【实践】如何利用tensorflow的object_detection api开源框架训练基于自己数据集的模型(Windows10系统)
如何利用tensorflow的object_detection api开源框架训练基于自己数据集的模型(Windows10系统)
一、环境配置
1. Python3.7.x(注:我用的是3.7.3。安装好后把python.exe的路径加入到全局环境变量path中,方便后续命令)
2. Tensorflow1.13.1(注:目前暂时还不能用tensorflow2.x,因为开源社区还没有针对Windows10+tensorflow2.x的object_detection api参考资料。)
3. Protobuf3.6.1(注:编译器直接从https://pypi.python.org/pypi/protobuf/下载。protobuf3.6.1是适合tensorflow1.13.1的最低protobuf版本号)
4. 其它依赖软件包安装:略(注:不一定要安装Anaconda3.x)
二、总体流程
1. 搭建tensorflow的object_detection api开源框架,运行demo例确认搭建成功。
2. 准备自己的数据集,标注,生成TFRecord格式的训练数据。
3. 增改tensorflow的object_detection api开源框架。
4. 训练,保存模型。
5. 使用模型。
三、步骤详述
1. 搭建tensorflow的object_detection api开源框架,运行demo例确认搭建成功。
1.1 使用参考资源1提供的models框架。这套models适用于tensorflow1.12,我试验了也可以用于tensorflow1.13.1(注:目前暂时没法用google放在github上的最新models,否则后续编译模型时会出现大量兼容性错误)。下载资源后,将原来的名称models-master修改为models,将models文件夹放置任意磁盘位置(我的放置路径:D:\tensorflow1\models)。
1.2 将以下三个路径设置到全局环境变量Path中:
D:\tensorflow1\models
D:\tensorflow1\models\research
D:\tensorflow1\models\slim
(注:设置slim路径是因为后续需要用到slim中的一些模块,如nets。)
1.3 用protoc编译器编译D:\tensorflow1\models\research\object_detection\protos下的文件。(注:非常关键的一步,工程问题较多。)
1.3.1 什么是protobuf协议?
请自行搜索学习。我的理解:一种类似xml的参数配置方法,但是更加短小。
1.3.2 安装protoc编译器及google提供的proto编译文件(指google\protobuf里自带的一些编译好的modules,例如descriptor等。D:\tensorflow1\models\research\object_detection\protos下proto文件在开头会导入这些modules)。
- 首先确定protobuf版本号3.6.1,原因在第一部分已经解释了。
- protoc.exe编译器:从https://pypi.python.org/pypi/protobuf/下载安装包,编译器在安装包的bin子文件夹里。将protoc.exe放到D:\tensorflow1\models\research下。
- 获得google提供的自带proto编译文件。我尝试了几种方法,以下方法最简单:pip install protobuf==3.6.1。安装好后,到python.exe所在文件夹下,进入Lib\site-packages\google\protobuf中,google自带的一些编译好的modules以.py文件的形式保存在这里。(注:如果google\protobuf中只有proto文件,没有.py文件,则需要调用protoc进行编译,编译方法见下一点)
- 编译D:\tensorflow1\models\research\object_detection\protos里的proto文件。命令如下:protoc object_detection/protos/*.proto --python_out=. (注:这里python_out的“.” 就是指object_detection/protos/。路径中用正反斜杠都可以)。编译完成后,每个proto文件会生成一个对应的xxx_pb2.py文件。
- 编译过程中,可能会有报错。请打开对应源码文件自行修正。
1.4 运行demo例确认搭建成功
1.4.1 demo例使用了coco数据集,windows10里需要安装pycocotools。
有效安装方法:请查询“参考文档2”相关主题部分。此步骤将pycocotools安装进site-packages,后续log里看到引用来自site-packages时请不要奇怪。
如果上述方法无效,请参考使用如下方法:
- 从 https://github.com/pdollar/coco.git下载源码解压到本地
- 进入cocoapi-master/PythonAPI文件夹,命令窗口运行:python setup.py build_ext --inplace。
- 若上一步没问题,则运行命令:python setup.py build_ext install
1.4.2 在\models\research目录中执行
python setup.py build
python setup.py install
安装demo运行所需环境。
1.4.3 将jupyter notebook训练脚本的源码下载到本地(本地名称:object_detection_tutorial.py)。下载适合当前版本的预训练模型(xxx.tar.gz文件,不用解压。demo使用的是coco数据集,所以可以选用名称中带coco的与训练模型文件,且不要选最新的文件,以防止版本兼容性问题)。修改下载到本地的object_detection_tutorial.py文件。请查询“参考文档2”相关主题部分。
(注:不要直接运行jupyter notebook。原因:查看object_detection_tutorial.py,可以发现jupyter notebook是在线从google的网址下载预训练模型的,可能由于网络原因导致下载失败)。
- 可能的报错1:from nets your-net-name ModuleNotFoundError: No module named 'nets'
解决方案:说明需要手动安装slim。在research/slim下运行:
python setup.py build
python setup.py install
如果和原来自带的BUILD文件有冲突,可以将BUILD文件移除,然后重新编译及安装即可成功。
