T-SQL查询进阶--理解SQL Server中索引的概念,原理
简介
在SQL Server中,索引是一种增强式的存在,这意味着,即使没有索引,sql server仍然可以实现应有的功能,但索引可以在大多数情况下提升查询性能,在OLAP(On line Transaction Processing)中尤其明显,要完全理解索引的概率,需要了解大量原理性的知识,包括B数,堆,数据库页,区,填充因子,碎片,文件组等到一系列相关知识,这些知识写一本小书也不为过。所以本文并不会深入讨论这些主题。
索引是什么
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息
精简来说,索引是一种结构.在SQL Server中,索引和表(这里指的是加了聚集索引的表)的存储结构是一样的,都是B树,B树是一种用于查找的平衡多叉树.理解B树的概念如下图:

理解为什么使用B树作为索引和表(有聚集索引)的结构,首先需要理解SQL Server存储数据的原理.
在SQL SERVER中,存储的单位最小是页(PAGE),页是不可再分的。就像细胞是生物学中不可再分的,或是原子是化学中不可再分的最小单位一样.这意味着,SQL SERVER对于页的读取,要么整个读取,要么完全不读取,没有折中.
在数据库检索来说,对于磁盘IO扫描是最消耗时间的.因为磁盘扫描涉及很多物理特性,这些是相当消耗时间的。所以B树设计的初衷是为了减少对于磁盘的扫描次数。如果一个表或索引没有使用B树(对于没有聚集索引的表是使用堆heap存储),那么查找一个数据,需要在整个表包含的数据库页中全盘扫描。这无疑会大大加重IO负担.而在SQL SERVER中使用B树进行存储,则仅仅需要将B树的根节点存入内存,经过几次查找后就可 以找到存放所需数据的被叶子节点包含的页!进而避免的全盘扫描从而提高了性能.
下面,通过一个例子来证明:
在SQL SERVER中,表上如果没有建立聚集索引,则是按照堆(HEAP)存放的
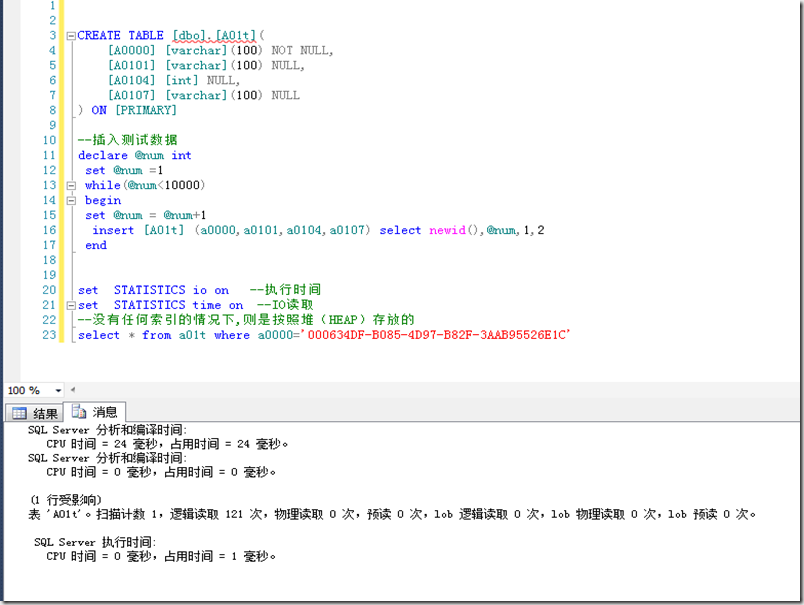
我通过在其上加上聚集索引(以B树存放)来展现对IO的减少:
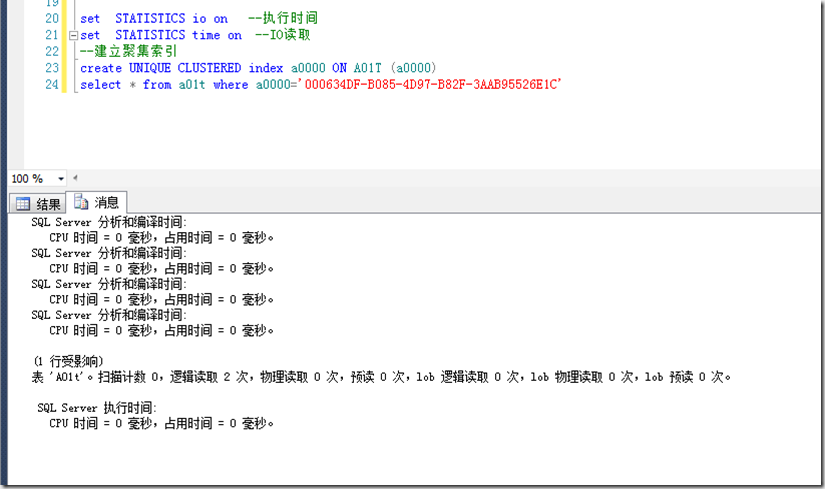
可以看出在堆(HEAP)存放时IO 读取为121个数据页,在B树存放时IO读取变成2个数据页
理解聚集和聚集索引
在SQL SERVER中,最主要的两类索引是聚集索引和非聚集索引。可以看到,这两个分类是围绕聚集这个关键字进行的.那么首先要理解什么是聚集.
