高级数据结构---赫(哈)夫曼树及java代码实现
我们经常会用到文件压缩,压缩之后文件会变小,便于传输,使用的时候又将其解压出来。为什么压缩之后会变小,而且压缩和解压也不会出错。赫夫曼编码和赫夫曼树了解一下。
赫夫曼树:
它是一种的叶子结点带有权重的特殊二叉树,也叫最优二叉树。既然出现最优两个字肯定就不是随便一个叶子结点带有权重的二叉树都叫做赫夫曼树了。
赫夫曼树中有一个很重要的概念就是带权路径,带权路径最小的才是赫夫曼树。
树的路径长度是从根结点到每一个结点的长度之和,带权路径就是每一个结点的长度都乘以自己权重,记做WPL。
假设有abcd数据,权重分别是7 5 2 4。下面构建出来的三棵带权二叉树。
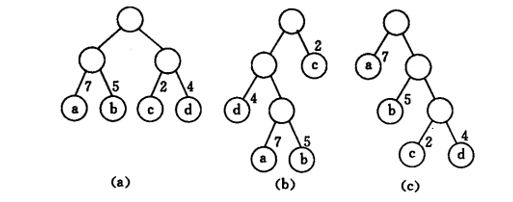
A树:WPL=7*2+5*2+2*2+4*2=36
B树:WPL=7*3+5*3+2*1+4*2=46
C树:WPL=7*1+5*2+2*3+4*3=35
显然C树的带权是最小的。而且无构建出比它更小的了。所以C树就是赫夫曼树
我们从C树发现了一个问题,就是要使得树的带权路径最小,那么权重越大的就应该离根结点越近。所以如果要构建一棵赫夫曼树,首先一定要将数据按权重排序。这是不是就是之前提到的贪心算法,一定有排序,从局部最优到整体最优。
赫夫曼编码:
我们都知道以前的地下党发送电报。都是加密了发送,然后使用密码本来解密。
我们还是发送上面的abcd
显然计算机的世界都是0和1,假设我们用三位来表示上面的字符。也就相当于制作一个密码本
a:000
b:001
c:010
d:011
那么我要传输的就变成了000001010011,然后收到之后按照三位一分来解密就可以了。但是如果数据很多之后。我们可能就不能不用3位来表示了,可能是8位,10位之类了的,那么这个二进制串的长度也相当可怕了。
再看赫夫曼树,如果我们将上面的C图的每一个左分支表示0,右分支表示1
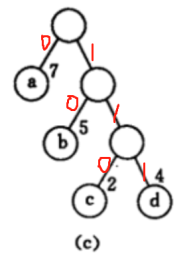
那么现在表示abcd就可以用每个结点长度路径上的值来表示了
a:0
b:10
c:110
d:111
abcd就可以表示为010110111,就从刚才的000001010011的12位缩减到了9位,如果数据量大,这个减少的位数是很可观的。
但是又有一个问题了,这样出来的编码长度不等,其实很容易混淆,所以要设计这种长短不等的编码,必须任意字符的编码都不是另一个字符编码的前缀,这种编码称做前缀编码。显然通过二叉树这样构造出来的编码,每个叶子结点都不同的编码。而这棵赫夫曼树就是我们的密码本。也就是说编码于解码都需要用同样结构的赫夫曼树。
解码:
每次从根开始寻找,找到叶子结点为止,然后又从根开始寻找,比如010110111,
0走左边,左边第一个就是叶子结点,所以找到a,
回到根继续寻找,编码串还剩下10110111,
1走右边,0走左边找到b,110 ->c, 111->d
一般来说设要编码的字符集{c1,c2,c3...},设置各个字符出现的频率{w1,w2,w3...},以各字符作为叶子结点,以相应的频率作为权重来构造赫夫曼树。
赫夫曼树的构建:
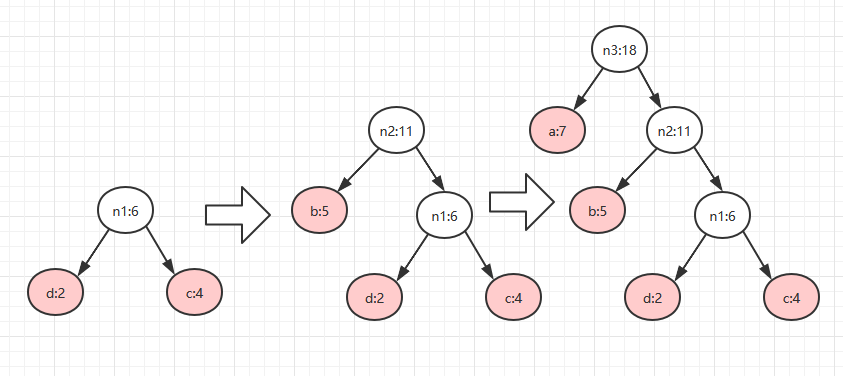
以我们上面的a:7 b:5 c:4 d:2为例。
1.上面从树的特点来看,首先我们需要按照权重从小到大排序,注意赫夫曼树的构建是逆向构建的,就是说是从叶子结点往根结点构建。排序:d:2 c:4 b:5 a:7
2.取前面两个权值最小结点作为新结点n1的两个子结点,注意二叉树的左小右大规则。新结点的权重为两孩子权重之和,将操作过的结点从数据中移除,新结点放进去继续操作:
n1的权重是 cd权重之和为6,新的排序:b:5 n1:6 a:7
3.取出b和n1构成新作为新结点n2的两个子结点剩余。 新的排序:a:7 n2:11
直到操作到最后两个结点结束。
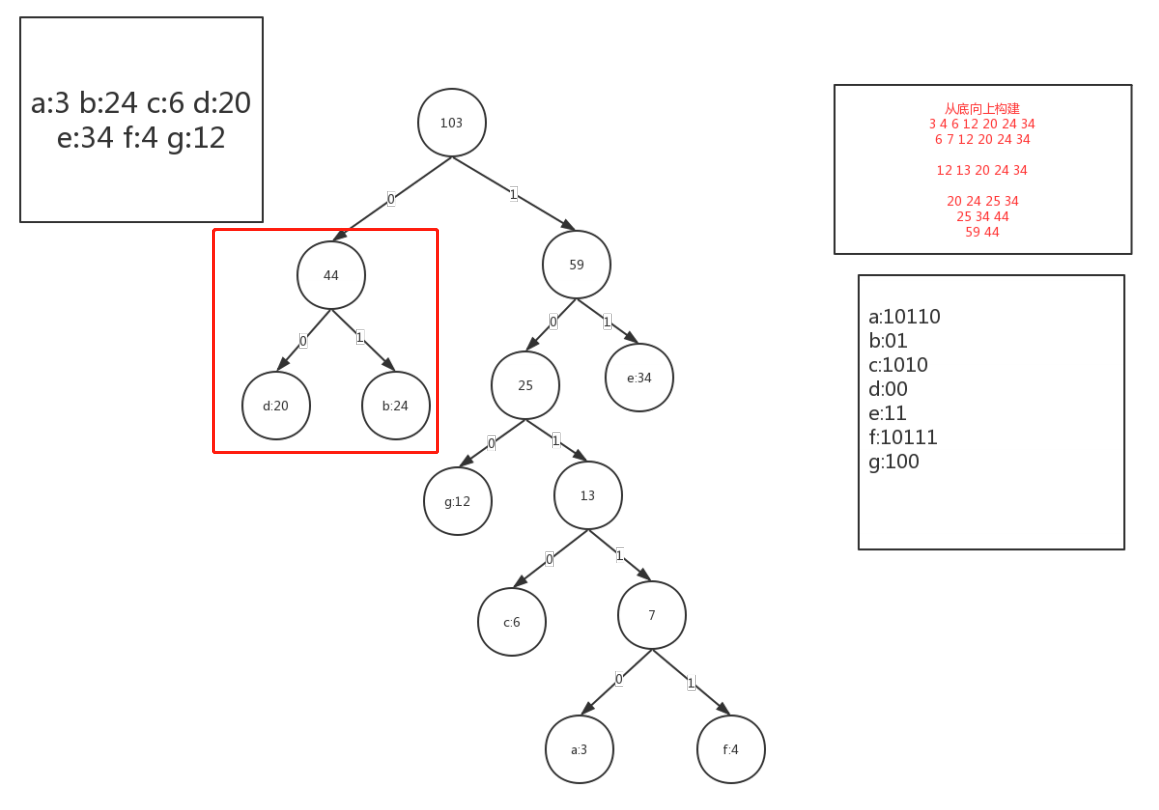
如果遇到操作的两个结点在已有的数上面还没有,那就另开一个子树,等到操作这个新子树的根结点的时候,再把这棵子树直接移植过去,比如这个数据来构建a:3 b:24 c:6 d:20 e:34 f:4 g:12
排序:a:3 f:4 c:6 g:12 d:20 b:24 e:34
d:20 和b:24 构造出来的子树就是后面移植上去的
代码实现:
现在就按照上面的逻辑,代码实现赫夫曼树的构建和编码解码,对比上面的第二个数据验证结果
