MySQL 学习之查漏补缺
1、InnoDB 相关知识点
InnoDB 引擎是将数据划分为若干数据页,页大小一般16 KB,16384个字节。
插入数据是以记录为单位,这些记录在磁盘的存放方式称之为 行格式/记录格式,有 compact、Redundant、Dynamic和Compressed 四种格式。
1)、Compact 行格式
一条完整的记录:记录的额外信息(变长字段长度列表、NULL 值列表、记录头信息)、记录的真实数据(列1、列2...的值)。
变长字段长度列表:例如varcha()是可以变长的数据类型,变长字段存储多少字节的数据不是不固定的。变长字段例如 varchar() 占用的存储空间:真正的数据内容、占用的字节数。
当字段A varchar 记录的字节数大于 255,例如某字段占用300个字节,那么该字段占数据页中空间就是302个字节。1、2个字节是表示真正字符串占用的字节数。
NULL 值列表:某些列可能存储 NULL 值,如果把这些 NULL 值都放到记录的真实数据中存储,会很占地方。所以 Compact 行格式统一管理这些 NULL 值。
除了我们自己创建的列,还有些默认生成的列,例如:row_id(非必须)、transaction_id(事务ID)、roll_pointer(回滚指针)。
2)、Redundant 行格式
该格式是MySQL5.0之前用的格式,直接看一下不记笔记了。
3)、Dynamic 和 Compressed 行格式
和Compact的行格式很像,只是处理行溢出数据有点分歧。
一个varchar()类型的列可以存储65532个字节,大于了一个数据页16KB的大小,可能存在一个数据页存放不了一条记录的尴尬情况。
那么就把数据分散在其他也,用20个字节存储指向这些页的地址。(行溢出、溢出页)
行溢出临界点:不用管临界点是什么,只需要知道一个行中存储了很大的数据,就可能发生行溢出的现象。
2、InnoDB数据页结构
InnoDB存放记录的是索引页(FIL_PAGE_INDEX)。
一个数据页的存储空间大致被划分为了7个部分。
InnoDB 会把页中的记录划分为若干个组,每个组的最后一个记录的地址偏移量作为一个槽,存放在 Page Directory 中。在一个数据页查找指定主键值的记录的过程分两步:
第一步是通过二分法确定该记录所在的槽,并找到该槽中主键值最小的那条记录;
第二步是通过记录的 next_record 属性遍历该槽所在组中的各个记录。
数据页之间是一个双链表,每一页记录了该页的上下页的页码。
页之间的记录,又是一个单链表,记录的当前数据字节码的偏移量,关联关系是存在记录的头信息中的 next_record 属性。
3、B+ 树索引
新分配的数据页编号可能并不是连续的,只要他们的关联关系在就行。
页分裂:下一个数据页中记录的主键值,必须大于上一个页中记录的最大主键值。这样就发生了页分裂。(因为插入的主键可能是处于中间值位置,而不是最大值位置)
索引底层:每个数据页对应一个目录项,包括了:页中用户记录中最小的主键值,用 key 表示;页号,我们用 page_no 表示。所有目录聚集在一起,就成了索引(针对聚簇索引)。
专门分配了一个数据页,用来存储 目录项记录,多个这样的数据页,就组成了索引树的层。
所以一层一层的数据页,最终就叫做 B+ 树索引。
真正存放数据的数据页,一般叫做叶节点。存放目录项的叫内节点,最上层的叫根节点。一般的 B+ 树不会超过4层。这样的索引,也叫聚簇索引/聚集索引/主键索引。
根据二级索引查询数据,还的回表(先查二级索引,再查聚簇索引)。
联合索引:多个列字段联合做索引,先根据列A排序,列A值相同再根据列B排序。
注意事项:
聚簇索引是默认创建,并且为该索引创建一个根节点页面。当有页分裂为2个数据页时,就产生了树状。
内节点中目录项记录的唯一性,聚簇索引的目录项,是索引列的值+页号。而二级索引的目录项,是索引列的值+主键值+页号。
一个数据页,最少存储2条记录。
key 和 index 是同义词,都是创建索引。