聚集在索引中的定义:
为了提高某个属性(或属性组)的查询速度,把这个或这些属性(称为聚集码)上具有相同值的元组集中存放在连续的物理块称为聚集。
简单来说,聚集索引就是:

在SQL SERVER中,聚集的作用就是将某一列(或是多列)的物理顺序改变为和逻辑顺序相一致;例如
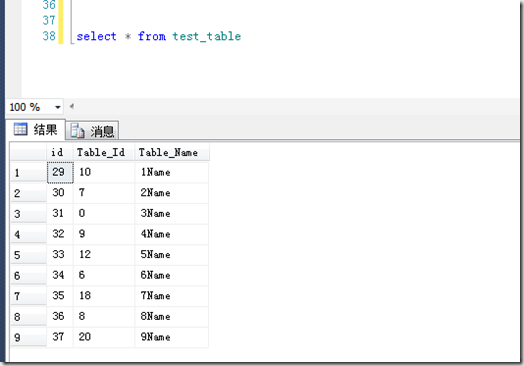
当我在Table_Id上建立聚集索引时,再次查询:
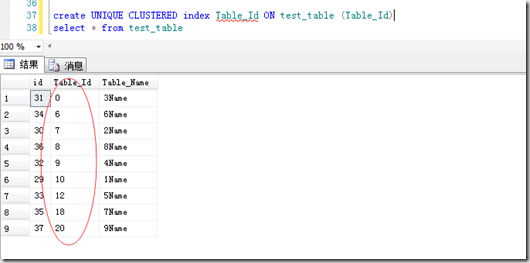
同一条语句,顺序变的不同了,物理顺序按照Table_Id排序了
在SQL SERVER中,聚集索引的存储是以B树存储,B树的叶子直接存储聚集索引的数据:

因为聚集索引改变的是其所在表的物理存储顺序,所以每个表只能有一个聚集索引.
非聚集索引
因为每一个表只能有一个聚集索引,如果我们对一个表的查询不仅仅限于聚集索引上的字段,我们又对聚集索引列之外的还有索引要求,那么就需要非聚集索引了。
非聚集索引,本质上来说也是聚集索引的一种,非聚集索引并不改变其所在表的物理结构,二手额外生成一个聚集索引的B树结构,但叶子节点对于其所在表的引用,这个引用分为两种,如果其所在表上没有聚集索引,则引用行号,如果其所在表上已经有了聚集索引,则引用聚集索引的页。
一个简单的非聚集索引概率如下:
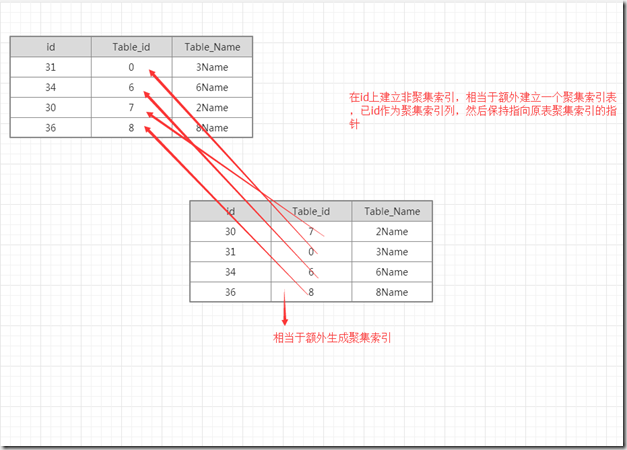
可以看到,非聚集索引需要额外的空间进行存储,按照被索引列进行聚集索引,并在B树的叶子节点包含指向非聚集索引所在表的指针.
