052.Kubernetes集群管理-故障排错指南
一 故障指南
1.1 常见问题排障
- 查看Kubernetes对象的当前运行时信息,特别是与对象关联的Event事件。这些事件记录了相关主题、发生时间、最近发生时间、发生次数及事件原因等,对排查故障非常有价值。此外,通过查看对象的运行时数据,还可以发现参数错误、关联错误、状态异常等明显问题。由于在Kubernetes中多种对象相互关联,因此这一步可能会涉及多个相关对象的排查问题。
- 对于服务、容器方面的问题,可能需要深入容器内部进行故障诊断,此时可以通过查看容器的运行日志来定位具体问题。
- 对于某些复杂问题,例如Pod调度这种全局性的问题,可能需要结合集群中每个节点上的Kubernetes服务日志来排查。比如搜集Master上的kube-apiserver、kube-schedule、kube-controler-manager服务日志,以及各个Node上的kubelet、kube-proxy服务日志,通过综合判断各种信息,就能找到问题的成因并解决问题。
二 常见措施
2.1 查看Event

- 没有可用的Node以供调度。
- 开启了资源配额管理, 但在当前调度的目标节点上资源不足。
- 镜像下载失败。
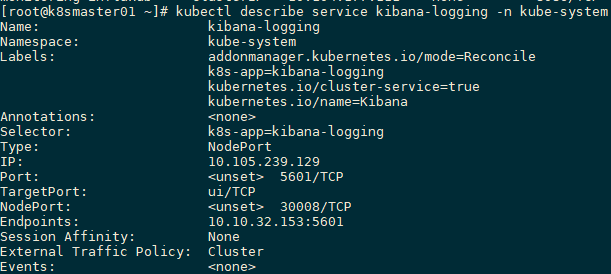
2.2 查看日志
2.3 查看Kubernetes服务日志

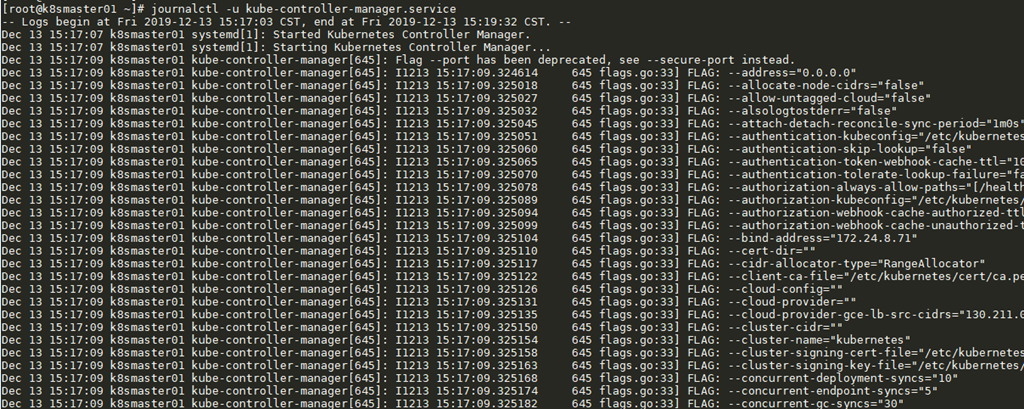
- --logtostderr=false:不输出到stderr。
- --log-dir=/var/log/kubernetes:日志的存放目录。
- --alsologtostderr=false:将其设置为true时,表示将日志同时输出到文件和stderr。
- --v=0:glog的日志级别。
- --vmodule=gfs*=2,test*=4:glog基于模块的详细日志级别。
- kube-controller-manager.ERROR;
- kube-controller-manager.INFO;
- kube-controller-manager.WARNING;
- kube-controller-manager.kubernetesmaster.unknownuser.log.ERROR.20150930-173939.9847;
- kube-controller-manager.kubernetesmaster.unknownuser.log.INFO.20150930-173939.9847;
- kube-controller-manager.kubernetesmaster.unknownuser.log.WARNING.20150930-173939.9847。
2.4 Kubernetes异常排查思路
三 常见Kubernetes问题
3.1 无法pull镜像
- 如果服务器可以访问Internet,并且不希望使用HTTPS的安全机制来访问gcr.io,则可以在Docker Daemon的启动参数中加上--insecure-registry gcr.io,来表示可以匿名下载。
- 如果Kubernetes集群在内网环境中无法访问gcr.io网站,则可以先通过一台能够访问gcr.io的机器下载pause镜像,将pause镜像导出后,再导入内网的Docker私有镜像库,并在kubelet的启动参数中加上--pod_infra_container_image,配置为:--pod_infra_container_image=<docker_registry_ip>:<port>/pause:3.1,之后重新创建redis-master即可正确启动Pod。
3.2 一直RESTARTS
3.3 通过服务名无法访问
- 查看Service的后端Endpoint是否正常
- Service的LabelSelector与Pod的Label不匹配;
- 后端Pod一直没有达到Ready状态(通过kubectlgetpods进一步查看Pod的状态);
- Service的targetPort端口号与Pod的containerPort不一致等。
- 查看Service的名称能否被正确解析为ClusterIP地址
- 查看kube-proxy的转发规则是否正确
052.Kubernetes集群管理-故障排错指南的更多相关文章
- 美团点评Kubernetes集群管理实践
背景 作为国内领先的生活服务平台,美团点评很多业务都具有非常显著.规律的”高峰“和”低谷“特征.尤其遇到节假日或促销活动,流量还会在短时间内出现爆发式的增长.这对集群中心的资源弹性和可用性有非常高的要 ...
