
googletag.pubads().enableSingleRequest();
googletag.enableServices();
});
fixPostBody();
deliverBigBanner();
setTimeout(function() { incrementViewCount(cb_entryId); }, 50); deliverAdT2();
deliverAdC1();
deliverAdC2();
loadNewsAndKb();
loadBlogSignature();
LoadPostCategoriesTags(cb_blogId, cb_entryId); LoadPostInfoBlock(cb_blogId, cb_entryId, cb_blogApp, cb_blogUserGuid);
GetPrevNextPost(cb_entryId, cb_blogId, cb_entryCreatedDate, cb_postType);
loadOptUnderPost();
GetHistoryToday(cb_blogId, cb_blogApp, cb_entryCreatedDate);
2019-2020-1 20199326《Linux内核原理与分析》第九周作业的更多相关文章
- 2019-2020-1 20199303<Linux内核原理与分析>第二周作业
2019-2020-1 20199303第二周作业 1.汇编与寄存器的学习 寄存器是中央处理器内的组成部份.寄存器是有限存贮容量的高速存贮部件,它们可用来暂存指令.数据和位址.在中央处理器的控制部件中 ...
- 20169219 linux内核原理与分析第二周作业
"linux内核分析"的第一讲主要讲了计算机的体系结构,和各寄存器之间对数据的处理过程. 通用寄存器 AX:累加器 BX:基地址寄存器 CX:计数寄存器 DX:数据寄存器 BP:堆 ...
- 2019-2020-1 20199314 <Linux内核原理与分析>第二周作业
1.基础学习内容 1.1 冯诺依曼体系结构 计算机由控制器.运算器.存储器.输入设备.输出设备五部分组成. 1.1.1 冯诺依曼计算机特点 (1)采用存储程序方式,指令和数据不加区别混合存储在同一个存 ...
- Linux内核原理与分析-第一周作业
本科期间,学校开设过linux相关的课程,当时的学习方式主要以课堂听授为主.虽然老师也提供了相关的学习教材跟参考材料,但是整体学下来感觉收获并不是太大,现在回想起来,主要还是由于自己课下没有及时动手实 ...
- 2019-2020-1 20199314 <Linux内核原理与分析>第一周作业
前言 本周对实验楼的Linux基础入门进行了学习,目前学习到实验九完成到挑战二. 学习和实验内容 快速学习了Linux系统的发展历程及其简介,学习了下的变量.用户权限管理.文件打包及压缩.常用命令的和 ...
- Linux内核原理与分析-第二周作业
写之前回看了一遍秒速五厘米:如果
- 2018-2019-1 20189221《Linux内核原理与分析》第一周作业
Linux内核原理与分析 - 第一周作业 实验1 Linux系统简介 Linux历史 1991 年 10 月,Linus Torvalds想在自己的电脑上运行UNIX,可是 UNIX 的商业版本非常昂 ...
- 2020-2021-1 20209307 《Linux内核原理与分析》第九周作业
这个作业属于哪个课程 <2020-2021-1Linux内核原理与分析)> 这个作业要求在哪里 <2020-2021-1Linux内核原理与分析第九周作业> 这个作业的目标 & ...
- 2019-2020-1 20199329《Linux内核原理与分析》第十三周作业
<Linux内核原理与分析>第十三周作业 一.本周内容概述 通过重现缓冲区溢出攻击来理解漏洞 二.本周学习内容 1.实验简介 注意:实验中命令在 xfce 终端中输入,前面有 $ 的内容为 ...
- 2019-2020-1 20199329《Linux内核原理与分析》第十二周作业
<Linux内核原理与分析>第十二周作业 一.本周内容概述: 通过编程理解 Set-UID 的运行机制与安全问题 完成实验楼上的<SET-UID程序漏洞实验> 二.本周学习内容 ...
随机推荐
- 针对Kafka的centos系统参数优化
TCP网络优化 sudo vim /etc/sysctl.conf vm.max_map_count=655360net.core.rmem_default=262144net.core.rmem_m ...
- 面试官:JavaScript 原始数据类型 Symbol 有什么用?
以前提到 JavaScript 原始数据类型时,我们知道有Number,String,Null,Boolean,Undefined这几种.ES6 引入了新的基本数据类型Symbol和BigInt.今天 ...
- Java并发基础07. ThreadLocal类以及应用技巧
在前面的文章(6. 线程范围内共享数据)总结了一下,线程范围内的数据共享问题,即定义一个 Map,将当前线程名称和线程中的数据以键值对的形式存到 Map 中,然后在当前线程中使用数据的时候就可以根据当 ...
- 徒手生撸一个验证框架,API 参数校验不再怕!
你们之中大概率早已练就了代码的拷贝.粘贴,无敌的码农神功,其实做久了业务功能开发,练就这两个无敌神功,那是迟早的事儿.今天先抛一个小问题,来打通你的任督二脉,就是很好奇的问一下:业务功能开发中,输入参 ...
- JS去除字符串内的空白字符方法
有时我们需要对用户的输入进行一些处理,比如用户输入的密码或者用户名我们就需要去除前后空格,下面写一个去除空白字符的方法 function trim(string = '') { return stri ...
- SWUSTOJ 960A题总结,又完成一个讨厌的题,内含链表操作启发
今天debug了一个nice代码,先码在这里,SWUST OJ960 双向链表的操作问题 1000(ms) 10000(kb) 2994 / 8244 建立一个长度为n的带头结点的双向链表,使得该链表 ...
- ssh 解决经常断开与记住密码功能
一.解决ssh经常自动断开问题 修改 /etc/ssh/sshd_config 其中对应项为 ClientAliveInterval 30 ClientAliveCountMax 3 表示每30秒发一 ...
- 多线程之旅(Task 任务)
一.Task(任务)和ThreadPool(线程池)不同 源码 1.线程(Thread)是创建并发工具的底层类,但是在前几篇文章中我们介绍了Thread的特点,和实例.可以很明显发现局限性 ...
- HDU1158:Employment Planning(暴力DP)
Employment Planning Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Othe ...
- SpringMVC(一):简介和第一个程序
本文是按照狂神说的教学视频学习的笔记,强力推荐,教学深入浅出一遍就懂!b站搜索狂神说或点击下面链接 https://space.bilibili.com/95256449?spm_id_from=33 ...