plsql programming 20 管理PL/SQL代码(个人感觉用不到)
这一章的内容, 只完成了一部分, 剩下的用到再补充吧
由于依赖关系, 而编译失败, 需要重新编译. ( 所谓依赖, 是指存储过程, 函数等在运行中调用的对象, 比如table 等, 比如你删除了过程中调用的table, 然后又创建了一个一模一样的, 这个过程就需要重新编译)
alter package bookworm compile body reuse settings;
alter procedure add_book compile reuse settings;
1. 数据字典帮助
USER_* : 查看当前连接模式所拥有的数据库对象的信息.
ALL_* : 当前连接模式能够访问的数据库对象的信息(可能是因为当前模式拥有这些对象, 也可能是因为当前模式已经被授予访问这些对象), 通常这类视图和对应的USER视图具有相同的列, 不过ALL 视图中会多出一个OWNER列.
DBA_* : 这个视图显示的是全部(不包括SYS拥有的)数据库对象的信息, 这类视图通常和对应的ALL视图具有相同的列.
USER_ARGUMENTS : 当前模式所拥有的全部过程和函数的参数信息.
USER_DEPENDENCIES: 当前模式的对象互相依赖关系, oracle 主要通过这个视图标识对象的无效状态.
USER_ERORRS : 当前模式拥有的对象(包括触发器)的编译错误. SQL*PLUS 的 show errors 命令访问的就是这个视图.
USER_IDENTIFIERS(oracle11g 之后引入): 强大的代码分析工具
USER_OBJECTS : 这个视图显示我们拥有的对象.
USER_OBJECT_SIZE : 对象的大小, 事实上, 这个视图显示的是源代码, 解析后的代码以及编译后的代码大小.
USER_PLSQL_OBJECT_SETTINGS(oracle10g 之后引入): 记录的是PL/SQL对象的可以通过ALTER 以及SET DDL 命名修改的属性信息.
USER_PROCEDURES : 这个视图显示的是存储程序的信息.
USER_SOURCE : 我们所拥有对象的源代码
USER_STORED_SETTINGS: PL/SQL 编译器标志, 通过这些视图可以发现哪些程序是通过原生编译的.
USER_TRIGGERS 及 USER_TRIG_COLUMNS : 我们所拥有的数据库触发器.
例如:
1: select object_type, object_name, status
2: from user_objects
3: where object_type in (
4: 'PACKAGE', 'PACKAGE BODY', 'FUNCTION', 'PROCEDURE'
5: 'TYPE', 'TYPE BODY', 'TRIGGER')
6: order by object_type, status, object_name
另外 user_source 这个字典也非常有用, 例如:

1: create or replace procedure progwith(str in varchar2)
2: is
3: type info_rt is record(
4: name user_source.name%type,
5: text user_source.text%type
6: );
7: type info_aat is table of info_rt
8: index by pls_integer;
9:
10: info_aa info_aat;
11: begin
12: select name || '-' || line,
13: text
14: BULK COLLECT INTO info_aa
15: from user_source
16: where upper(text) LIKE '%' || UPPER(str) || '%'
17: and NAME <> 'VALSTD'
18: and NAME <> 'ERRNUMS';
19:
20: disp_header('Checking for presence of "' || str || '"');
21:
22: for indx in info_aa first .. info_aa.last
23: loop
24: pl(info_aa(indx).name, info_aa(indx).text);
25: end loop;
26: end progwith;
一旦这个包编译成功, 我们就可以检查如下: exec valstd.progwith(‘-20’)

PL/SQL 程序调试
PL/SQL 自动测试




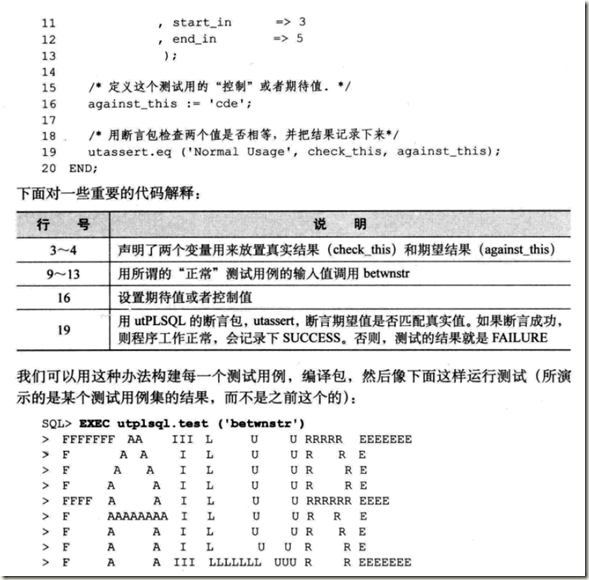

跟踪测试









PL/SQL 程序的调试





休息一下, 寻求帮助, 有的时候的确休息一下, 再考虑会有不一样的天空.