- 基于Python+Django的Kubernetes集群管理平台
➠更多技术干货请戳:听云博客 时至今日,接触kubernetes也有一段时间了,而我们的大部分业务也已经稳定地运行在不同规模的kubernetes集群上,不得不说,无论是从应用部署.迭代,还是从资源调 ...
- 快速部署Kubernetes集群管理
这篇文章介绍了如何快速部署一套Kubernetes集群,下面就快速开始吧! 准备工作 //关闭防火墙 systemctl stop firewalld.service systemctl disabl ...
- kubernetes集群管理常用命令一
系列目录 我们把集群管理命令分为两个部分,第一部分介绍一些简单的,但是可能是非常常用的命令以及一些平时可能没有碰到的技巧.第二部分将综合前面介绍的工具通过示例来讲解一些更为复杂的命令. 列出集群中所有 ...
- 049.Kubernetes集群管理-集群监控Metrics
一 集群监控 1.1 Metrics Kubernetes的早期版本依靠Heapster来实现完整的性能数据采集和监控功能,Kubernetes从1.8版本开始,性能数据开始以Metrics API的 ...
- Kubernetes集群管理工具kubectl命令技巧大全
一. kubectl概述 Kubectl是用于控制Kubernetes集群的命令行工具,通过kubectl能够对集群本身进行管理,并能够在集群上进行容器化应用的安装部署. kubectl命令的语法如下 ...
- kubernetes集群管理之通过jq来截取属性
系列目录 首先要声明,这里的jq并不是批前端框架里的jquery,而是一个处理json的命令行工具. jq工具相比yq,它更加成熟,功能也更加强大,主要表现在以下几个方面 支持递归查找(我点对我们平时 ...
- kubernetes集群管理命令(三)
系列目录 前面两节我们由浅入深介绍了不少kubernetes管理比较常用的命令.本节我们通过案例讲解一些需要更为复杂的操作才能完成的命令. 选择一个deployment下的所有pod 前面讲到过,ku ...
- kubernetes集群管理命令(二)
系列目录 上一节我们介绍了一些基本的命令,这一节我们介绍一些更为复杂的命令. pod排序 使用kubectl get pod获取pod资源默认是以名称排序的,有些时候我们可能希望按其它顺序排序.比如说 ...
随机推荐
- 简说python之安装
Python是跨平台程序语言,做为世界流行的语言之一,它可以平滑地部署在Windows,Linux,Mac等平台之上,并有很多第三方模块的函数可供使用. 学习Python,首先需要把Python的编译 ...
- Redis05——Redis Cluster 如何实现分布式集群
前面一片文章,我们已经说了Redis的主从集群及其哨兵模式.本文将继续介绍Redis的分布式集群. 在高并发场景下,单个Redis实例往往不能满足业务需求.单个Redis数据量过大会导致RDB文件过大 ...
- kubeasz部署高可用kubernetes1.17.2 并实现traefik2.1.2部署
模板机操作 # cat /etc/redhat-release CentOS Linux release 7.6.1810 (Core) # uname -a //内核升级到4.4.X以后, 关于如何 ...
- 苹果笔记本 安装 ubuntu 默认没有无线网卡 的 解决方案
sudo apt-get update sudo apt-get install bcmwl-kernel-source
- Git 基础入门
目录 git安装 基本设置 创建版本库 相关概念 将代码提交到分支仓库 版本回退 代码修改 撤销修改 文件删除 github 远程仓库 添加远程仓库 克隆远程仓库 分支操作 忽略特殊文件 git安装 ...
- Map-->HashMap练习(新手)
//导入的包.import java.util.*;//创建的一个类.public class zylx1 { //公共静态的主方法. public static void main(String[] ...
- Python Django撸个WebSSH操作Kubernetes Pod(下)- 终端窗口自适应Resize
追求完美不服输的我,一直在与各种问题斗争的路上痛并快乐着 上一篇文章Django实现WebSSH操作Kubernetes Pod最后留了个问题没有解决,那就是terminal内容窗口的大小没有办法调整 ...
- no parameterless constructor define for type 解决一例
在生成根据模型和上下文生成带增删查改操作的视图的控制器时,提示上述信息,网上查找了资料也没有解决,突然想起该项目是连接MSSQL数据库和Redis数据库的,并且已经依赖注入了,而Redis数据库的服务 ...
- 题解 P5663 【加工零件【民间数据】】
博客园体验更佳 讲讲我的做法 确定做法 首先,看到这道题,我直接想到的是递归,于是复杂度就上天了,考虑最短路. 如何用最短路 首先,看一张图 我们该如何解决问题? 问题:\(3\)做\(5\)阶段的零 ...
- 网维大师无盘刷新B盘方法