MSDN中,对于非聚集索引描述图是:

可以看到,非聚集索引也是一个B树结构,与聚集索引不同的是,B树的叶子节点存的是指向堆或聚集索引的指针.
通过非聚集索引的原理可以看出,如果其所在表的物理结构改变后,比如加上或是删除聚集索引,那么所有非聚集索引都需要被重建,这个对于性能的损耗是相当大的。所以最好要先建立聚集索引,再建立对应的非聚集索引.
聚集索引 VS 非聚集索引
前面通过对于聚集索引和非聚集索引的原理解释.我们不难发现,大多数情况下,聚集索引的速度比非聚集索引要略快一些.因为聚集索引的B树叶子节点直接存储数据,而非聚集索引还需要额外通过叶子节点的指针找到数据.
还有,对于大量连续数据查找,非聚集索引十分乏力,因为非聚集索引需要在非聚集索引的B树中找到每一行的指针,再去其所在表上找数据,性能因此会大打折扣.有时甚至不如不加非聚集索引.
因此,大多数情况下聚集索引都要快于非聚集索引。但聚集索引只能有一个,因此选对聚集索引所施加的列对于查询性能提升至关紧要.
索引的使用
索引的使用并不需要显式使用,建立索引后查询分析器会自动找出最短路径使用索引.
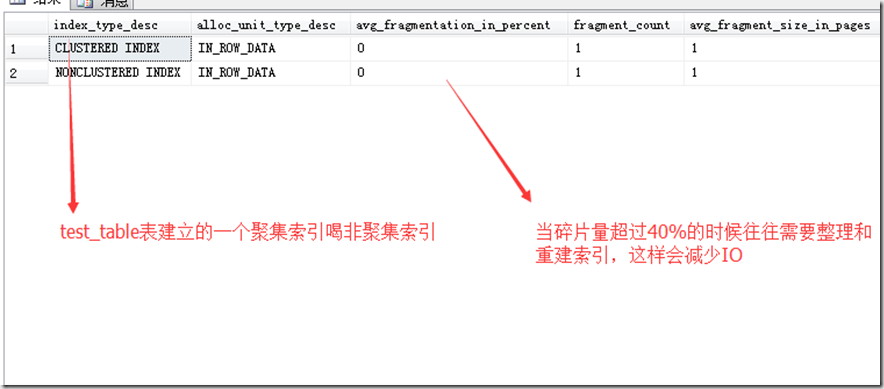
但是有这种情况.当随着数据量的增长,产生了索引碎片后,很多存储的数据进行了不适当的跨页,会造成碎片,我们需要重新建立索引以加快性能:
比如前面的test_table上建立的一个聚集索引和非聚集索引,可以通过DMV语句查询其索引的情况:
SELECT index_type_desc,alloc_unit_type_desc,avg_fragmentation_in_percent,fragment_count,avg_fragment_size_in_pages,page_count,record_count,avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID('youhua'),OBJECT_ID('test_table'),NULL,NULL,'Sampled')
使用索引的代价
我们通过索引获得的任何性能提升并不是不需要付出代价。这个代价来自几方面.
1.通过聚集索引的原理我们知道,当表建立索引后,就以B树来存储数据.所以当对其进行更新插入删除时,就需要页在物理上的移动以调整B树.因此当更新插入删除数据时,会带来性能的下降。而对于聚集索引,当更新表后,非聚集索引也需要进行更新,相当于多更新了N(N=非聚集索引数量)个表。因此也下降了性能.
2.通过上面对非聚集索引原理的介绍,可以看到,非聚集索引需要额外的磁盘空间。
3.前文提过,不恰当的非聚集索引反而会降低性能.
本文从索引的原理和概念对SQL SERVER中索引进行介绍,索引是一个很强大的工具,也是一把双刃剑.对于恰当使用索引需要对索引的原理以及数据库存储的相关原理进行系统的学习.
原文地址 :http://www.cnblogs.com/CareySon/archive/2011/12/22/2297568.html
T-SQL查询进阶--理解SQL Server中索引的概念,原理的更多相关文章
- 【转】T-SQL查询进阶—理解SQL Server中的锁
简介 在SQL Server中,每一个查询都会找到最短路径实现自己的目标.如果数据库只接受一个连接一次只执行一个查询.那么查询当然是要多快好省的完成工作.但对于大多数数据库来说是需要同时处理多个查 ...
- T-SQL查询进阶—理解SQL Server中的锁
在SQL Server中,每一个查询都会找到最短路径实现自己的目标.如果数据库只接受一个连接一次只执行一个查询.那么查询当然是要多快好省的完成工作.但对于大多数数据库来说是需要同时处理多个查询的.这些 ...
