Multi-batch TMT reveals false positives, batch effects and missing values(解读人:胡丹丹)
文献名:Multi-batch TMT reveals false positives, batch effects and missing values (多批次TMT定量方法中对假阳性率,批次效应,以及缺失值的研究)
期刊名:Molecular & Cellular Proteomics
DOI:10.1074/mcp.RA119.001472
Online:https://www.mcponline.org/content/early/2019/07/22/mcp.RA119.001472
单位:英国邓迪大学
摘要:
在蛋白质组定量领域,目前已经有多种蛋白定量方法,有标定量的TMT,ITRAQ,IBT等等,无标定量DIA,pSMART,Boxcar等等,各个方法各有优劣,标记的定量方法优点是定量相对准确,数据分析容易,不依赖预先建库,然而缺点是通量低,费用高。无标定量方法优点是通量高,无需同位素标记试剂,相对费用低,操作简单,缺点是需预先建库,而且数据分析相对困难。在这篇文章中,作者就尝试使用多批次TMT的定量方法,阐述方法的缺失值,批次效应,假阳性率等的问题来探究其可行性。
研究背景:
文中采用的样本是诱导性多能干细胞(iPSC),作者采用了10标TMT技术,并用MS3的报告离子定量,并跑了24批样本,每批10个样本,包含1个质控样本和9个不同来源的样本,总共跑了(24批X9样本+1质控)=217个不同来源的样本,作者评估数据后发现在多批次TMT分析中缺失值有放大效应,在蛋白水平上存在,在肽段水平上放大效应还会增加,另一方面,在定量的准确性上,如果没有质控样本去矫正,TMT多批次定量的准确性无法保证。此外,实验中采用的细胞,有男女性别的差异,根据男性Y染色体特有肽段可以评估实验的假阳性率,在所有批次中都有男性特有的肽段在女性样本中被鉴定到,假阳性的确存在,并且值得探究。
研究结果:
1)缺失值:
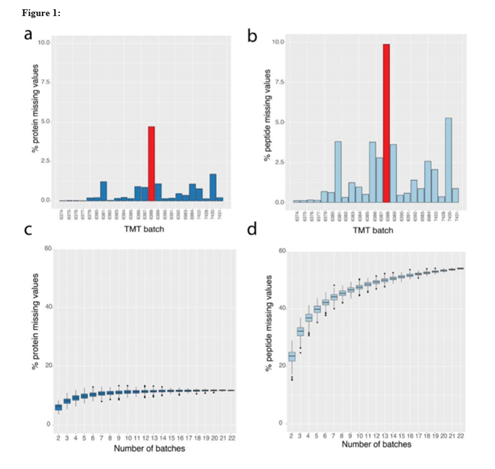
在图1中,ab为24次批次中缺失值,92%的批次(蓝色的柱)中,蛋白水平的缺失值都小于1%,且他们的肽段水平的缺失值小于5%,只有一个批次(红色)蛋白的缺失值大于1.5%,肽段水平的缺失值为9%,在后续的数据分析中,这个批次被剔除。
在单批次分析中,缺失值相对较小,但是在多个批次一起分析的时候,缺失值放大了,如图cd,在5个批次的时候肽段的缺失值接近了40%,这就表明在多批次的时候,肽段的重现性较差,全都是因为有些肽段丰度较低导致的吗?作者进一步分析了蛋白鉴定的数量和相应的MS3的信号强度(如图2ab),最终得出结论,即使非低丰度的蛋白也无法在多批次和多样本中持续的被检测到。作者综上对肽段鉴定做了总结,大约50%的肽段能在<40%的批次中检测到

2)不同批次的CV:
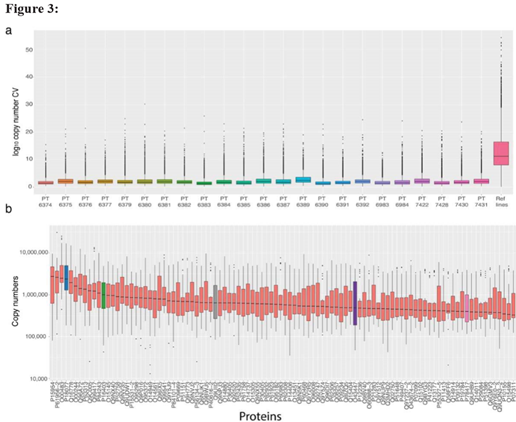
曾有文章报到过TMT定量的CV比无标定量小三倍。但是多数研究只是在单批次的水平,而此次可以探究多批次的CV。作者计算了230个样本的log10 copy number来评估CV,如图3a,之前提到的缺失值异常的批次又被剔除,copy number 的计算方法推荐去看原文章。在单批次中蛋白CV值小于2.5%,在所有批次的230个样本中蛋白的的CV值为11.03%,是单批次的6.4倍。另外,大家普遍认为低丰度的蛋白会对CV产生较大的影响,于是作者还选取了23个control样本中丰度top100的蛋白计算了CV,如图3b,得到的结果是CV大于7.5。
