主存到Cache直接映射、全相联映射和组相联映射
转自:https://blog.csdn.net/dongyanxia1000/article/details/53392315
---- Cache的容量很小,它保存的内容只是主存内容的一个子集,且Cache与主存的数据交换是以块(cache line)为单位的。为了把信息放到Cache中,必须应用某种函数把主存地址定位到Cache中,这称为地址映射。
---- 在信息按这种映射关系装入Cache后,CPU执行程序时,会将程序中的主存地址变换成Cache地址,这个变换过程叫做地址变换。
Cache的地址映射方式有直接映射、全相联映射和组相联映射。
假设某台计算机主存容量为1MB,被分为2048块,每个Block为512B;Cache容量为8KB,被分为16块,每块也是512B。
下面以此为例介绍三种基本的地址映射方法。
1. 直接映射
---- 一个内存地址能被映射到的Cache line是固定的。就如每个人的停车位是固定分配好的,可以直接找到。缺点是:因为人多车位少,很可能几个人争用同一个车位,导致Cache淘汰换出频繁,需要频繁的从主存读取数据到Cache,这个代价也较高。
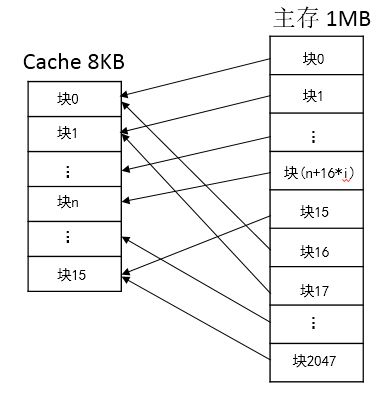
直接映射的Cache组织如图(1)所示。主存中的一个块只能映射到Cache的某一特定块中去。例如,
主存的第0块、第16块、第32块、第48块、……、第2032块等128块,只能映射到Cache的第0块;
主存的第1块、第17块、第33块、第49块、……、第2033块等128块,只能映射到Cache的第1块;
以此类推,主存的第15块、第31块、第47块、……、第2047块等128块,只能映射到Cache的第15块中。
映射完毕,Cache总共有0~15即16块,主存中的每128(2048/16)块,只能映射到Cache中的某一个块中。
即映射规则为cache line index = (主存(Page)的line数)%(cache中 cache line的总数)
主存的line数是0~2047,cache中cache line的总数是16.
图(1)
直接映射是最简单的地址映射方式,它的硬件简单,成本低,地址变换速度快,而且不涉及替换算法问题。但是这种方式不够灵活,Cache的存储空间得不到充分利用,每个主存块只有一个固定位置可存放,容易产生冲突,使Cache效率下降,因此只适合大容量Cache采用。例如,如果一个程序需要重复引用主存中第0块与第16块,最好将主存第0块与第16块同时复制到Cache中,但由于它们都只能复制到Cache的第0块中去,即使Cache中别的存储空间空着也不能占用,因此这两个块会不断地交替装入Cache中,导致命中率降低。
2. 全相联映射
---- 主存中的一个地址可被映射进任意cache line,问题是:当寻找一个地址是否已经被cache时,需要遍历每一个cache line来寻找,这个代价很高。就像停车位可以大家随便停一样,停的时候简单,找车的时候需要一个一个停车位的找了。
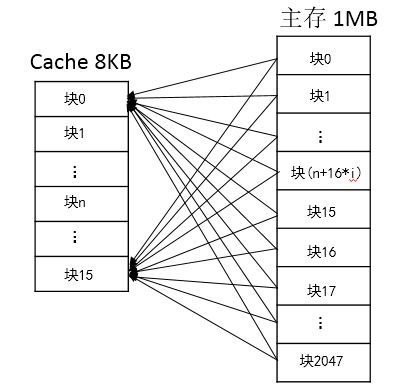
图(2)是全相联映射的Cache组织,主存中任何一块都可以映射到Cache中的任何一块位置上。
图(2)
全相联映射方式比较灵活,主存的各块可以映射到Cache的任一块中,Cache的利用率高,块冲突概率低,只要淘汰Cache中的某一块,即可调入主存的任一块。但是,由于Cache比较电路的设计和实现比较困难,这种方式只适合于小容量Cache采用。
3. 组相联映射
---- 组相联映射实际上是直接映射和全相联映射的折中方案,其组织结构如图(3)所示。
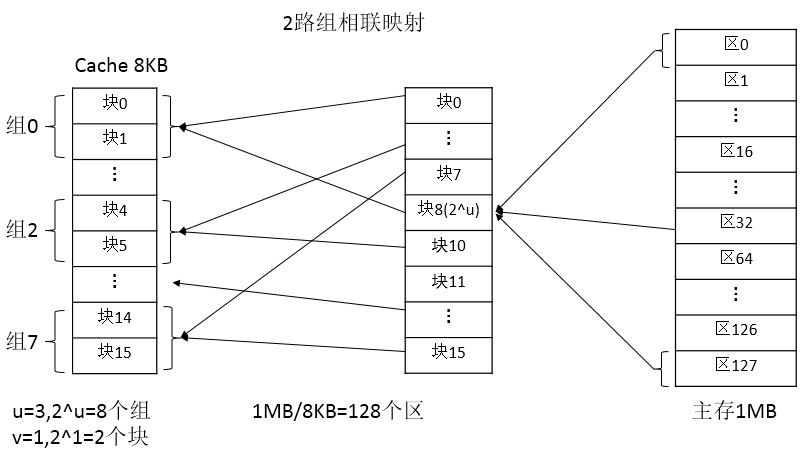
主存和Cache都分组,主存中一个组内的块数与Cache中的分组数相同,组间采用直接映射,组内采用全相联映射。也就是说,将Cache分成2^u组,每组包含2^v块,主存块存放到哪个组是固定的,至于存到该组哪一块则是灵活的。即主存的某块只能映射到Cache的特定组中的任意一块。主存的某块b与Cache的组k之间满足以下关系:k=b%(2^u).