- 可能的报错2:log显示,是从your_python_path\Lib\site-packages\object_detection-0.1-py3.7.egg\object_detection\protos里调用input_reader、image_resize等自行编译的modules的,但是调用不到,或者导入的modules中的serialized_pb=“xxxx”存在Syntax invalid错误。
解决方案:手动将D:\tensorflow1\models\research\object_detection文件夹直接拷贝到
your_python_path\Lib\site-packages\object_detection-0.1- py3.7.egg\下面,替换掉原来的object_detection文件夹。
(注:可能只需要替换掉protos子文件夹即可,由于时间紧张,我没有试过)
1.4.4 在D:\tensorflow1\models\research\object_detection文件夹下运行:python ./object_detection_tutorial.py启动demo测试例运行。
运行成功后,会在指定结果文件夹里生成两张结果图:

至此,说明训练框架和训练环境配置成功。
2. 准备自己的数据集,标注,生成TFRecord格式的训练数据。
这是一个耗时较长的过程,但难度相对小一些。详细请查询“参考文档-3”相关部分(第3、4两部分)。
这里大致说明一下流程:先使用labelImg生成符合PASCAL-VOC数据集格式的标注文件(xml格式),然后通过xml_to_csv.py将标注文件转换为csv格式,最后通过generate_tfrecord.py将csv格式数据转化为tensorflow指定的TFRecord格式文件。
3. 增改tensorflow的object_detection api开源框架。
请查阅“参考文档”的1、3、4。
特别说明:
- 首先下载参考文档3项目对应的github源码(见“参考资源2”),将源码整体拷贝到D:\tensorflow1\models\research\object_detection文件夹里去。
- 然后将第2步生成的两个TFRecord文件train.record和test.record拷贝到D:\tensorflow1\models\research\object_detection文件夹,
- 将自己的数据集替换到文件夹D:\tensorflow1\models\research\object_detection\images里去(详细位置见参考文档3的说明)。
4. 训练,保存模型参数。
将D:\tensorflow1\models\research\object_detection\legacy\下的train.py拷贝到上一级目录D:\tensorflow1\models\research\object_detection下面。
运行命令启动训练:python .\train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/faster_rcnn_inception_v2_pets.config
(注:如果相对路径调用train.py不行,可以使用绝对路径。faster_rcnn_inception_v2_pets.config是我使用的模型的配置文件,原文件放在D:\tensorflow1\models\research\object_detection\samples\configs里,需要修改一些参数。)
如果运行成功的话,在打印初始化log信息一小段时间后,会出现如下训练信息:显示训练steps,每步的loss等。loss值会随着训练steps的增加而逐渐下降。
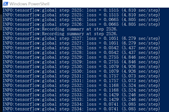
参考文档3里建议训练到loss稳定=0.05左右时结束。我使用纯CPU训练了七个小时,loss才逐渐稳定到0.07左右。说明:根据模型和计算机算力的不同,训练时长不同。建议:如果有GPU,尽量使用起来。
查看训练的命令:tensorboard –logdir=training不可用。可能受防火墙限制。
每训练大约5~15分钟,框架代码就会将当前checkpoint保存到D:\tensorflow1\models\research\object_detection\training\model.ckpt里,如下图亮显的两行所示。
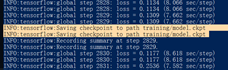
如果想结束训练,可以在当前的这轮checkpoint完成保存后,使用CTRL+C来停止。如果之后又重新启动训练,则训练将从最后保存的checkpoint处重新开始。
训练完成后,调用命令导出模型(inference graph,后缀是.pb)。导出命令:
python export_inference_graph.py --input_type image_tensor --pipeline_config_path training/faster_rcnn_inception_v2_pets.config
--trained_checkpoint_prefix training/model.ckpt-XXXX --output_directory inference_graph
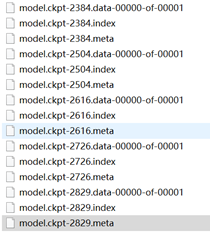
命令里的XXXX是一个数字,来源于保存在training里的model.ckpt文件名中的 最大数字。例如,下图所示ckpt文件名中,最大数字是2829,则XXXX就是2829。
5. 使用模型。
具体参阅参考文档3的第8部分。
四、参考资源
1. Models:
链接:https://pan.baidu.com/s/1_W4ahFmGLF-TlbAAf2SyZA
提取码:2tua
(来源:https://blog.csdn.net/qq_37273544/article/details/103490426)
2. TensorFlow-Object-Detection-API-Tutorial-Train-Multiple-Objects-Windows-10-master
五、参考文档
1. https://blog.csdn.net/qq_37273544/article/details/103490426
4. https://blog.csdn.net/weixin_40787712/article/details/90631258
【实践】如何利用tensorflow的object_detection api开源框架训练基于自己数据集的模型(Windows10系统)的更多相关文章
- tensorflow语义分割api使用(deeplab训练cityscapes)
安装教程:https://github.com/tensorflow/models/blob/master/research/deeplab/g3doc/installation.md citysca ...