两外,作者观察到一些批次中同时包含了健康的样本和罕见基因病的样本,而这些批次的CV值要比全部样本的CV值低10倍左右,作者表示这表明了比起TMT对数据的影响要小于样本本身的差异
最后,作者表示,copy number已经提供了第一步的normalization(这涉及了mann的一篇文章,推荐看下),但这不足以消除批次效应,在每个批次中加入质控样本仍然非常重要。使用质控样本去矫正,在所有细胞样本中和质控样本中的CV达到了2.96%。
3)假阳性率:
作者筛选了65条Y染色体特定表达的肽段分析假阳性率,结果很令人意外,在21次包含女性样本的批次中,都检测到了这些肽段,并且最低检测到的40%数量的Y染色体特定肽,21批的平均值为89%,具体如图4所示,作者表示这可能是二级共洗脱和三级报告离子干扰引起的。
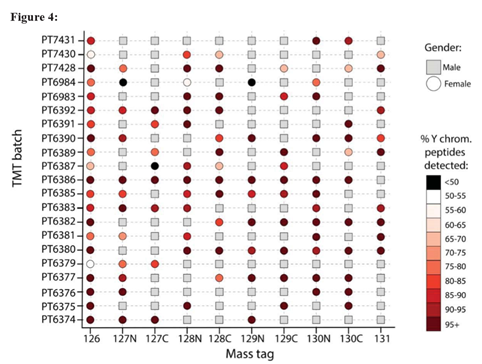
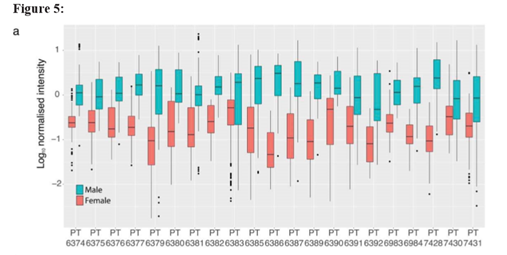
三级报告离子的干扰主要是由TMT厂商生产的试剂不纯和实验错误引起的,二级共洗脱是由于在二级质谱的时候两个母离子质量非常接近,四极杆无法分开,因此会导致碎出来的报告离子不够准确因为假阳性率比较高。因为数据显示在女性的样本中出现了Y染色体特定肽,于是作者分析了Y染色体特定肽在男性和女性样本中丰度的差异,如图5a所示,结果显示,有的样本丰度差异巨大,如PT6379与PT6386男性比女性的比值分别为,17倍,65倍,有的样本差异就不是那么大,像PT7430与PT6391,比值分别为2.5倍与4.4倍,这样的假阳性率就是有很大的问题,而且不好解释。
最后作者指出,低丰度的肽段容易受到二级共洗脱的影响,但是报告离子干扰非常少甚至没有影响。
4)对TMT实验的建议与优化:
作者建议对于多批次的TMT实验,应在126C,127N标签内加入质控样本,能够最大化的避免三级报告离子干扰。
文章讨论:
文章通过使用IPSC的样本在多次批次的TMT上机,评估产出数据的质量来判定方法的可行性,并给出了建设性的建议,文章中提到TMT的实验方法在单批次中缺失值较少,但在多批次中会存在缺失值放大的问题,个人认为从理论上来讲共洗脱带来也假阳性也会在一定程度上减小了缺失值的问题,作者没有从这一方面分析。另一方面如果不采用三级定量,用二级定量的方法虽然能够提高样本的鉴定率,但是二级定量的方法带来的共洗脱干扰恐怕会更严重,定量的准确性更无法保证。关于批次效应的问题,作者表示在多批次TMT实验时,copy number虽然已经提供了第一步的均一化步骤,但是仍然不够有效,作者表示在每个批次中插入质控样本能够帮助均一化,使实验得出的数据更加接近样本真实的浓度。关于假阳性率高的问题,作者认为主要是二级共洗脱干扰导致的,之前nature method 报道了mann的EASI-tag的文章表示能做到无二级共洗脱干扰,但是只是6标而不是10标。最后作者表示这次实验高深度,多批次,多样本的实验能够对之后的蛋白质组学有所帮助。
最后,Thermo 的研发实力有目共睹,目前已经他们有了16标的TMT技术,标记定量的方法仍然在定量蛋白质组学方面仍然有举足轻重的作用,国内也有国产的16标的标记定量技术,那就是华大基因成功自研的16标IBT技术,而且价格更便宜,值得期待。
阅读人:胡丹丹
Multi-batch TMT reveals false positives, batch effects and missing values(解读人:胡丹丹)的更多相关文章
- Recall(召回率);Precision(准确率);F1-Meature(综合评价指标);true positives;false positives;false negatives.