例如,Cache分为8组(u=3),每组2块(v=1),主存分为128个区,每个区16块。
图(3)
主存中的各块与Cache的组号之间有固定的映射关系,但可自由映射到对应Cache组中的任何一块。例如:
--主存的第0块、第2^u块、第2×(2^u)块、…第255x(2^u)即255x8=2040块等256块均映射于Cache的第0组,但可映射到其中的第0块或第1块;
--主存的第1块、第2^u+1块、第3^(2^u)+1块、…第255x(2^u+1)即2041块等均映射于Cache的第2组,但可映射到Cache第2组中的任意一块;
--主存的第2块、第2^u+2块、第(2^u)x2+2块、…第2042块等均映射于Cache的第3组,但可映射到Cache第3组中的任意一块;
--主存的第7块、第2^u+7块、第2^(u+1)+7块、…第2047块等均映射于Cache的第8组,但可映射到Cache第8组中的第14块或第15块。
常采用的组相联结构Cache,每组内有2、4、8、16块,称为2路、4路、8路、16路组相联Cache。以上为2路组相联Cache。组相联结构Cache是前两种方法的折中方案,适度兼顾二者的优点,尽量避免二者的缺点,因而得到普遍采用。
实例分析:
1.容量为64块的Cache采用组相联方式映像,字块大小为128字节,每4块为一组,若主容量为4096块,且以字编址,那么主存地址为(19)位,主存区号为(6)位。
解:组相联的地址构成为:区号+组号+块号+块内地址。
主存的每个分区/组大小与整个Cache大小相等,故此主存需要分的区数为:4096/64=64,因为26=64,因此需要6位来表示区号。每4块为一组,故共有组数 64/4 = 16 ,因为24=16,因此需要4位表示组号。每组4块,故表示块号需要2位。
块内地址共128字节,27=128,所以块内地需要7位表示。所以:主存地址的位数=6+4+2+7 = 19
主存区号的位数=6
个人见解:Cache有u组,每组有v块,即u = 16,v = 4,Cache大小:64块×128B = 8KB。
主存大小:4096×128B = 2^12*2^7 = 2^19,即主存地址有19位。4096/64= 2^6主存区号为6位。
2.某 32 位计算机的 cache 容量为 16KB,cache 块的大小为 16B,若主存与 cache 的地址映射采用直接映射方式,则主存地址为 1234E8F8(十六进制)的单元装入的 cache 地址为__C__。
A. 00 0100 0100 1101 (二进制)
B. 01 0010 0011 0100 (二进制)
C. 10 1000 1111 1000 (二进制)
D. 11 0100 1110 1000 (二进制)
解:Cache大小为16KB,块大小为16B,所以Cache被分成16KB/16B=1024块,因210=1024故需要10位来表示块数。
24=16故块内地址需要4位来表示。所以Cache的地址线位置为14位。
由于采用直接映像的方式,所以主存的后14位就是要装入的到Cache中的位置。故选 C.
个人见解:Cache的容量是16KB = 16×1024B = 16384B,主存的地址为0x1234E8F8/(16×1024B)= 18643. 该地址对应的是主存的第18643块。
根据公式:cache的块地址i = 主存的块地址 % 16384 = 1234E8F8 - 1234C000 = 0x28F8 选C
主存到Cache直接映射、全相联映射和组相联映射的更多相关文章
- cache与MMU与总线仲裁
为了以合理的价格,设计容量和速度满足计算机系统的需求,计算机体系结构设计者设计出了存储器的层次结构. "Cache-主存"和"主存-辅存"是最常见的两种层次结构 ...