4、B+ 树的使用
1)、索引的代价
空间上的代价:一个数据页16K,一个索引可能就占很大的内存空间。
时间上的代价:当对表中的数据进行增删改操作,都要去修改各个 B+ 树索引。增删改都可能对节点和记录的排序,造成破坏,InnoDB引擎可能需要额外的时间进行一些记录的移动、页面分裂、合并等操作来维护节点和记录的排序。
2)、B+ 树索引适用的条件
全值匹配:联合索引时,每个查询条件都是精确匹配了的。
匹配左边的列(最左前缀原则):查询条件,只包含了索引左边的字段。
匹配列前缀:like 语句就可以匹配列前缀的原则,Like 'name%'。
匹配范围值:当有多个条件对多个列进行范围查询,只有对索引最左边的那个列进行范围查询才用得到 B+ 树索引。
精确匹配某一列并范围匹配另外一列:此时两个查询都可以用到 B+ 树。
索引还可以用来排序:但是联合索引也只能按照索引的列顺序来排序。当 ASC、DESC 混用的时候,就不可以使用索引进行排序。
当where 条件的字段出现了非排序索引使用到的索引列,还是只有重新再内存中排序。
用于分组:分组的顺序和索引列的顺序一致,就可以使用索引列左边的列进行分组。
3)、回表的代价
一般回表会用到二级索引和聚簇索引,并且访问二级索引使用了顺序I/O,访问聚簇索引使用了随机I/O。需要回表的记录越多,使用二级索引的性能就越低。
所以就用到了覆盖索引。
4)、如何挑选索引
是为用于搜索、排序或分组的列创建索引。
考虑列的基数,就是该列不同的值越多,基数越大,越适合做索引。如果一列的值都差不多或者相同的太多,那就没必要建立索引。
索引列的类型尽量小:能用 Int 的就不使用 bigint 。数据类型越小,查询的操作比较快。索引占的存储空间也越少,在一个数据页可以放更多的记录,减少磁盘I/O带来的性能损耗,就可以把更多的数据页缓存在内存中,加快读写效率。
索引列字符串的值太长,我们可以取短的长度,例如字段的长度是100,我们可以把索引的长度设置为10。
让主键具有自增的属性,就可以减少聚簇索引的数据页分裂。
5、InnoDB 的表空间
1)、独立表空间
一个页16KB,一个区连续64页占1M空间,256个区为一组。第一组的前三个页面的类型是固定的(FSP_HDR、IBUF_BITMAP、INODE三个类型)。后面的各组前2个页面的类型是固定的(XDES、IBUF_BITMAP)。
为什么引入区的概念,是因为我们尽量要让链表中相邻的数据页在物理上也相邻,这样在范围查询的时候才可以顺序I/O,不然容易随机I/O。
当表中数据量大的时候,为某个索引分配空间的时候就直接按区分配内存,不需要按数据页来分配了。主要是为了消除随机I/O。
并且,存放数据页的叶节点的区的集合算一个段,存放内节点的区的集合算一个段。
区的分类:空闲的区、有剩余空间的碎片区、没有剩余空间的碎片区、附属某个段的区。
2)、系统表空间
系统表空间和独立表空间结构差不多,只是额外记录一些有关整个系统信息的页面。
3)、InnoDB 数据字典
元数据:在我们对数据库表插入一条数据时,让我们能准备找到我们要插入数据的表,以及一些相关的校验,这些额外的数据,就叫元数据。
记录元数据的系统表,也叫做数据字典。
6、连接Join
外连接时,凡不符合 where 条件的都不加入结果集。on 条件时,被驱动表无法找到匹配 on 子句的过滤条件,该记录还是会被加入到结果集中,对应的字段用 NULL 填充。
最好是在 on 条件后的字段上加索引,一般是主键和外键。
join buffer,执行查询前申请一块固定大小内存,把若干驱动表结果集放在这个 buffer 里。然后扫描被驱动表,每一条被驱动表和 join buffer 的多条驱动表记录匹配。内存中操作,所以减少了被驱动表的 I/O 代价。(Block Nested-Loop Join 算法,也可以叫做块嵌套)
可以用 join_buffer_size 调大佬做查询优化。
一般性项目中,最好是用被驱动表的 on 后的字段加索引,其次才是块嵌套。
