sklearn KMeans聚类算法(总结)
基本原理
Kmeans是无监督学习的代表,没有所谓的Y。主要目的是分类,分类的依据就是样本之间的距离。比如要分为K类。步骤是:
- 随机选取K个点。
- 计算每个点到K个质心的距离,分成K个簇。
- 计算K个簇样本的平均值作新的质心
- 循环2、3
- 位置不变,距离完成
距离
Kmeans的基本原理是计算距离。一般有三种距离可选:
- 欧氏距离
\[d(x,u)=\sqrt{\sum_{i=1}^n(x_i-\mu_i)^2}
\] - 曼哈顿距离
\[d(x,u)=\sum_{i=1}^n(|x_i-\mu|)
\] - 余弦距离
\[cos\theta=\frac{\sum_{i=1}^n(x_i*\mu)}{\sqrt{\sum_i^n(x_i)^2}*\sqrt{\sum_1^n(\mu)^2}}
\]
inertia
每个簇内到其质心的距离相加,叫inertia。各个簇的inertia相加的和越小,即簇内越相似。(但是k越大inertia越小,追求k越大对应用无益处)
代码
模拟数据:
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
X, y = make_blobs(n_samples=500, # 500个样本
n_features=2, # 每个样本2个特征
centers=4, # 4个中心
random_state=1 #控制随机性
)
画出图像:
color = ['red', 'pink','orange','gray']
fig, axi1=plt.subplots(1)
for i in range(4):
axi1.scatter(X[y==i, 0], X[y==i,1],
marker='o',
s=8,
c=color[i]
)
plt.show()
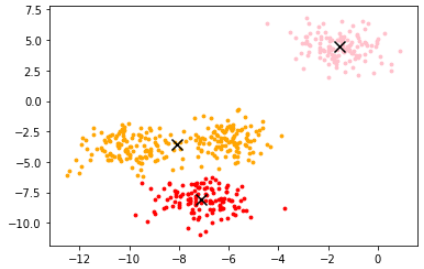
使用KMeans类建模:
from sklearn.cluster import KMeans
n_clusters=3
cluster = KMeans(n_clusters=n_clusters,random_state=0).fit(X)
也可先用fit, 再用predict,但是可能数据不准确。用于数据量较大时。
此时就可以查看其属性了:质心、inertia.
centroid=cluster.cluster_centers_
centroid # 查看质心
查看inertia:
inertia=cluster.inertia_
inertia
画出所在位置。
color=['red','pink','orange','gray']
fig, axi1=plt.subplots(1)
for i in range(n_clusters):
axi1.scatter(X[y_pred==i, 0], X[y_pred==i, 1],
marker='o',
s=8,
c=color[i])
axi1.scatter(centroid[:,0],centroid[:,1],marker='x',s=100,c='black')
sklearn KMeans聚类算法(总结)的更多相关文章
- 转载: scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- 一步步教你轻松学K-means聚类算法
一步步教你轻松学K-means聚类算法(白宁超 2018年9月13日09:10:33) 导读:k-均值算法(英文:k-means clustering),属于比较常用的算法之一,文本首先介绍聚类的理 ...
- 《数据挖掘导论》实验课——实验七、数据挖掘之K-means聚类算法
实验七.数据挖掘之K-means聚类算法 一.实验目的 1. 理解K-means聚类算法的基本原理 2. 学会用python实现K-means算法 二.实验工具 1. Anaconda 2. skle ...
- K-Means 聚类算法
K-Means 概念定义: K-Means 是一种基于距离的排他的聚类划分方法. 上面的 K-Means 描述中包含了几个概念: 聚类(Clustering):K-Means 是一种聚类分析(Clus ...
- k-means聚类算法python实现
K-means聚类算法 算法优缺点: 优点:容易实现缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他 ...
- K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
- Kmeans聚类算法原理与实现
Kmeans聚类算法 1 Kmeans聚类算法的基本原理 K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一.K-means算法的基本思想是:以空间中k个点为中心进行聚类,对 ...
- 机器学习六--K-means聚类算法
机器学习六--K-means聚类算法 想想常见的分类算法有决策树.Logistic回归.SVM.贝叶斯等.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别 ...
- 沙湖王 | 用Scipy实现K-means聚类算法
沙湖王 | 用Scipy实现K-means聚类算法 用Scipy实现K-means聚类算法
随机推荐
- C# Process类详解
C# Process类详解 Process[] processes = Process.GetProcessesByName(current.ProcessName); 根据进程名字找到所有进程,返回 ...
- Intent 显示意图 隐式意图
//显式意图 :必须指定要激活的组件的完整包名和类名 (应用程序之间耦合在一起) // 一般激活自己应用的组件的时候 采用显示意图 //隐式意图: 只需要指定要动作和数据就可以 ( 好处应用程序之 ...
- 目标检测算法的总结(R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD、FNP、ALEXnet、RetianNet、VGG Net-16)
目标检测解决的是计算机视觉任务的基本问题:即What objects are where?图像中有什么目标,在哪里?这意味着,我们不仅要用算法判断图片中是不是要检测的目标, 还要在图片中标记出它的位置 ...
- StringUtils.format用法
String.format()字符串常规类型格式化的两种重载方式 format(String format, Object… args) 新字符串使用本地语言环境,制定字符串格式和参数生成格式化的新字 ...
- 对python中元类的理解
1. 类也是对象 在大多数编程语言中,类就是一组用来描述如何生成一个对象的代码段.在Python中这一点仍然成立: >>> class ObjectCreator(object): ...
- Python学习——enumerate
enumerate(seq, start) seq -- 可遍历的序列 start -- 下标起始位置 seq = [11,22,33,44,55] for i in seq: print( ...
- 数据库连接池C3P0的使用
一.直接使用代码链接(一般企业开发不会用到.大多数用方法二) 1.导入jar 2.新建JDBCUtil import java.io.FileInputStream; import java.io.I ...
- Android进阶——Android视图工作机制之measure、layout、draw
自定义View一直是初学者们最头疼的事情,因为他们并没有了解到真正的实现原理就开始试着做自定义View,碰到很多看不懂的代码只能选择回避,做多了会觉得很没自信.其实只要了解了View的工作机制后,会发 ...
- quartz详解4:quartz线程管理
http://blog.itpub.NET/11627468/viewspace-1766967/ quartz启动后有多个线程同时在跑.启动时会启动主线程.集群线程.检漏线程.工作线程.主线程负责查 ...
- Day 10:浅谈正则表达式
正则表达式 以检验扣扣号是否合法为例引入正则表达式 要求:校验QQ号,要求:必须是5~15位数字,0不能开头. 1.没有正则表达式 public class Demo1 { public static ...