- Cache地址映射
原理:程序访问局部性 在较短时间内由程序产生的地址往往集中在存储器逻辑地址空间的很小范围内 时间:在一小段时间内,最近被访问过的程序和数据很可能再次被访问 ...
- cache 浅析
http://blog.chinaunix.net/uid-26817832-id-3244916.html 1. Cache Cache一词来源于法语,其原意是"藏匿处,隐秘的地方&q ...
- ****** 三十四 ******、软设笔记【存储器系统】-Cache存储器
Cache存储器 Cache(高速缓冲存储器) 高速缓冲存储器是位于主存与CPU之间的一级存储器,有静态存储芯片(SRAM)组成,容量比较小,速度比主存高得多,接近于CPU的速度,单位成本比内存高.C ...
- 专题-主存储器与Cache的地址映射方式
2019/05/02 10:23 首先,我们注意到地址映射有三种:分别是直接地址映射.全相联映射.组相联映射. 首先我们搞清楚主存地址还有Cache地址的关系,还有组内地址的关系,常见我们的块内地址, ...
- 高速缓冲存储器Cache
目录 概述 问题的提出 局部性原理 命中与未命中 Cache的命中率 Cache-主存系统的效率 例题 工作原理 地址映射方式(本节最重要) 直接映射 全相联映射 组相联映射 例子 替换策略 例题 写 ...
- Cache一致性协议与伪共享问题
Cache一致性协议 在说伪共享问题之前,有必要聊一聊什么是Cache一致性协议 局部性原理 时间局部性:如果一个信息项正在被访问,那么在近期它很可能还会被再次访问 比如循环.方法的反复调用等 空间局 ...
- verilog简易实现CPU的Cache设计
verilog简易实现CPU的Cache设计 该文是基于博主之前一篇博客http://www.cnblogs.com/wsine/p/4661147.html所增加的Cache,相同的内容就不重复写了 ...
- solr中Cache综述
一.概述 Solr查询的核心类就是SolrIndexSearcher,每个core通常在同一时刻只由当前的SolrIndexSearcher供上层的handler使用(当切换SolrIndexSear ...
随机推荐
- Java实现 LeetCode 123 买卖股票的最佳时机 III(三)
123. 买卖股票的最佳时机 III 给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格. 设计一个算法来计算你所能获取的最大利润.你最多可以完成 两笔 交易. 注意: 你不能同时参与 ...
- JavaScript使用for循环和splice删除数组指定元素的注意点
在JavaScript里可以结合for循环和splice来删除数组指定的元素.但是要注意删除元素后,数组索引会发生改变 示例 var arr = ["a","b" ...
- 二叉树的层次序列化和反序列化-----stringstream
string serialize(TreeNode* root) {//层序便利,将空的子节点也放入到字符串 ostringstream out; queue<TreeNode*> q; ...
- zabbix服务无法正常启动
环境介绍 操作系统 centos 7.4 zabbix 3.4.7 故障现象说明 zabbix agent无法启动 web 监控不到客户端服务器 查看日志报错 提示不能打开日志,不能创建信 ...
- leetcode75之颜色分类
题目描述: 给定一个包含红色.白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色.白色.蓝色顺序排列. 此题中,我们使用整数 0. 1 和 2 分别表示红色.白 ...
- 6、react中的交互
1.ajax 再react中使用ajax和直接使用ajax的用法是完全一样的,只要找好路径即可,但是也有不一样的地方,再react中是通过改变状态state来达到让组件重新渲染的效果,并且放ajax的 ...
- .Net Core微服务入门全纪录(二)——Consul-服务注册与发现(上)
前言 上一篇[.Net Core微服务入门全纪录(一)--项目搭建]讲到要做到服务的灵活伸缩,那么需要有一种机制来实现它,这个机制就是服务注册与发现.当然这也并不是必要的,如果你的服务实例很少,并且很 ...
- MySQL连接查询驱动表被驱动表以及性能优化
准备我们需要的表结构和数据 两张表 studnet(学生)表和score(成绩)表, 创建表的SQL语句如下 CREATE TABLE `student` ( `id` int(11) NOT NUL ...
- MQ系列(0)——MQ简介
mq简介 mq 就是消息队列(Message Queue).想必大家对队列的数据结构已经很熟悉了,消息队列可以简单理解为:把要传输的数据放在队列中,mq 就是存放和发送消息的这么一个队列中间件.在消息 ...
- OSI七层模型工作过程&&输入URL浏览器的工作过程(超详细!!)
从以下10个方面深入理解输入URL后整个模型以及浏览器的工作流程! 目录 1.HTTP 2.DNS 3.协议栈 4.TCP 5.IP 6.MAC 7.网卡 8.交换机 9.路由器 10.服务器与客户端 ...