MySQL 成本消耗
I/O 成本:顺序读、随机读、少读,顺序写、随机写。
CPU 成本:对结果集进行排序等操作。
执行计划:优化器找出查询成本最低的方案,就是执行计划。
Rows:预估的行数。Data_length:聚簇索引的页面数量 * 每个页面的大小(默认16K)
全盘扫描:I/O 成本:Data_length * 1.0。 CPU 成本:Rows * 0.2。 总成本就是两个值相加。
7、Explain 的 type 字段
const:主键/唯一索引,与常数进行等值匹配时,查询到的数据唯一,并且针对单表。因为只读一次,所以查询非常快。
range:使用索引获取某些 范围区间 的记录,就可能用到 range 访问方法。
index:不用回表,直接覆盖索引。(可能会全盘扫描二级索引树)
eq_ref:连接查询,被驱动表是主键/唯一索引,等值匹配(该主键/唯一索引是联合索引的话,所有的索引列都必须进行等值比较),则对被驱动表的访问方法就是 eq_ref。
ref:普通的二级索引列,与常量进行等值匹配查询一个表。当回表代价很低的时候,对该表的访问方法就可能是 ref。
ref_or_null:普通索引,进行等值匹配,该索引列的值也可以是 null 值时,则访问方法就可能是 ref_or_null。
index_merge:索引合并来对单表进行查询。一个 sql 语句用到多个索引。
unique_subquery:优化器觉得将 IN 子查询转换为 EXISTS 子查询,并且子查询可以使用到主键进行等值匹配,则该子查询就是用到的 unique_subquery。
index_subquery:和上面的 type 类似,只是子查询中的表使用的是普通索引。
all:全盘扫描。
一个使用到索引的搜索条件和没有使用该索引的搜索条件,用 OR 连接起来后是无法使用该索引的。
简化查询条件:当有等值查询和范围查询(字段不一样,但是都有索引),优化器会选择先等值查询,然后回表,然后匹配范围查询的条件。
如果有多个查询条件,且有的条件用不到索引,那就把该搜索条件替换为 true,因为不管索引记录满足该条件与否,都要取出所有数据,回表的时候才能比较。(用一个索引,其他条件都替换为 true)
8、Explain 的 Extra 字段
Using index:覆盖索引,不用回表。
Using index condition:索引下推(多个查询条件,有用不到索引的列。先根据普通索引查询到数据时,不回表,先过滤其他查询条件。符合所有查询条件的列,再回表查所有数据)。
Using where:全表扫描。或者 where 后有多个查询条件,并且有查询条件没有用到索引。此时会先匹配索引上的等值,先查出对应值,再比较其他无索引的条件值。
Using join buffer(Block Nested Loop):Join 语句中 被驱动表不能有效利用索引,使用 Join buffer 来减少对去被驱动的访问。
Not exists:join 查询被驱动表主键不可以为null,但是驱动表查询条件,包含了该关联字段= null。
Using temporary:临时表。
回表是一个随机IO,相对于来说还是比较耗时。
9、InnoDB Buffer Pool
连续的内存:Buffer Pool - 缓冲池,默认大小128M ,设置参数:innodb_buffer_pool_size = X,X 的单位是字节。
一个空闲控制块链表(free 链表),对应着所有空白缓存页(控制块和缓存页一一对应)。当需要从磁盘加载一个页面到缓存的时候,就从链表拿一个空闲缓存页,并且把控制块填上信息(表空间、页号等),然后从链表移除该数据页。
怎么确定,需要访问的数据页,是否已经在 Buffer Pool 中。主要是根据 表空间号 + 页号 来定位一个页的,将 表空间号 + 页号 作为 key,缓存页作为 value 值,存为一个 hash 表。查询就根据 hash 查询。如果 hash 表中没有查到该 key ,就从空闲控制块链表中选择一个空闲的缓存页。