- TensorFlow Object Detection API(Windows下测试)
"Speed/accuracy trade-offs for modern convolutional object detectors." Huang J, Rathod V, ...
- Pyhton开源框架(加强版)
info:Djangourl:https://www.oschina.net/p/djangodetail: Django 是 Python 编程语言驱动的一个开源模型-视图-控制器(MVC)风格的 ...
- tensorflow学习笔记--dataset使用,创建自己的数据集
数据读入需求 我们在训练模型参数时想要从训练数据集中一次取出一小批数据(比如50条.100条)做梯度下降,不断地分批取出数据直到损失函数基本不再减小并且在训练集上的正确率足够高,取出的n条数据还要是预 ...
- iOS开源 框架
UI界面类项目: Panoramagl ——720全景展示 Panorama viewer library foriPhone, iPad and iPod touch MBProgressHUD — ...
- 开源框架:Apache的DBUtils框架
开源框架:Apache的DBUtils框架 Commons DbUtils 1.4 API 开源框架:DBUtils使用详解 Download Apache Commons DbUtils 官方文档
- Jeasyframe 开源框架 稳定版 V1.5 发布
这是Jeasyframe开源框架的第一个稳定版本,感谢一起帮忙测试并给予反馈的网友们. 框架官网:http://www.jeasyframe.org/ 产品介绍: Jeasyframe开源框架是基于S ...
- 谷歌开源的TensorFlow Object Detection API视频物体识别系统实现教程
视频中的物体识别 摘要 物体识别(Object Recognition)在计算机视觉领域里指的是在一张图像或一组视频序列中找到给定的物体.本文主要是利用谷歌开源TensorFlow Object De ...
- 谷歌开源的TensorFlow Object Detection API视频物体识别系统实现(二)[超详细教程] ubuntu16.04版本
本节对应谷歌开源Tensorflow Object Detection API物体识别系统 Quick Start步骤(一): Quick Start: Jupyter notebook for of ...
随机推荐
- css3 属性阴影效果--box-shadow,text-shadow
1.text-shadow:h-shadow v-shadow blur color; h-shadow:水平阴影的位置,可以是负值,正值向右,负值向左 v-shadow:水平阴影的位置,可以是负值, ...
- Java实现 蓝桥杯 算法训练 矩阵乘法
算法训练 矩阵乘法 时间限制:1.0s 内存限制:512.0MB 提交此题 问题描述 输入两个矩阵,分别是ms,sn大小.输出两个矩阵相乘的结果. 输入格式 第一行,空格隔开的三个正整数m,s,n(均 ...
- Java实现 LeetCode 319 灯泡开关
319. 灯泡开关 初始时有 n 个灯泡关闭. 第 1 轮,你打开所有的灯泡. 第 2 轮,每两个灯泡你关闭一次. 第 3 轮,每三个灯泡切换一次开关(如果关闭则开启,如果开启则关闭).第 i 轮,每 ...
- java实现 洛谷 P1056 排座椅
import java.util.Arrays; import java.util.Map.Entry; import java.util.Scanner; import java.util.Tree ...
- 20行Python代码开发植物识别 app
这篇文章介绍如何用Python快速实现一个植物识别的app,家里养了几盆多肉还叫不上名字,正好拿来识别一下.实现这样一个app只需要20行左右的代码,先来看下效果: 另外,我也开发了微信小程序版本,大 ...
- .NET开发者省份分布排名
什么叫.NET开发者省份分布排名呢? 顾名思义,这几个词大家都认识,.NET开发者都集中在城市,涵盖一线城市到五线城市.排名的方法非常简单粗暴,就是根据本公众号(dotnet跨平台)的省份订阅读者数量 ...
- STM32学习笔记——printf
printf复习 当我们写printf("%d\n", 1);的时候,printf函数并不能通过C语言语法得知第二个参数是int类型.printf是一个变参函数(variadic ...
- springboot整合oss
原文链接:https://blog.csdn.net/weixin_42370891/article/details/99102508 登录阿里云,进入到控制台 创建Bucket 导入如下依赖 < ...
- MySQL ORDER BY:对查询结果进行排序
在 MySQL SELECT 语句中,ORDER BY 子句主要用来将结果集中的数据按照一定的顺序进行排序. 其语法格式为: ORDER BY {<列名> | <表达式> | ...
- c++无法解析的外部符号 "int const bufferSize
无法解析的外部符号 "int const bufferSize 严重性 代码 说明 项目 文件 行 禁止显示状态错误 LNK2001 无法解析的外部符号 "int const bu ...