Recall(召回率);Precision(准确率);F1-Meature(综合评价指标);在信息检索(如搜索引擎).自然语言处理和检测分类中经常会使用这些参数. Precision:被检测出来的信息 ...
- 阅读笔记:Solving the “false positives” problem in fraud prediction
刚读完一篇paper<Solving the “false positives” problem in fraud prediction>,趁热打铁,做个笔记. 文章下载链接:https: ...
- Deep Learning 27:Batch normalization理解——读论文“Batch normalization: Accelerating deep network training by reducing internal covariate shift ”——ICML 2015
这篇经典论文,甚至可以说是2015年最牛的一篇论文,早就有很多人解读,不需要自己着摸,但是看了论文原文Batch normalization: Accelerating deep network tr ...
- Recall(召回率);Precision(准确率);F1-Meature(综合评价指标);true positives;false positives;false negatives..
转自:http://blog.csdn.net/t710smgtwoshima/article/details/8215037 Recall(召回率);Precision(准确率);F1-Meat ...
- 陪你解读Spring Batch(一)Spring Batch介绍
前言 整个章节由浅入深了解Spring Batch,让你掌握批处理利器.面对大批量数据毫无惧色.本章只做介绍,后面章节有代码示例.好了,接下来是我们的主角Spring Batch. 1.1 背景介绍 ...
- False Positives和False Negative等含义
True Positive (真正, TP)被模型预测为正的正样本: True Negative(真负 , TN)被模型预测为负的负样本 : False Positive (假正, FP)被模型预测为 ...
- True(False) Positives (Negatives), 召回率和精度定义
True Positive (真正, TP)被模型预测为正的正样本: True Negative(真负 , TN)被模型预测为负的负样本 : False Positive (假正, FP)被模型预测为 ...
- Untargeted lipidomics reveals specific lipid abnormality in nonfunctioning human pituitary adenomas 非靶向脂质组学揭示非功能人类脑垂体瘤中的特异性脂质 (解读人:胡丹丹)
文献名:Untargeted lipidomics reveals specific lipid abnormality in nonfunctioning human pituitary adeno ...
- Proteomic Profiling of Paired Interstitial Fluids Reveals Dysregulated Pathways and Salivary NID1 as a Biomarker of Oral Cavity Squamous Cell Carcinoma (解读人:张聪敏)
文献名:Proteomic Profiling of Paired Interstitial Fluids Reveals Dysregulated Pathways and Salivary NID ...
随机推荐
- <USACO07JAN>解决问题Problem Solvingの思路
日常为dp贡献脑细胞 #include<iostream> #include<cmath> #include<cstdio> #include<cstdlib ...
- Unique Snowflakes(窗口滑动)
题目: Emily the entrepreneur has a cool business idea: packaging and selling snowflakes. She has devis ...
- 关于Docker清理
在Docker的日常使用中,我们或许偶尔遇到下面这些情况: 12345678 $ docker-compose ps[27142] INTERNAL ERROR: cannot create temp ...
- mac下配置开发环境
常用命令 显示隐藏文件 1 defaults write com.apple.finder AppleShowAllFiles -boolean true ; killall Finder 关闭隐藏文 ...
- 差旅日志i·长安&北京(更新于8.21_夜)
大学之时,看到zealer王自如的差旅日志系列欲罢不能,扁平化的管理理念以及轻松的工作氛围,耳目一新的出差体验,抵消了部分不曾走入职场的紧张感甚至是恐惧感.如今初入职场也进入了职业生涯,特记录此次的差 ...
- Mysql锁和死锁分析
在MySQL中,行级锁并不是直接锁记录,而是锁索引.索引分为主键索引和非主键索引两种,如果一条sql语句操作了主键索引,MySQL就会锁定这条主键索引;如果一条语句操作了非主键索引,MySQL会先锁定 ...
- PHP实现读取一个1G的文件大小
需求如下: 现有一个1G左右的日志文件,大约有500多万行, 用php返回最后几行的内容. 1. 直接采用file函数来操作 or file_get_content() 肯定报内存溢出注: 由于 fi ...
- memcached单点登录配置
域名 www.lxy.comblog.lxy.comnews.lxy.comshop.lxy.com php配置 session.save_handler = memcache session写mem ...
- Spring源码分析-BeanFactoryPostProcessors 应用之 PropertyPlaceholderConfigurer
BeanFactoryPostProcessors 介绍 BeanFactoryPostProcessors完整定义: /** * Allows for custom modification of ...
- Neural Turing Machine - 神经图灵机
Neural Turing Machine - 神经图灵机 论文原文地址: http://arxiv.org/pdf/1410.5401.pdf 一般的神经网络不具有记忆功能,输出的结果只基于当前的输 ...