package com.nijunyang.algorithm.tree; import java.util.*; /**
* Description: 哈夫曼树
* Created by nijunyang on 2020/4/28 21:43
*/
public class HuffmanTree { private static final byte ZERO = 0;
private static final byte ONE = 1;
HuffmanNode root;
Map<Character, Integer> weightMap; //字符对应的权重
List<HuffmanNode> leavesList; // 叶子
Map<Character, String> leavesCodeMap; // 叶子结点的编码 public HuffmanTree(Map<Character, Integer> weightMap) {
this.weightMap = weightMap;
this.leavesList = new ArrayList<>(weightMap.size());
this.leavesCodeMap = new HashMap<>(weightMap.size());
creatTree();
} public static void main(String[] args) {
Map<Character, Integer> weightMap = new HashMap<>();
//a:3 f:4 c:6 g:12 d:20 b:24 e:34
weightMap.put('a', 3);
weightMap.put('b', 24);
weightMap.put('c', 6);
weightMap.put('d', 20);
weightMap.put('e', 34);
weightMap.put('f', 4);
weightMap.put('g', 12);
HuffmanTree huffmanTree = new HuffmanTree(weightMap);
//abcd: 1011001101000
String code = huffmanTree.encode("abcd");
System.out.println(code);
System.out.println("1011001101000".equals(code));
String msg = huffmanTree.decode(code);
System.out.println(msg); } /**
* 构造树结构
*/
private void creatTree() {
PriorityQueue<HuffmanNode> priorityQueue = new PriorityQueue<>();
weightMap.forEach((k,v) -> {
HuffmanNode huffmanNode = new HuffmanNode(k, v);
priorityQueue.add(huffmanNode);
leavesList.add(huffmanNode);
});
int len = priorityQueue.size();//先把长度取出来,因为等下取数据队列长度会变化 //HuffmanNode实现了Comparable接口,优先队列会帮我们排序,我们只需要每次弹出两个元素就可以了
for (int i = 0; i < len - 1; i++) {
HuffmanNode huffmanNode1 = priorityQueue.poll();
HuffmanNode huffmanNode2 = priorityQueue.poll();
int weight12 = huffmanNode1.weight + huffmanNode2.weight; HuffmanNode parent12 = new HuffmanNode(null, weight12); //父结点不需要数据直接传个null
parent12.left = huffmanNode1; //建立父子关系,因为排好序的,所以1肯定是在左边,2肯定是右边
parent12.right = huffmanNode2;
huffmanNode1.parent = parent12;
huffmanNode2.parent = parent12;
priorityQueue.add(parent12); //父结点入队