plsql programming 20 管理PL/SQL代码(个人感觉用不到)的更多相关文章
- 将PL/SQL代码封装在机灵的包中
将代码封装在机灵的包中 http://www.oracle.com/technetwork/issue-archive/2013/13-jan/o13plsql-1872456.html 绝大多数基于 ...
- 同样的一句SQL语句在pl/sql 代码块中count 没有数据,但是直接用SQl 执行却可以count 得到结果
pl/sql 代码块: SELECT count(distinct t2.so_nbr) INTO v_count2 FROM KFGL_YW_STEP_qd t2 WHERE t2.partitio ...
- 使用PL/Scope分析PL/SQL代码
使用PL/Scope分析你的PL/SQL代码 从11g開始Oracle引入了PL/Scope 用于编译器收集PL/SQL程序单元的全部标识符(变量名.常量名.程序名等). 收集到的信息可通过一系列静态 ...
- oracle 中使用 pl/sql代码块
1.写匿名块,输入三角形三个表的长度.在控制台打印三角形的面积. declare -- (p=(a+b+c)/2) --声明三角形的面积 三条边 的 v_a number (10,2):=&n ...
- oracle中plsql练习题-----编写一个PL/SQL块,输出所有员工的员工姓名、员工号、工资和部门号
一.思路:首先输出需要变量接收,需要声明变量,于是考虑什么变量类型比较合适,在这我用的是table类型,最后,查询出来,循环输出即可. 二.具体实现 -- 编写一个PL/SQL块,输出所有员工的员工姓 ...
- plsql programming 16 动态SQL和动态PLSQL
动态SQL 是指在执行时才构建 SQL 语句, 相对于静态 sql 的编译时就已经构建. 动态PLSQL 是指整个PL/SQL代码块都是动态构建, 然后再编译执行的. 作用: 1. 可以支持 DDL ...
- pl/sql programming 02 创建并运行plsql代码
/* * chap 02 * ------------------------------------------------- */ create or replace function wordc ...
- PLSQL(PL/SQL)集成Team Foundation Server (TFS),实现数据库代码的版本管理
PL/SQL是面向Oralcle数据库的集成开发环境,是众多Oracle数据库开发人员的主要工具.由于PL/SQL(百度百科)不仅是一种SQL语言,更是一种过程编程语言,在项目实施过程中,会积累大量除 ...
- PL/SQL 01 代码编写规则
1.标识符命名规则当在 PL/SQL 中使用标识符定义变量.常量时,标识符名称必须以字符开始,并且长度不能超过 30 个字符.另外,为了提高程序的可读性,Oracle 建议用户按照以下规则定义各种标识 ...
随机推荐
- linux下分区相关知识
Linux 规定了主分区(或者扩展分区)占用 1 至 16 号码中的前 4 个号码.以第一个 IDE 硬盘为例说明,主分区(或者扩展分区)占用了 hda1.hda2.hda3.hda4,而逻辑分区占用 ...
- SQL Server 基础 之 CASE 子句
SELECT TOP 10 SalesOrderID, SalesOrderID % 10 AS 'Last Digit',-- 求最后一位的值 Position = CASE SalesOrderI ...
- ArrayAdapter、SimpleAdapter和BaseAdapter示例代码
import android.content.Context; import android.util.Pair; import android.view.View; import android.v ...
- PostgreSQL配置文件--连接和认证
1 连接和认证 CONNECTIONS AND AUTHENTICATION 1.1 连接 CONNECTIONS 1.1.1 listen_addresses 字符型 默认: listen_addr ...
- What's New In DevTools (Chrome 59)来看看最新Chrome 59的开发者工具又有哪些新功能
原文:https://developers.google.com/web/updates/2017/04/devtools-release-notes#command-menu 参考:https:// ...
- OpenGL实现多层绘制(Layered Rendering) [转]
http://blog.csdn.net/u010462297/article/details/50589991 引言 在某些情况下会需要用到多层绘制.FBO下有多个颜色挂接点(Color Attac ...
- http://blog.csdn.net/rosten/article/details/17068285
http://blog.csdn.net/rosten/article/details/17068285
- [Javascript] Use a Pure RNG with the State ADT to Select an Element from State
The resultant in a State ADT instance can be used as a means of communication between different stat ...
- 深入浅出CChart 每日一课——快乐高四第六课 二丫的青梅,返璞归真之普通窗体多区域画图
有好些朋友给我反映,就是一个窗体中加入好几个CChartWnd之后.工作不正常.这个的确是这样,CChartWnd会接管原来窗体的消息循环,加入多个CChartWnd之后,就相当于出租房转手好几道,消 ...
- lodash 工具库
lodash是一套工具库,内部封装了很多字符串.数组.对象等常见数据类型的处理函数. 1.lodash的引用 import _ from 'lodash' 用一个数组遍历来说明为什么要使用lodash ...