创建一个存储脏页的链表,脏页对应的控制块都会作为一个节点存入到链表中,该链表可以叫 flush 链表。
LRU 链表,根绝 LUR 算法来淘汰掉一些数据页。优化后,将 LRU 链表分区,分为热数据(young 区域)和冷数据区(old 区域)。old 区域大概占 LRU 链表的3/8(可设置)。
LRU 链表算法/原理:
1)、磁盘上的某个页面,初始加载到 Buffer Pool 中的某个缓存页时,该缓存页对应的控制块会被放到 old 区域的头部。这样针对预读到 Buffer Pool 却不进行后续访问的数据页,就会被逐渐从 old 区域逐出,而不会影响 young 区域中被使用的很频繁的缓存页。
2)、针对全盘扫描,短时间内访问大量使用频率很低的页面的情况的优化:对处于 old 区域的缓存页第一次访问时存一个时间,后续访问与第一次访问的时间,在某个时间内,就不从 old 区域移动到 young 区域的头部。如果超过了该时间,就移动到 young 区域的头部。
该时间由 innodb_old_blocks_time 的值控制,默认1S。
注:全盘扫描,一个数据页有多条数据,扫描某一个数据页的第一条数据页时,访问了一次该数据页。如果再次访问该数据页的其他数据,又会访问该数据页。其实只是经历的一次全盘扫描,但是每一个数据页都会被多次扫描到。 所以才有了上面的第二条优化。并且在很多全盘扫描中,第一次访问一个数据页和第二次访问该数据页,时间肯定不会多于1S。
3)、继续优化 LRU 链表:只有访问到缓存页位于 young 区域的 1/4 的后边,再移动到 LRU 链表的头部。就可以降低 LRU 链表的调整频率。
刷脏页:
1)、从 LRU 链表的冷数据中刷新一部分页面到磁盘;
2)、从 flush 链表中刷新一部分页面到磁盘;
都是后台线程定时刷新页面到磁盘。
可以在 Buffer Pool 大小等于1G的时候设置多个 Buffer Pool 实例。
可以用 show engine innodb status 查询 Buffer Pool 的一些信息。
10、undo log (回滚日志)
undo log:也叫快照数据,是 MVCC 的核心组成部分。并发访问的时候,读取的是 undo log,可以读取到当前修改完的数据,而不用加锁那种对并发不友好的操作。
事务 id:当事务执行过程中,对一个表进行了增、删、改操作,InnoDB 引擎就会给它分配一个独一无二的 事务 id。
MySQL 维护一个全局变量,每当需要为某个事务分配一个事务 id 时,就把该变量值赋予事务id,并且把该值自增1。
聚簇索引的记录里除了数据以外,还有有一个 trx_id 的隐藏列。存的就是事务 id。
undo no 在一个事务中是从 0 开始递增的,只要事务没提交,每生成一条 undo 日志,那么该条日志的 undo no 就增1。(undo no 是一个事务中,操作多条记录,对应多条 undo log 的编号)
一个数据页中的两个链表,分别记录了正常的数据已经被删除的垃圾数据。当一个事务删除数据时,先将正常链表中的数据标记为中间状态记录。当事务提交时,才把数据标记为已删除。
11、事务隔离级别和 MVCC
脏写:一个事务修改了另一个未提交事务修改过的数据。不允许出现在任何一个事务隔离级别。
脏读:一个事务读取到另一个事务未提交的数据,出现在 读未提交 隔离级别。
不可重复度:一个事务读取到另一个事务已经提交的数据,并且其他事务每对该数据进行一次修改并提交后,第一个事务都能查询到最新值,出现在 读提交(RC) + 读未提交(RU)。(前后读到其他事务已提交的数据,在修改前后,不重复)
幻读:一个事务(查总数等)读取到其他事务(新增)的记录(前一个事务,相同条件多次读取数据,后面一次读取到之前没有读取到的记录。第二个事务如果是删除操作,不叫幻读),出现在 可重复读(RR)+ 读提交(RC) + 读未提交(RU)。可重复读用 临键锁(行锁 + 间隙锁)来解决。
MVCC (多版本并发控制)原理