}
root = priorityQueue.poll(); //队列里面的最后一个即是我们的根结点 /**
* 遍历叶子结点获取叶子结点数据对应编码存放起来,编码时候直接拿出来用
*/
leavesList.forEach(e -> {
HuffmanNode current = e;
StringBuilder code = new StringBuilder();
do {
if (current.parent != null && current == current.parent.left) { // 说明当前点是左边
code.append(ZERO); //左边0
} else {
code.append(ONE);//左边1
}
current = current.parent;
}while (current.parent != null); //父结点null是根结点
code.reverse(); //因为我们是从叶子找回去的 ,所以最后需要将编码反转下
leavesCodeMap.put(e.data, code.toString());
});
} /**
* 编码
*/
public String encode(String msg) {
char[] chars = msg.toCharArray();
StringBuilder code = new StringBuilder();
for (int i = 0; i < chars.length; i++) {
code.append(leavesCodeMap.get(chars[i]));
}
return code.toString();
} /**
* 解码
*/
public String decode(String code) {
char[] chars = code.toCharArray();
Queue<Byte> queue = new ArrayDeque();
for (int i = 0; i < chars.length; i++) {
queue.add(Byte.parseByte(String.valueOf(chars[i])));
}
HuffmanNode current = root;
StringBuilder sb = new StringBuilder();
while (!queue.isEmpty() ){
Byte aByte = queue.poll();
if (aByte == ZERO) {
current = current.left;
}
if (aByte == ONE) {
current = current.right;
}
if (current.right == null && current.left == null) {
sb.append(current.data);
current = root;
}
}
return sb.toString();
} /**
* 结点 实现Comparable接口 方便使用优先队列(PriorityQueue)排序
*/
private class HuffmanNode implements Comparable<HuffmanNode>{ Character data; //字符
int weight; //权重
HuffmanNode left;
HuffmanNode right;
HuffmanNode parent; @Override
public int compareTo(HuffmanNode o) {
return this.weight - o.weight;
}
public HuffmanNode(Character data, int weight) {
this.data = data;
this.weight = weight;
}
}
}
高级数据结构---赫(哈)夫曼树及java代码实现的更多相关文章
- hdu 2527:Safe Or Unsafe(数据结构,哈夫曼树,求WPL)
Safe Or Unsafe Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)To ...
- C语言数据结构之哈夫曼树及哈夫曼编码的实现
代码清单如下: #pragma once #include<stdio.h> #include"stdlib.h" #include <string.h> ...