- 理解SQL Server中索引的概念
T-SQL查询进阶--理解SQL Server中索引的概念,原理以及其他 简介 在SQL Server中,索引是一种增强式的存在,这意味着,即使没有索引,SQL Server仍然可以实现应有的功能 ...
- T-SQL查询进阶--理解SQL Server中索引的概念,原理以及其他
简介 在SQL Server中,索引是一种增强式的存在,这意味着,即使没有索引,SQL Server仍然可以实现应有的功能.但索引可以在大多数情况下大大提升查询性能,在OLAP中尤其明显.要完全理解索 ...
- 理解SQL Server中索引的概念,原理
转自:http://www.cnblogs.com/CareySon/archive/2011/12/22/2297568.html 简介 在SQL Server中,索引是一种增强式的存在,这意味着, ...
- 理解SQL Server中索引的概念,原理以及其他(转载)
简介 在SQL Server中,索引是一种增强式的存在,这意味着,即使没有索引,SQL Server仍然可以实现应有的功能.但索引可以在大多数情况下大大提升查询性能,在OLAP中尤其明显.要完全理解索 ...
- Sql Server 中锁的概念(1)
Sql Server 中锁的概念 锁的概述 一. 为什么要引入锁 多个用户同时对数据库的并发操作时会带来以下数据不一致的问题: 丢失更新A,B两个用户读同一数据并进行修改,其中一个用户的修改结果破 ...
- 用SQL查询方式显示GROUP BY中的TOP解决方法[转]
用SQL查询方式显示GROUP BY中的TOP怎样用一个SQL语句来显示 分组后每个组的前几位 比如把一个学校所有学生的成绩按班级分组,再显示每个班级前五名的信息. 班级 学生 成绩 一班 ...
- 在Delphi中动态地使用SQL查询语句 Adoquery sql 参数 冒号
在Delphi中动态地使用SQL查询语句 在一般的数据库管理系统中,通常都需要应用SQL查询语句来提高程序的动态特性.下面介绍如何在Delphi中实现这种功能.在Delphi中,使用SQL查询语句的途 ...
随机推荐
- mysql索引之六:mysql高效索引之覆盖索引
概念 如果索引包含所有满足查询需要的数据的索引成为覆盖索引(Covering Index),也就是平时所说的不需要回表操作 判断标准 使用explain,可以通过输出的extra列来判断,对于一个索引 ...
- Vue.js:自定义指令
ylbtech-Vue.js:自定义指令 1.返回顶部 1. Vue.js 自定义指令 除了默认设置的核心指令( v-model 和 v-show ), Vue 也允许注册自定义指令. 下面我们注册一 ...
- PL/SQL 训练04--事务
--pl/sql通过SQL和ORACLE数据库紧密的整合在一起--在pl/sql中可以执行任何操作语句(DML语句),包括INSERT,UPDATE,DELETE,MERGE,也包括查询语句--可否执 ...
- Rest之路 - Rest架构中的重要概念(二)
状态无关性 Rest 架构中不维持client,resource and request 的状态,我们通常称 Rest 服务是状态无关的.基于此的优势是为设计Rest架构提供了简便:每一个请求可以被完 ...
- dB2 索引相关
ALTER TABLE "XXXX"."tableA" PCTFREE 20 ; CREATE INDEX "schema"."X ...
- Docker构建ssh镜像
FROM ubuntu MAINTAINER ggzone xxx@live.com ENV REFRESHED_AT 2015-10-21 RUN apt-get -qqy update & ...
- jQuery笔记——Ajax
Ajax 全称为:“Asynchronous JavaScript and XML”(异步 JavaScript 和 XML), 它并不是 JavaScript 的一种单一技术,而是利用了一系列交互式 ...
- python arp欺骗
使用python构造一个arp欺骗脚本 import os import sys from scapy.all import * import optparse def main(): usage=& ...
- Dev控件类似于ComBox的DropDownControl用法
dropDownButton1.DropDownControl= CreateDXPopupMenu(); private DXPopupMenu CreateDXPopupMenu() { DXPo ...
- 季逸超:90后IT少年的“盖茨梦”
2月15日,"90后"独立开发者季逸超在其微博称,个人获得徐小平和红杉资本投资,成立了Peak Labs--以贝尔和施乐为目标的实验室. 谁是季逸超?他现年20岁,曾单独一人做出猛 ...