先复习2个在聚簇索引记录中的两个必要的隐藏列:
trx_id:每次一个事务,对某条聚餐索引记录进行改动时,都会把该事务的 事务id 赋值给 trx_id 隐藏列。
roll_pointer:每次对某条聚簇索引记录进行改动时,都会把旧的版本写入到 undo 日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
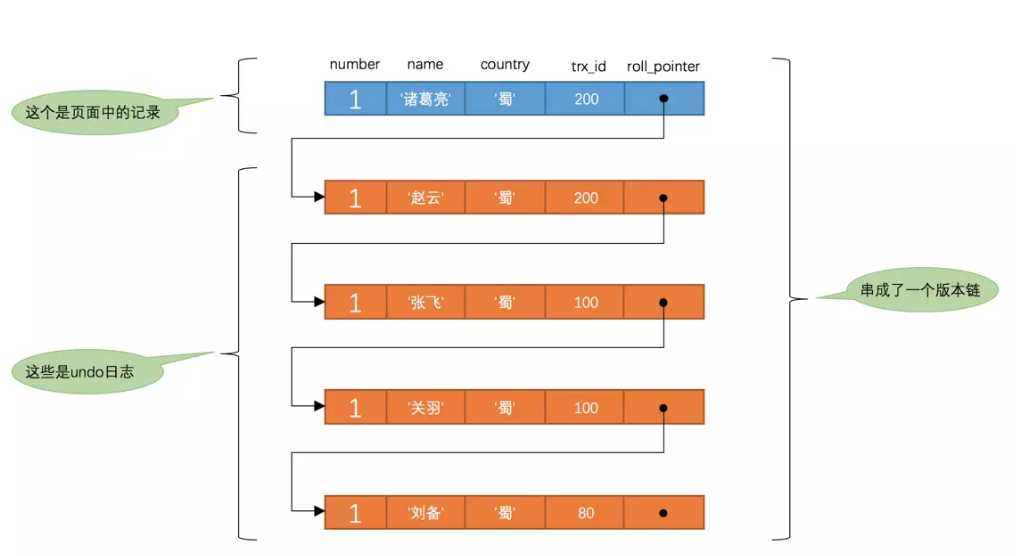
ReadView
RC 和 RR 隔离级别,核心问题是:需要判断这个版本链中的哪个版本,是对当前事务可见
所以提出了一个 ReadView 的概念,主要包含了4个重要内容:
m_ids:生成 ReadView 时,当前系统中活跃的读写事务的 事务id 列表;
min_trx_id:生成 ReadView 时,当前系统活跃的读写事务中的最小 事务id。也就是 m_ids 中的最小值;
max_trx_id:生成 ReadView 时系统中应该分配给下一个事务的 id 值。
creator_trx_id:生成该 ReadView 的事务的 事务id。
RC 级别:一个事务多条查询语句,每条语句读取数据前,都生成一个自己的 ReadView。
RR 级别:一个事务多条查询语句,一个事务只生成一个 ReadView。

总结:
多个版本的 undo log 日志,提供给并发查询的读取。每个事务都按照 ReadView 的规则来实际读取 undo log(快照) 不同版本的数据。
insert undo 在事务提交之后就可以被释放,因为是第一次提交,没有回滚的可能了。update undo 还需要指出 MVCC,所以不能在事务结束后立即删除。
为了指出 MVCC,对于 delete mark 操作来说,仅仅是在记录上打一个删除标记,而没有真正删除掉数据。
12、锁
并发事务会带来一个问题,在 写-写的时候,会发生脏写。所以就需要 锁 来解决该问题。
锁结构主要的两个信息:
trx信息:事务id,表示是哪个事务生成的。
is_waiting:代表当前事务是否在等待。false 表示当前事务获取到锁,true 表示当前事务等待锁。
当一个事务提交,释放当前事务的锁结构。查询其他事务是否还在等待获取当前数据的锁,如果是,就把该事务的 is_waiting 值改为 false,获取到锁。
一致性读
事务利用 MVCC 进行的读取操作被称之为 一致性读,一致性无锁读,快照读。不会对表的任何记录做 加锁 操作。
锁定读
共享锁(读锁)、独占锁(写锁)。
加读锁:select ... LOCK IN SHARE MODE,不影响其他事务获取读锁,但是其他事务要获取到写锁,就会阻塞,等到当前事务提交后(释放读锁),其他事务才能开始操作数据。
加写锁:select ... FOR UPDATE,其他事务获取读锁、写锁都会阻塞,等待该事务提交释放写锁,才能继续操作数据。
临键锁 = 行锁 + 间隙锁。
特别声明
该篇文章是我从掘金app上小孩子作者写的 MySQL 的文章的总结。并且只是我之前学习遗漏的知识点。所以里面的知识点不全。
所有有想看详细内容的朋友,可以转下面链接
https://juejin.im/book/5bffcbc9f265da614b11b731/section/5c0374a06fb9a049d37ed783
MySQL 学习之查漏补缺的更多相关文章
- 第一章Java学习(查漏补缺)
第一章主要内容: 1.Java的地位:网络地位 语言地位 需求地位 2.Java的特点:①简单 面向对象 平台无关:软件的运行不因操作系统,处理器的变化而无法运行或出现运行错误. ②多线程 动态 3. ...
- 2019Java查漏补缺(一)
看到一个总结的知识: 感觉很全面的知识梳理,自己在github上总结了计算机网络笔记就很累了,猜想思维导图的方式一定花费了作者很大的精力,特共享出来.原文:java基础思维导图 自己学习的查漏补缺如下 ...