- 【数据结构】赫夫曼树的实现和模拟压缩(C++)
赫夫曼(Huffman)树,由发明它的人物命名,又称最优树,是一类带权路径最短的二叉树,主要用于数据压缩传输. 赫夫曼树的构造过程相对比较简单,要理解赫夫曼数,要先了解赫夫曼编码. 对一组出现频率不同 ...
- 哈夫曼树(三)之 Java详解
前面分别通过C和C++实现了哈夫曼树,本章给出哈夫曼树的java版本. 目录 1. 哈夫曼树的介绍 2. 哈夫曼树的图文解析 3. 哈夫曼树的基本操作 4. 哈夫曼树的完整源码 转载请注明出处:htt ...
- Java 树结构实际应用 二(哈夫曼树和哈夫曼编码)
赫夫曼树 1 基本介绍 1) 给定 n 个权值作为 n 个叶子结点,构造一棵二叉树,若该树的带权路径长度(wpl)达到最小,称这样的二叉树为 最优二叉树,也称为哈夫曼树(Huffman Tree), ...
- Android版数据结构与算法(七):赫夫曼树
版权声明:本文出自汪磊的博客,未经作者允许禁止转载. 近期忙着新版本的开发,此外正在回顾C语言,大部分时间没放在数据结构与算法的整理上,所以更新有点慢了,不过既然写了就肯定尽力将这部分完全整理好分享出 ...
- Java数据结构和算法(四)赫夫曼树
Java数据结构和算法(四)赫夫曼树 数据结构与算法目录(https://www.cnblogs.com/binarylei/p/10115867.html) 赫夫曼树又称为最优二叉树,赫夫曼树的一个 ...
- javascript实现数据结构: 树和二叉树的应用--最优二叉树(赫夫曼树),回溯法与树的遍历--求集合幂集及八皇后问题
赫夫曼树及其应用 赫夫曼(Huffman)树又称最优树,是一类带权路径长度最短的树,有着广泛的应用. 最优二叉树(Huffman树) 1 基本概念 ① 结点路径:从树中一个结点到另一个结点的之间的分支 ...
- C#数据结构-赫夫曼树
什么是赫夫曼树? 赫夫曼树(Huffman Tree)是指给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小.哈夫曼树(也称为最优二叉树)是带权路径长度最短的树,权值较大的结点 ...
随机推荐
- vulnhub~MyExpense
最近有点忙,这几天的vulnhub断更了,今天试着做了一下myexpense,当然想要一帆风顺是不可能的,哪怕是有别人的steps 和walkthrough.所以就遇到的坑总结如下: 一般套路就是nm ...
- Java 为 Excel 中的行设置交替背景色
在制作Excel表格时,通过将数据表中上下相邻的两行用不同的背景色填充,可以使各行的数据看起来更清楚,避免看错行,同时也能增加Excel表格的美观度.本文将介绍如何在Java程序中为 Excel 奇数 ...
- block 的内存结构衍生出来的面试题
今天在群里看到大佬们在讨论一个面试题,问如下代码在 32bit 和 64bit 系统上分别报什么错误: #import <Foundation/Foundation.h> int main ...
- 1038 Recover the Smallest Number (30分)(贪心)
Given a collection of number segments, you are supposed to recover the smallest number from them. Fo ...
- Android 添加键值并上报从驱动到上层
转载:https://blog.csdn.net/weixin_43854010/article/details/94390803 Android 添加键值并上报从驱动到上层 平台 :RK3288 O ...
- Jenkins构建项目后发送钉钉消息推送
前言 钉钉是我们日常工作的沟通工具,在Jenkins构建持续集成项目配合钉钉机器人的功能,可以让我们在持续集成测试环节快速接收到测试结果的消息推送. 一:新建一个钉钉群,选择自定义机器人 二:添加机器 ...
- 基础类封装-Requests库封装
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # @Time : 2020/03/18 23:37 # @Author : Tang Yiwei # @ ...
- PHPDocumentor2.8.5 安装,使用及快速上手
PHPDocumentor当前版本是phpDocumentor-2.8.5.tgz 关于PHPDocumentor有什么用,还有其历史,我就不介绍了,直接进入正题.老版本的叫PHPDoc,从1.0开始 ...
- 【Selenium02篇】python+selenium实现Web自动化:鼠标操作和键盘操作!
一.前言 最近问我自动化的人确实有点多,个人突发奇想:想从0开始讲解python+selenium实现Web自动化测试,请关注博客持续更新! 这是python+selenium实现Web自动化第二篇博 ...
- JAVA debug 调试demo
1.设置断点,在代码的行号后面鼠标左键即可2.想要看调用方法的执行流程,那么调用方法也要加断点. package day6_debug; /* * 1.设置断点,在代码的行号后面鼠标左键即可 * 2. ...