- Mysql查漏补缺
Mysql查漏补缺 存储引擎 数据库使用存储引擎来进行CRUD的操作,不同的存储引擎提供了不同的功能.Mysql支持的存储引擎有InnoDB.MyISAM.Memory.Merge.Archive.F ...
- Mysql查漏补缺笔记
目录 查漏补缺笔记2019/05/19 文件格式后缀 丢失修改,脏读,不可重复读 超键,候选键,主键 构S(Stmcture)/完整性I(Integrity)/数据操纵M(Malippulation) ...
- 20165223 week1测试查漏补缺
week1查漏补缺 经过第一周的学习后,在蓝墨云班课上做了一套31道题的小测试,下面是对测试题中遇到的错误的分析和总结: 一.背记题 不属于Java后继技术的是? Ptyhon Java后继技术有? ...
- Go语言知识查漏补缺|基本数据类型
前言 学习Go半年之后,我决定重新开始阅读<The Go Programing Language>,对书中涉及重点进行全面讲解,这是Go语言知识查漏补缺系列的文章第二篇,前一篇文章则对应书 ...
- 《CSS权威指南》基础复习+查漏补缺
前几天被朋友问到几个CSS问题,讲道理么,接触CSS是从大一开始的,也算有3年半了,总是觉得自己对css算是熟悉的了.然而还是被几个问题弄的"一脸懵逼"... 然后又是刚入职新公司 ...
- js基础查漏补缺(更新)
js基础查漏补缺: 1. NaN != NaN: 复制数组可以用slice: 数组的sort.reverse等方法都会改变自身: Map是一组键值对的结构,Set是key的集合: Array.Map. ...
- Entity Framework 查漏补缺 (一)
明确EF建立的数据库和对象之间的关系 EF也是一种ORM技术框架, 将对象模型和关系型数据库的数据结构对应起来,开发人员不在利用sql去操作数据相关结构和数据.以下是EF建立的数据库和对象之间关系 关 ...
随机推荐
- mysql数据库远程访问设置方法
1. 修改方式1代码改表法. 可能是你的帐号不允许从远程登陆,只能在localhost.这个时候只要在localhost的那台电脑,登入mysql后,更改 "mysql" 数据库 ...
- python的基本数据类型简介
python的基本数据类型有:数字-numbers.字符串-str.列表-list.元组-tuple.字典-dict.布尔-bool.集合-set 下面来个概览先大概了解一下,后面博文中咱再细说- 1 ...
- 使用JavaScript策略模式校验表单
表单校验 Web项目中,登录,注册等等功能都需要表单提交,当把用户的数据提交给后台之前,前端一般要做一些力所能及的校验,比如是否填写,填写的长度,密码是否符合规范等等,前端校验可以避免提交不合规范的表 ...
- Django 中自定义用户模型及集成认证授权功能总结
1. 概述 Django 中的 django.contrib.auth 应用提供了完整的用户及认证授权功能. Django 官方推荐基于内置 User 数据模型创建新的自定义用户模型,方便添加 bir ...
- 关于WDK开发内核签名之WHQL签名认证流程简介
WHQL简介: WHQL全称Windows Hardware Quality Labs testing(Windows硬件质量实验室测试)它是对所涉及的第三方硬件或软件进行一系列测试,然后提交测试的日 ...
- 前端视频直播技术总结及video.js在h5页面中的应用
全手打原创,转载请标明出处:https://www.cnblogs.com/dreamsqin/p/12557070.html,多谢,=.=~ (如果对你有帮助的话请帮我点个赞啦) 目前有一个需求是在 ...
- 泛微E-cology OA 远程代码执行漏洞
分析文章:https://dwz.cn/bYtnsKwa http://127.0.0.1/weaver/bsh.servlet.BshServlet 若存在如上页面,则用下面数据包进行测试. POS ...
- Cisco 综合配置(三)
要求: 1.PC1 PC2使用DHCP,获取IP ,VLAN为10 和20,网关在Core Switch 2上2.DHCP和web server VLAN为100,网关在Core Switch 1上3 ...
- intern()方法的使用
intern() intern方法的作用是:如果字符串常量池中已经包含一个字符串等于此String对象的字符串,则返回常量池中的这个String对应的对象, 否则将其添加到常量池并返回常量池中的引用. ...
- 四、用户交互(输入input,格式化输出)与运算符
1.接收用户的输入 在Python3:input会将用户输入的所有内容都存成字符串类型 列: username = input("请输入您的账号:") # "egon&q ...